大模型的开发应用(十九):AIGC基础
AIGC基础
- 0 前言
- 1 ViT
- 1.1 模型结构
- 1.2 核心思想
- 1.3 代码
- 2 CLIP
- 2.1 对比学习机制
- 2.2 核心原理与架构
- 2.3 关键技术突破
- 2.4 简单代码实现
- 3 VAE
- 3.1 核心组件
- 3.2 损失函数
- (1)重构损失(Reconstruction Loss)
- (2)KL散度(KL Divergence)
- (3)两部分损失的平衡
- (4) 重参数化
- (5)总结
- 3.3 VAE的主要应用场景
- 4 Diffusion Model
- 4.1 核心原理:前向扩散与逆向生成
- 4.2 模型架构:改进的U-Net网络
- 4.3 数学基础:优化目标与损失函数
- 4.4 训练与推理流程
- 4.5 应用与前沿发展
- 5 总结
0 前言
AIGC(Artificial Intelligence Generated Content,人工智能生成内容)是指利用人工智能技术(如深度学习、自然语言处理、多模态模型等)自动生成文本、图像、音频、视频等内容的技术。在介绍 AIGC 模型之前,需要先知道 CLIP、VAE、Diffusion Model 的知识,本文就是介绍这些先修模型。
1 ViT
ViT 诞生于2020年,由 Google 团队提出,它是将 Transformer 结构应用在图像分类任务上,虽然之前也有其他团队开发了基于 Transformer 的视觉模型,但是 ViT 因为其模型“简单”且效果好,可扩展性强(模型越大效果越好),成为了 Transformer 在CV领域应用的里程碑著作,也引爆了后续相关研究。
1.1 模型结构
模型结构如下图所示:
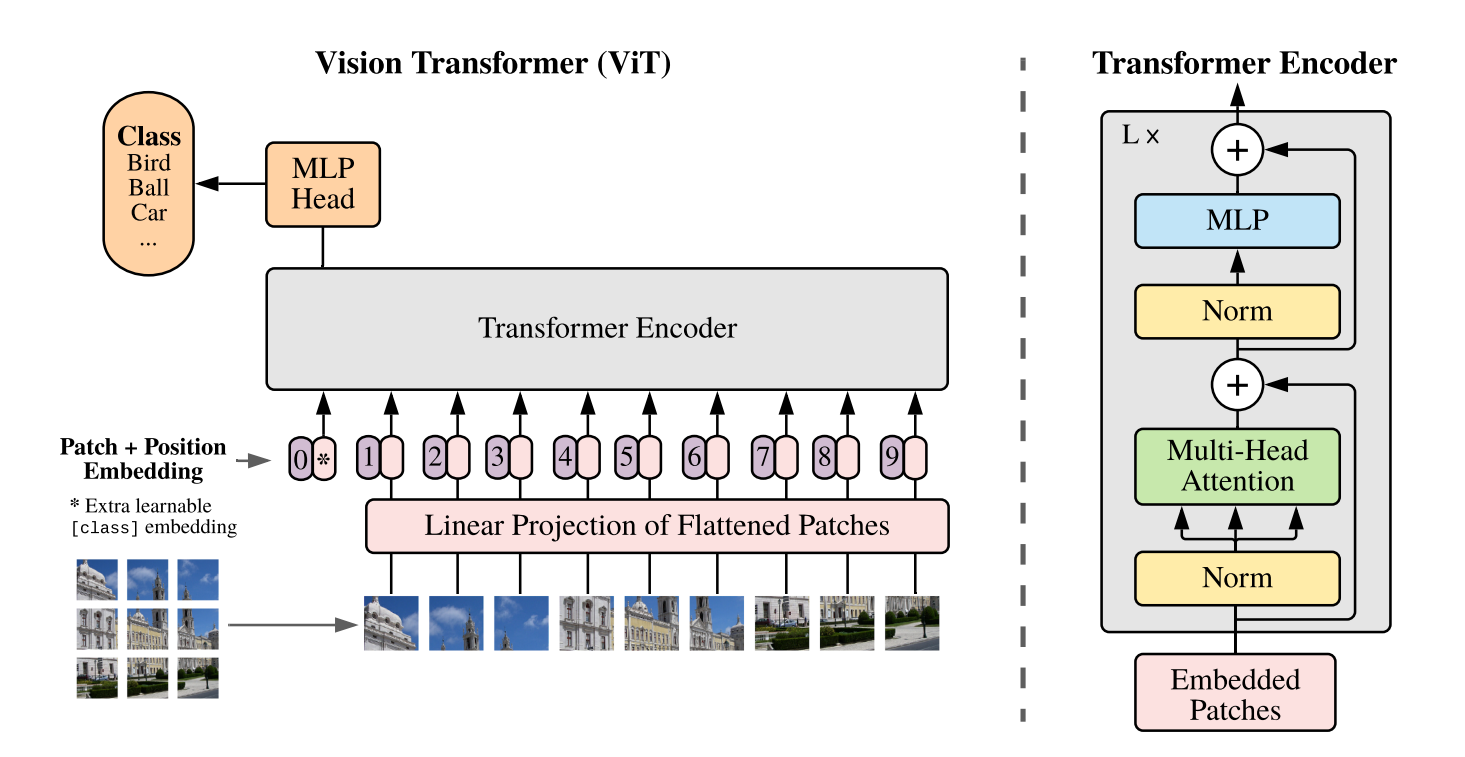
1.2 核心思想
ViT(Vision Transformer)的核心创新是将图像视为序列数据处理,而非传统的二维网格数据。具体步骤包括:
- 图像分块:将输入图像(如224×224像素)划分为固定大小的非重叠小块(如16×16像素),得到多个图像块(Patches)。
- 线性嵌入:每个块展平为向量后,通过线性投影映射到固定维度(如768维),形成类似NLP中的"词嵌入"序列。
- 位置编码:为每个块添加可学习的位置嵌入,保留空间信息(因Transformer本身无法感知顺序)。
- Class Token:在序列开头添加一个可学习的分类标记(类似BERT的[CLS]),最终输出用于分类任务。
1.3 代码
和 ResNet 类似,ViT 也是有多种变体的,典型变体如下:
- ViT-B/16、ViT-B/32:基础版(Base),参数量约86M,Patch尺寸分别为16×16和32×32。
- ViT-L/16、ViT-L/32:大型版(Large),参数量约307M,适合高精度任务。
- ViT-H/14:超大型版(Huge),参数量632M,Patch尺寸14×14,需极大数据和算力支持
接下来我们实现一下ViT-B/16。
先把需要的包导入进来:
import torch
import torch.nn as nn
from einops import rearrange
然后是图像块嵌入层(PatchEmbedding):
