C++STL在算法竞赛中的应用详解
写在前面
博主是一个想打a的大一下计科生,刚刚接触算法,只学了一部分,因为经常忘记STL这个有用的工具而不知道怎么去处理一些问题,所以想要总结一下STL常用的函数和数据结构及其特性,让脑子中存下这个东西,后续使用就有印象了
本篇篇幅很长,建议直接从目录跳转到你想找到的内容,一点一点往下翻很难翻完
常用STL内容罗列
STL的常用功能函数有:去重、排序、查找、翻转、交换、位运算、计算元素累加和、计算内积、求并集、求差集、求交集
STL的常用数据结构有:字符串、二元组、向量、队列、栈、优先队列、双端队列、基于红黑树实现的映射、集合、多重集合、多重映射、无序集合、无序映射
功能函数详解
(1)去重
这个函数的名字叫unique,需要包含引用头文件<algorithm>,针对的是已经排好序的序列
实现原理:将数组中不重复的元素移动到数组最前边,若是相邻位置已经移动过这个元素了,下一个元素就不会移动,依次类推,直到遍历到数组最开始的状态下的最后一个元素的位置。
这个函数的返回值是这个最后停留的位置的迭代器,可以用auto或指针类型捕获
适用范围:这是一个通用的算法,只要要去重的序列满足迭代器和元素可以比较的需求,就可以使用
图解:
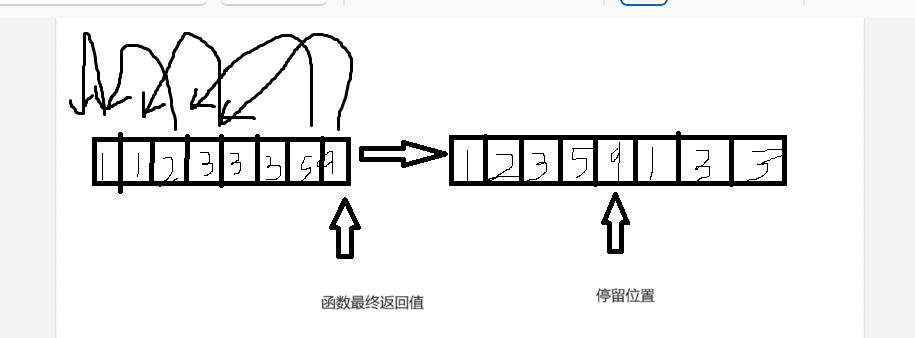
用法:
指针法:unique(数组初始位置指针,数组结束位置指针)
迭代器法:unique(迭代器初始位置,迭代器结束位置)
示例代码:
#include<iostream>
#include<vector>
#include<algorithm>
using namespace std;
int main()
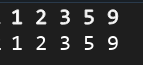
{vector<int>arr1{1,1,2,3,3,3,5,9};int arr2[8]={1,1,2,3,3,3,5,9};unique(arr1.begin(),arr1.end());unique(arr2,arr2+8);return 0;
}这个函数似乎只起到了移动元素的作用,数组内部其实还是有重复元素的,这样看起来是不是有点自欺欺人呢?在这里博主提供两种真正实现去重的方法,一种针对迭代器法,一种针对指针法。
真正实现去重的方法:
1.迭代器可以用erase辅助,erase是vector类型的函数,后续讲到向量会细讲,它起到的作用是删除
核心代码:
arr1.erase(unique(arr1.begin(),arr1.end()),arr1.end());2.新开一个数组存储去重后的原数组,因为数组没有erase这样的利器,所以只能用这种笨办法
两种方法的代码实例及运行结果:
#include<iostream>
#include<vector>
#include<algorithm>
using namespace std;
int main()
{vector<int>arr1{1,1,2,3,3,3,5,9};int arr2[8]={1,1,2,3,3,3,5,9};arr1.erase(unique(arr1.begin(),arr1.end()),arr1.end());int *index=unique(arr2,arr2+8);int newArr2[8];int num=0;for(int *i=arr2;i!=index;i++){newArr2[num]=*i;num++;}for(auto num:arr1){cout<<num<<" ";}cout<<endl;for(int i=0;i<num;i++){cout<<newArr2[i]<<" ";}return 0;
} 
(2)排序
这个函数的名字叫sort,也需要包含引用头文件<algorithm>
实现原理:不同编译器有不同的实现方法,最常见的是内省排序:结合快速排序、堆排序、插入排序,在不同情况下会自己判断使用哪种方法,平均时间复杂度很接近O(nlogn)
函数没有返回值
适用范围:只要是规定了比较符号的提供随机访问迭代器的序列都可以使用,最重要的限制是随机访问迭代器。随机访问迭代器是指可以随时任意地访问到迭代器中的任何一个元素的迭代器
用法:sort(迭代器初始位置,迭代器结束位置,指定的排序规则(默认从小到大)),指针类似
示例代码及结果:
#include<iostream>
#include<algorithm>
using namespace std;
int main()
{int arr[10]={1,4,3,2,5,7,9,8,6,10};sort(arr,arr+10);for(int i=0;i<10;i++){cout<<arr[i]<<" ";}return 0;
} ![]()
设定规则:
1.一个比较简单的就是从默认由小到大变到由大到小,只需要在最后加一个greater<int>()
2.还有一种更随心所欲的,它需要重载”<"符号,或者是自定义一个比较符号
代码举例:
bool compare(int a, int b)
{return a > b;
}
vector<int> numbers = {5, 2, 8, 1, 9};
sort(numbers.begin(), numbers.end(), compare);(3)查找
这两个函数叫做lower_bound、upper_bound,也需要包含引用头文件<algorithm>,它要处理的同样是排好序的序列,而且需要是升序
实现原理:二分查找
函数的返回值:它们的返回值都是迭代器位置,捕获方法也是指针或auto类型,如果没有找到的话就返回结束迭代器
作用:
lower_bound返回第一个大于等于指定值的元素的位置
upper_bound返回第一个大于指定值的元素的位置
适用范围:支持随机访问迭代器的序列,可以自定义比较函数
用法:
捕获变量 = lower_bound(迭代器初始位置,迭代器结束位置,指定值,比较函数(默认升序比较)),upper_bound一样
代码示例:
#include<iostream>
#include<algorithm>
using namespace std;
int main()
