数据中台-数据实施服务常用工具组件-(续)
除了上篇文章提到的工具(DataX、Flink、DolphinScheduler、TensorFlow、PyTorch),数据中台-常用工具组件:DataX、Flink、Dolphin Scheduler、TensorFlow和PyTorch等-CSDN博客
数据中台的实施服务工具链还包含其他重要组件。以下是补充的常用工具,覆盖数据全生命周期管理(采集、存储、处理、治理、分析、可视化等):

补充工具分类及说明
1. 数据采集与同步
| 工具 | 类型 | 核心功能 | 典型场景 |
|---|---|---|---|
| Sqoop | 离线数据迁移 | 关系型数据库(如MySQL)与Hadoop间批量传输 | 传统数仓数据迁移到HDFS/Hive |
| Logstash | 日志收集 | 实时采集、解析、转发日志数据 | 日志标准化后写入Elasticsearch |
| Debezium | 变更数据捕获(CDC) | 捕获数据库的增量变更(如MySQL Binlog) | 实时同步数据库变更到Kafka |
2. 数据存储与管理
| 工具 | 类型 | 核心功能 | 典型场景 |
|---|---|---|---|
| Apache Iceberg | 数据湖表格式 | 支持ACID事务、Schema演进的大规模数据管理 | 替代Hive表,提升数据湖查询性能 |
| MinIO | 对象存储 | S3兼容的高性能分布式对象存储 | 存储非结构化数据(图片、视频) |
| Apache Hudi | 数据湖引擎 | 增量更新、删除,支持近实时数据湖 | 实时数仓、CDC数据合并 |
3. 数据处理与计算
| 工具 | 类型 | 核心功能 | 典型场景 |
|---|---|---|---|
| Apache Spark | 批流一体计算 | 大规模ETL、机器学习(MLlib)、图计算 | 复杂批处理任务、DWD层清洗 |
| Trino (Presto SQL) | 分布式查询引擎 | 多数据源联邦查询(如Hive、MySQL、Kafka) | 交互式OLAP分析 |
| dbt (Data Build Tool) | 数据建模工具 | 基于SQL的声明式数据转换与文档生成 | 数据仓库建模、数据血缘管理 |
4. 任务调度与编排
| 工具 | 类型 | 核心功能 | 典型场景 |
|---|---|---|---|
| Apache Airflow | 工作流调度 | 基于DAG的任务编排、任务监控与重试机制 | 复杂ETL任务依赖管理 |
| Kubernetes CronJob | 容器化定时任务 | 在K8s集群中运行定时任务 | 容器化环境下的轻量级调度 |