class PatchEmbedding(nn.Module):"""图像分块嵌入模块(核心组件)"""def __init__(self, img_size=224, patch_size=16, in_chans=3, embed_dim=768):super().__init__()self.img_size = (img_size, img_size)self.patch_size = (patch_size, patch_size)self.num_patches = (self.img_size[0] // self.patch_size[0]) * (self.img_size[1] // self.patch_size[1])# 使用卷积层实现高效分块,并通过输出通道数来调整嵌入维度,等效于线性投影self.proj = nn.Conv2d(in_chans, embed_dim, # 输出通道数与嵌入维度一致kernel_size=patch_size, # 卷积核的大小为 patch_sizestride=patch_size # 卷积核的步长也为 patch_size)def forward(self, x):# [batch, channels, H, W] -> [batch, embed_dim, num_patches_h, num_patches_w]x = self.proj(x)# 展平并转置维度: [batch, embed_dim, num_patches_h, num_patches_w] -> [batch, N, embed_dim],N是 patch 的数量x = rearrange(x, 'b c h w -> b (h w) c')return x
下面是 ViT 块,其实就是 Transformer 的编码器子层,熟悉 Transformer 结构的同学一看就懂:
class ViTBlock(nn.Module):"""Transformer编码器基础模块(ViT核心单元)"""def __init__(self, dim=768, num_heads=12, mlp_ratio=4.0, dropout=0.1):super().__init__()self.norm1 = nn.LayerNorm(dim)self.attn = nn.MultiheadAttention(dim, num_heads, dropout=dropout, batch_first=True)self.norm2 = nn.LayerNorm(dim)self.mlp = nn.Sequential(nn.Linear(dim, int(dim * mlp_ratio)),nn.GELU(),nn.Dropout(dropout),nn.Linear(int(dim * mlp_ratio), dim),nn.Dropout(dropout))def forward(self, x):# 残差连接 + 层归一化 + 多头注意力attn_output, _ = self.attn(self.norm1(x), self.norm1(x), self.norm1(x))x = x + attn_output# 残差连接 + 层归一化 + MLPx = x + self.mlp(self.norm2(x))return x
最后是堆叠 ViTBlock,并把 PatchEmbedding 层加入进来,于此同时,实现 Class Token,代码如下:
class ViT_B(nn.Module):def __init__(self, img_size=224,num_classes=1000,in_chans=3,patch_size=16,embed_dim=768,depth=12,num_heads=12,mlp_ratio=4.0,dropout=0.1,emb_dropout=0.1):super().__init__()# 1. 分块嵌入self.patch_embed = PatchEmbedding(img_size=img_size,patch_size=patch_size, in_chans=in_chans,embed_dim=embed_dim)num_patches = self.patch_embed.num_patches # 获取图像块的数量# 2. 分类token和位置编码self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + 1, embed_dim)) # num_patches + 1,加1表示有一个分类tokenself.pos_drop = nn.Dropout(emb_dropout)# 3. Transformer编码器堆叠self.blocks = nn.Sequential(*[ViTBlock(dim=embed_dim,num_heads=num_heads,mlp_ratio=mlp_ratio,dropout=dropout) for _ in range(depth)])# 4. 分类头self.norm = nn.LayerNorm(embed_dim)self.head = nn.Linear(embed_dim, num_classes)# 初始化权重nn.init.trunc_normal_(self.cls_token, std=0.02)nn.init.trunc_normal_(self.pos_embed, std=0.02)def forward(self, x):# 分块嵌入 [B, C, H, W] -> [B, num_patches, embed_dim]x = self.patch_embed(x)# 添加分类tokencls_tokens = self.cls_token.expand(x.shape[0], -1, -1) # 将分类token按照 batch_size 扩展x = torch.cat((cls_tokens, x), dim=1)# 添加位置编码x = self.pos_drop(x + self.pos_embed)# 通过Transformer编码器x = self.blocks(x)# 取分类token对应的输出x = self.norm(x)cls_token_final = x[:, 0]# 将分类token对应的输出,输入到分类头中,获取图片的特征并返回return self.head(cls_token_final)
最后是输出测试用例:
# 实例化ViT-B/16模型(关键参数)
model = ViT_B(img_size=224, # 输入图像尺寸num_classes=1000, # 分类类别数patch_size=16, # 图像块的尺寸embed_dim=768, # 特征维度(ViT-B标准)depth=12, # Transformer层数num_heads=12, # 注意力头数mlp_ratio=4.0, # MLP扩展比例dropout=0.1, # 普通dropoutemb_dropout=0.1 # 嵌入层dropout
)# 示例输入(batch_size=4, 3通道,224x224图像)
input_tensor = torch.randn(4, 3, 224, 224)