{int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };int i = lower_bound(arr, arr + 10, 5) - arr;int j = *(upper_bound(arr, arr + 10, 5));cout << "1-10中大于等于5的第一个数是" << arr[i] << endl;cout << "1-10中大于5的第一个数是" << j << endl;return 0;
}运行结果:

(4)翻转
这个函数叫做reverse,需要包含引用头文件<algorithm>,作用是翻转一个序列
作用:实现一个序列的翻转
实现原理:
利用双指针法,从序列两端向内移动,依次交换对应位置元素直到起始指针大于等于末尾指针
图解:
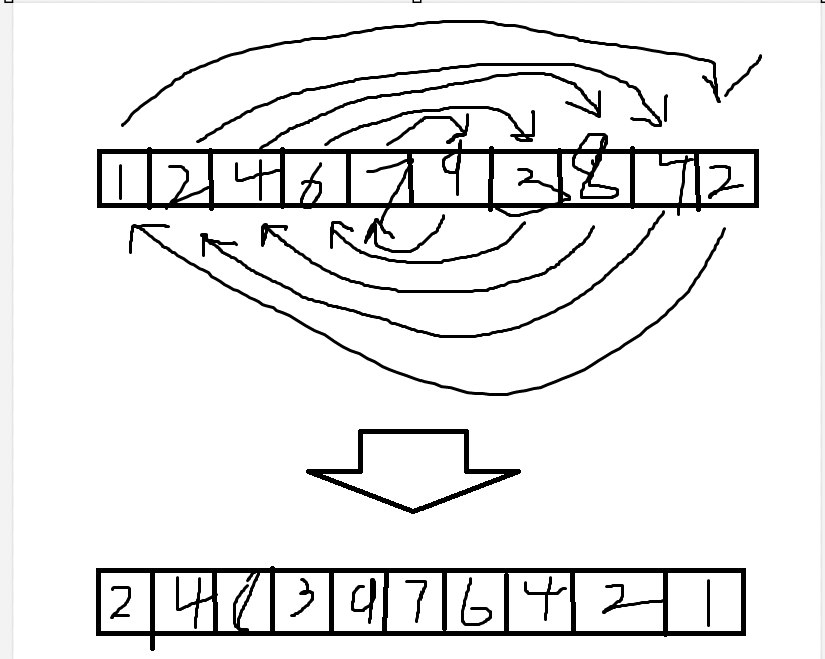
适用范围:只要是可以双向遍历的序列都可以
用法:reverse(序列初始位置,序列结束位置)
代码示例及运行结果:
#include<iostream>
#include<algorithm>
using namespace std;
int main()
{int arr[10] = { 1,2,5,4,3,2,7,6,8,9 };reverse(arr, arr + 10);for (int i = 0; i < 10; i++){cout << arr[i] << " ";}return 0;
}
(5)交换
这个函数叫做swap,需要包含引用头文件 <utility>
实现原理:对两个单独变量的话就是设置一个临时变量,对容器类交换有些复杂,不同容器有不同的交换方式,思路就是交换指针和数据类型这些数据,而不是直接交换元素,C++11版本以后是用移动语义直接转移对象资源
适用范围:并非只能交换变量,可以说是概念神了,单个变量、数组、容器类、自定义数据类型都可以交换,但是数组要交换的话只能一个元素一个元素交换
用法:swap(第一个要交换的对象,第二个要交换的对象)
代码示例及运行结果:
#include<iostream>
#include<utility>
#include<vector>
using namespace std;
int main()
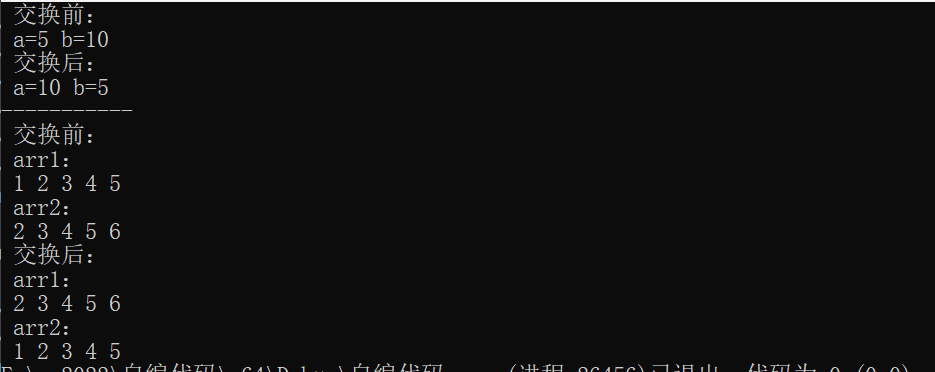
{int a = 5, b = 10;cout << "交换前:" << endl;cout << "a=" << a << " " << "b=" << b << endl;swap(a, b);cout << "交换后:" << endl;cout << "a=" << a << " " << "b=" << b << endl;cout << "---------" << endl;vector<int>arr1{ 1,2,3,4,5 };vector<int>arr2{ 2,3,4,5,6 };cout << "交换前:" << endl;cout << "arr1:" << endl;for (int num : arr1){cout << num << " ";}cout << endl;cout << "arr2:" << endl;for (int num : arr2){cout << num << " ";}cout << endl;swap(arr1, arr2);cout << "交换后:" << endl;cout << "arr1:" << endl;for (int num : arr1){cout << num << " ";}cout << endl;cout << "arr2:" << endl;for (int num : arr2){cout << num << " ";}
}
(6)计算元素累加和
这个函数叫做accumulate,需要包含引用头文件<numeric>
作用:计算一段序列内元素的累加和(默认),可指定计算方法
实现原理:遍历元素,再对每个元素计算
返回值是与传入的初始值有相同数据类型的数据
适用范围:只要是能实现迭代器功能的序列都可以使用,序列元素要求可以实现传入的计算方法(默认是加法)
用法:accumulate(序列起始迭代器,序列结束迭代器,初始值,计算方法(不写默认加法))
代码示例及运行结果:
#include<iostream>
#include<vector>
#include<numeric>
using namespace std;
int function(int a, int b)
{return a * b;
}
int main()
{vector<int>arr1{ 1,2,3,4,5,6,7,8,9,10 };int num1 = accumulate(arr1.begin(), arr1.end(), 0);cout << "1-10累加的结果为:" << num1 << endl;int num2 = accumulate(arr1.begin(), arr1.end(), 1, function);cout << "1-10累乘的结果为:" << num2 << endl;return 0;
}
(7)计算内积
这个函数叫做inner_product,需要包含引用头文件<numeric>,针对的是两段序列,第二段序列长度要大于等于第一段
实现原理:遍历第一段序列,第二段序列跟着走,直到第一段被遍历结束,期间每对元素都按指定方法计算
作用:对两段序列的元素成对处理,默认是先让两段序列中的对应元素相乘,再相加,返回值是最终的结果,数据类型和传进去的初始值参数一致
适用范围:只要是能实现迭代器功能的序列都可以,序列元素的数据类型要求能满足传进去的计算方法
用法:inner_product(一号序列初始迭代器,一号序列结束迭代器,二号序列初始迭代器,初始值,每对元素计算后的处理方法(默认加法),每对元素的处理方法(默认乘法))
代码示例及运行结果:
#include<iostream>
#include<numeric>
using namespace std;
typedef long long ll;
ll add(ll a, ll b)
{return a + b;
