自然语言处理的相关概念与问题
目录
一、学科的产生与发展
1、什么是自然语言?
2、自然语言处理技术的诞生
二、技术挑战
三、基本方法
1、方法概述
理性主义方法
经验主义方法
2、传统的统计学习方法
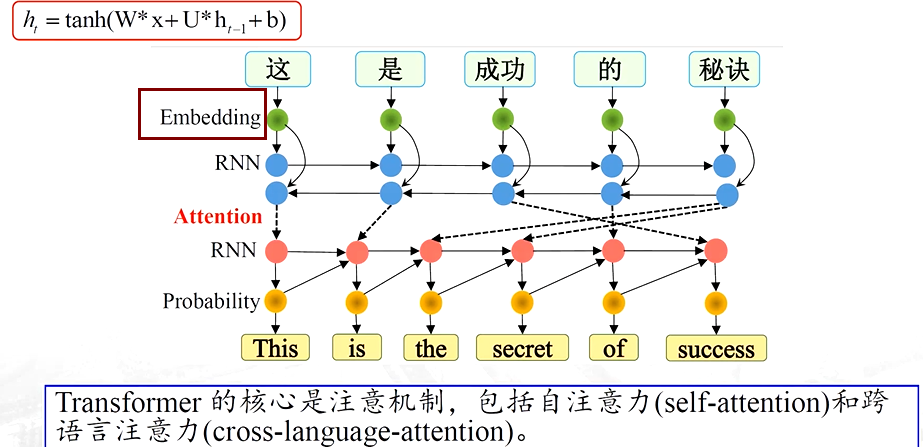
3、深度学习方法
词向量表示
词向量学习
开源工具
四、应用举例
1、汉语分词
(1)最大匹配法
(2)基于n-gram的分词方法
(3)由字构词的分词方法
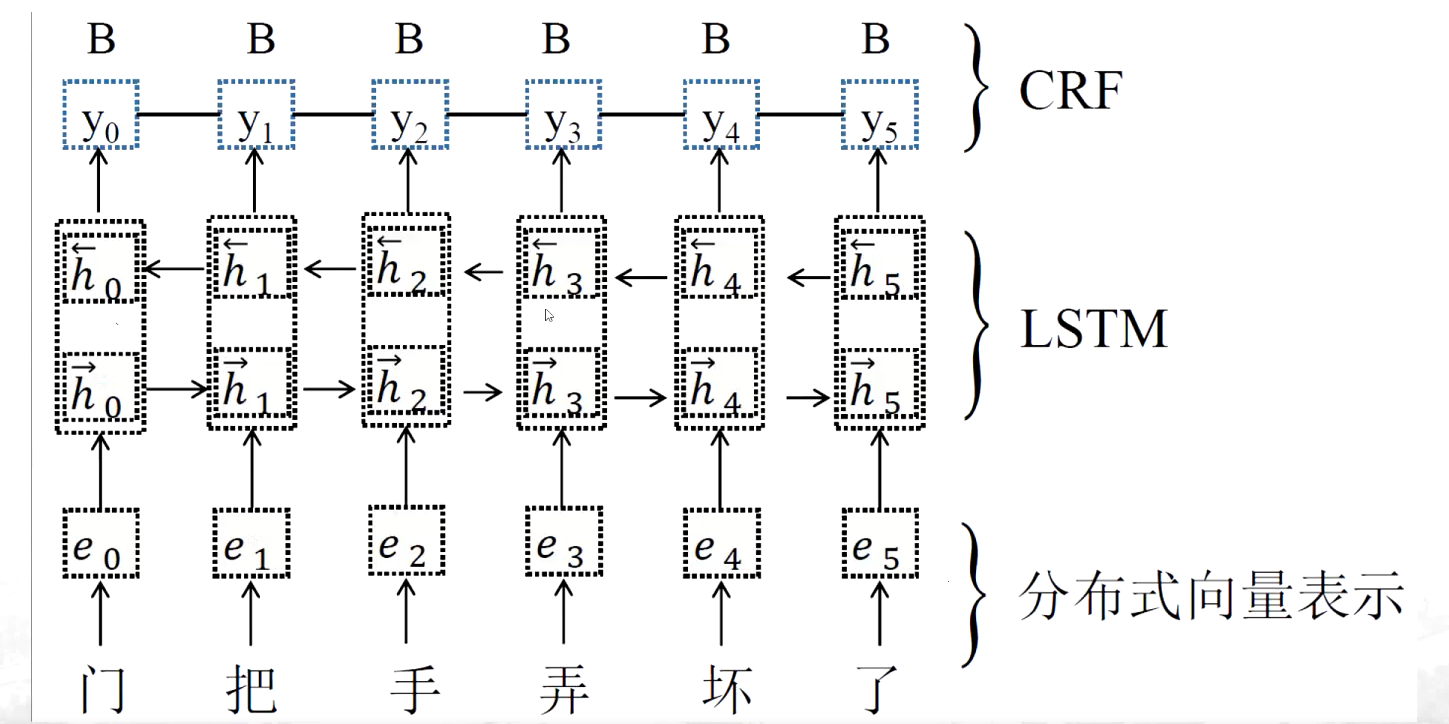
(4)基于神经网络的分词方法
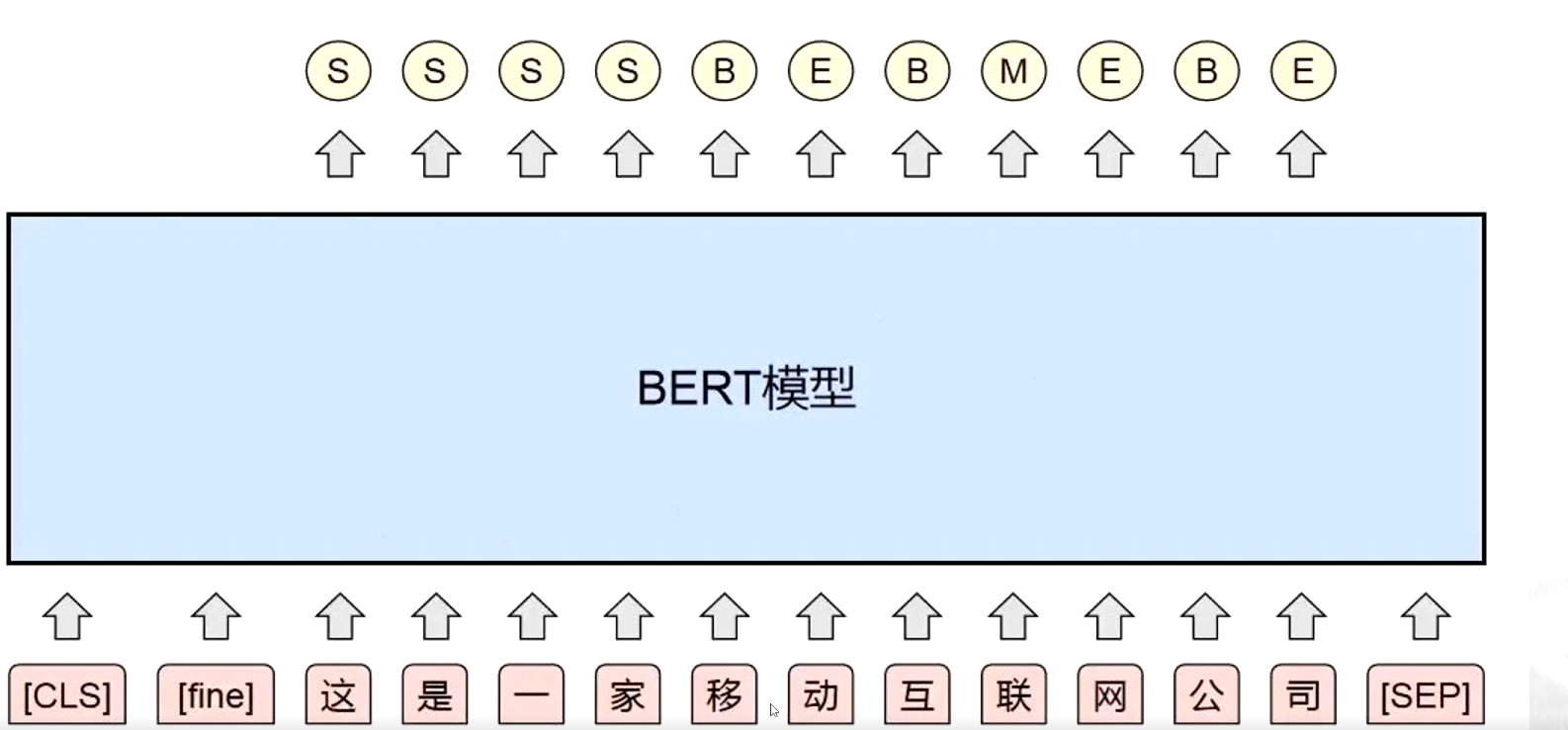
(5)基于预训练模型的分词方法
2、机器翻译【MT】
(1)基于模版的直接转换法
(2)基于规则的翻译方法
(3)基于中间语言的翻译方法
(4)基于语料库的翻译方法
统计机器翻译(SMT)
神经机器翻译方法
3、语音翻译/同声传译
五、技术现状
1、汉语自动分词技术现状
2、机器翻译译文的质量
3、做不到语言的深度理解,缺乏推理能力
书籍推荐
一、学科的产生与发展
1、什么是自然语言?
