Ai Qwen3解答epochs多少为最佳 仅共参考
“最佳”的 epochs(训练轮数)并没有一个固定的数值,它高度依赖于具体的模型类型、数据集、任务目标和训练策略。简单来说,太少会导致欠拟合,太多则容易过拟合。
以下是根据不同场景总结的最佳实践和建议:
📌 一、根据模型和任务类型选择
YOLO 目标检测模型
- 推荐范围:100 - 300 epochs
- 原因:目标检测任务较复杂,需要充分学习特征。
- 建议:使用早停机制(Early Stopping),当验证集损失不再下降时自动停止,避免过拟合。
大模型微调(如LLM)
- 全量微调(Full Fine-tuning):1-3 个 epoch 即可,超过5个极易过拟合。
- 参数高效微调(如LoRA):可训练更多轮,通常 3-10 个 epoch。
- 指令微调(Instruction Tuning):建议 2-5 个 epoch。
- 小数据集:1-3 个 epoch;大数据集:1-2 个 epoch 可能就足够。
通用深度学习模型(如CNN分类)
- 常见范围:100 - 200 epochs。
- 可作为初始实验的起点。
📌 二、影响 epochs 选择的关键因素
| 因素 | 说明 |
|---|---|
| 数据集大小 | 数据越多,可承受的 epochs 越多;数据少时需谨慎,避免过拟合。 |
| 模型复杂度 | 模型越复杂(参数越多),通常需要更多 epochs 才能收敛。 |
| 问题难度 | 简单任务(如二分类)可能几十个 epoch 就收敛;复杂任务(如生成、多模态)需要更多轮次。 |
| 计算资源 | 资源有限时,需在训练时间和性能间权衡。 |
| 优化算法 | Adam 通常比 SGD 收敛更快,所需 epochs 可能更少。 |
📌 三、如何确定最佳 epochs?—— 实用策略
✅ 使用早停机制(Early Stopping)
- 这是最推荐的方法。
- 监控验证集损失(或准确率),当其连续几个 epoch 不再改善时,自动停止训练。
- 既能防止过拟合,又能节省时间。
✅ 绘制 Loss/Accuracy 曲线
- 观察训练集和验证集的 loss 变化:
- 两者都下降 → 模型在学习。
- 训练 loss 下降,验证 loss 上升 → 过拟合! 应停止或减少 epochs。
- 找到验证 loss 的“最低点”作为最佳 epoch。
- 观察训练集和验证集的 loss 变化:
✅ 从小开始,逐步增加
- 初始可设为 10-20 个 epoch 快速测试。
- 若性能仍在提升,逐步增加 epoch 数,直到性能饱和。
✅ 结合学习率调度(Learning Rate Scheduling)
- 使用
ReduceLROnPlateau等策略,在 loss 停滞时降低学习率,帮助模型进一步收敛。
- 使用
✅ 总结:最佳实践建议
| 场景 | 推荐 epochs | 关键策略 |
|---|---|---|
| YOLO 检测 | 100 - 300 | Early Stopping + Loss 曲线观察 |
| 大模型全量微调 | 1 - 3 | 小步快跑,防过拟合 |
| LoRA 微调 | 3 - 10 | 可多训练,监控生成质量 |
| 图像分类(中等数据) | 50 - 200 | Early Stopping |
| 小数据集训练 | 10 - 50 | 严格防过拟合,数据增强 |
核心原则:不要盲目设大 epochs,要用验证集监控,让模型“恰到好处”地学习。
一、什么是“拟合”?过拟合 vs 欠拟合
“拟合(Fitting)”是指模型学习数据规律的能力。我们希望模型能恰到好处地学习数据的规律,而不是死记硬背或完全学不会。
1. 欠拟合(Underfitting)
- 表现:模型在训练集和验证集上都表现很差。
- 原因:模型太简单、训练轮数太少、学习率太高或数据特征不足。
- 比喻:学生上课没听懂,考试也考不好。
✅ 解决方法:
- 增加模型复杂度(如更多层、更多神经元)
- 增加训练 epochs
- 调整学习率
- 增强特征工程
2. 过拟合(Overfitting)
- 表现:模型在训练集上表现很好,但在验证集/测试集上表现差。
- 原因:模型“死记硬背”了训练数据的细节和噪声,没有学会泛化规律。
- 比喻:学生把课本答案背下来了,但换个题就不会做。
✅ 解决方法:
- 使用 早停机制(Early Stopping)
- 添加 正则化(如 Dropout、L2 正则)
- 数据增强(Data Augmentation)
- 减少模型复杂度
- 增加训练数据
📌 关键点:我们追求的是“良好拟合(Good Fit)”——在训练集和验证集上都表现稳定优秀。
好消息是:Ultralytics 已经内置了早停机制(Early Stopping)和自动学习率调度,你不需要手动实现!
