【每天一个知识点】大模型训推一体机
一、定义
大模型训推一体机是专门面向 大规模预训练模型(LLM/多模态模型) 的一体化算力设备,整合了 高性能训练 与 高并发推理 两大功能,通常结合专用 AI 芯片和软硬件平台,目标是让企业或研究机构在本地快速完成大模型从训练到应用的全流程。
二、关键特点
算力强大
配备 多颗高端 GPU(如 NVIDIA H100/A800)或国产 NPU(昇腾910B、寒武纪 MLU 等)。
高速互联(NVLink/PCIe 5.0/100G IB 网络)。
支持 百亿—千亿参数规模大模型 训练与微调。
存储与数据IO优化
高速 NVMe SSD + 分布式存储架构。
针对大模型的 流水线并行 / 张量并行 / 数据并行 提供调度支持。
训推一体
训练:支持大模型预训练、微调(Fine-tuning)、增量学习。
推理:内置推理加速引擎(TensorRT、MindSpore Serving、DeepSpeed-Inference),支持 低时延、高并发、分布式推理。
模型优化:量化、蒸馏、剪枝,降低推理成本。
管理与安全
一体化管理平台(集群调度、监控、容器化)。
信创国产化适配(鲲鹏/飞腾 CPU,麒麟/UOS 系统)。
等保/国密支持,满足政企安全需求。
三、典型应用场景
企业大模型:政企/能源/金融行业的专属大模型部署。
科研与教育:高校科研团队用于 LLM 训练与教学。
行业应用:
智能客服(语音/文本)
工业巡检(大模型+多模态)
医疗诊断(影像+文本)
知识库问答(企业知识大模型)
四、厂商产品参考
华为 Atlas 900 大模型一体机:昇腾910B + MindSpore,全栈国产化。
浪潮 AI&LLM 一体机:支持 Megatron-LM、DeepSpeed,预置 LLM 微调框架。
NVIDIA DGX H100 SuperPOD:国际主流方案,支持 GPT/多模态模型。
曙光/联想 AI 超算一体机:适配政企大模型落地。
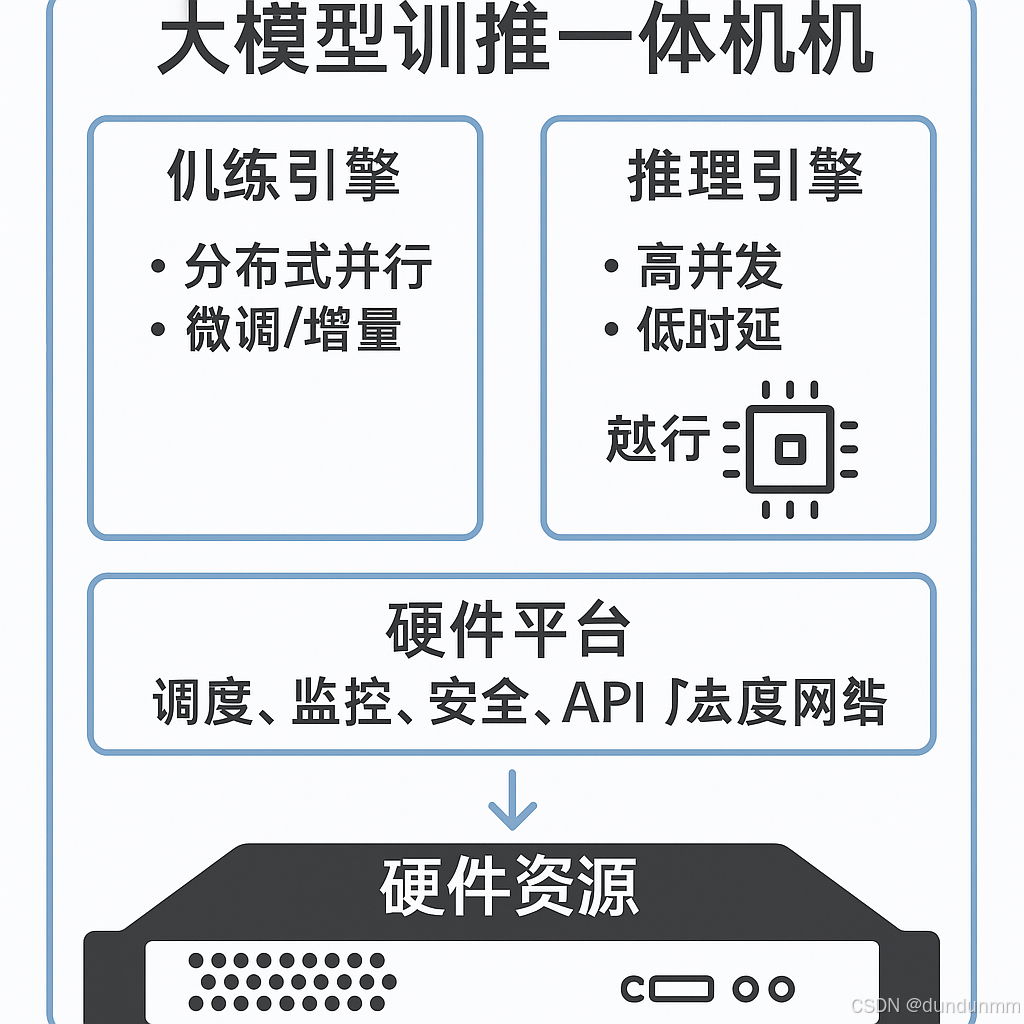
五、架构示意(逻辑)
┌───────────────────────────────┐│ 大模型训推一体机 ││ ││ ┌───────────────┐ ┌──────┐ ││ │ 训练引擎 │ │ 推理引擎 │ ││ │ - 分布式并行 │ │ - 高并发 │ ││ │ - 微调/增量 │ │ - 低时延 │ ││ └───────────────┘ └──────┘ ││ │ 管理平台 │ ││ ┌──────────────────────────┐ ││ │ 调度、监控、安全、API发布 │ ││ └──────────────────────────┘ ││ │ 硬件资源 │ ││ CPU/GPU/NPU + NVMe + 高速网络 │└───────────────────────────────┘