【笔记ing】大模型算法架构
前言
随着人工智能技术的飞速发展,大模型算法及其架构已成为推动科技前沿的重要力量。它们不仅能够处理海量的数据,还具备强大的表征学习能力,能够应对日益复杂的场景需求。本章节将介绍大模型算法及其架构,带您了解其背后的原理、技术创新以及在实际应用中的广阔前景。
目标
学完本课程后,您将能够:
掌握transformer架构和计算流程
了解transformer优化点
掌握FlashAttention、PagedAttention
了解GLM、LLaMA模型结构
目录
1.深度学习算法发展及瓶颈
2.Transformer详解
3.Transformer中的问题及优化方式
4.大语言模型架构介绍
5.多模态大模型架构介绍
6.MoE结构介绍
1.深度学习算法发展及瓶颈
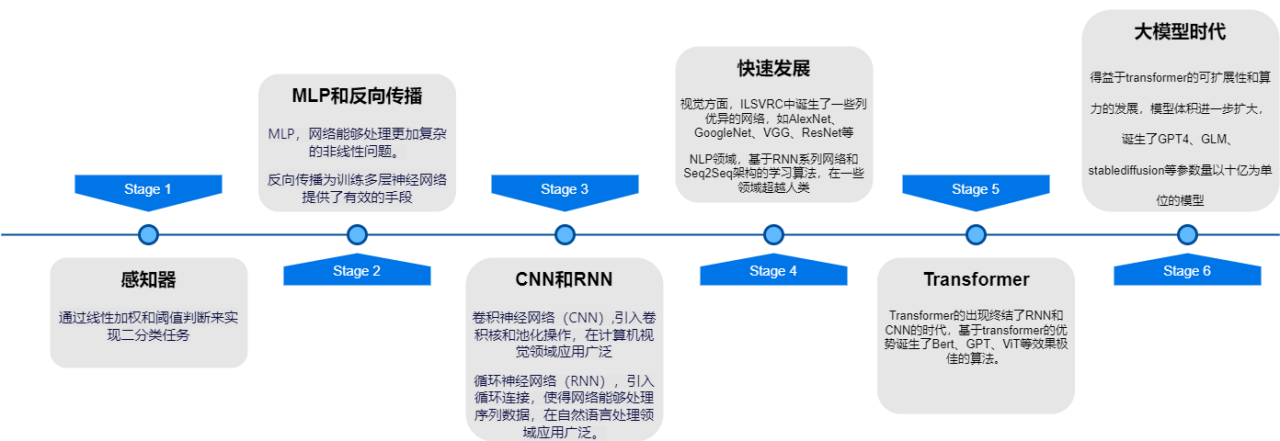