output = model(input_tensor) # 输出形状: [4, 1000]
print(output.shape)
输出:
torch.Size([4, 1000])
2 CLIP
CLIP(Contrastive Language-Image Pre-training)是由OpenAI于2021年提出的多模态预训练模型,通过对比学习将图像与文本映射到同一语义空间,实现跨模态理解。
2.1 对比学习机制
- CLIP通过对比损失函数训练模型:通过图像编码器和文本编码器,将图像和文本嵌入到同一空间中(共享空间),在共享嵌入空间中,若图像和文本描述的是同一事物,则最大化两个特征向量的相似度(余弦相似度),若描述的不是同一事物,则最小化两个向量的相似度。
- 训练数据:使用4亿个互联网图文对(WebImageText数据集),覆盖广泛视觉概念。
2.2 核心原理与架构
- 双编码器架构
- 图像编码器:支持ResNet或Vision Transformer(ViT),提取图像特征向量。
- 文本编码器:基于Transformer,将文本转换为向量,文本特征向量的维度,与图像特征向量的维度一致。
- 两个编码器输出的特征,经L2归一化后计算相似度,确保跨模态可比性。
- Clip 结构如下(左边为训练过程,右边为推理过程):
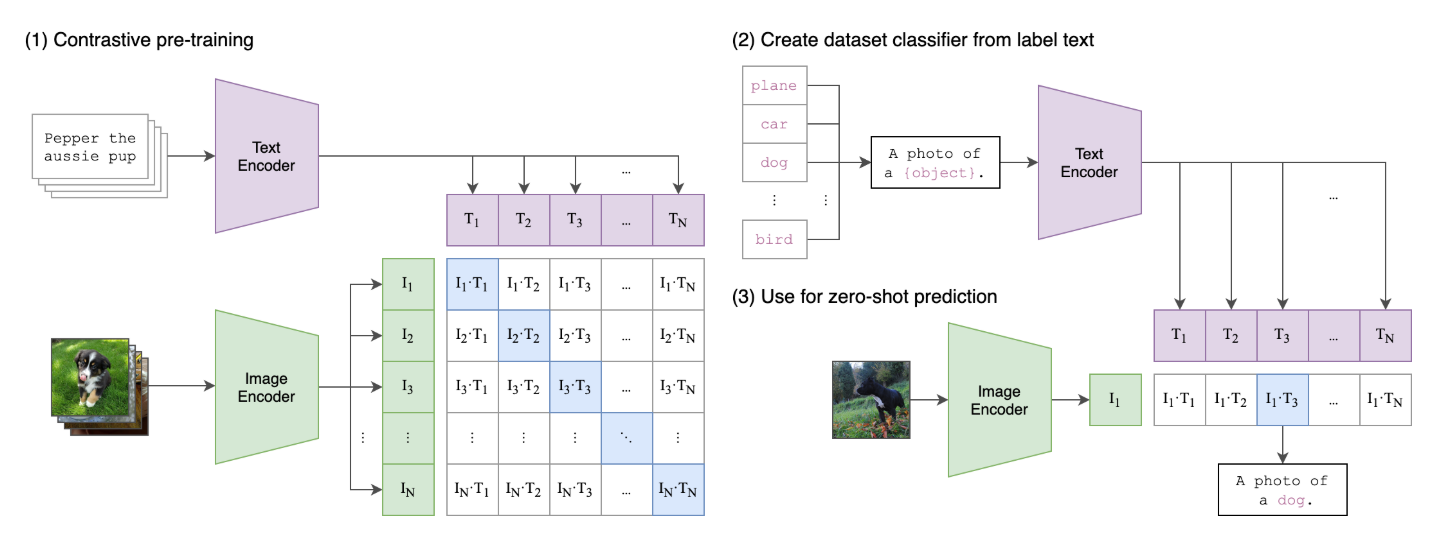
- 推理时,根据任务设定提示模板,例如图像分类任务,那么提示词模板可以设置成
a photo of a {object},可以把 ImageNet 中的1000个类别的名称当成 object 填进去,得到 1000 个条提示词,输入到文本编码器得到1000个向量,然后把图像输入到图像编码器,得到图像特征向量,最后将图像特征向量与1000个文本特征向量比较余弦相似度,最相似的文本向量对应的类别名称,就是这个图像的类别。
2.3 关键技术突破
-
零样本学习(Zero-Shot Learning)
- 无需微调:直接通过文本描述分类图像。例如,输入“一张狗的照片”,模型计算图像特征与所有类别文本特征的相似度,选择最高匹配类别。
- 灵活适配:分类标签可动态扩展,不受预定义类别限制,可以是100个类别,也可以是1000个类别,甚至更多。
-
高效的损失函数设计
- 代码:
import torch.nn.functional as Fdef contrastive_loss(image_emb, text_emb, tau=0.07):# tau 是温度系数# 归一化嵌入向量image_emb = F.normalize(image_emb, dim=-1)text_emb = F.normalize(text_emb, dim=-1)# 计算相似度矩阵logits_per_image = (image_emb @ text_emb.T) / taulogits_per_text = (text_emb @ image_emb.T) / tau# 标签:对角线为正样本labels = torch.arange(len(image_emb)).to(image_emb.device)# 对称交叉熵损失loss_image = F.cross_entropy(logits_per_image, labels) # 图像到文本的损失loss_text = F.cross_entropy(logits_per_text, labels) # 文本到图像的损失return (loss_image + loss_text) / 2- 对称损失设计思路:跨模态对齐,同时优化