}
ll multiple(ll a, ll b)
{return a * b;
}
int main()
{ll arr1[10] = { 1,2,3,4,5,6,7,8,9,10 };ll arr2[10] = { 1,2,3,4,5,6,7,8,9,10 };int num1 = inner_product(arr1, arr1 + 10, arr2, 0);cout << "1*1+2*2+……+10*10的结果为:" << num1 << endl;ll num2 = inner_product(arr1, arr1 + 10, arr2, ll(1), multiple, add);cout << "(1+1)*(2+2)*……*(10+10)的结果为:" << num2 << endl;return 0;
}
(8)求并集
这个函数叫做set_union,需要包含引用头文件<algorithm>,针对两段已排序序列
实现原理:和归并类似,但是相同元素只会处理一次。按照预先规定好的排序方法遍历,然后把不重复元素存进另一个序列中。所以这个存储序列一定要足够长
用法:set_union(一号序列初始迭代器,一号序列结束迭代器,二号序列初始迭代器,二号序列结束迭代器,新的存储序列的初始迭代器,两段序列的排序方式(默认升序))
返回值:存储序列的最后一个元素的下一个位置的迭代器
适用范围:支持迭代器的序列,可以进行比较的数据类型(自定义比较方式也可以)
代码示例及其运行结果:
#include<iostream>
#include<algorithm>
using namespace std;
int newArr[10];
int main()
{int arr1[5] = { 1,2,3,4,5 };int arr2[5] = { 4,5,6,7,8 };int* i = set_union(arr1, arr1 + 5, arr2, arr2 + 5, newArr);cout << endl;cout << " {1,2,3,4,5}和{4,5,6,7,8}的并集为:";for (int* j = newArr; j != i; j++){cout << *j << " ";}return 0;
}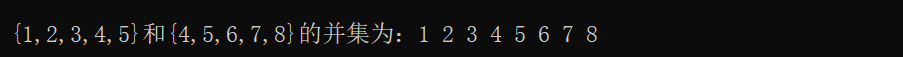
(9)求差集
这个函数叫做set_difference,需要包含引用头文件<algorithm>,针对两段已排序序列
作用:找出属于第一段序列不属于第二端序列的元素
实现原理:遍历两个序列,比较对应元素,因为默认排序方式是升序,所以第一段序列的元素若小于第二段对应的元素,就说明第二段绝对没有这个元素,把第一段这个元素放进新数组,再往后走一位;如果第一段序列的元素大于第二段对应的元素,什么都说明不了,第二段就往后推一个,然后继续比。直到遍历完两个序列
用法:set_difference(一号序列初始迭代器,一号序列结束迭代器,二号序列初始迭代器,二号序列结束迭代器,新的存储序列的初始迭代器,两段序列的排序方式(默认升序))
返回值:存储序列的最后一个元素的下一个位置
适用范围:支持迭代器的序列,可以进行比较的数据类型(自定义比较方式也可以)
代码示例及其运行结果:
#include<iostream>
#include<algorithm>
using namespace std;
int main()
{int arr1[5] = { 1,2,3,4,5 };int arr2[5] = { 5,6,7,8,9 };int newArr[4];int* index = set_difference(arr1, arr1 + 5, arr2, arr2 + 5, newArr);cout << endl;cout << " {1,2,3,4,5}对{5,6,7,8,9}的差集为:";for (int* i = newArr; i != index; i++){cout << *i << " ";}cout << endl;
}
(10)求交集
这个函数叫做set_intersection,需要包含引用头文件<algorithm>,针对两段已排序序列
作用:找出两端序列共有元素
实现原理:遍历两段序列,比较对应元素。若是相同,就把这个元素放进新数组;若是不相同,就把小的那个元素所在序列再往后移动一位,直到遍历完两个序列
用法:set_difference(一号序列初始迭代器,一号序列结束迭代器,二号序列初始迭代器,二号序列结束迭代器,新的存储序列的初始迭代器,两段序列的排序方式(默认升序))
返回值:存储序列的最后一个元素的下一个位置
适用范围:支持迭代器的序列,可以进行比较的数据类型(自定义比较方式也可以)
代码示例及其运行结果:
#include<iostream>
#include<algorithm>
using namespace std;
int main()
{int arr1[5] = { 1,2,3,4,5 };int arr2[5] = { 3,4,5,6,7 };int newArr[3];int* index = set_intersection(arr1, arr1 + 5, arr2, arr2 + 5, newArr);cout << endl;cout << " {1,2,3,4,5}和{3,4,5,6,7}的交集为:";for (int* i = newArr; i != index; i++){cout << *i << " ";}cout << endl;
}
(11)位运算
这个操作算是STL中比较特殊的,因为它有自己的一套体系。
先来介绍几个C++本来就有的位运算符:
1. ~ 按位取反 ,针对一个数字的运算符,作用是把这个数的二进制形式中的每一位都取反,即0变1,1变0。实际应用是求对应负数的二进制
2.&按位与,针对两个数字的运算符,作用是判断这两个数的二进制形式中的每一对对应的位上的数是不是同时为1,若是则这位是1,若不是则这位是0。实际应用是判断特定位上的数字是0还是1
3.|按位或,针对两个数字的运算符,作用是判断这两个数的二进制形式中的每一对对应的位上的数是不是至少有一个为1,若是则这位是1,若不是则这位是0。实际应用是把特定位的数字变成1
