快速在RK3588上部署运行DeepSeek-R1-Distill-Qwen-1.5B模型并进行板端推理调用流程记录
RK3588
- 下载
- 简介
- 安装anaconda
- 安装RKLLM-Toolkit
- 更新NPU版本
- 模型转换
- 编译模型推理调用的示例代码
- 推送相关的文件到板端
- 板端推理调用
下载
DeepSeek-R1-Distill-Qwen-1.5B
RKLLM-Toolkit(rknn-llm-release-v1.2.1)
交叉编译工具
参考正点原子
简介
RKLLM-Toolkit 是为用户提供在计算机上进行大语言模型的量化、 转换的开发套件。 通过该工具提供的 Python 接口可以便捷地完成以下功能:
1) 模型转换: 支持将 Hugging Face 和 GGUF 格式的大语言模型( Large Language Model,LLM) 转换为 RKLLM 模型,转换后的 RKLLM 模型能够在 Rockchip NPU 平台上加载使用。
2) 量化功能: 支持将浮点模型量化为定点模型。
RKLLM-Toolkit和RKNN_Toolkit2区别(来自豆包):
RKLLM-Toolkit:主要聚焦于大语言模型(LLM)相关的推理和应用开发 。它为在瑞芯微芯片平台上高效运行大语言模型提供支持,例如对像 LLaMA、ChatGLM 等常见大语言模型进行适配和优化,让开发者能够基于瑞芯微硬件,进行大语言模型相关的应用开发,比如开发端侧的智能对话机器人、文本生成应用等。
RKNN_Toolkit2:是用于将各类深度学习模型(不限于大语言模型,像图像识别模型、目标检测模型等)转换为瑞芯微神经计算内核(RKNPU)可执行的 RKNN 格式,并在瑞芯微设备上进行推理计算。它涵盖了模型转换、量化、性能评估、推理加速等一系列功能,方便开发者将基于 TensorFlow、PyTorch 等框架训练好的模型部署到瑞芯微的芯片平台,以实现图像分类、目标检测、语义分割等多种计算机视觉和其他深度学习应用。
安装anaconda
在自己需要的文件夹下执行命令:
wget -c https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/Anaconda3-2023.03-1-Linux-x86_64.sh
下载完成后使用bash命令安装:
bash Anaconda3-2023.03-1-Linux-x86_64.sh
创建python环境:
conda create -n RKLLM-Toolkit python=3.8
我使用3.12版本的话安装auto_gptq会报错。换回官方推荐的3.8版本没问题
如果激活conda环境报错,提示需要初始化,可以使用:
source activate RKLLM-Toolkit
安装RKLLM-Toolkit
以下将rknn-llm-release-v1.2.1解压后命名为rkllm。路径:rkllm/rkllm-toolkit :

cpxxx中xxx为创建的conda环境中python版本,以下需要在conda环境中运行,使用https://pypi.tuna.tsinghua.edu.cn/simple源安装RKLLM-Toolkit 和RKNN-Toolkit2 都没有问题。
pip install rkllm_toolkit-1.2.1-cp38-cp38-linux_x86_64.whl -i https://pypi.tuna.tsinghua.edu.cn/simple
安装好后进入python命令行,输入from rkllm.api import RKLLM命令不提示没有RKLLM模块就可以:
更新NPU版本
查询NPU版本:
cat /sys/kernel/debug/rknpu/version

NPU驱动文件路径:rkllm/rknpu-driver/rknpu_driver_0.9.8_20241009/drivers/rknpu
将rknpu文件复制到SDK中,rk3588_linux_sdk/kernel/drivers/rknpu
修改kernel/include/linux/mm.h,加入:
static inline void vm_flags_set(struct vm_area_struct *vma,vm_flags_t flags)
{vma->vm_flags |= flags;
}static inline void vm_flags_clear(struct vm_area_struct *vma,vm_flags_t flags)
{vma->vm_flags &= ~flags;
}
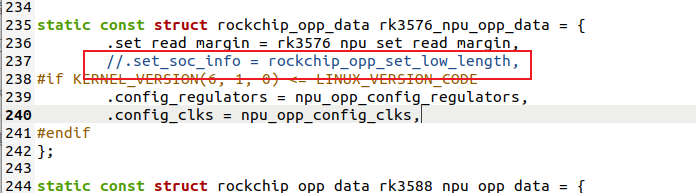
修改kernel/drivers/rknpu/rknpu_devfreq.c,屏蔽237行,否则编译内核会报错:
drivers/rknpu/rknpu_devfreq.c:237:18: error: ‘rockchip_opp_set_low_length’ undeclared here (not in a function); did you mean ‘rockchip_pvtpll_add_length’?
然后编译内核:
./build.sh kernel
将编译完成后的boot.img下载到开发板。
模型转换
修改rkllm/examples/DeepSeek-R1-Distill-Qwen-1.5B_Demo/export/export_rkllm.py,把modelpath替换为实际的模型路径:
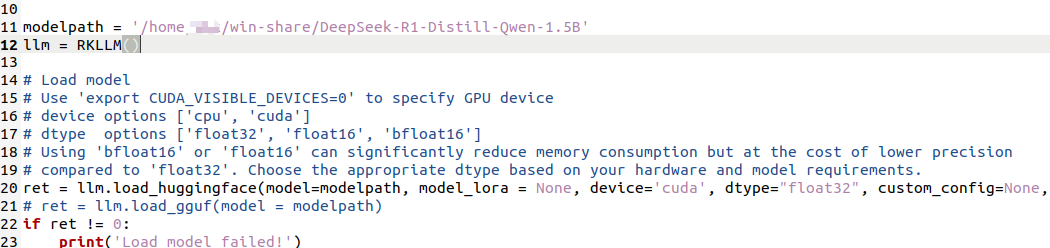
然后输入下面命令开始转换:
python export_rkllm.py