自然语言是人类社会发展过程中自然产生的语言,是最能体现人类智慧和文明的产物。
语言是思维的载体,是人类交流思想、表达感情最自然、最直接、最方便的工具;人类
历史上以语言文字形式记载和流传的知识站比达八成以上。
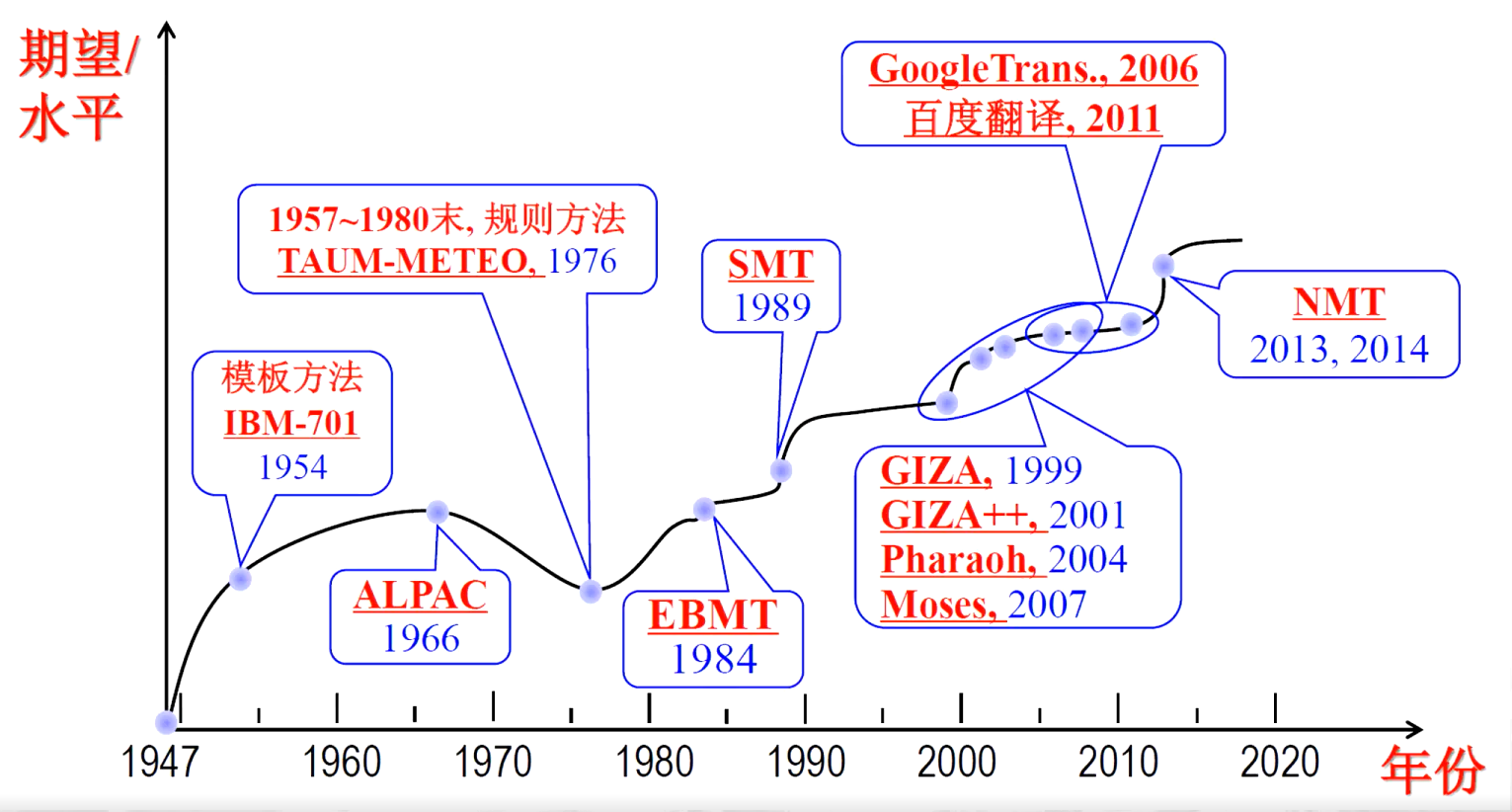
2、自然语言处理技术的诞生
- 自W. Weaver 和A.D.Booth 提出机器翻译概念后,美国和英国的学术界对机器翻译(machine translation,MT)产生了浓厚的兴趣,并得到了实业界的支持。

- 1954年Georgetown大学在IBM协助下,用IBM-701计算机实现了世界上第一个MI系统,实现俄译英翻译,1954年1月该系统在纽约公开演示。系统只有250条俄语词汇,6 条语法规则,可以翻译简单的俄语句子。
- 随后10 多年里,MT研究在国际上出现热潮。
- 1962年国际计算语言学学会(Association for Computational Linguistics,ACL)成立;
- 1965年国际计算语言学委员会(International Committee on Computational Linguistics,ICCL)成立。
- 1964年,美国科学院成立语言自动处理咨询委员会(AutomaticLanguage Processing Advisory
Committee,ALPAC),调查机器翻译的研究情况,于1966年11月公布了一个题为“语言与机器”的调查报告,简称ALPAC 报告,宣称:“在目前给机器翻译以大力支持还没有多少理由”
“机器翻译遇到了难以克服的语义障碍(semantic barrier)”。从此机器翻译研究在世界范围内进入低迷状态。计算语言学(computational linguistic)术语首次以正式身份出现在这个报告里。 - 1980S,随着计算机网络的快速发展和普及,以开发实用自然语言处理系统为目标的语言工程技术应运而生,自然语言处理(natural language processing,NLP)术语由此诞生
二、技术挑战
- 大量存在的未知语言现象如:高山、高升;吉林、武夷山、桂林、温泉、温馨、时光;虎蝇,埃博拉,奥特曼、闷骚 ;BoW,word2vec
- 无处不在的歧义词如:苹果、粉丝:bank,interest……;那辆白色的车是黑车/臭豆腐真香啊!