4.^按位异或,针对两个数字的运算符,作用是判断这两个数的二进制形式中的每一对对应的位上的数是否相同,若相同则这位是0,否则为1.实际应用是不使用临时变量交换两个数、找出数组中唯一不重复的元素、切换特定位
5.<<左移 >>右移,针对一个数字的运算符,作用是将一个数的二进制形式向左或向右移动n位。实际应用是让一个数乘2的幂,移动几位就乘几次幂;或者让一个数除以2的幂,移动几位就除以几次幂,最后向下取整
这些运算符很基础很常规,一定要记牢
然后再讲一下STL库里的东西,之所以把它放在这里,就是因为它兼有功能函数和数据结构的形式
这个类叫做bitset,需要包含引用头文件<bitset>,它的作用是对固定长度的二进制序列进行高效处理
声明方式:bitset<长度>名字,默认所有位都是0
初始化方式:
1. 用数字初始化,bitset<长度>名字(数字),这样的话bitset就变成了括号里的数字对应的二进制形式
2.用字符串初始化,string 字符串名="1010(类似这种类型的字符串)";bitset<长度>名字(字符串名),不足的位会补0
常用操作:
1.对象名.count(),返回值是二进制串中1的个数
2.对象名.any(),判断是否至少有一个1
3.对象名.none(),判断是否全为0
4.对象名.set(),将所有位置换成1
5.对象名.set(k,v)将第k位变成v
6.对象名.reset()将所有位变成0
7.对象名.flip()按位取反
8.对象名.flip(k)把第k位取反
数据结构详解
(1)字符串
这个容器叫string,需要包含引用头文件<string>,它是一个非常好用的字符串,比普通的字符数组要方便、安全很多
初始化方式:四种,直接空字符串、用字符串初始化、用另一个string初始化、用指定数量的相同字符初始化
1.声明一个空的字符串:string 字符串名;
2.使用字符串初始化:string 字符串名 = "字符串";
3.使用另一个string对象初始化:string 新字符串(旧字符串);
4.使用指定数量的相同字符初始化:string 字符串名(个数, '字符');
基本操作:拼接、比较、返回长度、访问字符、插入、删除、替换、查找、判断是否为空、清空、提取子字符串
1.拼接:使用+、+=符号就可以实现拼接,非常的方便
2.比较:==、!=、<、>、<=、>=这些C++的比较符都可以用。比较规则也是字典序,即按位依次比对应的ASCII码值,值大的就判大,一样大就比较下一位
3.返回长度:对象名.size()、对象名.length()
4.访问某个字符:对象名[下标]、对象名.at(下标)
5.访问首尾字符:对象名.front()、对象名.back()
6.插入字符:对象名.insert(要插入位置前的下标,"字符串");
7.删除字符串:对象名.erase(要开始删除的起始下标,要删除的字符的个数);
8.替换字符串:对象名.replace(要开始替换的起始下标,要替换的个数,"要替换成的字符串");
9.查找字符:
从前往后查:size_t find = 对象名.find(要查找的字符,开始查找的位置(默认为开始))返回值是首次出现的位置,若未找到返回string::npos
从后往前查:size_t rfind = 对象名.rfind(要查找的字符,开始查找的位置(默认为末尾))返回值是最后一次出现的位置,若未找到返回string::npos
10.查找字符串:
从前往后查:size_t find = 对象名.find(要查找的字符串,开始查找的位置(默认为开始))返回值是首次出现的起始位置,未找到返回string::npos
从后往前查:size_t rfind = 对象名.rfind(要查找的字符串,开始查找的位置(默认为末尾))返回值是最后一次出现的起始位置,未找到返回string::npos
11.判断是否为空:对象名.empty()返回值是true或false
12.清空:对象名.clear()
13.提取子字符串:对象名.substr(子字符串初始下标,子字符串结束下标)
代码示例及运行结果:
#include<iostream>
#include<string>
using namespace std;
int main()
{//初始化测试string test1; //声明空字符串string test2 = "我是你爸爸"; //声明存在的字符串string test3(test2); //复制已有字符串string test4(10, 'a'); //初始化一个连续相同字母的字符串//字符串拼接测试test1 = test2 + test3 + test4;cout << "test1:" << test1 << endl;test2 += test3;cout << "test2:" << test2 << endl;//字符串比较测试if (test1 < test2){cout << "test1赢了" << endl;}else{cout << "test2赢了" << endl;}//字符串长度计算测试int size = test1.size();cout << "test1的元素个数是" << size << endl;//用下标访问元素测试cout << test4[0] << endl;//字符串插入操作测试test2.insert(3, "我爱你");cout << test2 << endl;//字符串删除操作测试test2.erase(3, 10);cout << test2 << endl;//字符串替换操作测试test2.replace(3, 5, "abcde");cout << test2 << endl;//字符串查找操作测试size_t isize = test2.find("xyaz");cout << "是你爸爸首次出现在" << size << endl;return 0;
}

注意:为什么这里会有乱码呢?因为string的本质上还是以char为单位的,一个字节一个字节操作,而汉字是三或四个字节,所以会出现这种乱码。如果要用汉字最好还是用宽字符,但是这个不在这篇博客的讨论范围
(2)二元组