图像→文本和文本→图像的匹配损失,提升对齐效果。 - 温度系数τ:τ值小(如 0.01),相似度差异被放大,则模型更关注困难负样本,τ值大(如 0.5),则差异被 “平滑” 掉了,避免过度自信。初始值设为
0.07,根据训练动态调整(如随训练步数衰减)。
2.4 简单代码实现
先把需要的包导进来:
import torch
import torch.nn as nn
from torchvision.models import resnet50
from einops import rearrange
接下来是图像编码器,有 ResNet 或 ViT 两种实现方式,ViT 可以使用我们上一节实现的 ViT,这里我们把 ResNet 的编码器实现一下:
from torchvision.models import resnet50class ResNetEncoder(nn.Module):""" 改进版ResNet-50(CLIP调整版) """def __init__(self, output_dim=512):super().__init__()base = resnet50()# 移除原分类头,替换为CLIP的适配结构self.backbone = nn.Sequential(*list(base.children())[:-2])self.attnpool = nn.Sequential(nn.AdaptiveAvgPool2d(1),nn.Flatten(),nn.Linear(2048, output_dim))def forward(self, x):features = self.backbone(x) # [B, 2048, 7, 7]return self.attnpool(features) # [B, 512]class ImageEncoder(nn.Module):def __init__(self, arch='ViT-B/32', output_dim=512):super().__init__()if 'ViT' in arch:self.encoder = ViT_B(num_classes=output_dim,patch_size=int(arch.split('/')[-1]), depth=12,)elif 'RN' in arch:self.encoder = ResNetEncoder(output_dim=output_dim)else:raise ValueError(f"Unsupported architecture: {arch}")def forward(self, x):features = self.encoder(x)return features
接下来是文本编码器:
class TextEncoder(nn.Module):def __init__(self, vocab_size=10000, embed_dim=512):super().__init__()self.token_embed = nn.Embedding(vocab_size, embed_dim)self.pos_embed = nn.Parameter(torch.randn(1, 77, embed_dim))self.transformer = nn.TransformerEncoder(nn.TransformerEncoderLayer(d_model=embed_dim, nhead=8),num_layers=6)self.ln = nn.LayerNorm(embed_dim)def forward(self, x):# [B, 77] -> [B, 77, 512]x = self.token_embed(x) + self.pos_embedx = self.transformer(x)return self.ln(x[:, 0]) # 取首字符特征