深度学习发展历程
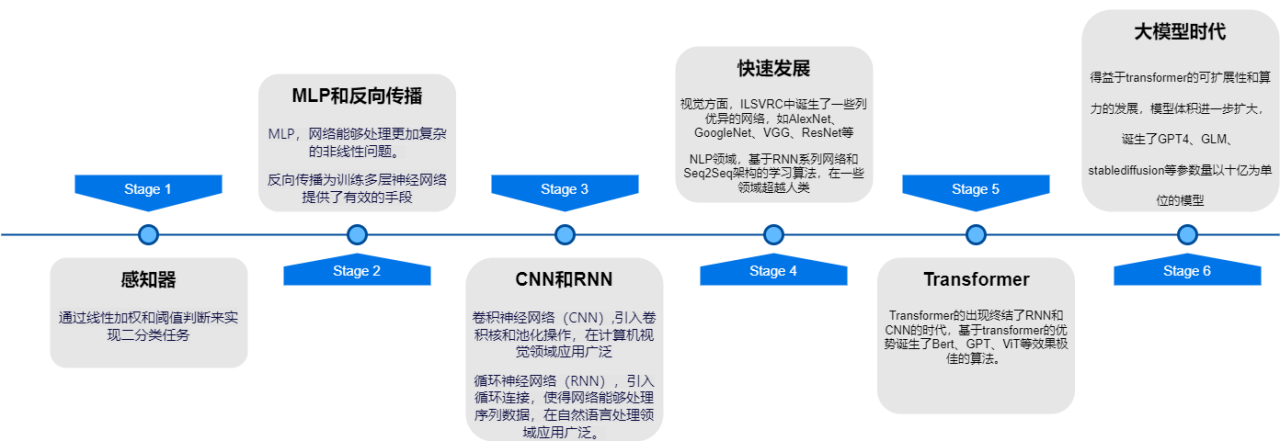
1957年感知器的出现到ILSVRC中诞生的一系列网络,深度学习从简单的二分类到部分领域超越人类。
stage1
感知器
通过线性加权和阈值判断来实现二分类任务
stage2
MLP和反向传播
MLP,网络能够处理更加复杂的非线性问题。
反向传播,为训练多层神经网络提供了有效的手段
stage3
CNN和RNN
CNN卷积神经网络,引入卷积核和池化操作,在计算机视觉领域应用广泛
RNN循环神经网络,引入循环连接,使得网络能够处理序列数据,在自然语言处理领域应用广泛。
stage4
快速发展
视觉方面,ILSVRC中诞生了一系列优异的网络,如AlexNet、GoogleNet、VGG、ResNet等
NLP领域,基于RNN系列网络和Seq2Seq结构的学习算法,在一些领域超越人类