这个容器叫做pair,需要包含引用头文件<utility> 这个东西的作用是把两个对象建立起联系
初始化方式:pair<第一个数据类型,第二个数据类型> 对象名(数据1,数据2)
访问方式:对象名.first是第一个元素,对象名.second是第二个元素
代码示例及运行结构
#include<iostream>
#include<utility>
using namespace std;
int main()
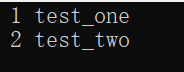
{pair<int, string> arr1(1, "test_one");pair<int, string> arr2(2, "test_two");cout << arr1.first << " " << arr1.second << endl;cout << arr2.first << " " << arr2.second << endl;return 0;
}
(3)向量
这个容器叫做vector,需要包含引用头文件<vector>这个东西本质上就是一个动态数组
因为常规数组长度是固定的,不灵活还有越界危险,所以就出现了vector这个好东西
初始化方式:五种。声明空容器、声明长度确定值默认为0的容器、声明长度确定值全为指定的容器、使用初始化列表、从另一个容器复制
1.声明空容器:vector<数据类型>容器名
2.声明长度确定值默认为0的容器:vector<数据类型>容器名(长度)
3.声明长度确定值全为指定的容器:vector<数据类型>容器名(长度,默认值)
4.使用初始化列表:vector<数据类型>容器名={值列表}
5.从另一个容器复制:vector<数据类型>容器名(被复制的容器名)
基本操作:返回元素个数、返回是否为空、清空、访问首尾元素、添加删除尾元素、返回迭代器、访问内部元素、返回容器最大容量
1.返回元素个数:容器名.size()
2.返回是否为空:容器名.empty()
3.清空:容器名.clear()
4.访问首尾元素:容器名.front()、容器名.back()
5.添加删除尾元素:容器名.push_back()、容器名.pop_back()
6.返回迭代器:容器名.begin()、容器名.end()
7.访问内部元素:容器名[下标]
8.返回容器最大容量:容器名.capacity()
代码示例及运行结果:
#include<iostream>
#include<vector>
using namespace std;
int main()
{//初始化测试vector<int>test1; //声明一个空容器vector<int>test2(3); //声明一个长度为3,元素值都为0的容器vector<int>test3(3, 5); //声明一个长度为3,元素值都为5的容器vector<int>test4{ 1,2,3,4,5 }; //声明一个长度为5,元素值是1,2,3,4,5的容器vector<int>test5(test4); //声明一个和test4长度和元素值一样的容器//遍历方法1:for (int i = 0; i < 5; i++){cout << test5[i] << " "; //可以指定遍历个数,但是在最大值不确定时不顺利}cout << endl;//遍历方法2:for (size_t i = 0; i < test4.size(); i++){cout << test4[i] << " "; //可以动态实现从头到尾,无需知道数据的个数,但是无法指定遍历个数}cout << endl;//遍历方法3:for (auto& t : test3){cout << t << " "; //for范围遍历,与list通用}cout << endl;//遍历方法4:for (auto it = test2.begin(); it != test2.end(); it++){cout << *it << " "; //迭代器遍历,与list通用}cout << endl;//插入函数测试vector<int> newtest{ 1, 2, 3 };test1.push_back(1); //push_back函数测试test1.emplace_back(2); //emplace_back函数测试test1.insert(test1.begin() + 1, 3); //insert测试test1.emplace(test1.end() - 1, 4); //emplace插入单个元素测试test1.insert(test1.begin(), newtest.begin(), newtest.end()); //insert插入多个元素测试//预测结果:1231342for (auto& s : test1){cout << s;}cout << endl;//修改元素测试test1[0] = 100;cout << test1[0] << endl;//删除元素测试test1.pop_back();test1.erase(test1.begin());test1.erase(test1.begin(), test1.begin() + 2);for (auto it = test1.begin(); it != test1.end(); it++){cout << *it;}cout << endl;//预测结果:134//容量管理测试cout << "当前test1能容纳的元素个数是" << test1.capacity() << endl;return 0;
}

(4)队列
队列是一种先进先出的数据结构,队尾只能进元素,队头只能出元素
这个容器叫做queue,需要包含引用头文件<queue>
初始化方式:两种。声明空队列、复制另一个队列
1.声明空队列:queue<数据类型>容器名
2.复制另一个队列:queue<数据类型>容器名(被复制的容器名)
基本操作:返回元素个数、返回是否为空、向队尾插入一个元素、返回队头元素、返回队尾元素、弹出队头元素
1.返回元素个数:容器名.size()
2.返回是否为空:容器名.empty()
3.向队尾插入一个元素:容器名.push()
4.返回队头元素:容器名.front()
