数据对话的“通用语法”:SQL与KingbaseES的智能处理艺术
引言
翻手机银行的近三月账单,指尖轻轻一滑——后台早已为你结过账;挂号台递出就诊单,数据库像老派书记官,干净利落地落下时间戳与经手人;闸机“滴”的一声,清分与结算不声不响地启动,像接力赛的下一棒。你可能从未亲自敲过一行 SQL,却已被这张语义织成的网稳稳托住。工具?不止。它更像一门维持秩序的语言,一套可执行的契约。
在这门语言的剧场里,KingbaseES(下文简称 KES)更像一位会多种腔调的调音师:同一把钥匙,既能通译,又能调校,还能加速——锋利,也克制。一条看似普通的查询,究竟如何跋涉到“结果”的彼岸?不同“方言”的 SQL,为什么在 KES 里能同台共舞,跑得顺、也跑得久?别急。先摸清这门语言的骨和皮,再看它的步法、路线与耐力。

文章目录
- 引言
- 一、读懂 SQL:不仅是“查几条”,更是数据世界的语法范式
- 1.1 四类“基本功”:结构、操作、事务、安全
- 1.2 “方言陷阱”:迁移路上的隐形高墙
- 二、SQL 的“旅程”:一句话,如何抵达结果?
- 2.1 语法解析:先把话“翻译清楚”
- 2.2 语义分析:再确认“话有无意义”
- 2.3 查询优化:走哪条路更快?
- 2.4 执行与返回:把结果“递到你手里”
- 三、KingbaseES的“破局之道”:兼容、加速、守护
- 3.1 多语法兼容:说得来,跑得动
- 3.1.1 主流特性“即插即用”
- 3.1.2 迁移评估与建议:看得见、改得少
- 3.2 智能优化:越跑越聪明
- 3.2.1 记路、荐路、诊路
- 3.2.2 慢SQL画像:把凶手拉到聚光灯下
- 3.3 高效执行:高并发的动力引擎
- 3.3.1 并行执行:把重活拆给多人
- 3.3.2 高可用:不中断,才叫稳
- 四、工具链:从编写到运维,少走弯路
- 4.1 KStudio:SQL 的“智能笔”
- 4.2 KEMCC:SQL 的“监控仪”
- 五、行业实证:把“纸上的好看”落到地上
- 5.1 能源:国家电网的高频SQL调度
- 5.2 医疗:解放军总医院的快与安
- 六、结语:当 SQL“长出智能”,数据库不再只是数据库
一、读懂 SQL:不仅是“查几条”,更是数据世界的语法范式
很多人提到 SQL,会条件反射地想起那句熟悉的 SELECT * FROM 表名。没错,但太单薄。到了企业级现场,它像一部“语法宪章”:定义数据长什么样,划定谁能动它、怎么动,确保每一次操作都有边界、有后果、有审计痕迹。银行转账、电网调度、航旅清结算——这份可依赖,靠的是规则被一遍遍严肃执行。短句能落地,体系才耐久;长句撑起的是秩序的骨架。
1.1 四类“基本功”:结构、操作、事务、安全
围绕数据的一生,SQL常以四种能力现身,像四根支柱,少一根都不稳。
-
- 数据定义(DDL):给世界搭骨架
定义表、索引、约束等元数据,明确字段类型与边界。示例:
-- 创建银行客户表:形状与纪律同时上线 CREATE TABLE bank_customer (customer_id VARCHAR(18) PRIMARY KEY, -- 主键:身份证号,唯一且可索引customer_name VARCHAR(50) NOT NULL, -- 姓名不可为空balance DECIMAL(10,2) CHECK (balance >= 0), -- 余额必须为非负数create_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP -- 默认写入创建时间 );结构演进期用
ALTER TABLE做“微整形”,避免“大拆大建”。 - 数据定义(DDL):给世界搭骨架
-
- 数据操作(DML):对记录动真格
插入、更新、删除、查询,承载最繁忙的业务路径:
-- 1) 新增订单 INSERT INTO orders (order_id, user_id, goods_id, amount) VALUES ('ORD20250825001', 'USER123', 'GOODS456', 299.00);-- 2) 扣减库存 UPDATE goods SET stock = stock - 1 WHERE goods_id = 'GOODS456';-- 3) 查询用户订单 SELECT order_id, amount, create_time FROM orders WHERE user_id = 'USER123'AND create_time >= '2025-08-01';朴素?是的。却足以支撑绝大多数日常交易的进出与回声。