5. 数据治理与质量
| 工具 | 类型 | 核心功能 | 典型场景 |
|---|---|---|---|
| Apache Atlas | 元数据管理 | 数据血缘追踪、元数据搜索与分类 | 数据资产目录、合规审计 |
| Great Expectations | 数据质量监控 | 自动化数据校验(如空值检测、分布验证) | 数据入湖前的质量关卡 |
| Apache Ranger | 数据安全治理 | 统一权限控制(表/列级权限)、审计日志 | 敏感数据脱敏、访问控制 |
6. 数据可视化与BI
| 工具 | 类型 | 核心功能 | 典型场景 |
|---|---|---|---|
| Apache Superset | BI工具 | 自助式数据探索、Dashboard构建 | 内部数据可视化报表 |
| Tableau | 商业BI平台 | 拖拽式交互分析、企业级数据故事 | 高管决策支持、客户报告 |
| Grafana | 监控可视化 | 实时指标监控、告警与日志联动 | 运维监控大屏、业务实时状态展示 |
7. 机器学习与AI工程
| 工具 | 类型 | 核心功能 | 典型场景 |
|---|---|---|---|
| MLflow | 机器学习生命周期 | 实验跟踪、模型注册与部署 | 管理从开发到生产的模型流水线 |
| Kubeflow | AI平台 | 基于K8s的分布式训练与推理服务 | 大规模深度学习训练任务编排 |
| Hugging Face | NLP模型库 | 预训练模型库(如BERT、GPT)与Pipeline工具 | 快速构建文本分类、翻译模型 |
8. 消息队列与流处理
| 工具 | 类型 | 核心功能 | 典型场景 |
|---|---|---|---|
| Apache Kafka | 分布式消息队列 | 高吞吐量实时数据管道、事件流存储 | 流处理数据源(如Flink消费Kafka) |
| Apache Pulsar | 云原生消息队列 | 多租户、分层存储、低延迟 | 混合云环境下的实时消息总线 |
工具链整合全景图
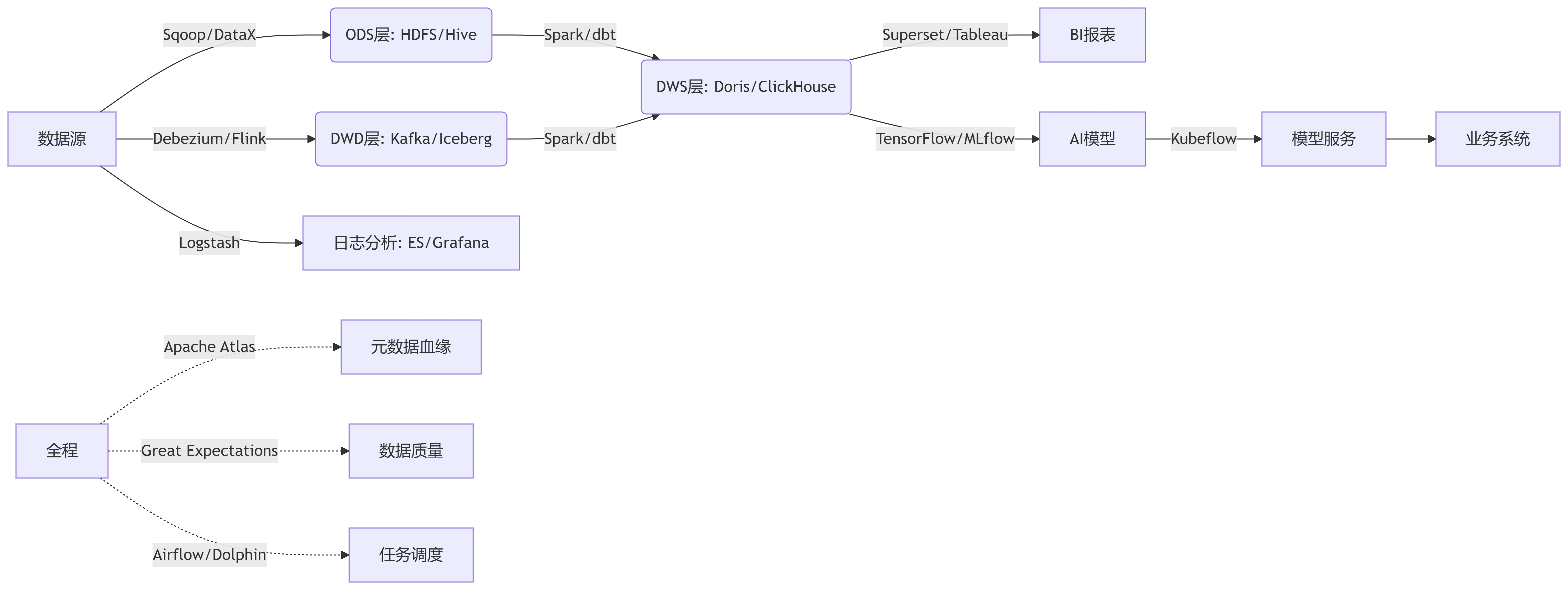
总结
数据中台的建设需要覆盖 “采、存、算、管、用” 全流程,除了核心工具(如Flink、DataX),还需结合:
-
数据治理工具(Atlas、Ranger)保障数据可信;
-
数据湖技术(Iceberg、Hudi)支持灵活分析;
-
BI与AI工具(Superset、MLflow)实现数据价值落地;
-
云原生技术(K8s、Pulsar)提升扩展性与弹性。
根据业务场景(实时性要求、数据规模、团队技术栈)选择合适的工具组合,避免过度复杂化。