Milvus(17):向量索引、FLAT、IVF_FLAT
1 索引向量字段
利用存储在索引文件中的元数据,Milvus 以专门的结构组织数据,便于在搜索或查询过程中快速检索所需的信息。
Milvus 提供多种索引类型和指标,可对字段值进行排序,以实现高效的相似性搜索。下表列出了不同向量字段类型所支持的索引类型和度量。目前,Milvus 支持各种类型的向量数据,包括浮点嵌入(通常称为浮点向量或密集向量)、二进制嵌入(也称为二进制向量)和稀疏嵌入(也称为稀疏向量)。
浮点嵌入:
| 度量类型 | 索引类型 |
|---|---|
|
|
二进制嵌入:
| 度量类型 | 索引类型 |
|---|---|
|
|
稀疏嵌入:
| 度量类型 | 索引类型 |
|---|---|
| IP | 稀疏反转索引 |
| BM25 | 稀疏_反转索引 |
1.1 准备工作
正如管理 Collections 中所解释的,如果在创建 Collections 请求中指定了以下任一条件,Milvus 会在创建 Collections 时自动生成索引并将其加载到内存中:
- 向量场的维度和度量类型,或
- Schema 和索引参数。
下面的代码片段对现有代码进行了重新利用,以建立与 Milvus 实例的连接,并在不指定其索引参数的情况下创建 Collections。在这种情况下,Collection 缺乏索引并保持未加载状态。
from pymilvus import MilvusClient, DataType# 1. 设置一个Milvus客户端
client = MilvusClient(uri="http://localhost:19530"
)# 2.1. 向数据库添加一个新模式
schema = MilvusClient.create_schema(auto_id=False,enable_dynamic_field=True,
)# 2.2. 向模式添加字段
schema.add_field(field_name="id", datatype=DataType.INT64, is_primary=True)
schema.add_field(field_name="vector", datatype=DataType.FLOAT_VECTOR, dim=5)# 3. 创建新集合
client.create_collection(collection_name="customized_setup", schema=schema,
)1.2 索引一个 Collection
要为一个 Collection 创建索引或为一个 Collection 建立索引,可使用 prepare_index_params() 准备索引参数,并使用 create_index() 来创建索引。
# 4.1. 设置索引参数
index_params = MilvusClient.prepare_index_params()# 4.2. 在矢量域上添加一个索引
index_params.add_index(field_name="vector",metric_type="COSINE",index_type="IVF_FLAT",index_name="vector_index",params={ "nlist": 128 }