- 数据操作(DML):对记录动真格
-
- 事务控制(TCL):把边界“焊死”
多条语句拧成一个原子单元:要么都成功,要么一起回滚。
BEGIN; -- 开启事务 UPDATE bank_customer SET balance = balance - 1000 WHERE customer_id = '110101199001011234';UPDATE bank_customer SET balance = balance + 1000 WHERE customer_id = '110101199001015678';COMMIT; -- 全成则提交;遇异常即 ROLLBACK在金融与医疗等场景,ACID 不是口号,是硬阈值。越界?不行。
- 事务控制(TCL):把边界“焊死”
-
- 数据控制(DCL):让权限像“闸门”那样精确
对象级、操作级授权与回收,贯彻“最小权限”。还要留痕、可追溯。
-- 医生可查、可改病历 GRANT SELECT, UPDATE ON medical_record TO doctor_role;-- 患者仅能查看自己的病历(策略示意) GRANT SELECT ON medical_record TO patient_role WITH CHECK OPTION (patient_id = CURRENT_USER);-- 实习医生不具备修改权 REVOKE UPDATE ON medical_record FROM intern_role;风险前置拦截,越权就停在门外;审计链路,则把门后发生过什么说清楚。
- 数据控制(DCL):让权限像“闸门”那样精确
1.2 “方言陷阱”:迁移路上的隐形高墙
SQL 有标准(SQL-92、SQL:2003……),也有方言:Oracle 的 PL/SQL,MySQL 的 LIMIT,SQL Server 的 TOP。这没毛病,一旦迁移,问题就从脚注跳到了扉页。比如:
-- Oracle 风格:用 CONNECT BY 递归部门树
SELECT dept_id, dept_name, parent_dept
FROM department
START WITH parent_dept = 0
CONNECT BY PRIOR dept_id = parent_dept;
换到不兼容的引擎?往往只能重写,或另起策略。若系统里塞满了存储过程与触发器,改动的“粘性成本”会迅速抬升——像带着浓重乡音远行,句句磕绊,团队的节奏被硬生生拖慢。何况还有函数语义差异、日期处理习惯、分页语法、并行执行提示等细碎差别在暗处使绊子。迁移这件事,从来不只是“跑起来”,还是“跑得对、跑得久”。
二、SQL 的“旅程”:一句话,如何抵达结果?
在 APP 里点“查账单”,系统不是直冲磁盘。SQL 会经历四道工序,像原料单走入精密工厂。每一步,都可能决定速度与正确。
2.1 语法解析:先把话“翻译清楚”
第一关是语法检查。解析器像挑剔的老师:拼写、结构、关键字顺序,一样不放过。SELEC * FROM orders?报错。过关后,语句被转为抽象语法树(AST),一种对机器更友好的结构化表示。
此刻只看“说得顺不顺”,不问“后厨有没有这道菜”。
2.2 语义分析:再确认“话有无意义”
字段在不在?类型对不对?权限给没给?这一步着眼“事实语义”。例如:
-- 语义分析会检查两点:
-- 1) goods表存在否 2) price字段是否为数值类型
UPDATE goods SET price = 'abc' WHERE goods_id = 'GOODS123';
若 price 为数值类型,却写入字符串“abc”,会被即时拦截。像是确认你点的不是“盐水咖啡”,且你确实能付钱。
2.3 查询优化:走哪条路更快?
同一条查询,路径可能成倍差异。全表扫描?索引寻道?连接顺序谁先谁后?优化器根据代价模型(Cost Model)、基数估计(Cardinality Estimation)选择执行计划。例如“找 2025年8月金额>1000 的订单”,若存在 create_time + amount 组合索引,直奔索引显然更经济。