- 复杂或歧义结构比比皆是:喜欢乡下的孩子;上大学子烛光追思钱伟长;’“动物保护警察”明年上岗。。。。
- 普遍存在的隐喻表达:在微信圈里潜水;打铁还要自身硬;你简直是个木头脑袋;
- 对翻译而言,不同语言之间的概念不对等: 馒头 steamed bread
三、基本方法
1、方法概述

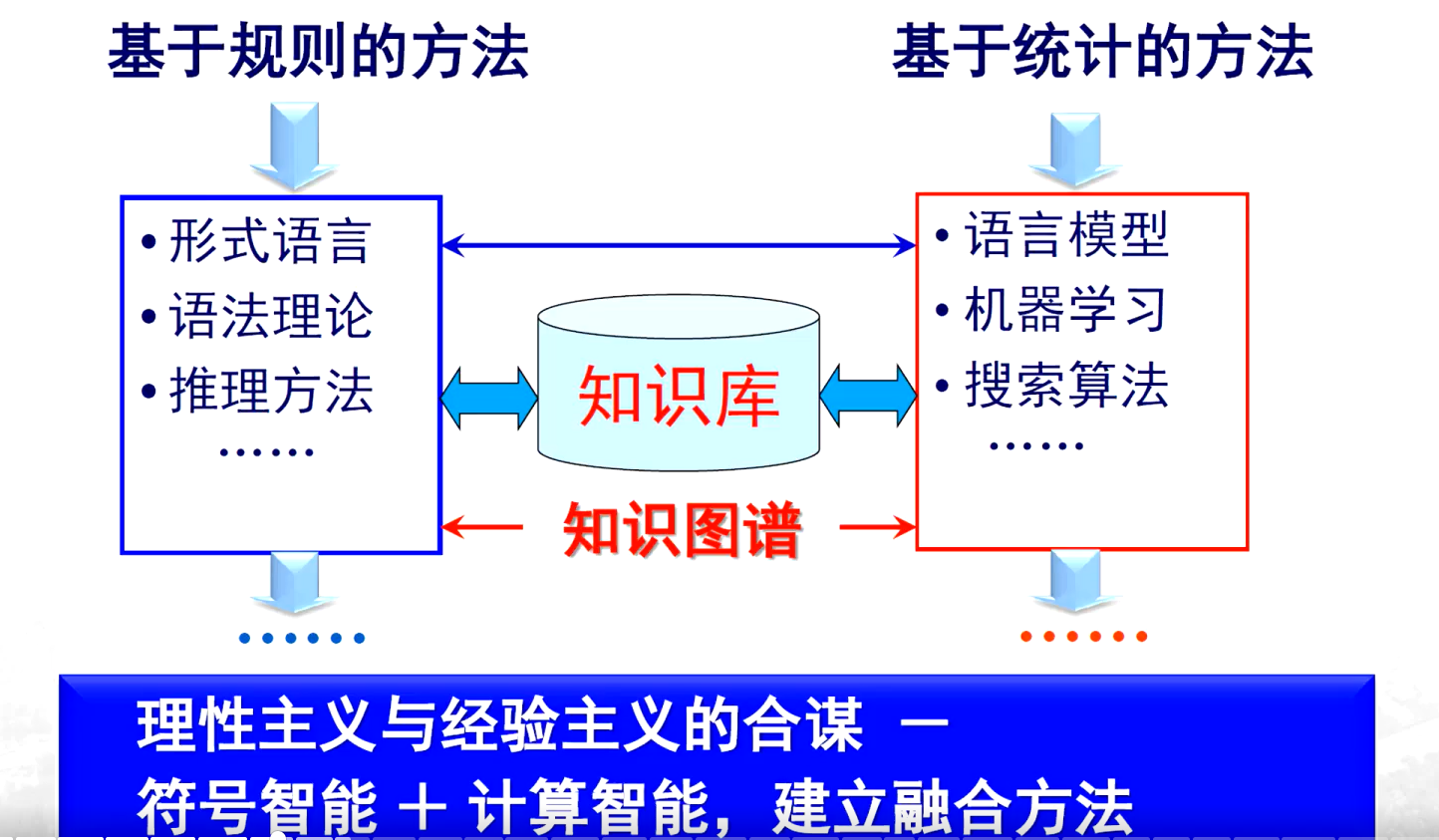
理性主义方法
- 核心思路:将分析对象转化为 “数据 + 算法”。其中,数据即语言符号,算法则是根据分析目的设计的方法、原则和过程。
- 分析层面:
- 词法分析:研究词与词、字与字之间的搭配规律及计算方式。
- 句法分析:探讨词汇组成句子时,词与词之间、句子与句子之间的关系。
- 语义分析:试图解析语言文字所包含的意义(包括浅层和深层意义)。
- 辅助手段:
- 构建词典:存储能组成词的字或词。
- 总结规则:将词与词、字与字之间的搭配及连接关系总结为规则,以此说明符号间的逻辑关系。
- 特点:依赖语言学理论,建立形式化的规则体系,进行基于符号的推理。
经验主义方法