)# 4.3. 创建索引文件
client.create_index(collection_name="customized_setup",index_params=index_params,sync=False # 是否等待索引创建完成后再返回。默认为True。
)| 参数 | 参数 |
|---|---|
field_name | 应用此对象的目标文件名称。 |
metric_type | 用于衡量向量间相似性的算法。可能的值有IP、L2、COSINE、JACCARD、HAMMING。只有当指定字段是向量字段时才可用。 |
index_type | 用于在特定字段中排列数据的算法名称。 |
index_name | 应用此对象后生成的索引文件名称。 |
params | 指定索引类型的微调参数。 |
collection_name | 现有 Collections 的名称。 |
index_params | 包含IndexParam对象列表的IndexParams对象。 |
sync | 控制与客户端请求相关的索引构建方式。有效值:
|
1.3 检查索引详细信息
创建索引后,可以检查其详细信息。要检查索引详细信息,请使用 list_indexes() 列出索引名称,并用 describe_index() 获取索引详细信息。
res = client.list_indexes(collection_name="customized_setup"
)print(res)# Output
#
# [
# "vector_index",
# ]res = client.describe_index(collection_name="customized_setup",index_name="vector_index"
)print(res)# Output
#
# {
# "index_type": ,
# "metric_type": "COSINE",
# "field_name": "vector",
# "index_name": "vector_index"
# }您可以检查在特定字段上创建的索引文件,并收集使用该索引文件索引的行数统计。
1.4 删除索引
如果不再需要索引,可以直接将其删除。
client.drop_index(collection_name="customized_setup",index_name="vector_index"
)2 FLAT
FLAT索引是最简单、最直接的浮点向量索引和搜索方法之一。它依赖于一种 "蛮力 "方法,即直接将每个查询向量与数据集中的每个向量进行比较,而无需任何高级预处理或数据结构。这种方法保证了准确性,由于对每个潜在匹配都进行了评估,因此可提供 100% 的召回率。
不过,这种穷举式搜索方法也有代价。FLAT 索引是最慢的索引选项,因为每次查询都要对数据集进行一次全面扫描。因此,它并不适合海量数据集的环境,因为在这种环境中,性能是个问题。FLAT 索引的主要优点是简单可靠,因为它不需要训练或复杂的参数配置。
2.1 建立索引