转换完成后在rkllm/examples/DeepSeek-R1-Distill-Qwen-1.5B_Demo/export文件夹下会生成一个rkllm格式的文件。
如果转换时出现下面的错误提示:

使用下面命令查看系统内核日志最新 7 条记录:
sudo dmesg | tail -7

若运行后看到类似 Out of memory: Killed process 3238(XXXXX) 的日志,说明 Python 进程因内存不足被内核终止。
在ubuntu下创建10g的交换分区,使用硬盘的空间作为运存。
# 创建指定大小的交换文件
# if=/dev/zero:从空字符设备读取数据(用于生成空白文件)
# of=/tmp/swapfile:输出到 /tmp/swapfile(交换文件路径)
# bs=1M:每次读写的块大小为 1MB
# count=10240:共写入 10240 个块,总大小为 10GB(1M×10240)
sudo dd if=/dev/zero of=/tmp/swapfile bs=1M count=10240
# 设置交换文件权限
sudo chmod 0600 /tmp/swapfile
# 格式化交换文件为 Swap 文件系统,将普通文件转换为 Swap 格式,使其能被系统识别为交换空间。
sudo mkswap /tmp/swapfile
# 启用交换文件,立即激活该交换文件,系统会开始使用它作为虚拟内存补充。
sudo swapon /tmp/swapfile
# 查看分区情况,输出所有已启用的 Swap 设备 / 文件信息,包括路径、类型、大小和使用情况,确认新创建的 Swap 是否生效。
swapon -s
编译模型推理调用的示例代码
交叉编译工具使用官方推荐的版本:

修改rkllm/examples/DeepSeek-R1-Distill-Qwen-1.5B_Demo/deploy/build-linux.sh,把交叉编译工具的路径替换为自己的实际路径。

执行下面命令编译,编译后会在deploy文件夹下生成install文件夹,文件夹下会有一个demo_Linux_aarch64文件夹。
./build-linux.sh
推送相关的文件到板端
硬件:正点原子RK3588开发板
复制gcc-arm-10.2-2020.11-x86_64-aarch64-none-linux-gnu/aarch64-none-linux-gnu/lib64路径下的libgomp.so和libgomp.so.1文件到rkllm/examples/DeepSeek-R1-Distill-Qwen-1.5B_Demo/deploy/install/demo_Linux_aarch64/lib文件夹下。这两个是链接文件,使用下面命令复制:
cp -LR libgomp.so libgomp.so.1 /path/to/software/rkllm/examples/DeepSeek-R1-Distill-Qwen-1.5B_Demo/deploy/install/demo_Linux_aarch64/lib/
libgomp.so是GCC(GNU Compiler Collection)所使用的自由软件编译器的一部分,也是GCC并行(OpenMP)库的一部分。它是一个可以与GCC链接的动态共享库,可以提供并行计算的支持。 在GCC编译期间,链接器将libgomp.so作为一个库链接到可执行文件中。在运行时,程序会加载libgomp.so,从而使用并行计算功能。
复制完成后lib文件夹下有3个lib文件:

如果没有libgomp文件会报错./llm_demo: error while loading shared libraries: libgomp.so.1: cannot open shared object file: No such file or directory:

使用adb工具将可执行文件、 函数库文件夹 lib ,定频文件及 RKLLM 模型(RKLLM-Toolkit 工具转换后的)推送至板端:
# 推送可执行文件、 函数库文件夹 lib
adb push rkllm/examples/DeepSeek-R1-Distill-Qwen-1.5B_Demo/deploy/install/demo_Linux_aarch64 /userdata/Qwen_1.5b
# 推送RKLLM 模型
adb push rkllm/examples/DeepSeek-R1-Distill-Qwen-1.5B_Demo/export/DeepSeek-R1-Distill-Qwen-1.5B_W8A8_RK3588.rkllm /userdata/Qwen_1.5b/demo_Linux_aarch64
# 推送定频文件
adb push rkllm/scripts/fix_freq_rk3588.sh /userdata/Qwen_1.5b/demo_Linux_aarch64
推送完成后文件如下:

板端推理调用
调用前先修改一下当前进程的最大文件描述符数量,默认应该是1024。
# 查询
ulimit -n
# 修改
ulimit -n 65500

否则可能会出现段错误:

调用前准备:
# 通过环境变量指定函数库路径
export LD_LIBRARY_PATH=./lib
# 运行定频文件
sh fix_freq_rk3588.sh
# 开启日志(可选)
export RKLLM_LOG_LEVEL=1 //仅查看 TTFT、 TPS 和内存数据
export RKLLM_LOG_LEVEL=2 //除了性能数据, 还会打印 cache 长度等更多信息
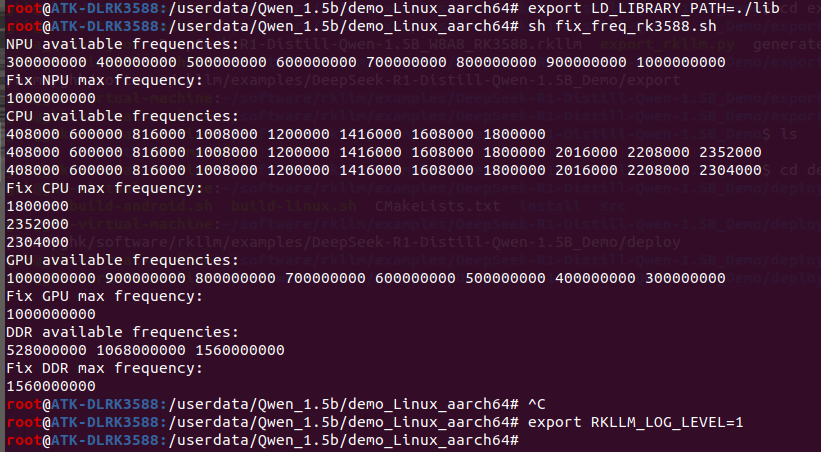
执行下面命令开始板端推理:
./llm_demo DeepSeek-R1-Distill-Qwen-1.5B_W8A8_RK3588.rkllm 2048 4096
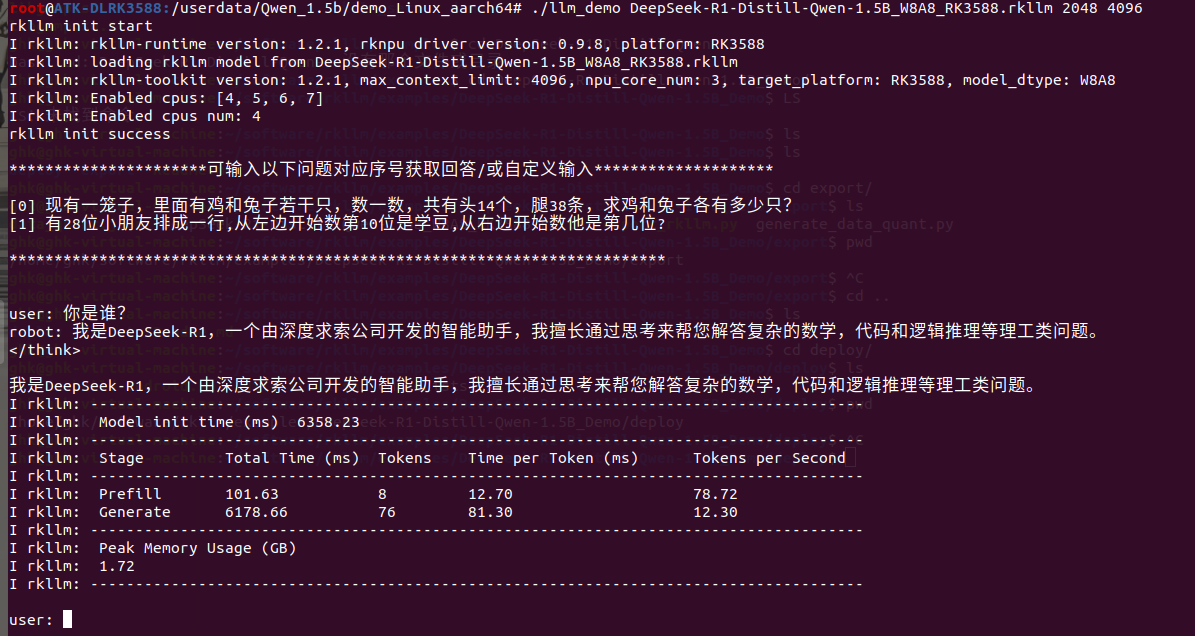
至此,就能在RK3588上部署运行DeepSeek-R1-Distill-Qwen-1.5B模型并进行板端推理调用。