- 核心思路:关注词与词之间的搭配情况,包括前后、并列等各种结构关系,其关注的结构相对宽泛,涉及共现关系(如哪些词更容易同时出现在同一文本、上下文或存在前后关系等)。
- 经验来源:从大量以往的书写文本(语料库)中获取,认为文本中如此使用,便可以这样运用。
- 方法特点:
- 基于统计:通过统计学方法从大规模语料库中统计出规律,属于数据驱动型。
- 概率计算:计算符号(词)前后出现的概率大小。
两者都关注语言的结构,但理性主义方法侧重人工构建词典和规则,依赖语言学理论与符号推理;经验主义方法则依赖大规模语料库的统计数据,注重从实际使用经验中挖掘规律。
也就是深度学习、大语言模型
2、传统的统计学习方法


3、深度学习方法
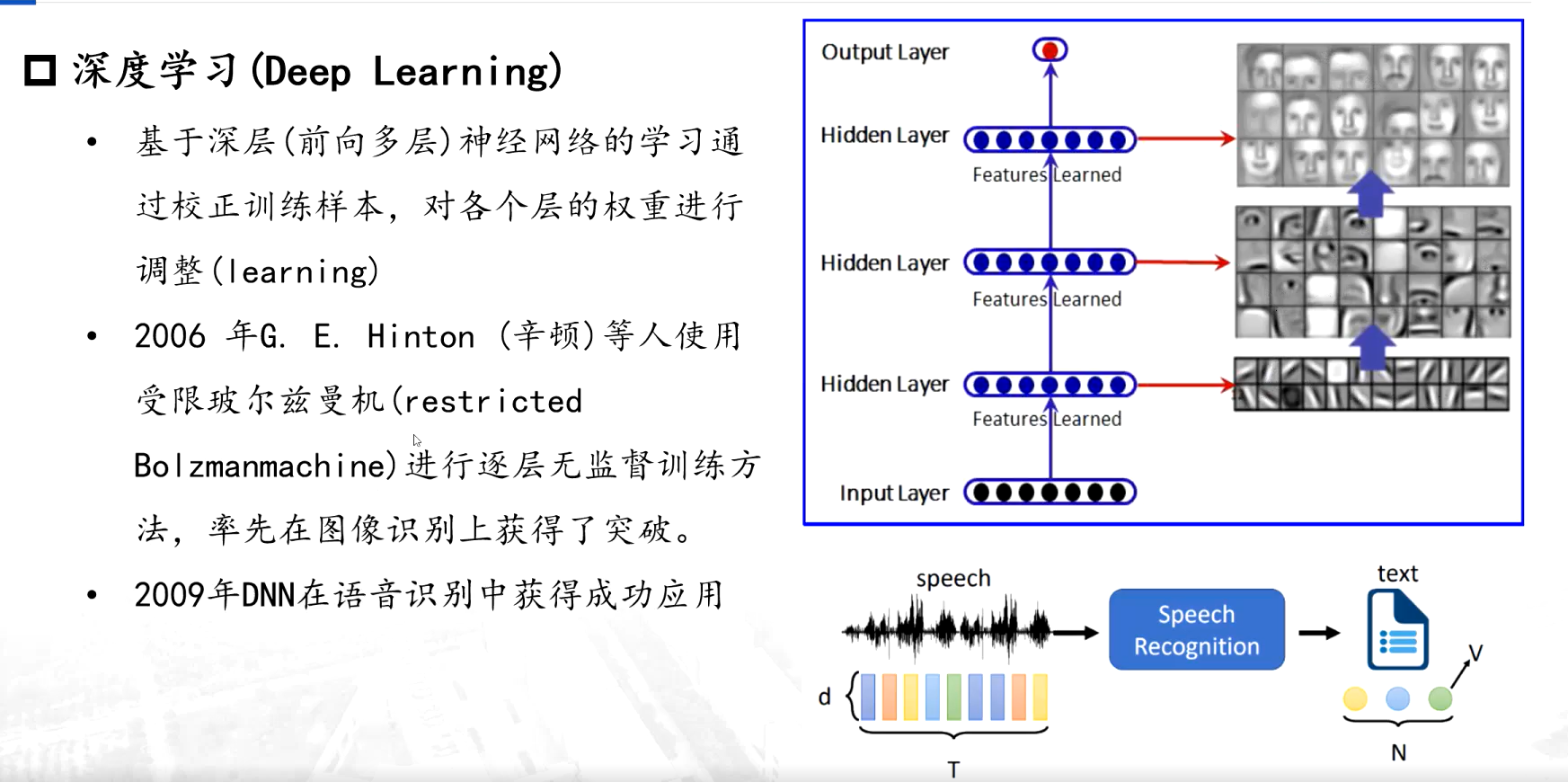
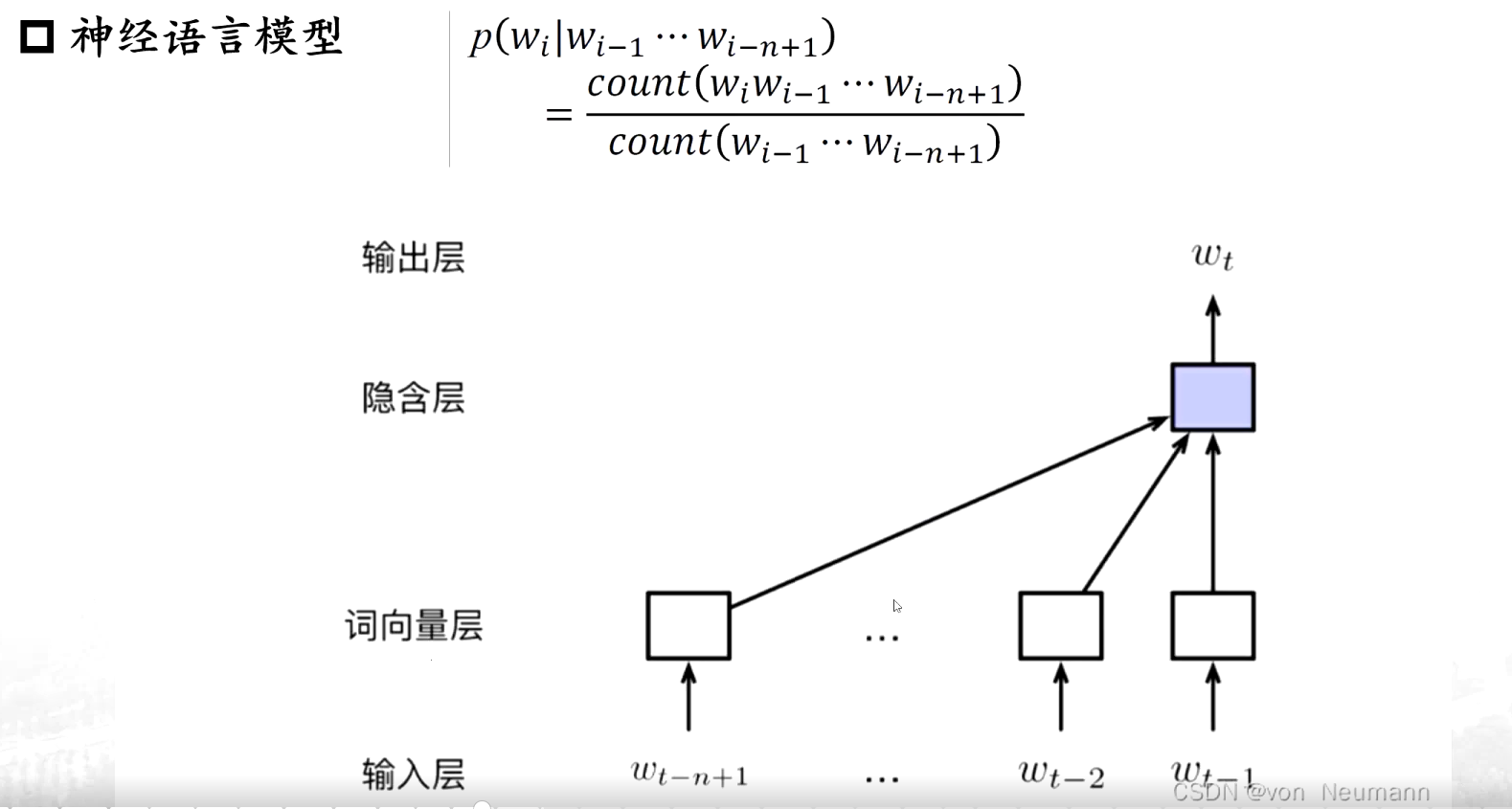
对这个特征的描述等等发生了变化,变成一个序列的形式,也就是第一个词、第二、第三个词,直到第七个词的时候,我们能够通过前几个字判断一下第七个词大最大的可能是哪一个词....
