《计算机视觉度量:从特征描述到深度学习》—图片多模态CLIP,BLIP2,DINOv2特征提取综述
2024年以后大模型开始被大家熟知,同样基于图片的大模型基础框架同时也被大家开始熟知。最早的图片大模型是OpenAI提出的CLIP,他是一套基于图片数据和文本数据对齐的模型。通过文本对图片数据的描述,来对齐和学习图片特征数据。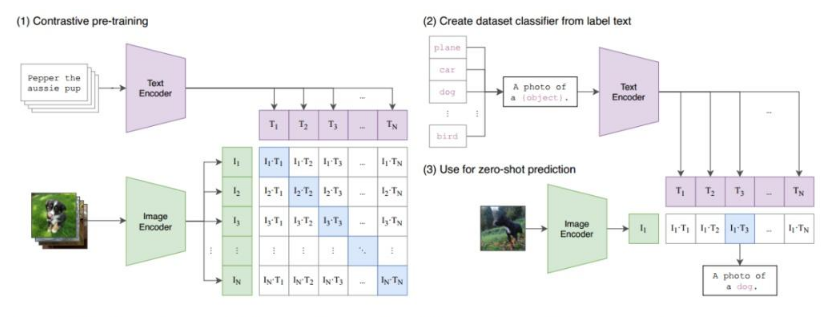
在使用这种文本和图像数据对齐模型的过程中,就衍生出图生文和文生图的模型。后来被称为多模态大模型。
模型的实现原理是通过提取和训练图像的特征数据,和文本数据。通过强化学习实现两者数据特征的对齐。在对齐的过程中模型对图像特征数据细节也越来越具体,所以在把多模态的基础模型衍生到传统的视觉模型后,很明显提升准确率。最突出的结论是,目前分类,目标检测,分割模型的TOP1都是多模态的基础模型开发的。
2025年4月为止,在近两年的发展过程中,多模态基础模型也百花齐放,目前主流的除了CLIP以外,还有BLIP2和DINOv2等主流的模型。同样多模态基础模型图像数据特征也使用越来广泛,图片数据的特征提取方法如下:
特征的提取都是基于VIT的基础网络,把图片切割成Patch(补丁),通过大模型的推理获取关于每个Patch的位置和图片数据的描述特征。模型大小和训练方式的不一样,获取的Patch描述维度也不一样。BLIP2单个Patch描述维度是768,CLIP单个Patch的描述维度是512,DINOv2根据模型大小不一样分为384,768,1024三种维度,对应不同大小的模型
BLIP2图片特征数据提取代码:
#添加Pytorch依赖
import torch
from PIL import Image
#添加多态依赖库
from lavis.models import load_model_and_preprocess
#获取GPU
device = torch.device("cuda") if torch.cuda.is_available() else "cpu"
#加载预训练多模态大模型
model, vis_processors, txt_processors = load_model_and_preprocess(name="blip2_feature_extractor", model_type="pretrain", is_eval=True, device=device)
#读取图片数据
image = Image.open("image.bmp").convert("RGB")
#图片数据Patch编码
image_tensor = vis_processors["eval"](image).unsqueeze(0).to(device)
#通过模型获取编码特征
features = model.extract_features(sample, mode="image")#环境依赖pytorch和lavisCLIP图片特征提取代码:
import torch
from PIL import Image
from transformers import CLIPProcessor, CLIPModel# 加载预训练的CLIP模型和处理器
model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")#加载模型到GPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = model.to(device)#加载图片
image = Image.open("Image.bmp").convert("RGB")
#对图片进行Patch编码
inputs = processor(images=image, return_tensors="pt").to(device)
with torch.no_grad():#获取图片特征数据features= model.get_image_features(**inputs).cpu().numpy()#环境依赖pytorch和transformers,PILDINOv2图片特征提取代码:
import torch
from PIL import Image
from torchvision import transforms#设置模型图片尺寸
image_w = 1120
image_h = 1120
#加载模型
model = torch.hub.load('facebookresearch/dinov2', self.model_name)
model.eval()
#图片数据预处理方法设置
Transform = transforms.Compose([transforms.Resize(size=self.smaller_edge_size, interpolation=transforms.InterpolationMode.BICUBIC, antialias=True),transforms.ToTensor(),transforms.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)), # imagenet defaults])#读取图片函数
img = Image.open(img).convert("RGB")
img = img.resize(1120,1120)
#图片预处理
image_tensor = transform(img)
#图片迁移到GPU
image_batch = image_tensor.unsqueeze(0).to(self.device)
#获取图片特征数据
features = model.get_intermediate_layers(image_batch)[0].squeeze()#环境依赖pytorch和transformers,torchvision ,PIL体验大模型在工业检测的应用方法,DY搜索'军哥讲视觉',或者WX搜索军哥讲视觉',关注留言