低开高走的典例:DeepSeek V3.1于8月19日晚更新:128K 上下文击败 Claude 4 Opus
继 3 月推出 V3-0324 版本后,DeepSeek 于 8 月 19 日正式上线线上模型 V3.1,不仅将上下文窗口翻倍至 128K(可处理 30 万字连续文本),还在编程测试中击败 Claude 4 Opus。此次更新,可以被视作 “对 GPT5 的有力回应” 。

网传 8 月下旬发布的 R2 版本并未如期而至,一向 “无重大突破不推新版本” 的 DeepSeek,此次 V3.1 究竟是 “诚意升级” 还是 “过渡之作”?
一、更新背景:低调迭代,澄清 R2 传闻
1.版本定位
此次 V3.1 是 3 月 V3-0324 后的常规迭代,并非网传的 “R2 版本”,官方暂未提及 R2 发布计划,延续了 DeepSeek“无关键突破不轻易推新阶段版本(如 R 系列)” 的低调风格。
2.行业排名
更新后,DeepSeek V3.1 已在 Hugging Face(HF)相关榜单中位列第四,非推理模型在 Aider Polyglot 测试中以 71.6% 的得分击败 Claude 4 Opus,成为当前表现最佳的 “非 TTC 编码模型”。
二、V3.1 五大核心突破:从长文本到性价比全面升级
1. 上下文窗口翻倍至 128K,长文本处理能力跃升
V3.1 将上下文窗口从 64K 扩展至 128K,可处理长达 30 万字的连续文本,彻底解决了前代 “长文档需分段处理” 的痛点。给大家举个例子,在面对数万行代码的项目的时候,模型能完整理解代码逻辑并生成精准优化建议,无需频繁中断上下文;还有分析企业年报、学术论文等长文本时,信息连贯性较旧版提升显著。
2. 编程与物理理解能力双突破
编程效率提升 40%:生成网页开发代码时,完成度与美观性大幅优化 —— 如生成的个人博客网站,不仅包含完整 HTML/CSS 框架,还能自动适配响应式布局,减少开发者二次修改成本。
物理规律模拟更精准:在模拟小球弹跳等物理现象时,可精准计算重力、摩擦系数等参数,生成符合真实物理规律的动态效果,较前代模型的 “粗略模拟” 有明显进步。
小球
3. Aider Polyglot 测试击败 Claude 4 Opus