词向量表示
相近的词之间距离小
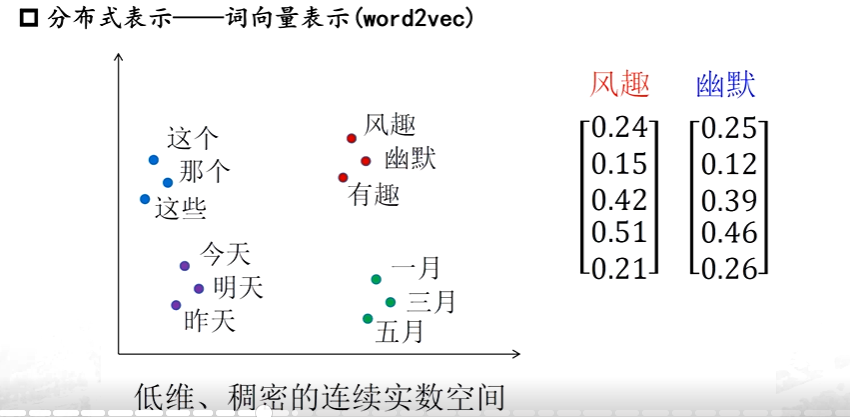
而之前都是符号化的,变为词向量后就可计算了【计算风趣和幽默两个之间的向量的欧式距离,它的距离一定比风趣和这个之间的距离近】
不同词语之间距离差异
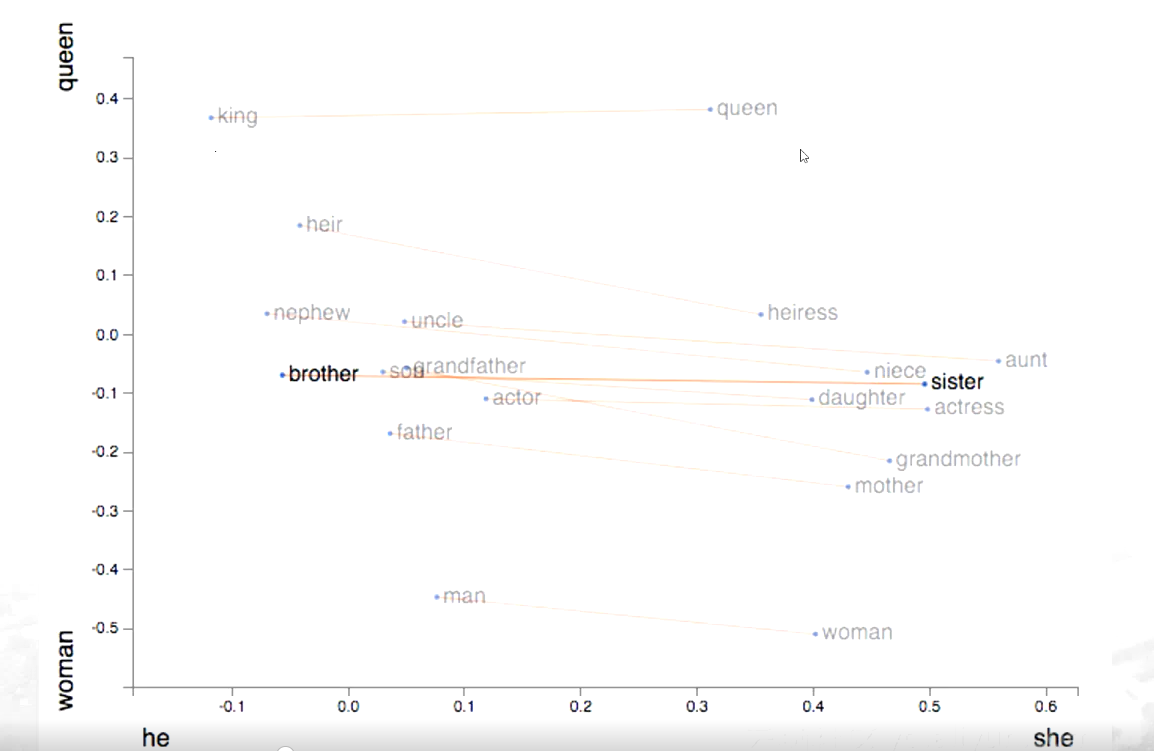
不同的词和词之间的距离也会有差异,像表示亲属关系、血缘关系的这些词会近一些,而表示身份地位【king\queen】这个词,要远离这些亲属这种特质的这个词; 以男女不同性别之间区分时,发现他们之间的距离的=差不多一样【如brother与sister的距离约等于 king和queen的距离】
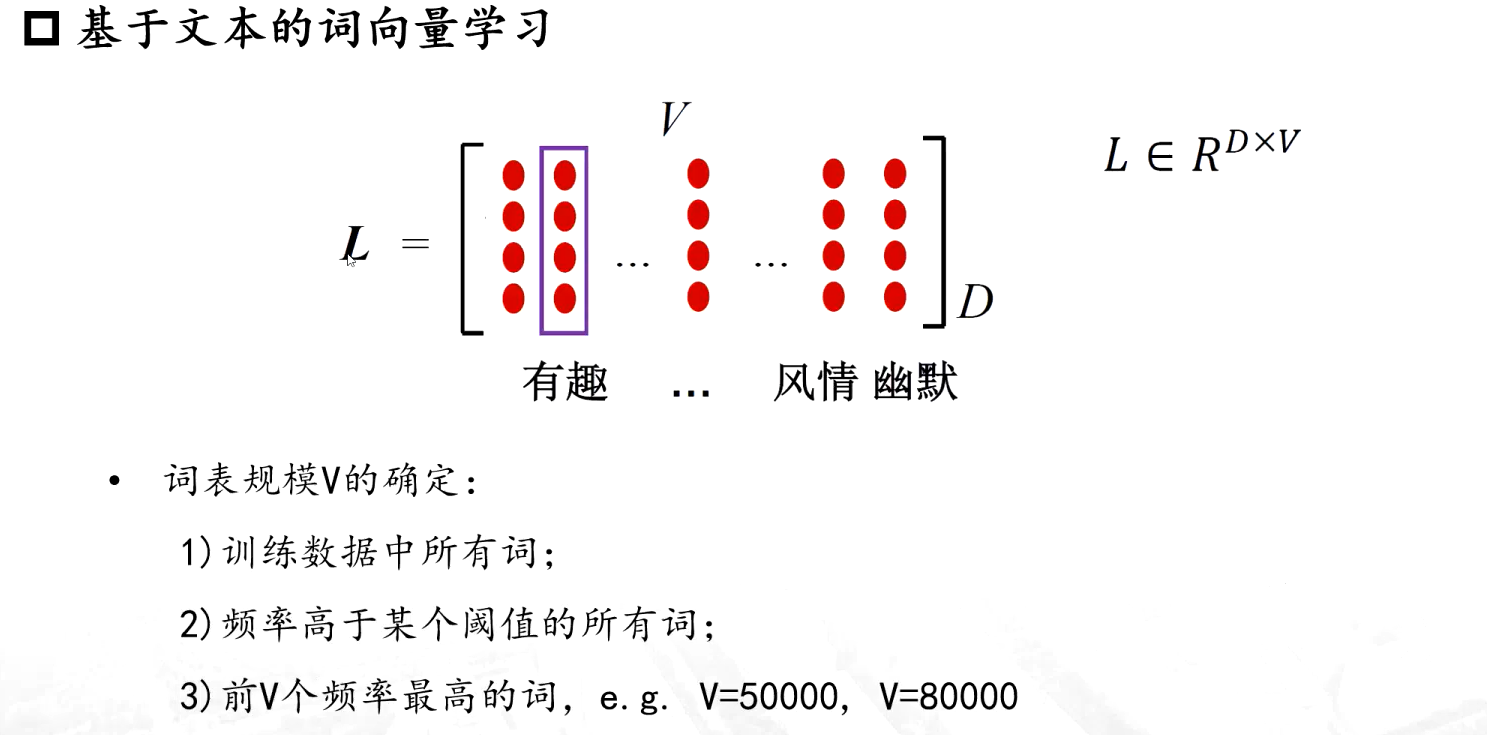
词向量学习
基于文本的词向量学习就是要学这样的一个语义空间 L ,认为每一个词只要是包含在这个空间中了,它要对应的他的词向量【词表的规模V的确定是很重要的,不一定需要训练数据中的所有词,一般会采用频率高于某阈值的词,甚至也会在训练前设置一些停用词】
开源工具

四、应用举例
1、汉语分词

已有的方法:全切分方法/最短路径切分方法/基于n-gram的统计方法/基于HMM的分词与词性标注一体化方法.....