最后是模型整合:
class CLIP(nn.Module):def __init__(self):super().__init__()self.image_encoder = ImageEncoder(arch='ViT-B/32')self.text_encoder = TextEncoder()self.logit_scale = nn.Parameter(torch.tensor(2.6592)) # 可学习温度系数# 特征投影层(对齐维度)self.image_proj = nn.Linear(512, 512)self.text_proj = nn.Linear(512, 512)def encode_image(self, image):features = self.image_encoder(image)return F.normalize(self.image_proj(features), dim=-1)def encode_text(self, text):features = self.text_encoder(text)return F.normalize(self.text_proj(features), dim=-1)def forward(self, image, text):image_features = self.encode_image(image)text_features = self.encode_text(text)# 计算相似度矩阵logit_scale = self.logit_scale.exp()logits = logit_scale * image_features @ text_features.t()return logits
我们写一个测试用例,看看模型是否存在bug:
# 4. 使用示例
if __name__ == "__main__":device = "cuda" if torch.cuda.is_available() else "cpu"model = CLIP().to(device)# 模拟输入(实际需预处理)image = torch.randn(2, 3, 224, 224).to(device) # 2张图片text = torch.randint(0, 10000, (3, 77)).to(device) # 3段文本# 前向计算logits = model(image, text)print("图像-文本相似度矩阵:\n", logits.detach().cpu().numpy())
输出:
图像-文本相似度矩阵:[[-0.7128611 -0.9151645 -0.86004055][ 0.04123104 -0.04031402 -0.02805367]]
3 VAE
变分自编码器 VAE(Variational Autoencoder)是一种深度生成模型,结合了自编码器(Autoencoder)和概率图模型的思想,由Kingma和Welling于2013年提出,其核心目标是通过学习数据的潜在分布(latent distribution),实现数据生成、重构和特征提取。与传统自编码器不同,VAE引入概率编码,将输入数据映射为潜在空间的概率分布(如高斯分布),而非确定性向量。
