人工智能-python-深度学习-过拟合与欠拟合:概念、判断与解决方法
文章目录
- 过拟合与欠拟合:概念、判断与解决方法
- 一、概念认知
- 1. 欠拟合(Underfitting)
- 2. 过拟合(Overfitting)
- 二、如何判断
- 三、解决欠拟合的方法
- 四、解决过拟合的方法
- 1. **L2 正则化(权重衰减)**
- 2. **L1 正则化**
- 3. **Dropout**
- 4. **数据增强**
- 五、总结
过拟合与欠拟合:概念、判断与解决方法
在机器学习和深度学习的训练过程中,模型的性能往往受限于过拟合和欠拟合问题。合理地识别和解决这两个问题,才能训练出泛化能力更强的模型。
一、概念认知
1. 欠拟合(Underfitting)
-
定义:模型过于简单,无法捕捉数据中的规律。
-
表现:在训练集和测试集上的准确率都很低。
-
原因:
- 模型复杂度过低(如用线性模型拟合非线性数据)。
- 特征不足,信息不够。
- 训练时间过短,未收敛。
2. 过拟合(Overfitting)
-
定义:模型过于复杂,把训练数据学“死记硬背”了,无法推广到新数据。
-
表现:训练集上表现很好,但测试集上效果差。
-
原因:
- 模型复杂度过高(层数太多、参数太多)。
- 训练集数据不足。
- 特征选择不合理,存在噪声。
二、如何判断
-
损失函数变化
- 训练误差低,验证误差高 → 过拟合。
- 训练误差和验证误差都高 → 欠拟合。
-
学习曲线
- 欠拟合:训练曲线和验证曲线都没有收敛。
- 过拟合:训练曲线下降快,但验证曲线提前上升。
三、解决欠拟合的方法
- 增加模型复杂度(加层、加神经元)。
- 提供更多特征。
- 训练更久(调整学习率和迭代次数)。
四、解决过拟合的方法
1. L2 正则化(权重衰减)
-
数学表示:
L=L0+λ∑iwi2L = L_{0} + \lambda \sum_{i} w_i^2 L=L0+λi∑wi2
-
梯度更新:
w←w−η(∇L0+2λw)w \leftarrow w - \eta (\nabla L_{0} + 2\lambda w) w←w−η(∇L0+2λw)
-
作用:让权重趋向于较小值,避免过大权重导致模型复杂化。
-
代码实现:
optimizer = torch.optim.SGD(model.parameters(), lr=0.01, weight_decay=1e-4)
2. L1 正则化
-
数学表示:
L=L0+λ∑i∣wi∣L = L_{0} + \lambda \sum_{i} |w_i| L=L0+λi∑∣wi∣
-
梯度更新:
w←w−η(∇L0+λ⋅sign(w))w \leftarrow w - \eta (\nabla L_{0} + \lambda \cdot \text{sign}(w)) w←w−η(∇L0+λ⋅sign(w))
-
特点:会使部分参数稀疏化(变为 0),具有特征选择的效果。
-
与 L2 对比:
- L1 更适合稀疏特征选择。
- L2 更适合防止过大权重。
-
代码实现(通过自定义正则化项实现):
l1_lambda = 0.001 l1_norm = sum(p.abs().sum() for p in model.parameters()) loss = loss_fn(outputs, targets) + l1_lambda * l1_norm
3. Dropout
-
原理:训练时随机丢弃部分神经元(权重设为 0),防止过度依赖某些特征。
-
影响:相当于集成多个子网络,提高泛化能力。
-
代码实现:
import torch.nn as nn model = nn.Sequential(nn.Linear(256, 128),nn.ReLU(),nn.Dropout(0.5), # 50% 概率丢弃nn.Linear(128, 10) )
4. 数据增强
通过人为扩大数据集,增加多样性,从而降低过拟合风险。
常见方法如下:
- 图片缩放:调整大小。
- 随机裁剪:模拟不同场景下的物体位置。
- 随机水平翻转:让模型学到对称特征。
- 调整图片颜色:亮度、对比度、饱和度。
- 随机旋转:增加旋转不变性。
- 图片转 Tensor:转为模型可用的张量。
- Tensor 转图片:便于可视化。
- 归一化:加速训练,提升稳定性。
整合示例:
import torchvision.transforms as transformstransform = transforms.Compose([transforms.RandomResizedCrop(224),transforms.RandomHorizontalFlip(),transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1),transforms.RandomRotation(15),transforms.ToTensor(),transforms.Normalize(mean=[0.5,0.5,0.5], std=[0.5,0.5,0.5])
])
五、总结
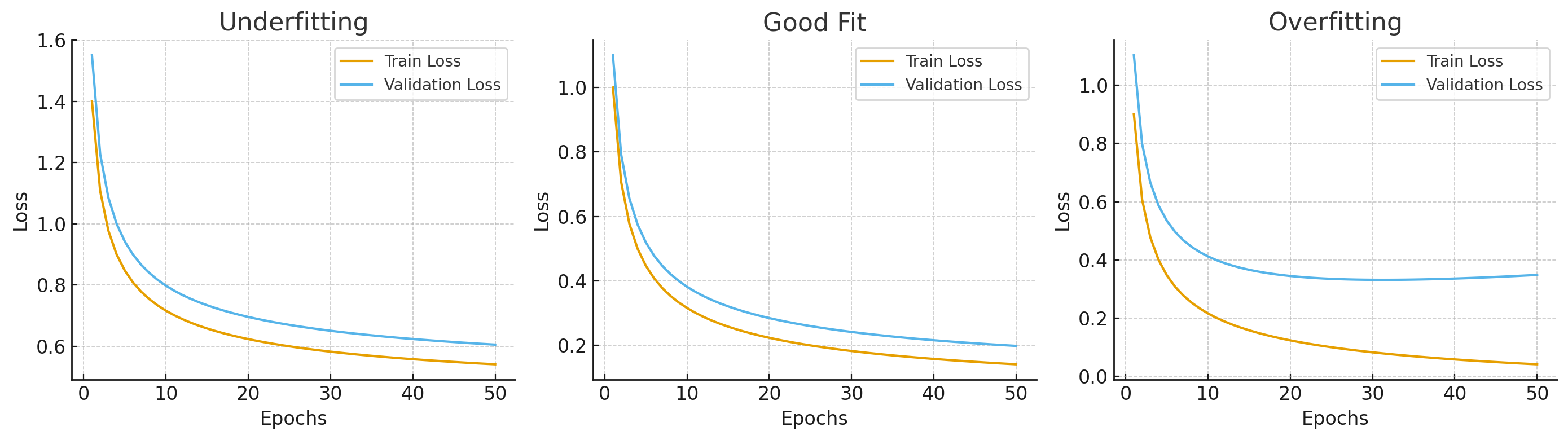
这是一个 欠拟合、合适拟合和过拟合的损失曲线对比图 📊:
欠拟合:训练集和验证集 loss 都较高,下降也不明显。
合适拟合:训练 loss 持续下降,验证 loss 下降后趋于稳定。
过拟合:训练 loss 下降很快,但验证 loss 出现反弹。
- 欠拟合:模型太简单,训练不足 → 解决方法:增加复杂度、更多特征、训练更久。
- 过拟合:模型记住了训练集 → 解决方法:正则化、Dropout、数据增强。
- 结果导向:所有这些方法的目的,都是提高模型的泛化能力,即让模型不仅能在训练集上表现好,也能在未知数据上保持较高精度。
要不要我帮你把这篇文章整理成 Markdown 表格 + 图示(比如过拟合与欠拟合的损失曲线对比图),这样发到 CSDN 会更直观?