(1)最大匹配法
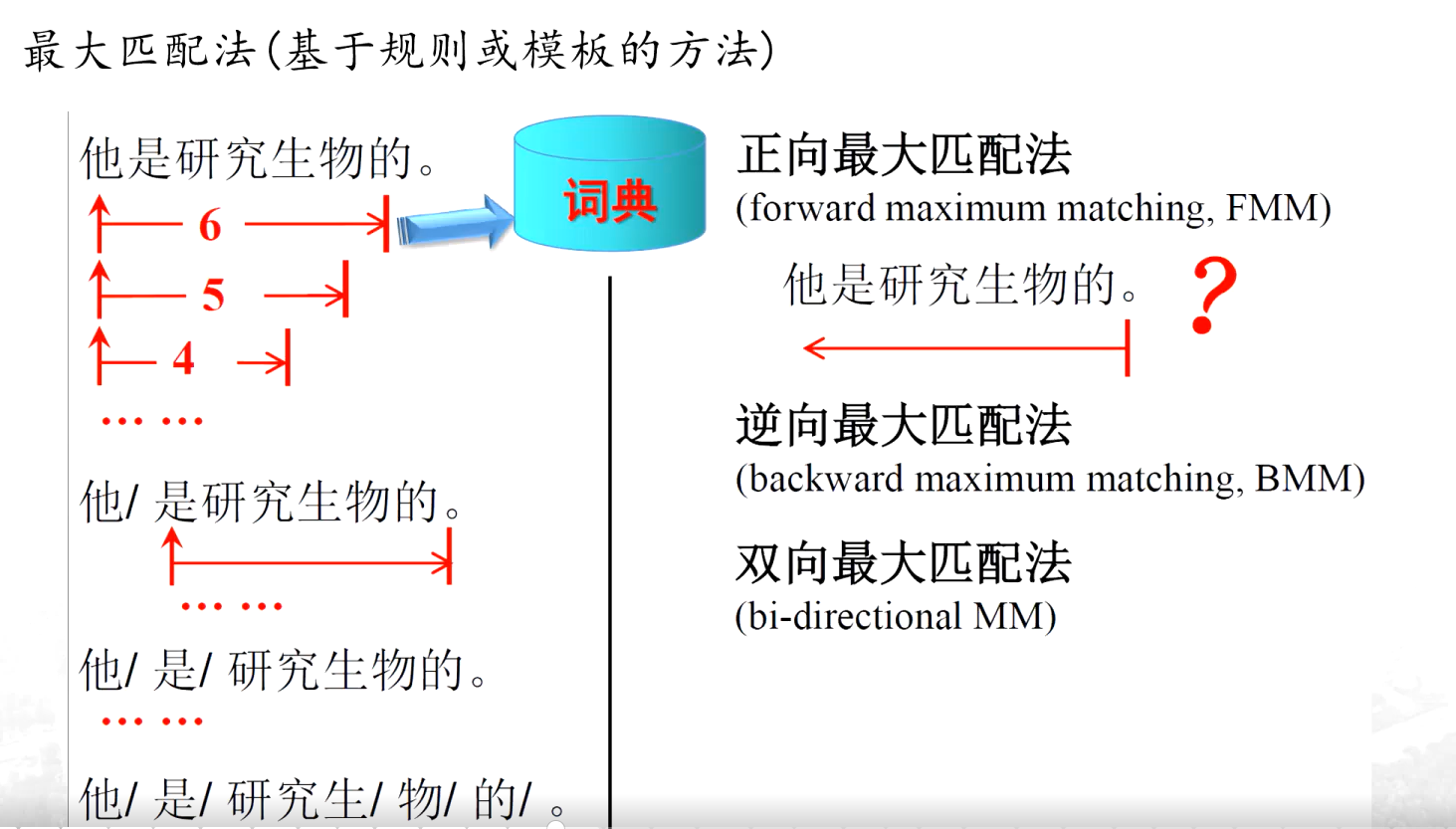
“他是研究生物的。”,先从最左边开始,看看最长能组成词典里有的词语是几个字。一开始找 6 个字 “他是研究生物”,发现词典里没有这个词;然后减少一个字,找 5 个字 “他是研究生”,词典里还是没有;再减少一个字,找 4 个字 “他是研究” ,词典里依然没有;直到找到 “他”,词典里有这个词,就把 “他” 切出来,接着从剩下的部分 “是研究生物的。” 继续用同样的方法找,依次拆分出 “是”“研究”“生物”“的” 。简单来说,就是从句子左边起,每次尽可能找最长的、能在词典里匹配上的词语。
逆向最大匹配法是从句子的最右边开始 “切” 。
双向最大匹配法就是把正向最大匹配法和逆向最大匹配法结合起来用。先分别用正向和逆向最大匹配法对句子进行分词,然后对比两种方法得到的结果。如看哪种分词方式得到的词语数量更合理
(2)基于n-gram的分词方法

(3)由字构词的分词方法

B M E S相当于是标签,这样有样本就可以训练处一个分类器,之后针对一个新样本的每一个字就可以预测出一个标签,然后再进行分词,但是这样对字和字之间出现的前后距离会比较窄
(4)基于神经网络的分词方法
(5)基于预训练模型的分词方法
2、机器翻译【MT】
(1)基于模版的直接转换法