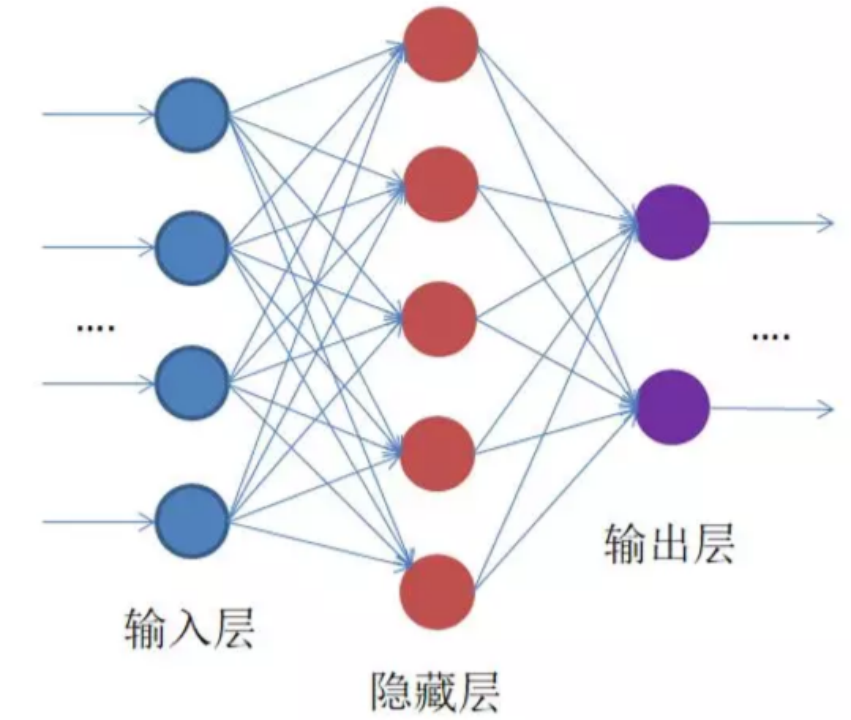
典型神经网络单元
DNN
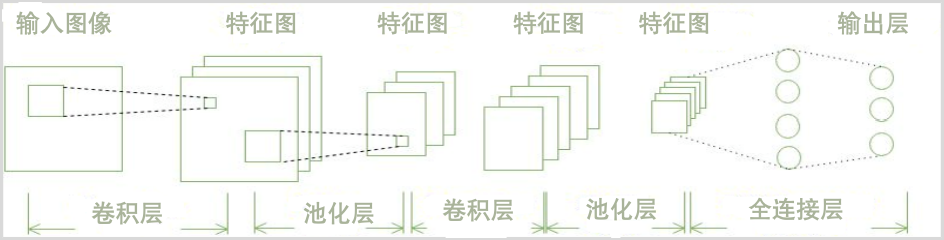
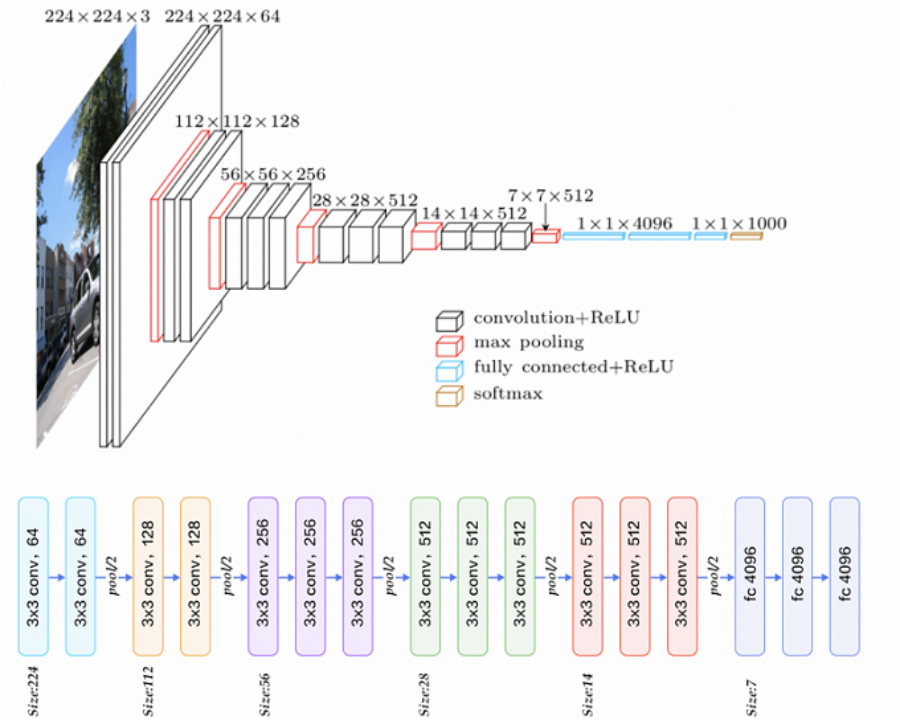
CNN
卷积神经网络 Convolutional Neural Network
是一种专门用于图像处理的神经网络,它可以自动提取图像中的特征,从而实现图像分类、目标检测等任务。
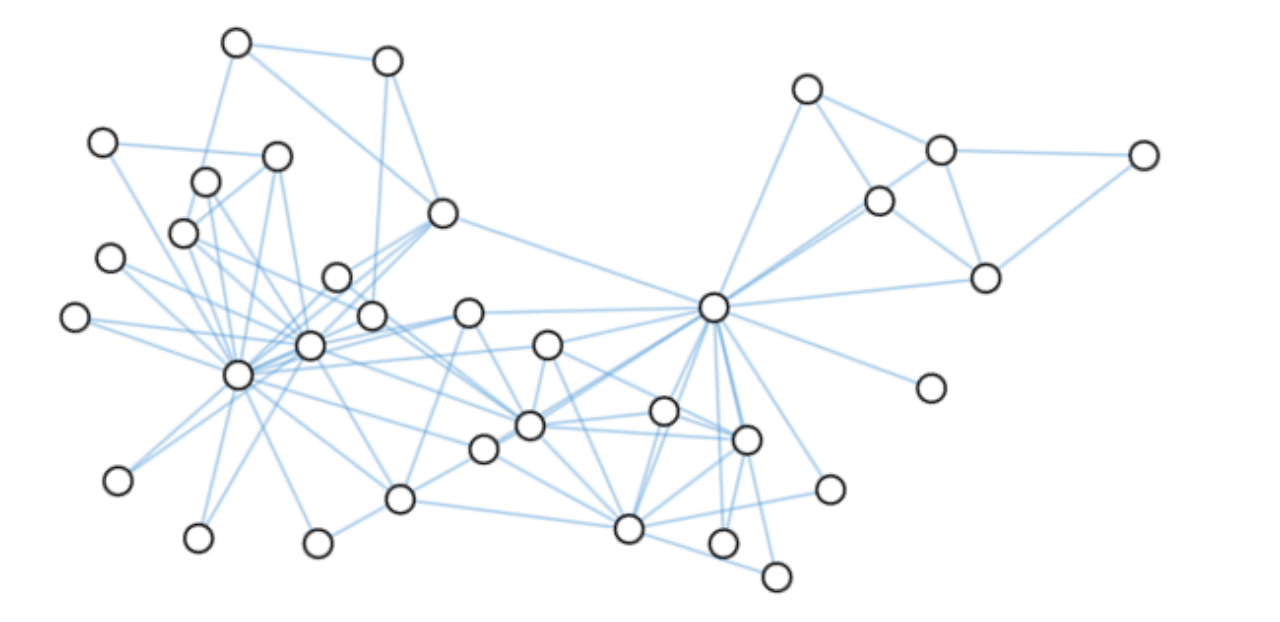
GNN
图神经网络 Graph Neuron Network
是一种用于处理图形数据的神经网络模型。它可以对图形数据进行分类、聚类、预测等任务。图神经网络在社交网络分析、化学分析分析、推荐系统等领域有广泛的应用。
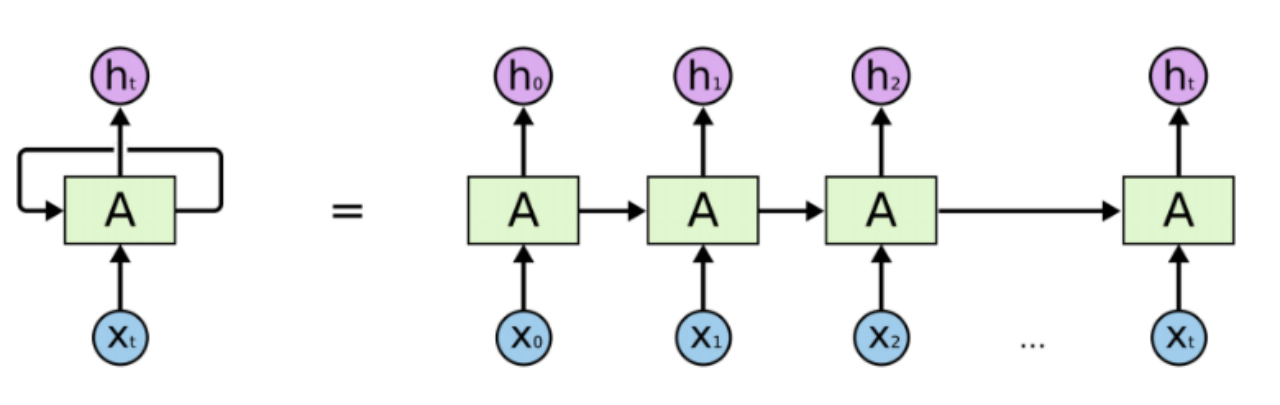