5.返回队尾元素:容器名.back()
6.弹出队头元素:容器名.pop()
代码示例及运行结果:
#include<iostream>//包含必要的头文件#include<queue>
using namespace std;//主函数,用于测试功能int main()
{//定义一个queue对象queue<int>test1;//测试push()函数和emplace()函数test1.push(10);test1.emplace(100);//再定义一个对象,测试复制式构造queue<int>test2(test1);//测试front()函数和back()函数cout << "test1的头元素是" << test1.front() << endl;cout << "test2的尾元素是" << test2.back() << endl;//测试pop()函数test1.pop();test1.pop();//测试size函数cout << "test2的元素的数量是" << test2.size() << endl;//测试emoty()函数if (test1.empty()){cout << "test1是空的" << endl;}else{cout << "test1不是空的" << endl;}//测试swap()函数test1.swap(test2);if (test2.empty()){cout << "test2和test1互换了元素" << endl;}else{cout << "test1和test2没有互换元素" << endl;}cout << "test1的头元素为" << test1.front() << endl;return 0;
}

(5)栈
栈是一种先进后出的数据结构,元素只能从栈顶出来进去
这个容器叫做stack,需要包含引用头文件<stack>
初始化方式:两种。声明空栈、指明底层容器后的空栈
1.声明空栈:stack<数据类型>容器名,底层容器默认是双端队列
2.指明底层容器:stack<数据类型,指定容器>容器名,这个底层容器是指定好的
它事实上只提供封闭一端的功能,而存储是由底层容器实现的,不同的底层容器在不同应用场景下的性能也不一样
基本操作:返回元素个数、返回是否为空、向栈顶插入一个元素、返回栈顶元素、弹出栈顶元素
1.返回元素个数:容器名.size()
2.返回是否为空:容器名.empty()
3.向栈顶插入一个元素:容器名.push()
4.返回栈顶元素:容器名.top()
5.弹出栈顶元素:容器名.pop()
代码示例及运行结果:
#include<iostream>
#include<stack>
#include<vector>//包含引用必要的头文件using namespace std;//主函数,用于测试int main()
{//声明空栈stack<int>goal1;//测试两个增加元素函数的功能goal1.push(1);goal1.emplace(2); cout << "栈顶元素为" << goal1.top() << endl;//测试出栈函数的功能goal1.pop();cout << "栈顶元素为" << goal1.top() << endl;cout << "栈的元素个数是" << goal1.size() << endl;stack<int>goal2;goal2.push(100);//测试交换函数的功能goal1.swap(goal2);cout << "goal1的栈的元素为" << goal1.top() << endl;cout << "goal2的栈的元素为" << goal2.top() << endl;return 0;
}

(6)优先队列
不同于普通队列的先进先出,它的进是随意进,出的时候会先出优先级最高的元素
那这个神奇的功能是怎么实现的呢?
这个队列的底层容器是堆。堆是一种完全二叉树,通过某些手法可以实现每个根节点是最大或最小值,然后每次移除根节点就是优先级最高的
这里我们不细讲堆,总之它可以让最大值或最小值突出出来
这个容器叫做priority_queue,需要包含引用头文件<queue>
初始化方式:priority_queue<数据类型,底层容器,比较函数>容器名
默认是大根堆比较方式,即越大的元素优先级越高
要转为小根堆的话:priority_queue<数据类型,vector<int>,greater<int>>容器名
基本操作:插入元素、访问堆顶元素、弹出堆顶元素
1.插入元素:容器名.push(元素)
2.访问堆顶元素:容器名.top(),返回值是堆顶元素
3.弹出堆顶元素:容器名.pop()
代码示例及其运行结果:
#include<iostream>
#include<queue>
using namespace std;
int main()
{//声明以大根堆为排序方式的优先队列,会先出最大的数priority_queue<int> test1;for (int i = 1; i <= 10; i++){test1.push(i);}//声明以小根堆为排序方式的优先队列,会先出最小的数priority_queue<int, vector<int>, greater<int>>test2;for (int i = 1; i <= 10; i++){test2.push(i);}cout << " test1队列的最大值为" << test1.top() << endl;test1.pop();cout << " test1队列弹出最大值后的最大值为" << test1.top() << endl;cout << " test2队列的最小值为" << test2.top() << endl;test2.pop();cout << " test2队列弹出最小值后的最小值为" << test2.top() << endl;return 0;
}
(7)双端队列
双端队列也是一种特殊的队列,它支持两头插入删除
双端队列和刚才讲到的向量在显式功能上是一样的,即双端队列能实现的向量也能实现,向量能实现的双端队列也能实现,甚至包括通过下标访问元素也和向量一样可以实现
那它们有什么区别呢?开发者闲的没事干多此一举吗?