3.1 核心组件
- 编码器(Encoder):将输入数据 xxx 映射到潜在空间,输出分布参数(均值 μ\muμ 和方差 σ\sigmaσ)。
- 解码器(Decoder):从潜在变量 zzz 采样,重构生成数据 x′x'x′,目标是逼近原始输入。
- 潜在空间(Latent Space):低维连续空间,用于捕捉数据的隐含特征,通常假设服从标准正态分布 N(0,I)N(0, I)N(0,I)。
- 模型架构:
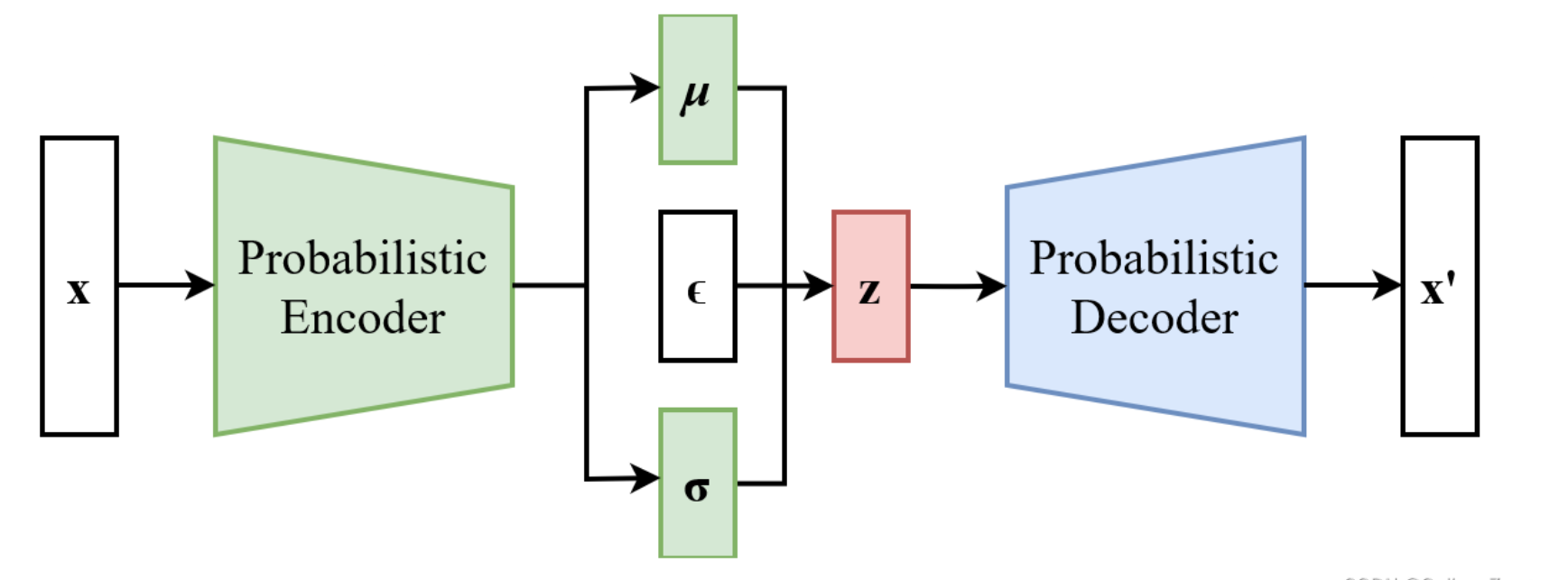
图中 ϵ\epsilonϵ 是为标准高斯噪声,它是随机变量,服从正态分布;无论训练还是推理,zzz 都不是编码器直接生成的,编码器只会生成 μ\muμ 和 σ\sigmaσ,然后通过 z=μ+σ⊙ϵz = \mu + \sigma \odot \epsilonz=μ+σ⊙ϵ 生成 zzz。
3.2 损失函数
VAE(变分自编码器)的损失函数是其核心设计,由两部分组成:重构损失(Reconstruction Loss) 和 KL散度(Kullback-Leibler Divergence)。这两部分共同作用,确保模型既能准确重建输入数据,又能学习到结构化的潜在空间。以下是详细解析:
VAE的损失函数可表示为:
LVAE=Lreconstruction+β⋅DKL(q(z∣x)∥p(z))\mathcal{L}_{\text{VAE}} = \mathcal{L}_{\text{reconstruction}} + \beta \cdot D_{\text{KL}}(q(z|x) \parallel p(z)) LVAE=Lreconstruction+β⋅DKL(q(z∣x)∥p(z))
其中:
- Lreconstruction\mathcal{L}_{\text{reconstruction}}Lreconstruction 是重构损失;
- DKLD_{\text{KL}}DKL 是KL散度,衡量两个分布的差异;
- β\betaβ 是平衡两部分的超参数(默认 β=1\beta=1β=1)。
(1)重构损失(Reconstruction Loss)
作用:衡量解码器重建输入数据 xxx 的能力,确保生成的 x^\hat{x}x^ 与原始数据尽可能接近。
常见形式:
- 均方误差(MSE):适用于连续数据(如图像像素值):
LMSE=1n∑i=1n(xi−x^i)2\mathcal{L}_{\text{MSE}} = \frac{1}{n} \sum_{i=1}^{n} (x_i - \hat{x}_i)^2 LMSE=n1i=1∑n(xi−x^i)2 - 二元交叉熵(BCE):适用于二值数据(如二值化图像):
LBCE=−∑i=1n[xilog(x^i)+(1−xi)log(1−x^i)]\mathcal{L}_{\text{BCE}} = -\sum_{i=1}^{n} \left[ x_i \log(\hat{x}_i) + (1 - x_i) \log(1 - \hat{x}_i) \right] LBCE=−i=1∑n[xilog(x^i)+(1−xi)log(1−x^i)]
选择依据:数据特性决定损失类型(连续数据用MSE,二值数据用BCE)。
(2)KL散度(KL Divergence)