要在 Milvus 中的向量场上建立FLAT 索引,请使用add_index() 方法,为索引指定index_type 和metric_type 参数。
from pymilvus import MilvusClient# 准备索引构建参数
index_params = MilvusClient.prepare_index_params()index_params.add_index(field_name="your_vector_field_name", # 要索引的向量字段的名称index_type="FLAT", # 要创建的索引类型index_name="vector_index", # 要创建的索引的名称metric_type="L2", # 用于度量相似性的度量类型params={} # FLAT不需要额外的参数
)在此配置中
index_type:要建立的索引类型。在本例中,将值设为FLAT。metric_type:用于计算向量间距离的方法。支持的值包括COSINE,L2, 和IP。params:FLAT 索引不需要额外参数。
配置好索引参数后,可直接使用create_index() 方法或在create_collection 方法中传递索引参数来创建索引。
2.2 在索引上搜索
建立索引并插入实体后,就可以在索引上执行相似性搜索。
res = MilvusClient.search(collection_name="your_collection_name", # 集合名称anns_field="vector_field", # 向量字段名data=[[0.1, 0.2, 0.3, 0.4, 0.5]], # 查询向量limit=3, # 返回TopK结果search_params={"params": {}} # FLAT不需要额外的参数
)3 IVF_FLAT
IVF_FLAT索引是一种可以提高浮点向量搜索性能的索引算法。这种索引类型非常适合需要快速查询响应和高精确度的大规模数据集,尤其是在对数据集进行聚类可以减少搜索空间,并且有足够内存存储聚类数据的情况下。
3.1 概览
术语IVF_FLAT代表反转文件扁平,概括了其索引和搜索浮点向量的双层方法:
- 反转文件 (IVF):指使用K 均值聚类将向量空间聚类为可管理的区域。每个聚类都有一个中心点,作为内部向量的参考点。
- 扁平:表示在每个聚类中,向量以原始形式(扁平结构)存储,不做任何压缩或量化,以便进行精确的距离计算。
下图显示了其工作原理:
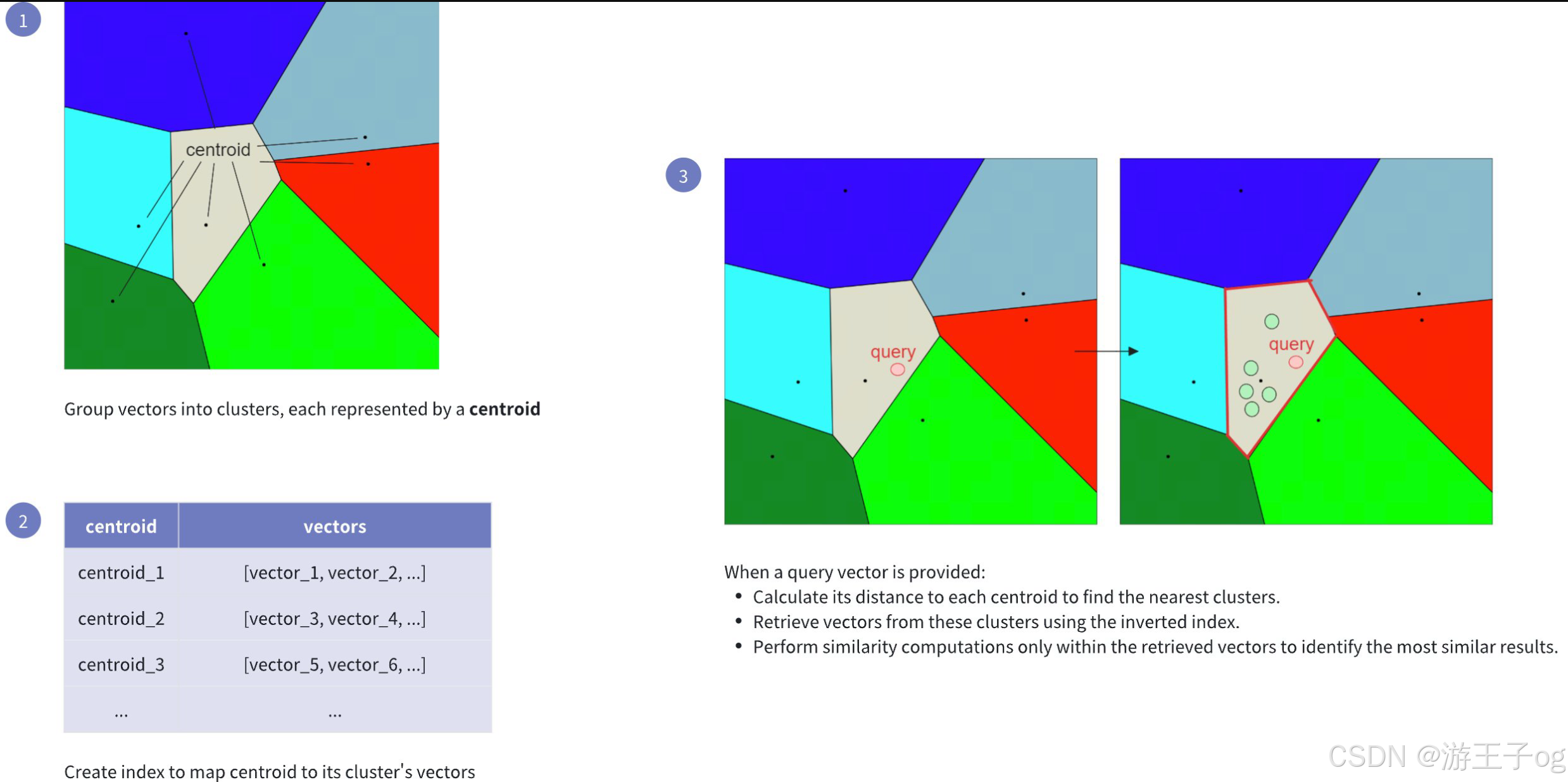
这种索引方法加快了搜索过程,但也有潜在的缺点:找到的最接近查询嵌入的候选嵌入可能并不是准确的最近嵌入。如果与查询嵌入点最近的嵌入点所在的聚类与根据最近中心点选择的聚类不同,就会出现这种情况(见下面的可视化图示)。为了解决这个问题,IVF_FLAT提供了两个超参数供我们调整:
nlist:指定使用 k-means 算法创建的分区数量。nprobe:指定在搜索候选对象时要考虑的分区数量。
现在,如果我们将nprobe 设置为 3,而不是 1,就会得到如下结果:
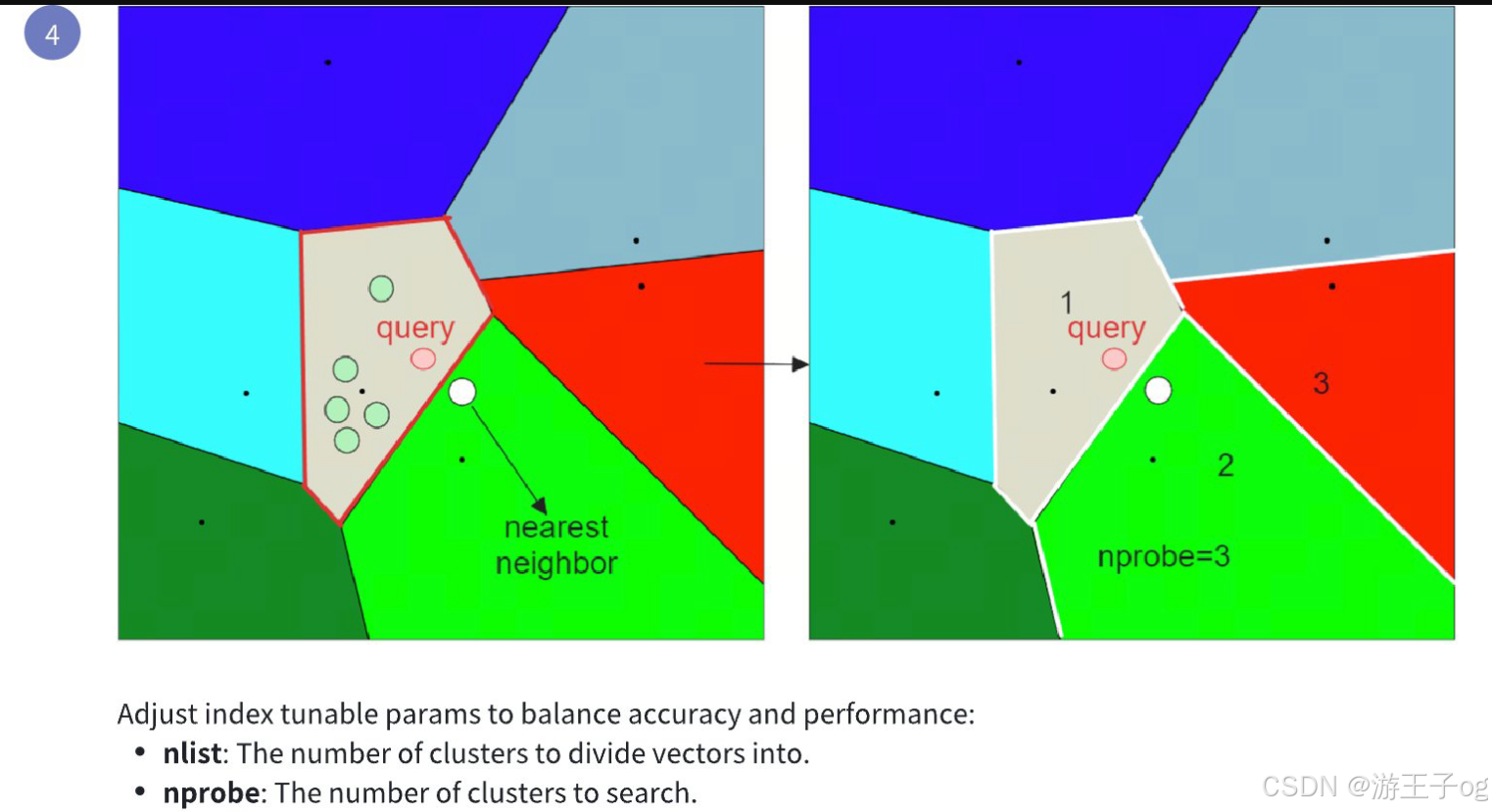