更巧妙的是,KES 的优化器会“临机应变”:高峰时段,某些索引热点拥挤,成本动态上升,计划可能切换;低峰再回归原道。像导航应用遇见拥堵,临时绕路。
2.4 执行与返回:把结果“递到你手里”
执行引擎拿到计划,开始动作:访问页缓存、读取磁盘、做过滤、排序、连接、聚合,最后组装成结果。例如:
SELECT order_id, amount, create_time
FROM orders
WHERE create_time >= '2025-08-01'
ORDER BY create_time DESC
LIMIT 10;
结果往往以JSON等友好格式返还前端。若是写入类操作,还会同步写入事务日志,保障断电可恢复。这是可靠性的保险丝。
三、KingbaseES的“破局之道”:兼容、加速、守护
两个难题:方言兼容与执行效率。KES的答案是“三位一体”:通译多语法、智能化优化、高可用执行。翻译者、向导、卫士,三角稳如磐石。
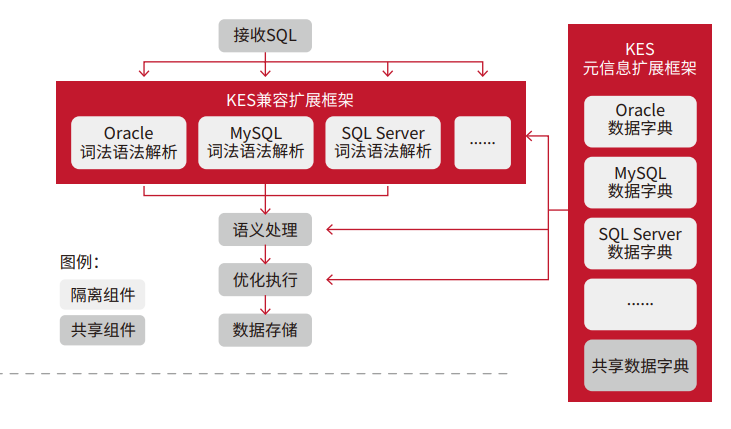
3.1 多语法兼容:说得来,跑得动
KES 以“多语法体系一体化”架构,对 Oracle、MySQL、SQL Server 等主流方言直接兼容。迁移时,代码改动量往往极小。
3.1.1 主流特性“即插即用”
-
Oracle 兼容:覆盖
CONNECT BY、PL/SQL、MERGE等特性:-- Oracle 风格:存在则更新,不存在则插入 MERGE INTO bank_customer t1 USING (SELECT '110101199001011234' AS customer_id,'张三' AS customer_name,5000.00 AS balanceFROM DUAL ) t2 ON (t1.customer_id = t2.customer_id) WHEN MATCHED THENUPDATE SET t1.customer_name = t2.customer_name, t1.balance = t2.balance WHEN NOT MATCHED THENINSERT (customer_id, customer_name, balance)VALUES (t2.customer_id, t2.customer_name, t2.balance);某头部基金公司迁移 60TB 数据,
PL/SQL基本“零修改”上线,周期至少砍半。 -
MySQL 兼容:支持
LIMIT、LOAD DATA INFILE等:-- MySQL 风格:分页取第 2 页,每页 10 条 SELECT goods_id, goods_name, price FROM goods WHERE category = 'electronics' ORDER BY sales DESC LIMIT 10 OFFSET 10;迁移后分页逻辑可顺滑复用。
-
SQL Server 兼容:支持
TOP、IDENTITY:-- SQL Server 风格:取前 5 条最新公告 SELECT TOP 5 notice_id, title, publish_time FROM government_notice ORDER BY publish_time DESC;政务常见写法,无需改造。
3.1.2 迁移评估与建议:看得见、改得少
借助 KDMS(数据库迁移评估系统),可批量扫描存量 SQL,生成兼容性报告与改写建议。比如 Oracle 中常见的隐式转换:
-- Oracle 允许 '123' 与 123 隐式比较
SELECT * FROM orders WHERE order_id = 123456;
报告会建议显式化:将 123456 改为 '123456'。在实际项目中,SQL 改动量常低于 0.5%。厚书翻译,润色几处标点——成本差异就出来了。
3.2 智能优化:越跑越聪明
优化器不只“选路”,还“学路”。KES V9 2025版在代价模型之外,引入 AI 加持与执行画像。
3.2.1 记路、荐路、诊路
- 记路:记录时段化性能特征。早高峰索引热、低峰顺序扫描更合算?动态切换。
