MySQL/Kafka数据集成同步,增量同步及全量同步
业务库(MySQL)的数据要同步到数仓(HDFS),每天定时跑任务,实时业务(如订单Binlog)需要立刻同步到分析平台(Kafka),
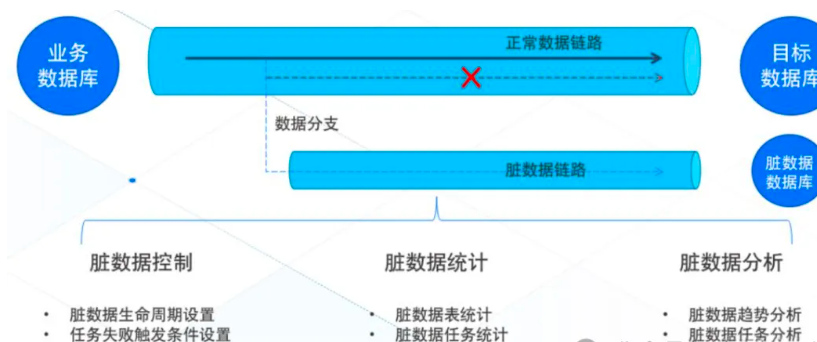
传统的数据集成工具往往存在批流分离,技术栈复杂(需同时维护Flink、Spark、Sqoop等)
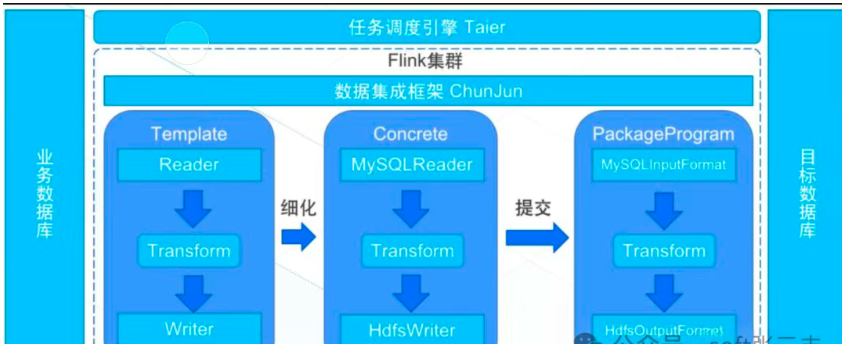
同时支持批处理(静态数据)和流处理(实时数据),一套架构搞定全场景同步,还能降低开发和运维难度,基于Apache Flink工具——ChunJun(原FlinkX)
ChunJun(原名FlinkX)是一款基于Apache Flink的易用、稳定、高效的批流一体数据集成工具,它的核心目标是解决“不同数据源之间数据同步和计算”的难题,尤其擅长处理静态数据(如MySQL、HDFS)和实时变化数据(如Binlog、Kafka)的采集与同步
- 批处理模式(静态数据):定时或一次性同步MySQL、Oracle等数据库的数据到HDFS、Hive等数仓,适合T+1报表、离线分析场景;
- 流处理模式(实时数据):实时捕获Binlog(数据库变更日志)、Kafka消息流等动态数据,同步到下游分析平台(如实时数仓、大屏展示),适合实时监控、风控等场景;
- 批流一体:同一套代码/配置,既能跑批任务又能跑流任务,无需为批和流分别开发维护两套系统。
1. 静态数据源(离线批处理)
- 数据库:MySQL、Oracle、PostgreSQL、SQL Server等关系型数据库;
- 大数据存储:HDFS、Hive、HBase等离线存储系统;
- 同步模式:全量同步(一次性拉取全部数据)、增量同步(基于时间戳/自增ID同步新增数据)、定时任务(如每天凌晨同步一次)。
2. 实时数据源(流式处理)
- 变更数据捕获(CDC):通过监听MySQL/Oracle的Binlog,实时获取表数据的增删改操作(如订单状态从“待支付”变为“已支付”);
- 消息队列:Kafka、RocketMQ等实时消息流(如用户行为日志、IoT设备数据);
- 同步模式:持续监听数据变化并实时同步到下游(如实时数仓、实时计算引擎Flink/Spark Streaming)
支持单一数据源的读写,还能实现多源之间的数据转换与同步(如MySQL数据清洗后写入Hive,或Kafka消息聚合后存入HBase
常见的关系型数据库(MySQL/Oracle)、大数据存储(HDFS/Hive)、实时消息队列(Kafka)、NoSQL(HBase)等,无需额外开发即可快速对

对比维度 | ChunJun(基于Flink的批流一体工具) | DataX(阿里开源离线工具) | Sqoop(Hadoop生态批处理) | Kafka Connect(实时消息集成) | Flink CDC(仅CDC同步) |
|---|---|---|---|---|---|
| 批流支持 | 批流一体(一套架构搞定批+流) | 仅离线批处理 | 仅离线批处理 | 仅实时流处理 | 仅CDC实时同步(需额外开发流任务) |
| 实时性 | 支持Binlog/Kafka实时同步 | 延迟高(小时/天级) | 延迟高(小时/天级) | 实时性高但仅限消息队列 | 实时性好但功能较单一 |
| 数据源覆盖 | 30+种(含数据库/数仓/消息队列) | 主流数据库+HDFS | Hadoop生态为主 | Kafka/RocketMQ等消息队列 | MySQL/Oracle等数据库CDC |
| 功能扩展性 | 基于Flink,可自定义算子与逻辑 | 扩展需修改源码 | 扩展依赖Hadoop生态 | 依赖Connector插件 | 需自行封装流处理逻辑 |
| 精确一次语义 | 支持(Flink Checkpoint机制) | 不支持 | 不支持 | 部分支持 | 部分支持 |
| 易用性 | JSON配置+低代码算子 | 脚本配置但功能固定 | 命令行参数复杂 | 需配置Connector | 需Flink开发经验 |
数据仓库团队:需要将MySQL/Oracle等业务库的数据定时同步到HDFS/Hive,构建离线数仓(T+1报表);
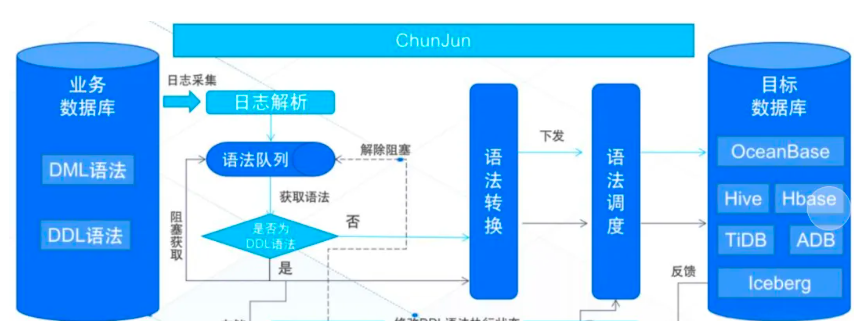
- 实时计算团队:需要监听数据库Binlog或Kafka消息流,实时同步到Flink/Spark Streaming进行风控、大屏展示;
- 大数据平台运维:需要一套工具同时管理批处理和流处理任务,降低运维复杂度;
- 国产化替代场景:兼容国产数据库(如OceanBase、TiDB)和大数据组件(如Hadoop生态),满足信创需求。
ChunJun凭借基于Flink的批流一体架构、丰富的连接器、高可靠性能与低代码易用性