突破传统!TTRL如何开启大模型无监督强化学习新篇章?
在大语言模型(LLMs)蓬勃发展的时代,如何让模型在无明确标签数据下有效学习成为关键难题。本文提出的Test-Time Reinforcement Learning(TTRL)给出了创新解法。它利用多数投票估计奖励,实现LLMs自我进化,在多种任务和模型上显著提升性能,快来一探究竟吧!
论文标题
TTRL: Test-Time Reinforcement Learning
来源
arXiv:2504.16084v1 [cs.CL] + https://arxiv.org/abs/2504.16084
文章核心
研究背景
Test-Time Scaling(TTS)成为提升大语言模型推理能力的新兴趋势,强化学习(RL)在增强模型思维链推理方面也至关重要,但现有模型在处理无标签新数据时仍面临困境。
研究问题
- 在推理时,缺乏真实信息的情况下难以进行奖励估计,从而限制了基于RL的模型在无标签数据上的训练。
- 大规模标注数据用于RL在实际中越来越不切实际,这成为领先模型持续学习的重大障碍。
主要贡献
1. 提出全新训练方法:引入TTRL,在测试时利用RL对预训练模型进行训练,通过多数投票估计标签和计算奖励,实现无监督训练,突破了传统RL依赖已知奖励信号的局限。
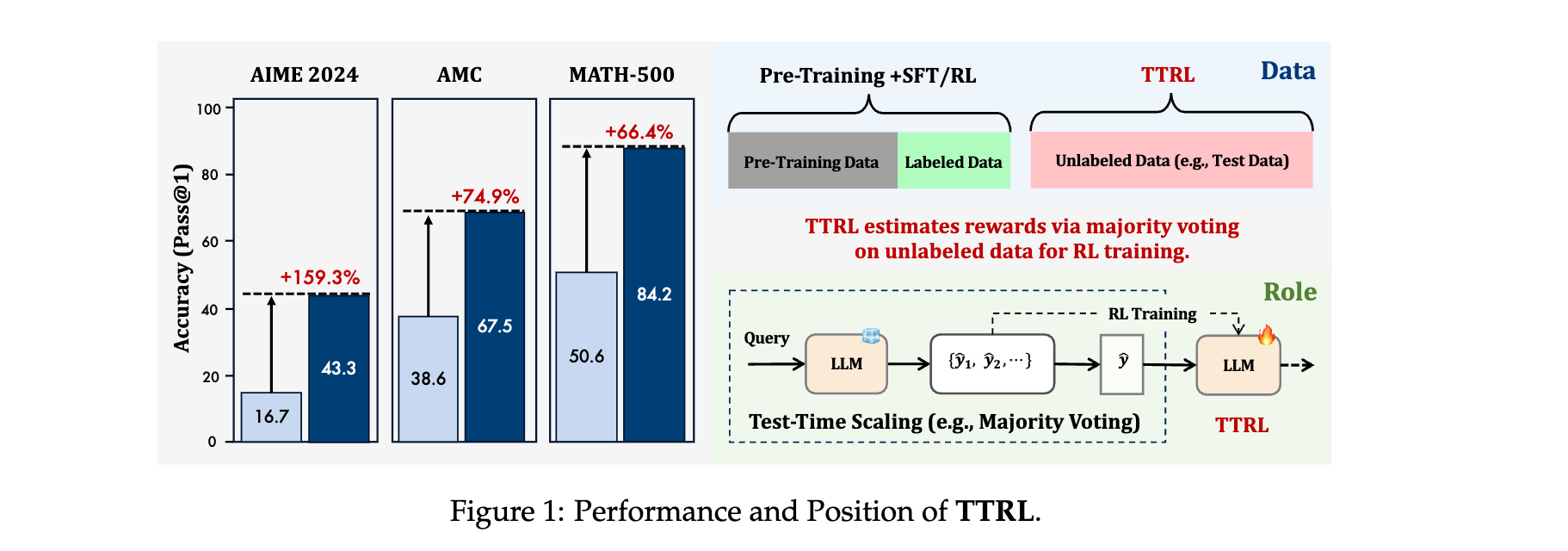