- 荐路:基于热SQL模式给出索引建议。例如频繁按
user_id + create_time检索订单,系统主动提示创建组合索引idx_order_user_time,预计提速 30%。 - 诊路:对“变慢”的SQL给出因果剖析。索引失效?锁等待?统计信息过期?系统能指出症结并给出修复建议(如重建
idx_order_time,刷新统计)。
某三甲医院的“病历查询”从 1.2s 降至 0.3s,就源于这类建议的落地。
3.2.2 慢SQL画像:把凶手拉到聚光灯下
KWR(自动负载信息库)记录执行快照:耗时、等待事件(I/O or CPU)、扫描行数、返回行数等。KDDM(性能诊断报告)在此基础上产出体检式分析。
例如某直辖市高法“司法统计”延迟 15s,报告定位为“全表扫描导致I/O过高”,建议添加 idx_case_date。优化后降至 0.8s。证据充分,行动明确。
3.3 高效执行:高并发的动力引擎
优化只是计划书;执行引擎才是工地上的吊车、分拣与流水线。
3.3.1 并行执行:把重活拆给多人
对超大表的聚合与批量更新,KES能将扫描分片、任务拆分,提升吞吐:
-- 并行查询示意:按并行度4执行
SELECT COUNT(*)
FROM orders
WHERE create_time BETWEEN '2025-01-01' AND '2025-08-01'
PARALLEL 4; -- 并行度
某石油企业统计半年度数据,5分钟缩短到30秒。并行度,不是噱头,是杠杆。
3.3.2 高可用:不中断,才叫稳
关键行业的关键词是“不断”。KES 以主备集群实现 RPO=0(零数据丢失)、RTO<5s(快速切换):
- 主库实时将日志流复制至备库,保持强一致;
- 故障触发时,备库自动接管,业务无感。
在人民银行征信中心的“异构双中心双活”架构中,即使一地失效,SQL仍在另一中心稳态运行——数据零丢失,流程不掉线。
四、工具链:从编写到运维,少走弯路
KES不仅让SQL“能跑”,还给你一套趁手的工具,从研发到运维闭环加速。
4.1 KStudio:SQL 的“智能笔”
- 智能提示:从
SELECT到WHERE字段类型,光标一移,提示即至; - 过程调试:
PL/SQL断点、单步执行、变量观察,像调试程序一样调试存储过程; - 可视化建模:点点鼠标,自动生成SQL。
某软件团队反馈:写SQL效率提升约40%,过程调试从“几小时”降到“十几分钟”。
4.2 KEMCC:SQL 的“监控仪”
- 实时画像:QPS、响应时间、时段波峰一眼可见;
- 自动告警:阈值越线,邮件/短信即时推送;
- 长期洞察:最耗时SQL、最高频SQL榜单,优化方向一目了然。
某运营商借此提前发现“设备状态查询”因索引失效带来的迟滞,及时修复,避开高峰拥堵。
五、行业实证:把“纸上的好看”落到地上
5.1 能源:国家电网的高频SQL调度
单表 1443 列、70万行在10秒内更新,1000+ 并发连接同时在线。KES的组合拳——
- 原 Oracle
PL/SQL兼容复用,几乎不改动; - 对大表更新进行源码级优化,全表更新从若干秒级降到 3 秒左右;
- 主备集群兜底高可用。
现已在 26 省部署稳定运行。每次调度,都是SQL与引擎的协作演出。

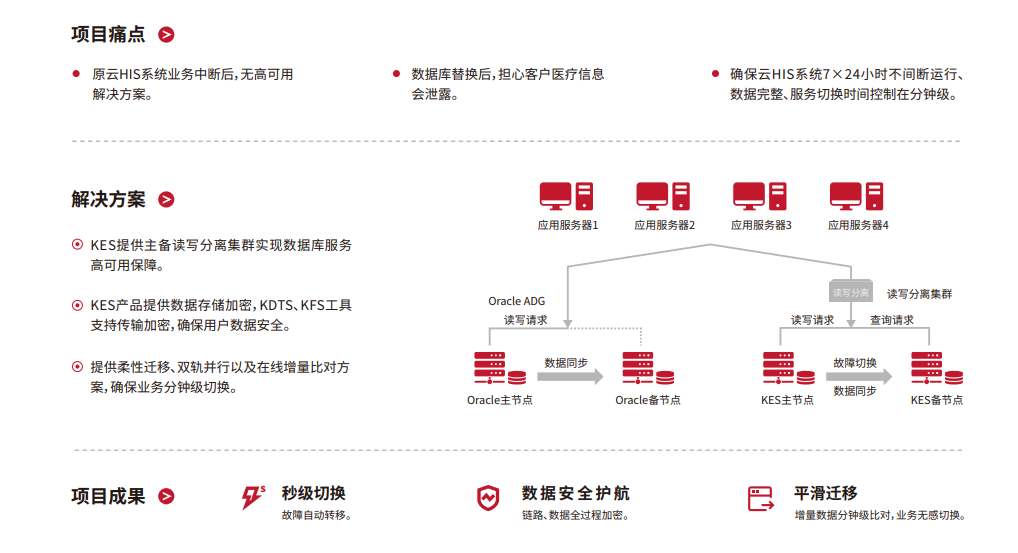
5.2 医疗:解放军总医院的快与安
云HIS场景要两头兼顾:速度与安全。KES实践路线:
- 读写分离:写入走主库,查询走只读节点,压力分摊;
- 全链路加密:传输与存储采用国密算法,截获也看不懂;
- 秒级切换:主库故障,备库在5秒内接棒。
就诊高峰,病历查询仍可毫秒级返回——医患不等待,流程不打结。
六、结语:当 SQL“长出智能”,数据库不再只是数据库
SQL 不会“老去”,它会“升级”。也许不久,你只说一句“给我近一周订单”,系统便生成高质量 SQL,自主挑选最佳路径;优化器按场景自调并行度、择索引、避热点——像老练的调度师。
KES 的职责,是把这种“智能”从概念变成日常:按钮可按、数据可证、效果可复盘。
二十余年打磨,中电科金仓把“把 SQL 处理好”当铁律:方言兼容、智能优化、高可用集群,一个不缺。
归根到底,一个组织的 SQL 处理力,就是它的数据竞争力。现在把问题递回去——你的 SQL,跑得快吗?
