Windows远程桌面实现之十七:基于浏览器的文件和目录传输(一)
by fanxiushu 2025-05-07 转载或引用请注明原作者
其实这个课题本来没啥好说的,
因为通常意义上在实现远程控制之后,都会想到要实现文件目录的传输,这样才算完整。
但是xdisp_virt软件一直都没有这么做,
一是因为我有另外的软件 xFsRedir 完全能替代文件目录传输功能,
二是xdisp_virt比较特别,它的客户端是浏览器,这就给文件目录传输的实现带来了诸多限制。
不过在实现完成Web Terminal之后,就在琢磨着添加文件目录传输功能,
即便要添加也不能像普通的远程桌面软件那样,得基于浏览器的页面来做,
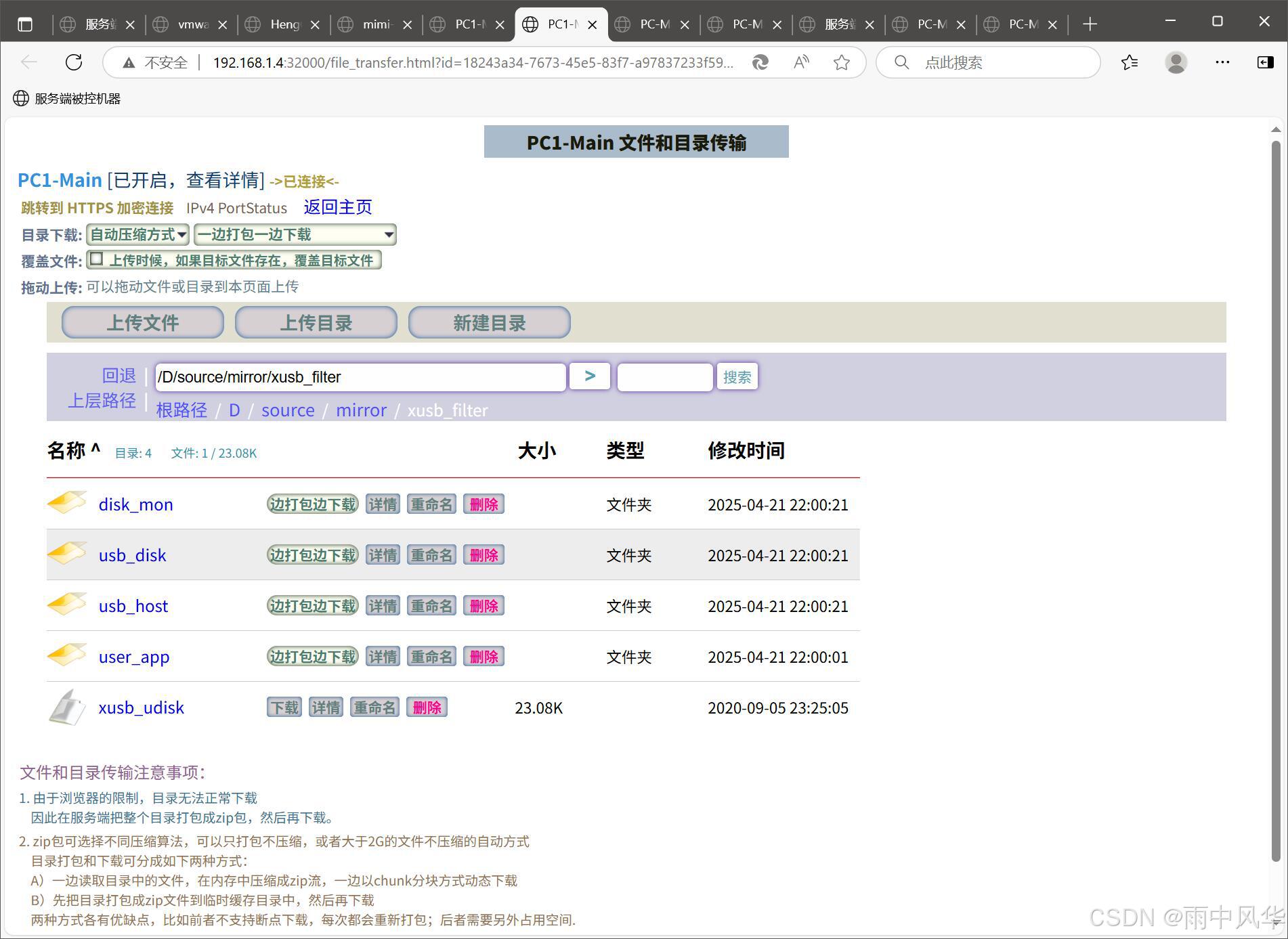
于是只能借鉴类似IIS,nginx等这些Web服务器那样,提供可以浏览目录的页面。
因此,xdisp_virt做出来的Web页面如下(比起简陋的IIS等目录浏览页面,这个下载页面要丰富许多):
演示视频可看下面,主要是为了加深对xdisp_virt文件目录传输的印象。
xdisp_virt软件的文件目录传输功能演示
接下来我们大致阐述 xdisp_virt 实现文件目录传输的流程。
首先我们看看底层的网络传输协议,
基于浏览器的文件目录传输,其实完全可以只使用HTTP,HTTPS协议,基本上就可以实现文件的上传和下载。
不过xdisp_virt基于浏览器方面的传输协议基本都是基于WebSocket的,有自己的一套通讯协议。
而且还需要实现xdisp_server这个中间服务器程序传输数据,
因此xdisp_virt的文件目录传输中,文件目录上传以及各类其他控制信息,都是通过WebSocket传输的。
除了下载,下载实在是没办法,只能使用https,http协议,基于浏览器的传统下载办法。
这也是浏览器下载有别于普通程序的地方,我们自己实现的普通程序,下载目录就真的是下载目录,
浏览器做不到,它得把目录打包成一个文件之后,按照文件的方式下载。
我们来看看,在浏览器中,如何上传文件或者目录。
查询了下相关资料,浏览器中上传文件和目录,
除了拖动只能使用唯一的办法:使用类型是 file的 input元素。
在Web页面中创建如下元素,即可实现简单的文件上传:
<input type="file" id="fileInput" multiple />
multiple 表示可以同时选择多个文件,
如果要上传目录,怎么做呢? 很简单,添加 webkitdirectory属性,如下:
<input type="file" id="dirInput" webkitdirectory directory multiple />
这样就会在web页面上会出现一个丑丑的按钮,点这个按钮,浏览器就会弹出一个让你选择文件的对话框。
现在该如何响应这个按钮事件呢?
那就是给这个 input 添加 change事件。
document.getElementById('fileInput').addEventListener('change', function (event) {
///
const files = event.files; 这个files就是你选择的文件列表信息。
});
因为原始的input的按钮都很丑,因此我们基本都是把input给隐藏掉,然后另外创建一个属于我们自己的风格的button来,如下:
<input type="button" style="width:160px;height:32px;" class="round-button" value="上传文件" id="btnUploadFiles" />
<input type="file" id="fileInput" style="display:none;" multiple />
然后添加事件函数:
document.getElementById('btnUploadFiles').addEventListener('click', function () {
document.getElementById('fileInput').click();
});
document.getElementById('fileInput').addEventListener('change', function (event) {
///
const files = event.files; 这个files就是你选择的文件列表信息。
});
接下来的主要内容,就是我们该如何处理 这个 files 对象了。
这个files其实是个数组,对应每个file对象,我们可以从每个file对象中,获取这个文件的大小,修改日期,读取这个文件的内容等。
比如我们选择目录的时候,files就会对应多个文件,都是保留了在目录中的相对位置的文件列表。
因此我们只需要把这个files内的全部file的上传给服务器端,就完成了文件或目录的上传。
这个过程,我们可以的使用传统的http或者https协议的POST命令上传,服务端实现对应的POST命令的接收功能即可。
但是上面说了,xdisp_virt基于浏览器这部分的通讯核心都是使用的WebSocket的,
因此这里使用WebSocket来上传文件,
不单是上传,上边的演示web页面中,创建目录,重命名,删除,查看详情等都是通过WebSocket传输的命令。
而且正是因为使用了WebSocket,我们还可以把上传的功能实现的更加丰富一些,
比如实现断点上传,如果上传过程中网络中断,下次接着从断点处上传。
至于使用WebSocket上传文件的具体过程,每个人都可以有自己的实现,没有统一规定。
xdisp_virt程序采用先发命令到服务端查看文件是否存在,如果存在就不处理,
接着判断后缀是 xdisp_virt.uping的临时文件是否存在,如果存在则获取这个临时文件大小,
然后就是以这个临时文件大大小为偏移,读取文件,以分块的方式上传,每块的大小大概是 256KB。
这块内容上传完成,得到服务器端的回应之后,接着把偏移增加256KB,然后接着再读取下一个256KB,
直到达到文件末尾上传完成,
完成之后,再发送命令把临时文件名称改成最终文件名,同时更正文件的修改时间等信息。
至此,一个文件传输完成。如果有多个文件同时传输,继续循环即可。
这里简单说说如何在javascript中,偏移读取某个文件的某个数据块。
按照上面的例子,假设我们获得上传的文件数组 files,
对于某个 文件 file: for( file in files){ }
假设我们对file文件,要从 offset 开始读取 block_size 大小的数据块,按照如下方式读取:
var blob = file.slice(offset, offset+ block_size);
var reader = new FileReader();