通过增加nprobe 值,可以在搜索中包含更多分区,这有助于确保不会错过与查询最接近的嵌入,即使它位于不同的分区中。不过,这样做的代价是增加搜索时间,因为需要评估更多候选项。
3.2 建立索引
要在 Milvus 中的向量场上建立IVF_FLAT 索引,请使用add_index() 方法,指定index_type,metric_type, 以及索引的附加参数。
from pymilvus import MilvusClient# 准备索引构建参数
index_params = MilvusClient.prepare_index_params()index_params.add_index(field_name="your_vector_field_name", # 要索引的向量字段的名称index_type="IVF_FLAT", # 要创建的索引类型index_name="vector_index", # 要创建的索引的名称metric_type="L2", # 用于度量相似性的度量类型params={"nlist": 64, # 索引的簇数} # 索引建立参数
)在此配置中
index_type:要建立的索引类型。在本例中,将值设为IVF_FLAT。metric_type:用于计算向量间距离的方法。支持的值包括COSINE,L2, 和IP。params:用于建立索引的附加配置选项。nlist:划分数据集的簇数。
配置好索引参数后,可直接使用create_index() 方法或在create_collection 方法中传递索引参数来创建索引。
3.3 在索引上搜索
建立索引并插入实体后,就可以在索引上执行相似性搜索。
search_params = {"params": {"nprobe": 10, # 要搜索的集群数}
}res = MilvusClient.search(collection_name="your_collection_name", # 集合名称anns_field="vector_field",data=[[0.1, 0.2, 0.3, 0.4, 0.5]], # 查询向量limit=3, # 返回TopK结果search_params=search_params
)3.4 索引参数
3.4.1 索引建立参数
| 参数 | 说明 | 值范围 | 调整建议 |
|---|---|---|---|
|
| 在建立索引时使用 k-means 算法创建的簇数。每个簇由一个中心点代表,存储一个向量列表。增加该参数可减少每个簇中的向量数量,从而创建更小、更集中的分区。 | 类型: 整数整数范围:[1, 65536] 默认值: |
|
3.4.2 特定于索引的搜索参数
| 参数 | 说明 | 值范围 | 调整建议 |
|---|---|---|---|
|
| 搜索候选集群的集群数。数值越大,搜索的簇数越多,搜索范围越大,召回率越高,但代价是查询延迟增加。 | 类型: 整数整数范围[1,nlist] 默认值: | 增加该值可提高召回率,但可能会减慢搜索速度。设置 在大多数情况下,我们建议您在此范围内设置一个值:[1,nlist]。 |