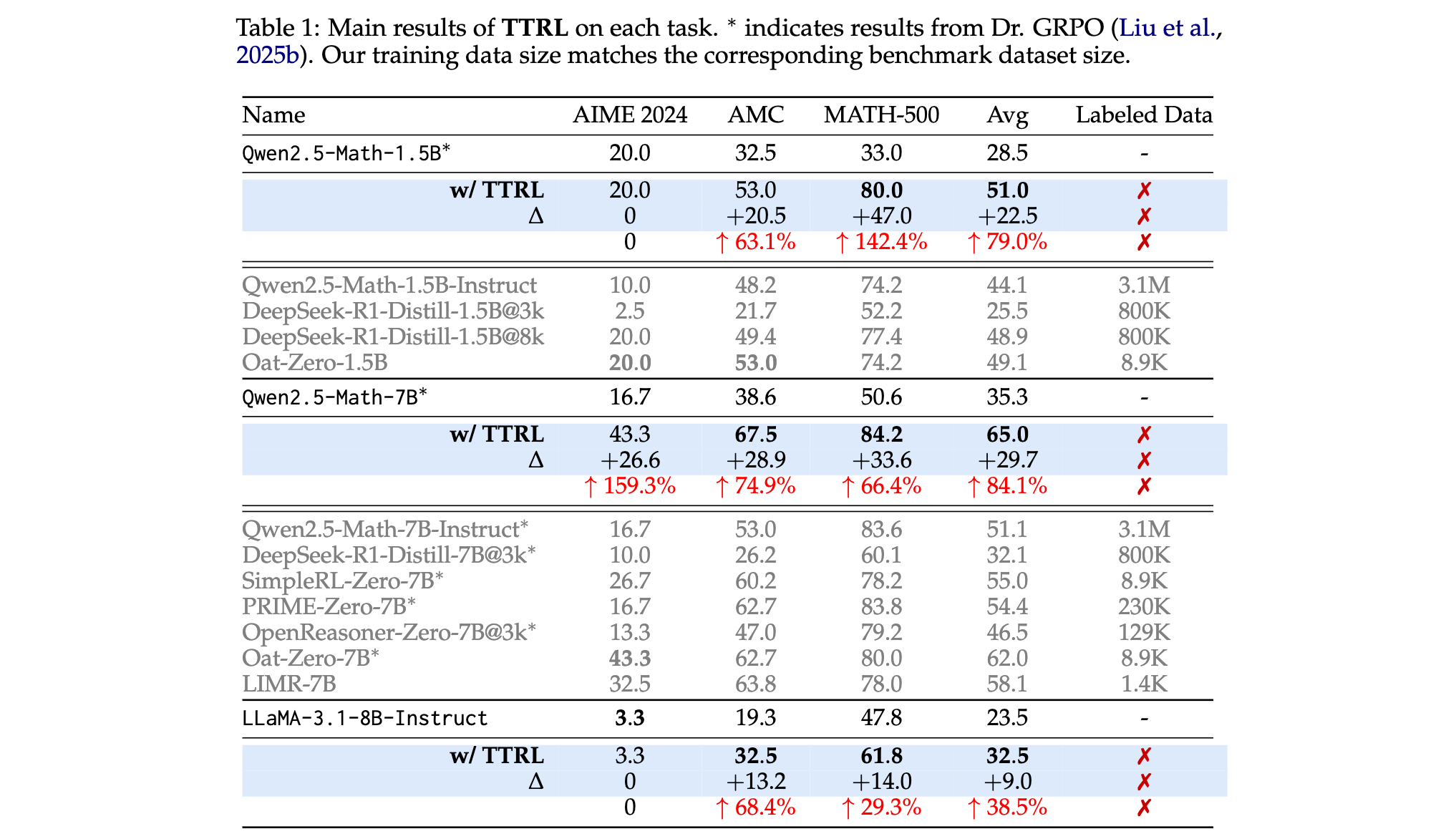
2. 有效提升模型性能:TTRL能让模型超越自身训练信号和初始模型的直观上限,性能接近使用真实标签在测试数据上直接训练的模型。例如在AIME 2024上,Qwen-2.5-Math-7B使用TTRL后pass@1性能提升约159%。
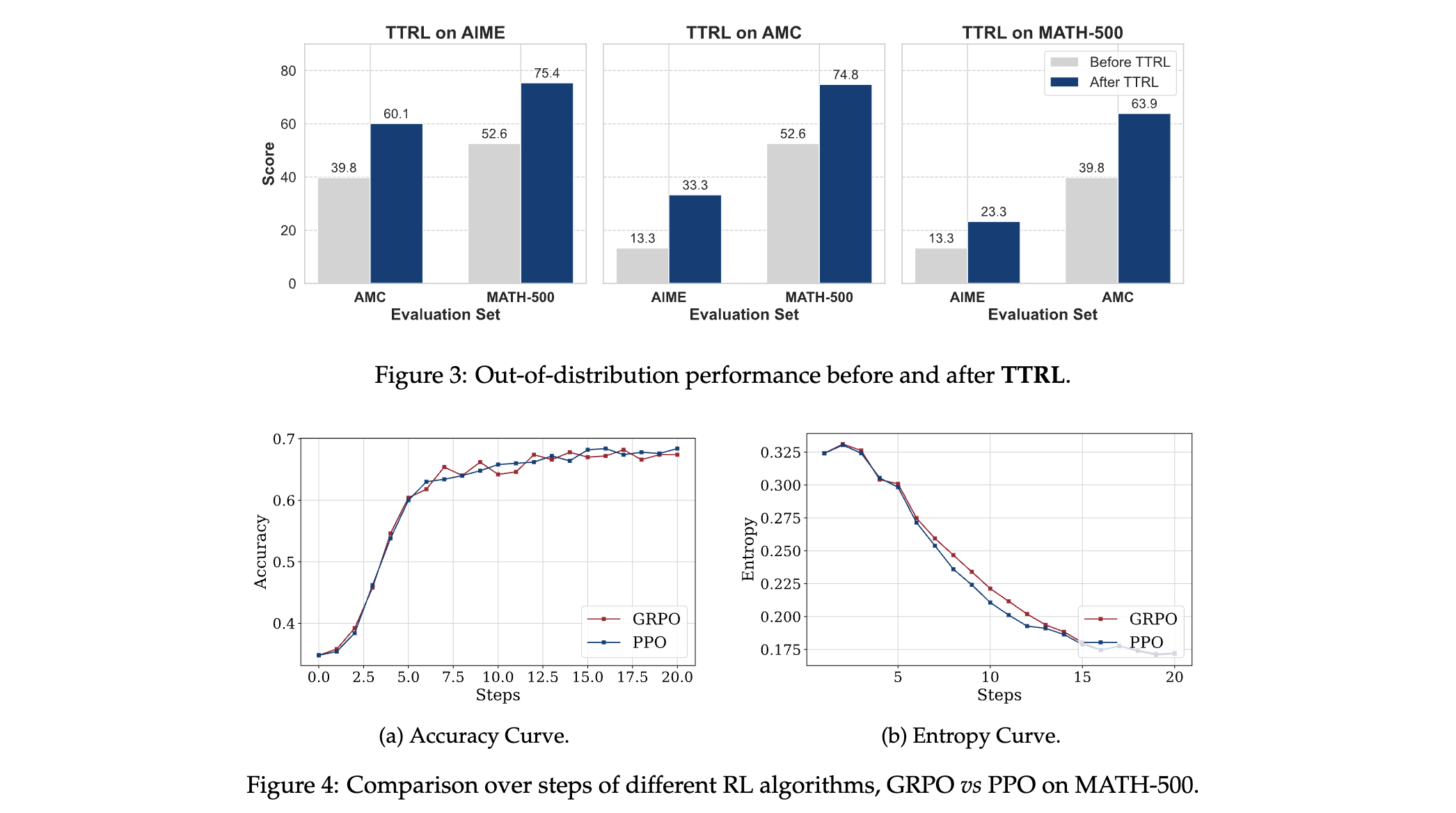
3. 展现良好特性:TTRL具有自然扩展性,模型规模增大时性能提升更明显;能在不同任务间有效泛化;还可与不同RL算法兼容,如与PPO结合表现稳定。
方法论精要
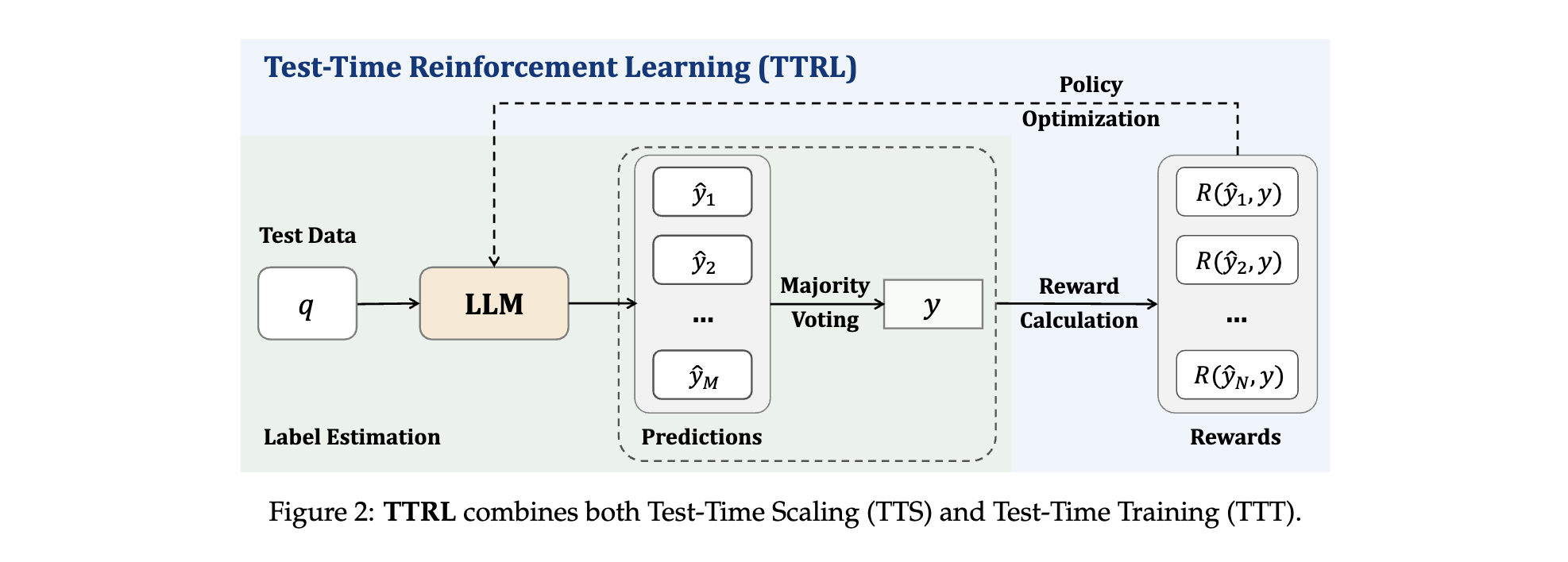
1. 核心算法/框架:TTRL基于策略梯度优化框架,给定输入提示 x x x,模型根据参数化策略 π θ ( y ∣ x ) \pi_{\theta}(y|x) πθ(y∣x) 生成输出 y y y 。通过重复采样得到多个候选输出,用多数投票等方法得出共识输出 y ∗ y^{*} y∗ ,环境依据 y y y与 y ∗ y^{*} y∗的一致性给出奖励 r ( y , y ∗ ) r(y, y^{*}) r(y,y∗),模型通过梯度上升更新参数 θ \theta θ ,以最大化期望奖励。