reader.onload = function (e) {
///已经读到这个数据块了, data就是数据内容,真实读取的数据长度是 data.length
///然后我们把这个数据通过websocket上传。
var data = new Uint8Array(e.target.result);
}
reader.onerror = function (e) {
/读取文件发生了错误,做出错处理
}
reader.readAsArrayBuffer(blob); ///开始读取数据块
以上代码看起来有种一气呵成的感觉,看起来比C语言简洁,这也是js脚本语言的的优势。
至于其他比如删除,重命名,创建目录等等,浏览器端只需要发出命令,
一切都交给服务端也就是xdisp_virt程序去处理即可,这里不再赘述。
正如上面所述,
目录的上传,是可以做到罗列出目录中的单个文件形成一个files数组,
然后把files全部上传,同时保持文件的相对位置不变,也就达到了目录上传的目的。
其实我们在普通的程序中,也是这么处理目录的上传和下载的。
然而,现在我们得看看浏览器的下载的问题,尤其是目录的下载。
新版本的浏览器实现了一套基于文件下载的一套js API接口,
但是很可惜,很多浏览器都不支持,而且必须得https环境中,反正就是各种限制。
因此果断放弃这套API,还是采用传统的 http,https的下载方式。
至此,WebSocket也就是无法使用到文件的下载中了,
同时还有个相当麻烦的事情:目录无法直接下载。
这可能是最头大的事情,即使使用新接口也没法做到。
原因是浏览器基于安全考虑,直接屏蔽了在js脚本中访问本地文件系统
(除了读,而且读也是只能通过input方式或者拖动获取 files 才能读)。
好在天无绝人之路:
浏览器支持单个文件下载的,而且从浏览器诞生开始就支持,
我们可以在服务端,把整个目录打包成单一文件,然后再通过浏览器下载,
这就是解决浏览器下载目录的思路。
对于这个打包过程,则有些考究,一般最容易想到的办法就是:
先在服务端把某个目录打包到临时缓存目录中,同时打成zip包是最容易实现的方式。
然后等打包完成之后,再告诉浏览器一个URL链接地址,这样浏览器就能通过这个地址下载这个zip包。
这也是我在xdisp_virt中最开始实现的一个方式: 先打包再下载。
这种方式的缺点也很明显:
当目录很多很大的时候,打包过程很费时间,浏览器端就得等很长一段时间。
xdisp_virt中的解决办法就是整个的打包过程,通过WebSocket传输进度信息给浏览器,
这样浏览器端就不会傻傻等待,起码知道处理过程。
另外一个缺点就是目录很多很大,占用的临时磁盘空间也会很大,
这就没有具体的办法了,只能是使用者自己评估,然后考虑要不要通过这种方式下载目录。
再到后来,想在xdisp_virt的Web Terminal超级终端中下载目录,
同时还需要在xdisp_virt的远程桌面功能(xdisp_virt本来就是个远程桌面)中实现目录的下载,
因此,这种先打包后下载的办法就显得有些力所不及了。
其实很早前,就有一个疑惑,就是我在使用github的时候,
里边有个功能,可以直接把整个项目,打包成zip下载,
当时稀里糊涂的就以为是github实现中,先把整个项目打包到临时缓存目录中,然后再下载,
然后就在疑惑,他们的服务器得提供多大的硬盘空间来处理这种下载啊?