RNN
循环神经网络 Recurrent Neural Network
循环神经网络是一种可以处理序列数据的神经网络,它可以自动学习序列中的规律和模式,从而实现语音识别、自然语言处理等任务。
典型网络结构
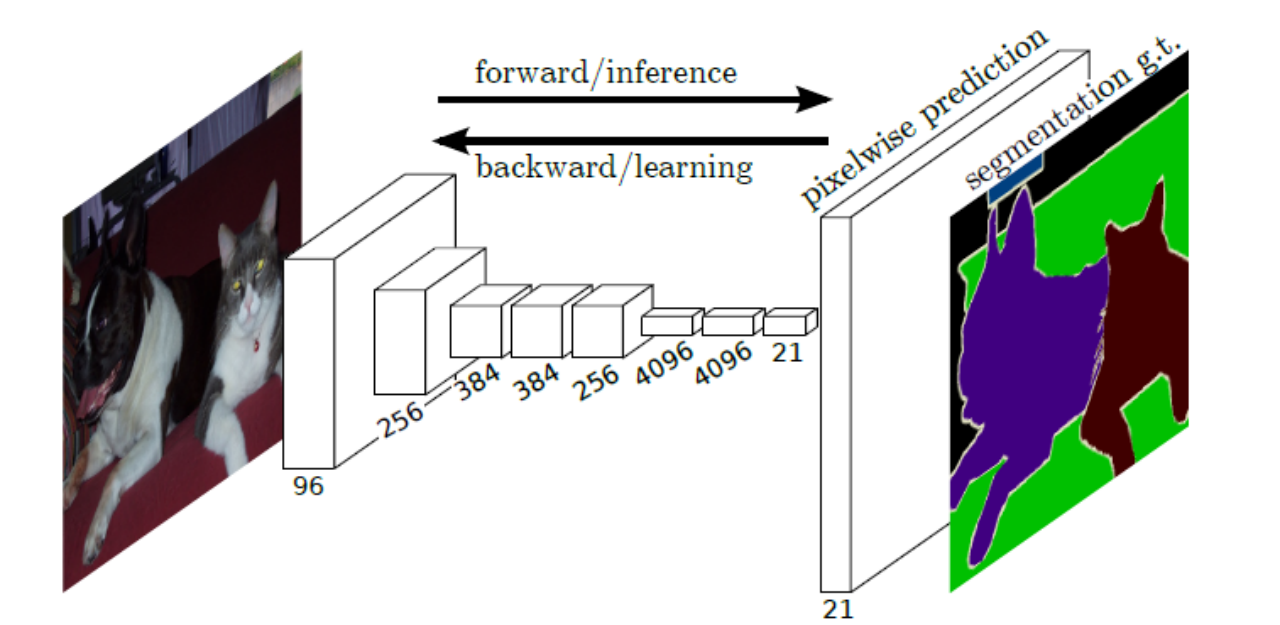
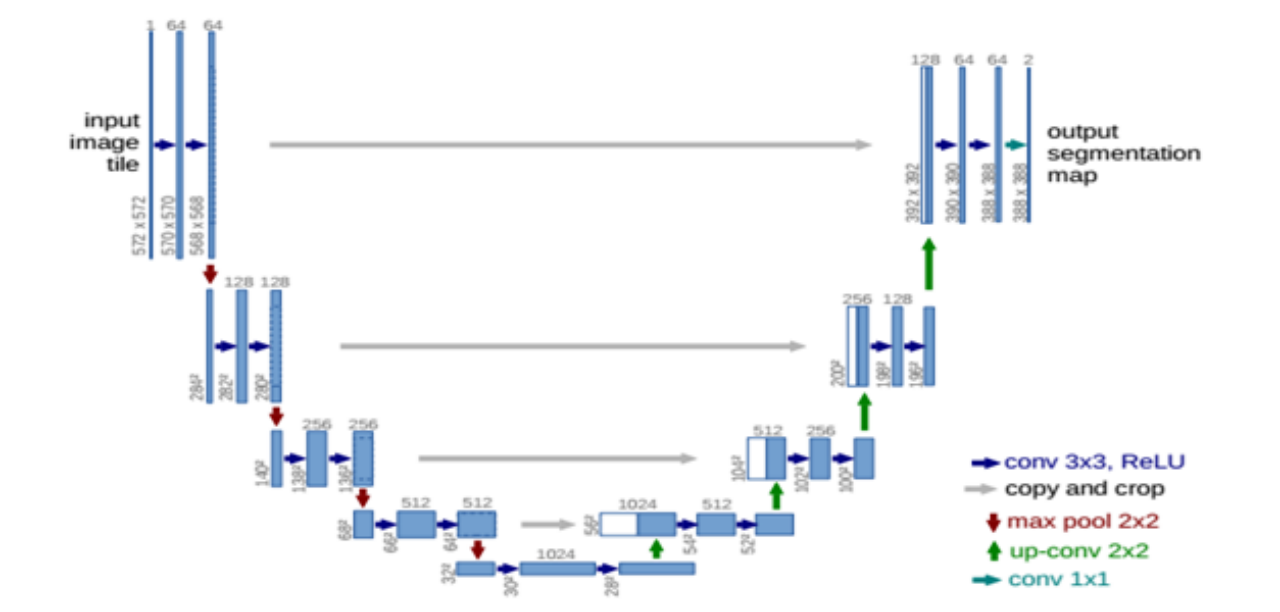
基于CNN、RNN等基础结构诞生的诸多学习算法,如FCN、VGG、GoogleNet等在一些特定领域效果极佳,甚至可以超越人类。
批注:
传统深度学习诞生了很多效果很好的模型结构,如:VGG、Unet、GAN、ResNet等。
大模型阶段
随着计算能力的提升和数据量的增长,训练更大更深的神经网络成为了可能。以GPT系列、LLaMA、GLM等为代表的TRM架构大模型,通过海量的数据和计算资源,训练出了具有强大生成能力和泛化能力的模型。
这些模型不仅能够在单一任务上取得优异性能,还能够通过微调的方式,快速适应新的任务和数据。
stage5
Transformer
Transformer的出现终结了RNN和CNN的时代,基于transformer的优势诞生了Bert、GPT、ViT等效果极佳的算法。
stage6
得益于transformer的可扩展性和算力的发展,模型体积进一步扩大,诞生了GPT4、GLM、stablediffusion等参数量以十亿为单位的模型
思考
基于CNN、RNN的传统深度学习算法在某些(语音识别、图像分类、文本理解等)领域已经超过了人类,为何还要给予Transformer设计更大的模型?
为什么目前大模型都是TRM架构而不是CNN和RNN?
传统深度学习算法的问题
传统深度学习算法在某些领域已经超过了人类,但是依然存在诸多问题。
扩展性差
泛