从源语言句子的表层出发,将单词、短语或句子直接置换成目标语言译文,必要时进行简单的词序调整。直接将源语言句子按照固定的模版或句型结构转换为目标语言,不经过复杂的语法分析,属于早期机器翻译的基础方法。为常见的短语、句子结构预先设定一一对应的翻译模版(如 “Hello” 对应 “你好”,“I am...” 对应 “我是...”)

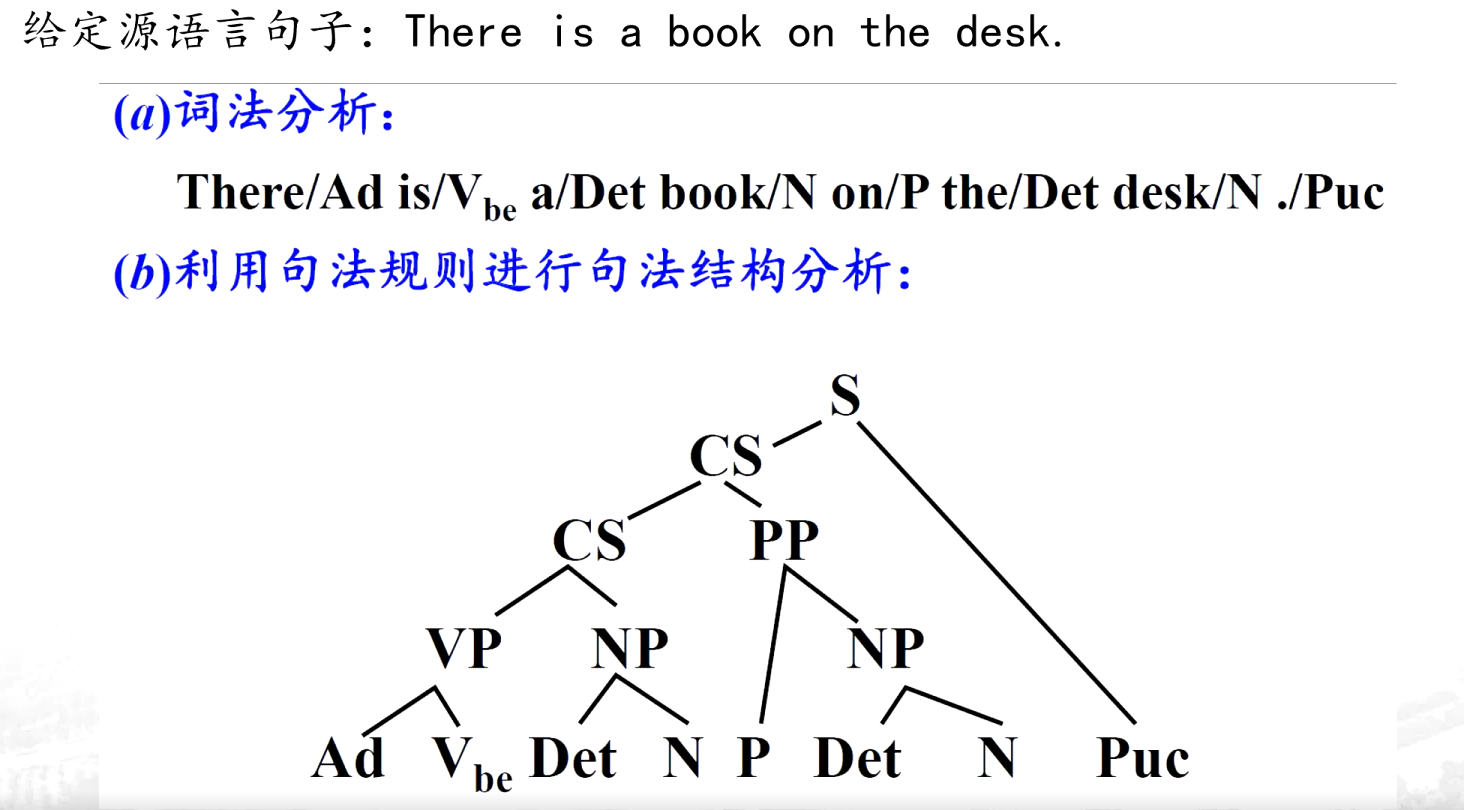
(2)基于规则的翻译方法
通过人工定义源语言和目标语言的语法规则、词汇规则及转换规则,利用计算机对句子进行语法分析,再根据规则生成目标语言。
基于规则的翻译过程分成6个步骤:
(a)对源语言句子进行词法分析
(b)对源语言句子进行句法/语义分析
(c)源语言句子结构到译文结构的转换
(d)译文句法结构生成
e)源语言词汇到译文词汇的转换
(f)译文词法选择与生成
(3)基于中间语言的翻译方法
引入一种独立于源语言和目标语言的 “中间语言”(Interlingua),作为翻译的中介。先将源语言转换为中间语言,再将中间语言转换为目标语言,避免直接处理双语对应关系。
(4)基于语料库的翻译方法
依赖大规模双语平行语料库(即源语言文本及其对应的目标语言翻译),通过统计或机器学习方法从语料中学习双语对应规律,实现翻译。是目前主流的机器翻译方法。
统计机器翻译(SMT)

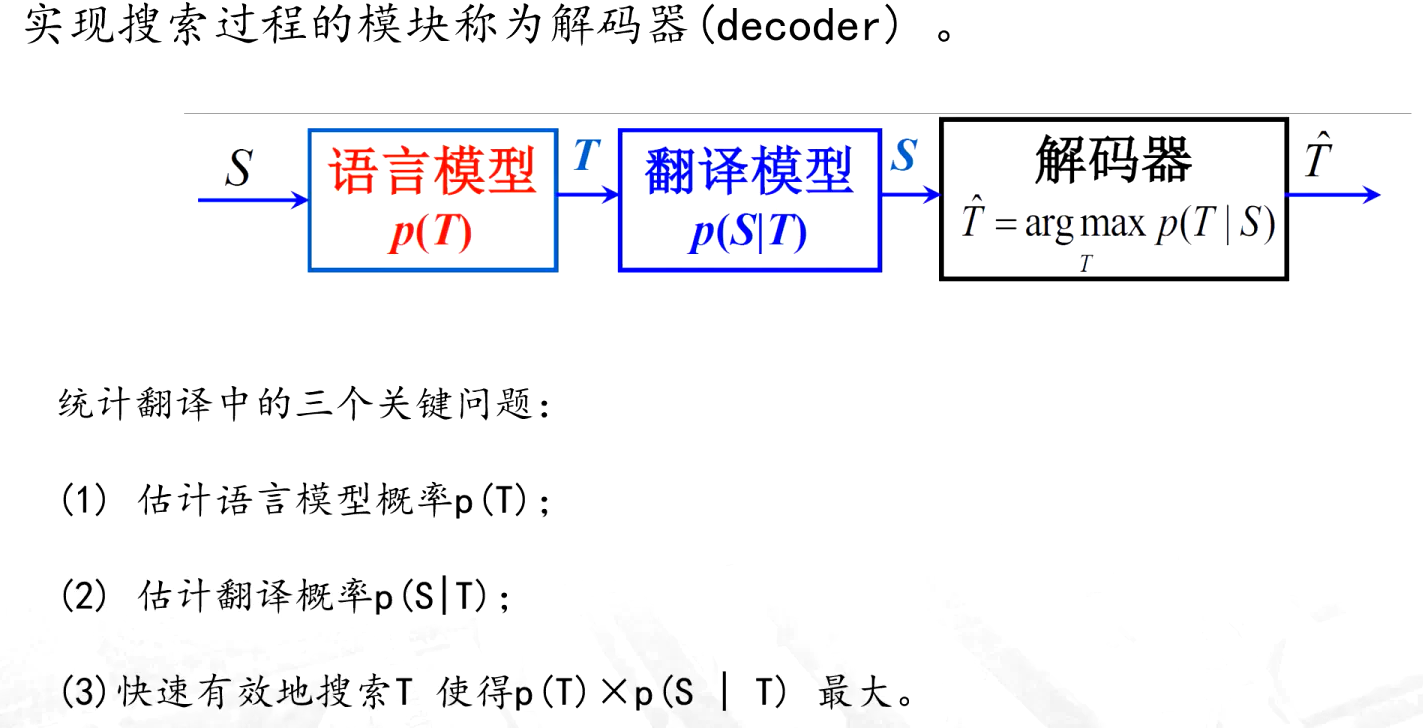
神经机器翻译方法

如:
| 方法 | 核心依赖 | 优势 | 主要局限 | 适用场景 |