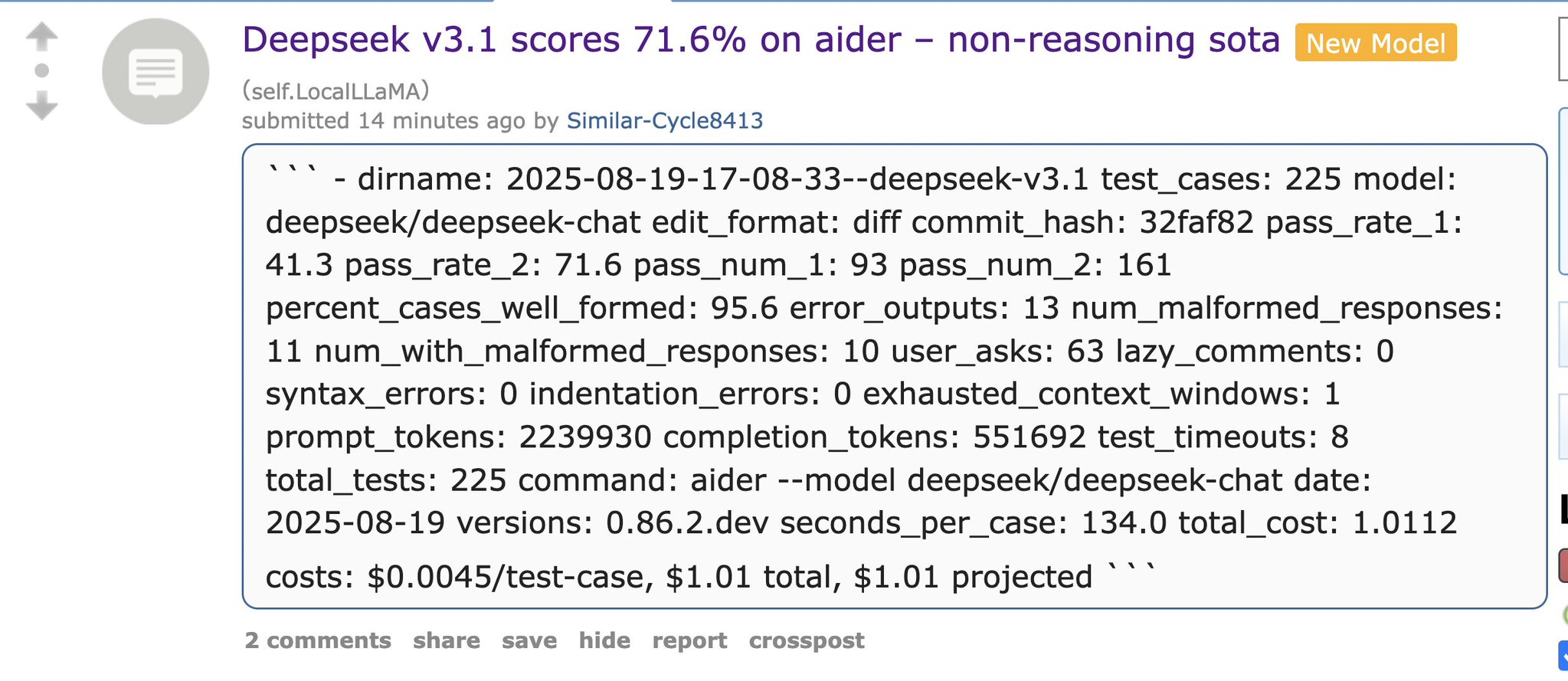
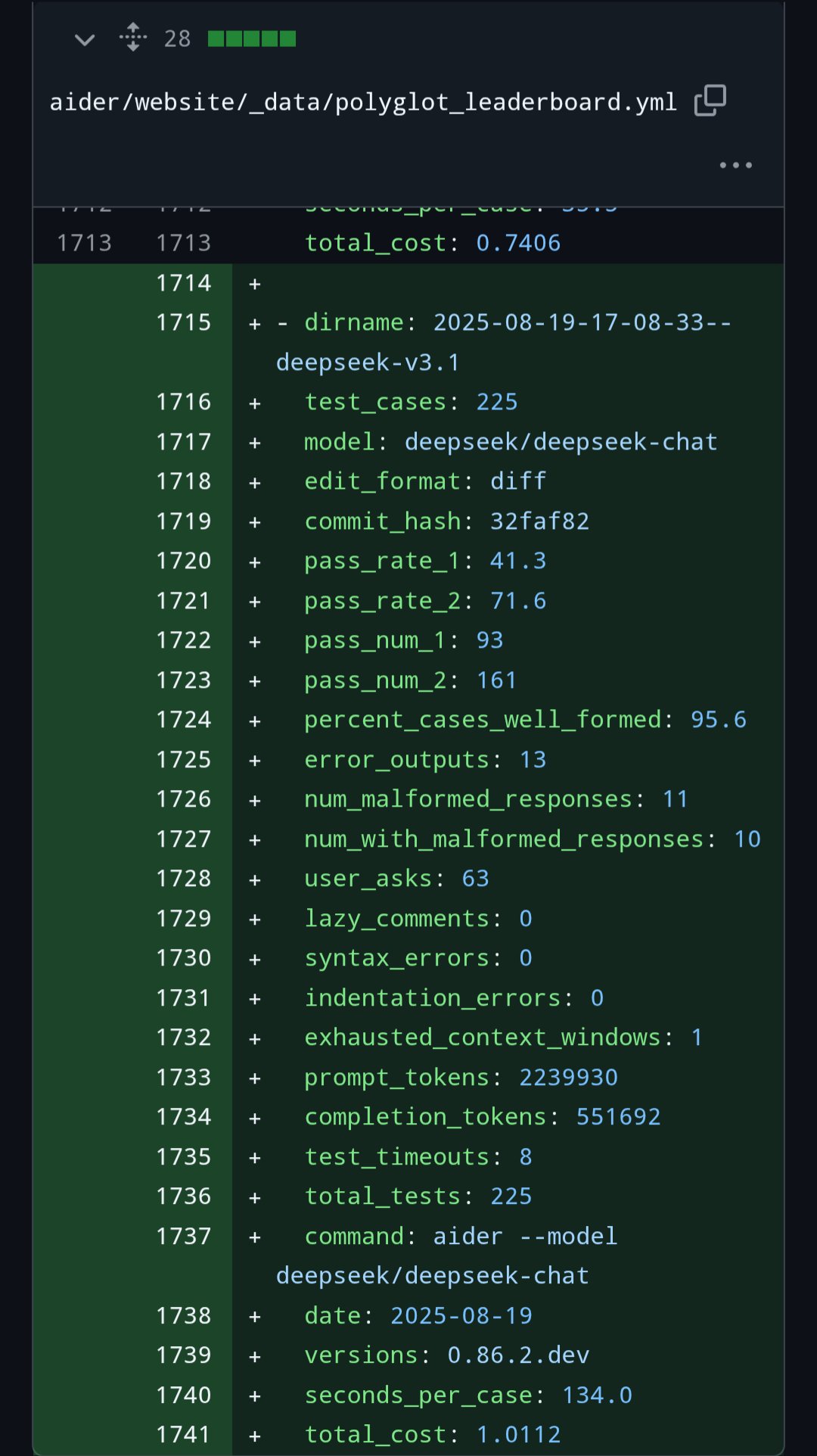
根据 HF 社区测试数据,V3.1 在 225 个测试案例中,第二阶段通过率(pass_rate_2)达 71.6%,击败 Claude 4 Opus,且测试总成本仅1.01美元,性价比优势显著。测试中未出现语法错误、缩进错误,95.6% 的输出格式规范,仅 1 例出现上下文窗口耗尽问题。
4. 性价比碾压竞品,Agent 性能接近 Claude 4 Opus
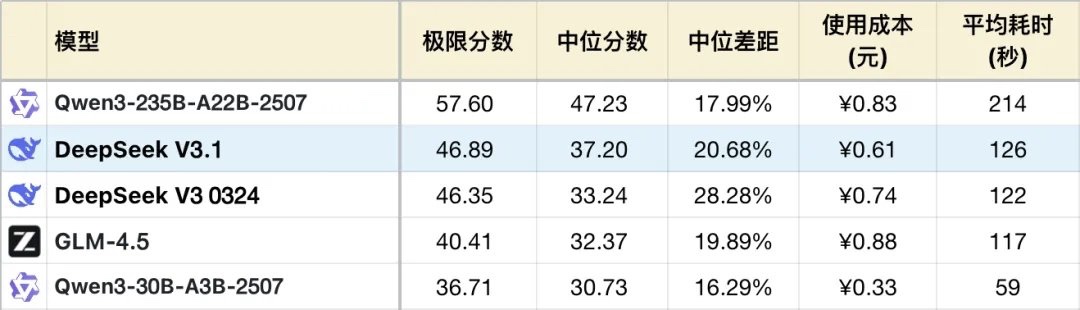
使用成本更低:对比其他主流模型,V3.1 的 token 使用率更低,平均单测试案例成本约 0.0045 美元,仅为 Claude 4 Opus 的 1/50。
Agent 能力跃升:在深度网络信息检索(DeepResearch)、智能体(Agent)搭建等场景中,性能已接近 Claude 4 Opus,可满足企业级自动化任务需求。
5. 交互体验更人性化
V3.1 摒弃了 “机械说教” 式回答,采用 “口语化 + 情境化” 表达:解释技术概念时先以生活案例引入(如用 “心有灵犀的双胞胎” 类比量子纠缠),再逐步展开专业分析;同时避免绝对化结论,以 “端水式” 回答增强可读性,降低非专业用户理解门槛。
三、不容忽视的三大短板
1.中英夹杂问题,增加阅读成本
长文本输出时频繁出现 “单词级语言切换”,例如技术分析中突然插入 “具体实现请参考 GitHub repository 中的 README.md”,代码注释里混杂英文表述(如 “Please refer to the official documentation for API details”),导致上下文连贯性断裂,尤其给非英文背景开发者带来困扰。
2.复杂场景 “幻觉” 依旧严重
生成虚假信息(“幻觉”)的问题未得到解决:处理年报总结时,关键财务数据提取错误率较高,甚至虚构未披露的业务数据;在魔方旋转、代码逻辑推导等需大量中间数据的任务中,幻觉率较 V3-0324 版本反而上升。