再到后来也懒得去仔细考虑这个问题了。
直到现在,自己遇到这个问题,才不得不再次面对。
然后就想到,要是能一边打包一边下载就好了,
然后仔细再去研究这些提供zip打包下载的网站,包括github,
还真就是一边打包一边下载的。
这可是个近期的大发现。
在传统的固有的思路中,一边打包一边下载,是很难做到的,
等于就是流式打包,就跟音视频流一样,
压缩数据写入之后,就一路狂奔,绝不回头,否则就不叫流式打包压缩。
然而zip压缩算法恰好支持流式打包,这是挺神奇的事,
本来按道理讲,zip格式是很早定义的,当时的人们应该想不到这么长远的,
只不过呢,当时就有磁带机了啊,而磁带机恰好就是个一路狂奔不回头的顺序读写的设备。
当时的数据要压缩到磁带机上,就只能设计一个流式协议的压缩方式。
现在我们简单看看zip格式。
zip打包格式的中,主要要,两大块:
1,数据区,
2,中央目录记录,中央目录区记录了所有被压缩文件的相关信息。
其中“数据区”包括:
1,本地文件头,包括文件基本信息,比如文件大小,压缩后的大小,文件名,压缩方式等
2,压缩的文件内容,
3,数据描述符,用于校验完整性。
其中我们重点关注 ”数据区“,因为在通常情况下,在这里压缩一个文件的时候,会发生随机写。
首先我们把文件头结构写入,其中关键信息就是未压缩文件大小,压缩之后的大小等信息,
一开始的时候,这两个内容都是 0,因为一开始的时候并不知道压缩后的大小,
等全部压缩完成,才能知道大小,这个时候,就必须重新定位,然后更新这两个内容,
这样,显然就会造成随机写,不再是流式写了。
而且在普通方式中,第3个数据描述符是可以不用的。
好在zip在设计打包的方式的时候,考虑到了流式的需求(估计当时就是为了考虑磁带机的需求)
通过设置flag参数,告诉这是个流式压缩,同时压缩完成不再回头更新本地文件头的内容,
同时也必须包括 数据描述符,在数据描述符中必须包括 文件原始大小和压缩后的大小。
这样就确保了整个压缩过程是流式进行的。
具体可以查看 zlib库中的 contrib目录下的minizip目录中 的 zip.c 源代码,
可惜的是,zip.c源代码中并未直接实现流式压缩,
我们必须对这个代码做些修改,增加上面我描述的大致内容。
我们也可以通过分析源代码,尤其是分析 ZSEEK64 这宏,来确保这个宏不被调用。
因为正是这个宏会造成随机写。
以修改过的支持流式压缩的 zip.c 为基础,
我们可以简洁的设计以下三个接口函数来实现流式压缩目录:
void* stream_zipdir_create(const char*lpath);
void stream_zipdir_destroy(void* handle);
int stream_zipdir_read(void* handle, char* buf, int len);
stream_zipdir_create
大致动作就是打开 lpath指定的目录,等待进一步遍历使用。
然后调用 zip.c的接口函数 zipOpen2_64 创建一个空白zip文档。
同时 给 zipOpen2_64提供的都是我们自己定义的回调函数,用来接收压缩的数据。
接着 stream_zipdir_read 的实现就非常热闹了。
每次调用stream_zipdir_read 都会记录下当前搜索到目录中的哪个文件了,以及接下来需要搜索哪个文件,
这里边会牵涉到对目录的广度还是深度搜索问题,
然后就是对每个搜索到的文件调用 zipOpenNewFileInZip4_64,之后就是读取这个文件,
调用zipWriteInFileInZip 压缩到zip流中,这时候我们在zipOpen2_64设置的回调函数就会被调用,
在回调函数中读取到数据流,stream_zipdir_read 写到buffer中,并且记录当前的状态,然后返回。
等下次再调用stream_zipdir_read 的时候,由上次记录的状态开始继续处理。
直到目录搜索完成,最后一个文件处理完成为止。
具体的实现过程,有兴趣的同学,可自行去研究实现。
下一章,接着阐述文件传输,包括浏览器拖动文件上传,以及在远程桌面中如何实现文件粘贴等功能。