|---|---|---|---|---|
| 基于模版的直接转换 | 固定模版 | 简单易实现 | 灵活性极差 | 简单短句、固定场景 |
| 基于规则 | 人工语法规则 | 可以较好的保持原文的结构 | 规则覆盖有限、人工量大,主观性强 | 语法严谨的小范围翻译 |
| 基于中间语言 | 通用中间语言 | 多语言扩展方便 | 中间语言设计难、语义解析复杂 | 理论上适合多语言互译 |
| 基于语料库 | 大规模平行语料 | 数据驱动、性能优、不需要对源语言进行深层次分析 | 依赖语料、可解释性弱 | 通用场景、现代主流翻译方法 |
3、语音翻译/同声传译
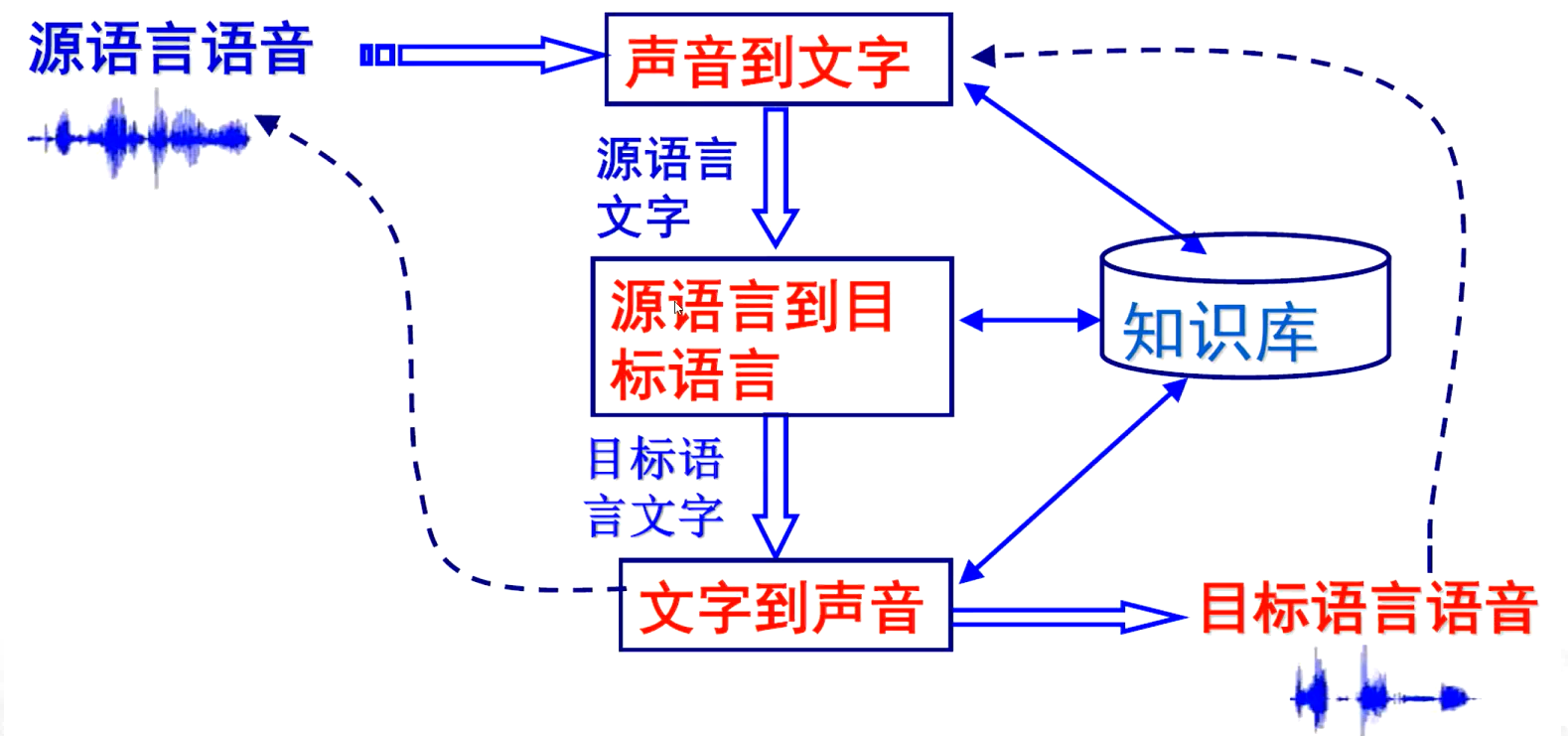
三个关键技术:语音识别、口语理解和翻译、语音合成
五、技术现状
1、汉语自动分词技术现状
2、机器翻译译文的质量

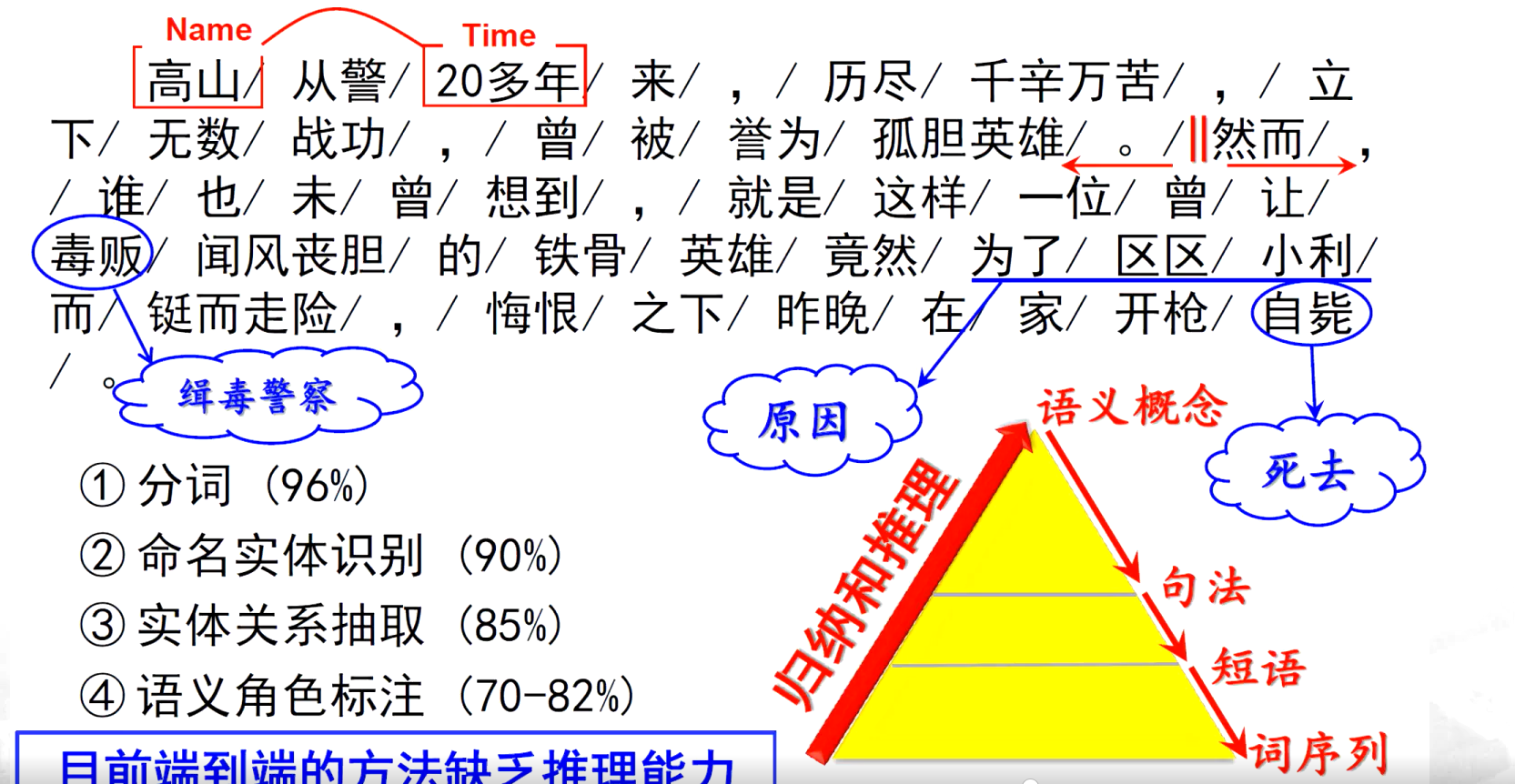
3、做不到语言的深度理解,缺乏推理能力
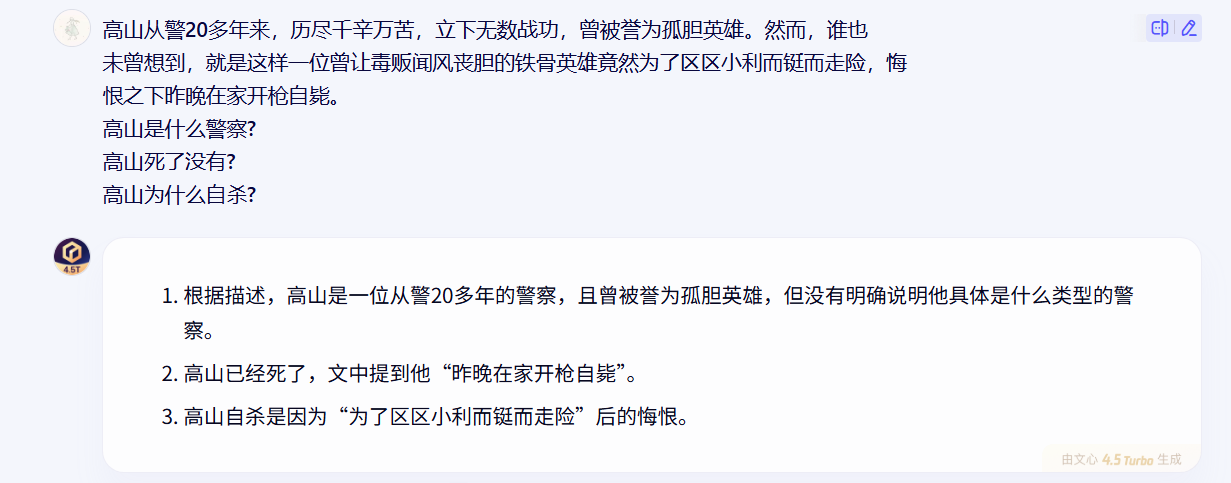
- 生词识别和切分是汉语自动分词技术面临的最大问题
- 跨领域和非规范是导致生词大量出现的主要原因
- 研究半监督学习、迁移学习等方法,解决领域的自适应问题,提高系统的鲁棒性和准确率,尽量减少系统对标注样本的依赖性,是未来汉语自动分词技术研究的主要方向

书籍推荐