2. 关键参数设计原理:学习率 η \eta η设置为 5 × 1 0 − 7 5×10^{-7} 5×10−7 ,采用AdamW优化器。在rollout阶段,采样数量、温度等参数根据任务和数据集调整,如为估计标签,对AIME 2024和AMC采样64个响应,对MATH-500采样32个响应,温度设为1.0,以平衡模型探索与利用能力。
3. 创新性技术组合:结合Test-Time Scaling(TTS)和Test-Time Training(TTT),利用多数投票奖励函数在无真实标签情况下构建有效奖励信号,实现模型在测试时的自我进化。
4. 实验验证方式:选用不同类型和规模的模型,如Qwen2.5-Math-1.5B、Qwen2.5-Math-7B、LLaMA-3.1-8B-Instruct等。在AIME 2024、AMC、MATH-500这3个数学推理基准测试上进行实验。基线选择包括骨干模型、经过大规模后训练的Instruct版本以及当前领先的“R1-Zero-Like”模型,通过对比验证TTRL的有效性。
实验洞察
1. 性能优势:在AIME 2024上,Qwen2.5-Math-7B使用TTRL后pass@1性能提升159.3% ,远超所有在大规模数据集上训练的模型;在三个基准测试上,Qwen2.5-Math-7B使用TTRL平均提升84.1%;LLaMA-3.1-8B-Instruct使用TTRL在AMC和MATH-500上也有显著提升。