3.仍不支持图像识别
作为国内头部大模型,V3.1 至今未实现图像识别功能 —— 国内多数主流模型已支持图片解析,而 V3.1 仅能处理文本、文档(TXT、PDF、PPT 等),无法解析技术图纸、电路图等图形信息,多模态能力存在明显短板。
四、用户评论
上述为个人对DeepSeek V3.1的看法。个人认为有一点值得肯定的是,DeepSeek并不会耗费大量的时间精力在营销上, 此次更新,也仅仅只是在社群里发布通告,这也很符合“深度求索”的作风。反观,Open AI从过去的方方面面遥遥领先,到如今的GPT5被人吐糟继承了乔布斯的营销手段。Deepseek除了今年年头的R1高调出场以外,剩余更多的时间投入在性能提升上,个人也是非常期待R2的重磅登场。
接下来,是让我们看看网上对于此次V3.1更新的评价:
1.好评

2.差评

五、模型应用:V3.1+Agent
AI大模型的升级,也会推动Agent性能的提升,现在国内的智能体AiPy已经完成了DeepSeek V3.1的调试与商家,下载最新版本即可免费体验最新DeepSeek V3.1。
给大家列举几个Agent接入DeepSeek V3.1后的落地应用:
1.数据分析
输入 “分析 618 平板销售数据并生成带图表的报告”,可自动完成数据爬取、清洗、可视化,输出可交互 HTML 报告,耗时较传统方法缩短 80%。
2.自动化工具开发
生成 CTF 竞赛漏洞利用脚本时,能精准识别 SQL 注入点并生成攻击 Payload,成功率较旧版提升 35%。
3.智能招聘筛选
在 AIPy 中上传简历并输入 “筛选 Java 开发候选人”,V3.1 自动解析技能、经验并排序(支持多模态简历),满足快速筛选海量简历并匹配岗位需求。
4.法律合同分析
在 AIPy 中上传合同并输入 “分析违约责任”,V3.1 自动提取关键条款并生成风险报告,能够快速解析合同条款并识别风险点,将传统合同审查时间从 2 小时缩短至 15 分钟。
最后,DeepSeek V3.1 以 128K 上下文、低至 1/50 的成本、接近 Claude 4 Opus 的 Agent 能力,成为中小开发者和企业的高性价比选择,对于追求成本控制的用户,V3.1个人觉得值得一试。