但你需要正确设置参数来激活并优化这些功能。
patience 参数说明(最重要!)
- 默认值:Ultralytics 默认
patience=100(v8.2+ 版本) - 推荐设置:
- 小数据集 / 快速实验:
patience=20~30 - 正常训练:
patience=50 - 追求极致性能:
patience=100
- 小数据集 / 快速实验:
- 你的例子:你设了
epochs=400,但实际很可能不需要这么多轮。配合patience=50,可能训练到 150 轮就自动停了。
✅ 建议:把
patience明确写出来,不要依赖默认值。
二、完整推荐训练代码(带早停)
from ultralytics import YOLOif __name__ == '__main__':# Load a pretrained YOLOv8 model (e.g., yolo11n.pt)model = YOLO('yolo11n.pt')# Train the model with early stoppingresults = model.train(data='data/data.yaml', # 数据配置文件epochs=400, # 最大训练轮数(早停会提前停止)patience=50, # ⭐ 早停耐心值:连续50轮没提升就停imgsz=640, # 图像尺寸batch=64, # batch sizeworkers=8, # 数据加载线程数device=0, # 使用GPU(0表示第一块GPU)project='runs/train', # 保存项目目录name='exp', # 实验名称exist_ok=False, # 防止覆盖已有实验optimizer='AdamW', # 可选优化器lr0=0.001, # 初始学习率amp=True, # 自动混合精度(加速训练))print("✅ Training completed. Best model saved automatically.")✅ 三、Ultralytics 早停机制的细节
| 特性 | 说明 |
|---|---|
| 📊 监控指标 | 默认监控 val/box_loss(边界框损失),也可以是 metrics/mAP50-95 |
| ⏸️ 自动停止 | 当指标连续 patience 轮没改善时,自动停止 |
| 💾 自动保存最佳权重 | 最佳模型已自动保存,文件为 runs/train/exp/weights/best.pt |
| 📈 最终模型 | 训练结束后,模型权重是 最佳 epoch 的权重,不是最后一轮的! |
✅ 所以你不需要手动加载 best.pt,Ultralytics 在训练结束时已经恢复了最佳权重。
✅ 四、如何判断是否过拟合?
训练过程中会生成日志和图表,重点关注:
train/box_lossvsval/box_loss- 如果
train一直下降,但val开始上升 → 过拟合 - 此时早停会自动干预
- 如果
metrics/mAP50或mAP50-95- 验证集上的精度是否还在提升?