实则不然。双端队列与向量因为实现方式不同所以各有优势:双端队列更适合频繁在队列两头插入删除的场景,而向量更适合大量随机访问容器内的元素
说的简单一点就是:[]、at()访问元素时向量更厉害;push()、pop()的时候双端队列更厉害
这个容器叫做deque,需要包含引用头文件<deque>
初始化和基本操作:与vector都一样
代码示例及其运行结果:
#include<iostream>//定义必要的头文件#include<deque>
using namespace std;//主函数,用于测试功能int main()
{//测试各种初始化方式deque<int>test1; //生成一个空队列deque<int>test2(10); //生成一个长度为10,元素值都是0的队列deque<int>test3(10, 1); //生成一个长度为10,元素值都是1的队列deque<int>test4 = { 1,2,3,4,5 }; //生成一个元素值为1,2,3,4,5的队列deque<int>test5(test4); //把test4复制给test5//测试empty()函数if (test1.empty()){cout << "测试:test1构造成功" << endl;}else{cout << "test1构造失败" << endl;}//测试size()函数和for范围遍历cout << "测试:test2的元素有" << test2.size() << "个" << endl;cout << "测试:test3的元素为:";for (auto& t : test3){cout << t << " ";}cout << endl;//测试迭代器遍历cout << "测试:test4的元素为:";for (auto it = test4.begin(); it != test4.end(); it++){cout << *it << " ";}cout << endl;test1.push_back(10);cout << "测试:test1的首元素是" << test1[0] << endl; //测试push_back()函数test1.push_front(1);cout << "测试:test1的首元素是" << test1[0] << endl; //测试push_front()函数test1.insert(test1.begin(), 3);cout << "测试:test1的首元素是" << test1[0] << endl; //测试insert插入cout << "测试:test2的首元素是" << test2.front() << endl; test4.pop_back(); //测试pop_back()函数cout << "测试:test4的尾元素是" << test4.back() << endl;return 0;
}
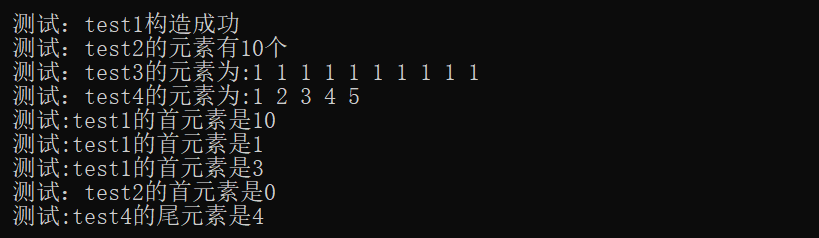
(8)映射
先讲一下映射是个什么东西:映射是一种关联容器,用于存储键值对,那键值对又是什么?键值对可以直接理解为pair,即刚才讲到的二元组,pair的first就是键,pair的second就是值。每个键是唯一的,可以通过键来查找对应的值。
底层容器分为两种,这两种容器的区别造就了两种映射:基于红黑树的映射叫有序映射,简称映射;基于哈希表的映射叫无序映射,这个小节讲有序映射,下个小节讲无序映射和它们的区别
用一种通俗方式来理解映射:映射就是pair的集合,只不过pair的first不能重复
这小节讲的是映射,叫做map,需要包含引用头文件<map>,底层实现是红黑树,红黑树是一种自平衡的二叉搜索树,我们这里不讲它,只需要知道这个数据类型可以自己控制自己,让自己一直维持搜索的高效性
初始化方式:三种简单常用的。初始化空容器、初始化列表、复制其他容器
1.初始化空容器:map<第一个数据类型,第二个数据类型>容器名
2.初始化列表:map<第一个数据类型,第二个数据类型>容器名 ={{键,值},……}
3.复制其他容器map<第一个数据类型,第二个数据类型>容器名(被复制的容器名)
基本操作:访问元素、插入元素、删除元素、查找元素、遍历、返回元素个数、返回是否为空、清空、返回边界迭代器、返回当前指向元素的前驱和后继
1.访问元素:容器名[键]返回值是对应的值,如果键不存在将插入默认值0;容器名.at(键)返回值是对应的值,如果键不存在不会插入默认值而是会抛出异常;迭代器访问,这个就不多说了
2.插入元素:容器名.insert({键,值});容器名.emplace(键,值),这个不需要关注下标因为它会自动排好序,如果键是重复的它会自动去重,把上一个取代掉
3.删除元素:容器名.erase(键)
4.查找元素:容器名.find(键)
5.遍历:迭代器遍历、范围循环
6.返回元素个数:容器名.size()
7.返回是否为空:容器名.empty()
8.清空:容器名.clear()
9.返回边界迭代器:容器名.begin()、容器名.end()
10.返回当前指向元素的前驱和后继:先解释一下前驱和后继是什么意思,前驱指的是当前键的上一个元素,后继指的是当前键的下一个元素,因为红黑树自动排序,所以可以这样移动迭代器
迭代器++、迭代器--,返回值是前驱和后继的迭代器
代码示例及其运行结果:
#include<iostream>
#include<map>
using namespace std;
int main()