2. 消融研究:对MATH-500按难度分级进行实验,发现随着问题难度增加,TTRL的性能提升和长度缩减比率下降,表明模型先验知识不足会影响TTRL效果;研究还发现温度和训练批次大小等超参数对训练稳定性和性能影响显著。
3. TTR性能/有效性及局限性讨论: (1)TTRL 在性能表现上十分出色,超越自身训练信号及初始模型上限 Maj@N,接近使用真实标签测试数据直接训练的模型性能,如 Qwen2.5-Math-7B 的 TTRL 的 Avg@64 在基准测试中优于该模型 Maj@64,在 MATH-500 上其性能曲线与 RL (leakage) 相近,小模型 Qwen2.5-Math-1.5B 在 MATH-500 上准确率提升显著。(2)TTRL 有效的原因在于强化学习对奖励不准确有容忍度,策略模型自身估计的奖励信号更利于学习,且奖励比标签更密集,模型能力弱时奖励可能更准确。(3)不过,TTRL 也存在可能失败的场景,算法层面它对数据难度敏感、依赖先验知识且有崩溃风险,实现层面通过多数投票估计标签和在稀疏未见测试数据上运行放大了这些问题,如模型缺乏目标任务先验知识时(像 Qwen2.5-Math-1.5B 和 LLaMA-3.1-8B-Instruct 在 AIME 2024 上的表现),以及强化学习超参数不合适(如温度设置为 0.6 时),都会影响训练效果 。