你可以在训练结束后打开:
runs/train/exp/results.csv # 所有指标
runs/train/exp/results.png # 自动绘制的曲线图(关键!)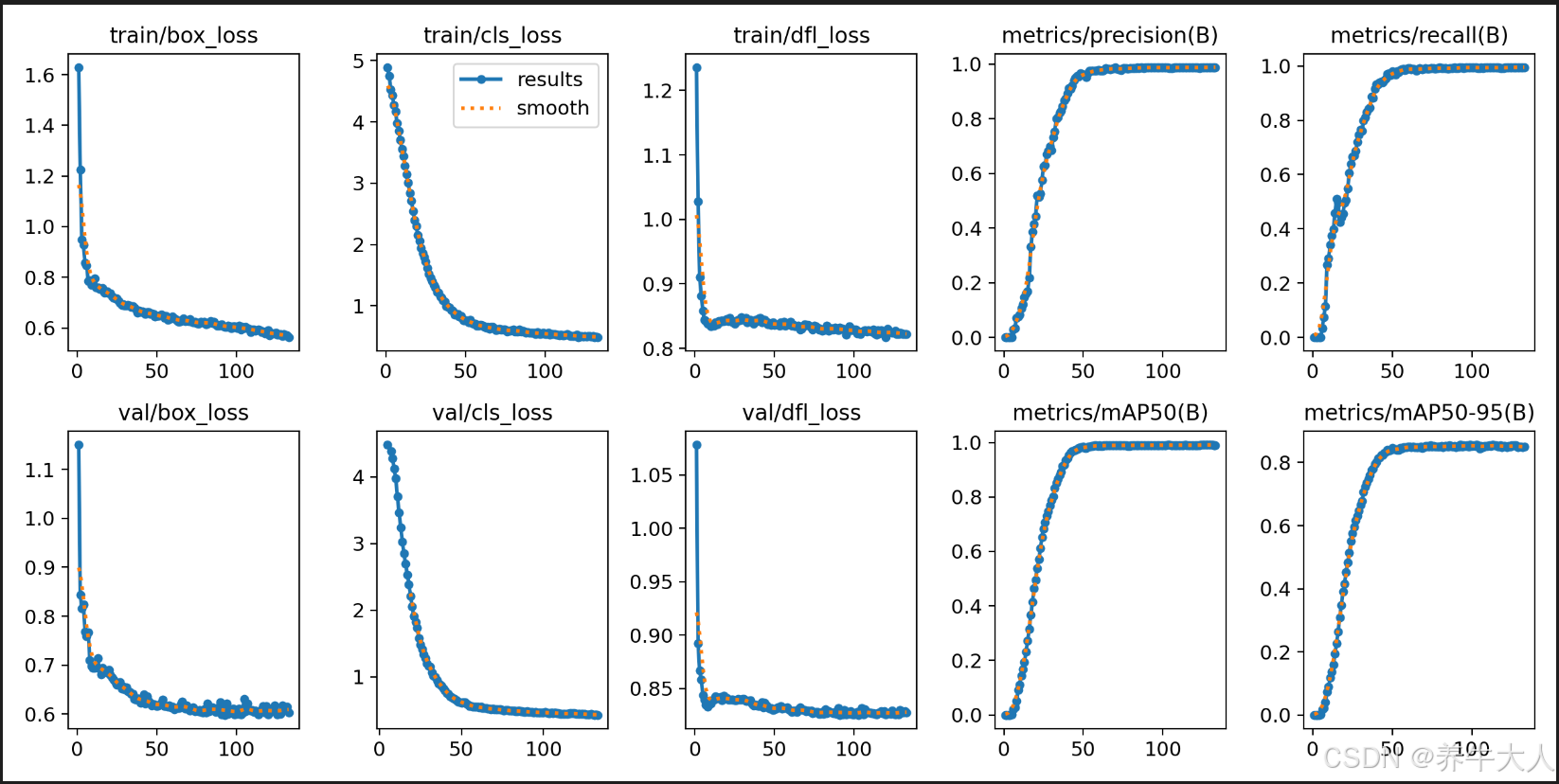
✅ 五、建议参数总结
| 参数 | 推荐值 | 说明 |
|---|---|---|
epochs | 300~500 | 设大一点,靠早停控制实际训练轮数 |
patience | 30~50 | 小模型可小,大模型可大 |
batch | 64 | 根据显存调整 |
imgsz | 640 | 常用尺寸 |
amp | True | 混合精度,提速省显存 |
optimizer | 'AdamW' | 通常比 SGD 更稳定 |