{map<string, int>ages1 = { {"user1",14},{"user2",15},{"user3",16} };map<string, int>ages2;map<string, int>ages3(ages1);cout << endl;cout << " ages1中user1的年龄为" << ages1.at("user1") << endl;cout << " ages1中user2的年龄为" << ages1["user2"] << endl;ages2.emplace("user1", 24);ages2.insert({ "user2" ,25 });cout << " ages2中user1的年龄为" << ages2.at("user1") << endl;ages3.erase("user1");cout << " ages3还有" << ages3.size() << "个用户" << endl;cout << " ages1的第一个用户是" << ages1.begin()->first << endl;cout << " ages1的最后一个用户是" << (--ages1.end())->first << endl;cout << " ages2的第二个用户是" << (++ages2.begin())->first << endl;return 0;
}
这里有一个关键的问题,是博主第一次测试时出现的:end()这个迭代器返回的是结束迭代器,这个迭代器不指向任何元素,而是最后一个元素的下一个位置
(9)无序映射
这小节讲无序映射和它与有序映射的区别
这个容器叫做unordered_map,需要包含引用头文件<undered_map>。它的底层实现是哈希表,那哈希表是什么呢?我们这里也是不细讲,只需要知道它是一个可以让大范围数据缩小成小范围数据的数据结构就可以了。
初始化方式:unordered_map(第一个元素,第二个元素,哈希函数(默认已经给出了一个不错的哈希函数),键相等比较函数(这个是用于解决哈希冲突的,默认也给出了一个不错的函数))容器名,其余和map一样
基本操作:和map类似,它有的map都有,但是它是无序的,所以和范围有关的它都不能实现
这样看来,map完全可以吊打unordered_map,实则不然。当牺牲了一些东西的时候,一定在另一个方面有突出效果
无序映射查找、删除元素的平均时间复杂度是O(1),最坏复杂度是O(n),而有序映射的时间复杂度是O(logn),放在相当大的数据集中且操作频繁的情况下,运行速度的差距可想而知
所以在不关注元素顺序时用无序映射可以大幅度提高效率,需要考虑元素顺序时只能用映射了
(10)多重映射
这个映射与有序映射和无序映射的区别是:它的键不是唯一的。当然它也根据底层容器的不同分成了有序多重映射和无序多重映射。
再借助pair理解一下:多重映射也是pair的集合,只不过这个集合允许pair的first有重复
有序多重映射叫做multimap,需要包含引用头文件<multimap>
无序多重映射叫做unordered_multimap,需要包含引用头文件<unordered_multimap>
初始化:和普通映射一样,只是键可以重复
基本操作:插入、查找、删除
1.插入:容器名.insert({键,值}),键可以重复
2.查找:容器名.find(键)返回第一个匹配键的迭代器,不存在返回end();
容器名.count(键)返回该键出现的次数
容器名.equal_range(键)返回一个二元组包含匹配键的元素范围
3.删除:容器名.erase(键),删除所有匹配键的元素,返回删除元素的个数
那这个东西有什么用呢?其实它的用处很多
在一对多的情况下就要用到它了,一个事件对应的相关者 这就是一对多;还有本来就有重复的,一篇作文中一个单词的出现位置
(11)集合
通俗解释一下它就是一个可以自动去重自动排序的数组,但是性能上要好很多,对应的限制也有很多
它也是根据底层实现的不同分为有序集合和无序集合
本小节讲一下有序集合,下一节讲无序集合及其区别
这个容器叫做set,底层实现也是红黑树
初始化:与映射相同
基本操作:插入元素、查找元素、删除元素、统计元素、返回比较后的迭代器
1.插入元素:容器名.insert(元素)如果是重复的会忽略
2.查找元素:容器名.find(元素)找到返回迭代器,没找到返回end()
3.删除元素:容器名.erase(元素)删除指定元素,返回删除的个数
4.统计元素:容器名.count(元素)返回元素个数
5.返回比较后的迭代器:容器名.lower_bound(元素)返回大于等于指定元素的最小的数的迭代器
容器名.upper_bound(元素)返回大于指定元素的最小的数的迭代器
(12)无序集合
这小节讲无序集合和它与有序集合的区别
这个容器叫做unordered_set,需要包含引用头文件<undered_set>。它的底层实现是哈希表
初始化:与映射相同
基本操作:与set类似,但是同理和范围、顺序有关系的他都不能实现
它与set的区别及各自应用场景:
同样,它也是牺牲顺序得到极致的效率,所以在不需要考虑顺序的时候用它就对了
(13)多重集合
它和普通集合的区别就是它允许元素重复
好了,写到这里,你们有没有感觉很奇怪?允许重复了,它和vecotr有啥区别,不是更像个数组了?实则不然,它在计数、排序、范围查询等地方的效率比vector高了不少。
初始化和基本操作都和普通集合差不多,就不附了。
篇末总结
本篇博客写完用了博主一周的时间,因为我要干的事情比较多,时间也比较碎,还要最重要的是博主也是边学边写的。写完这篇博客博主也有很多感慨,对数据结构和算法也有了更多的理解
每一个数据结构都是开发者团队深思熟虑很久之后才推出的,不可能存在没用的数据结构。其实,所有的数据结构都可以解决问题,它们之间的区别只是效率和适不适合的问题。向量论排序、查找什么的被集合打爆了,但是它可以通过下标直接找到某个元素,这是集合做不到的事情。map可以存多个pair,但是理解和实现起来又比pair复杂得多,pair轻量化的情况下不是更好?只有最难理解和最难实现的数据结构,但是没有最好的数据结构。红黑树难理解吧?他也有实现起来很困难的需求。
人同样如此,天生我材必有用,可能我们在这个方面做的不好,在其他方面却远远超出其他人。没有最好的人,只有在某个领域里优秀的人。
除去这部分人生感悟,博主对迭代器也有了更深的理解,这个类似指针的东西实在是好用,它可以指向容器中的某个位置。
还有开发者开发的库函数,其实你可以看到,这些数据结构的初始化、操作很多东西都是相同的,在基于同一个类型的迭代器的情况下更是一样了。
程序员要学好英语,这么多库函数都可以直接见名知义,如果学好英语在编程上一定是大有帮助的
很高兴能帮助到其他正在学习STL的同行。