作用:正则化潜在空间,强制编码器输出的分布 q(z∣x)q(z|x)q(z∣x)(通常是高斯分布)接近先验分布 p(z)p(z)p(z)(标准正态分布 N(0,I)\mathcal{N}(0, I)N(0,I)),即让 q(z∣x)q(z|x)q(z∣x) 往正态分布的方向靠拢。
KL散度用于衡量两个分布的距离,KL散度越小,说明两个分布越接近,数学形式(下式是连续分布的KL散度计算公式,我们不需要知道怎么推出来的):
DKL(q(z∣x)∥p(z))=12∑i=1d(μi2+σi2−1−logσi2)D_{\text{KL}}(q(z|x) \parallel p(z)) = \frac{1}{2} \sum_{i=1}^{d} \left( \mu_i^2 + \sigma_i^2 - 1 - \log \sigma_i^2 \right) DKL(q(z∣x)∥p(z))=21i=1∑d(μi2+σi2−1−logσi2)
其中 ddd 是潜在变量维度,μi\mu_iμi 和 σi\sigma_iσi 是编码器输出的均值和方差。
效果:
- μi→0\mu_i \to 0μi→0:潜在分布中心向原点靠拢;
- σi→1\sigma_i \to 1σi→1:潜在分布形状接近标准高斯(球形)。
(3)两部分损失的平衡
- 重构损失主导:模型更关注重建细节,但潜在空间可能不连续,导致生成样本缺乏多样性(例如插值时生成扭曲图像)。
- KL散度主导:潜在空间更规整,但重建质量下降(生成图像模糊)。
- 超参数 β\betaβ 的作用:调整 β>1\beta >1β>1 可增强正则化,强制潜在空间更接近标准正态分布;β<1\beta <1β<1 则侧重重建精度。
(4) 重参数化
-
重参数化技巧(Reparameterization Trick):
解决采样 z∼q(z∣x)z \sim q(z|x)z∼q(z∣x) 不可导的问题,将随机性转移到外部变量 ϵ∼N(0,I)\epsilon \sim \mathcal{N}(0, I)ϵ∼N(0,I):
z=μ+σ⊙ϵz = \mu + \sigma \odot \epsilon z=μ+σ⊙ϵ
这里的 μ\muμ 和 σ\sigmaσ 是潜空间向量的均值和标准差,通过它们可以确保梯度反向传播。 -
损失计算示例(PyTorch代码):
def loss_function(recon_x, x, mu, logvar):# 重构损失(BCE示例)BCE = F.binary_cross_entropy(recon_x, x.view(-1, 784), reduction='sum')# KL散度(闭合解)KLD = -0.5 * torch.sum(1 + logvar - mu.pow(2) - logvar.exp())return BCE + KLD
(5)总结
VAE的损失函数通过重构精度与潜在空间正则化的双目标优化,实现了数据生成与结构化表示的平衡:
- 重构损失 → 逼真还原细节;
- KL散度 → 构造连续、可插值的潜在空间,支撑可控生成。
3.3 VAE的主要应用场景
-
图像生成与重构
- 生成新图像(如人脸、手写数字):支持潜在空间插值实现连续变化,即把已有图像对应的潜空间向量 zzz 保存下来,然后插值获得新的 zzz,然后输入到解码器获得新的图像。
- 图像修复与去噪:从损坏或噪声数据中恢复清晰图像,即把损坏的图像输入到编码器,得到 μ\muμ 和 σ\sigmaσ,然后随机生成 ϵ\epsilonϵ,进而得到潜空间向量 zzz,再把 zzz 输入到解码器实现数据恢复,应用于医学影像处理。训练时仅使用正常数据,推理时根据验证集确定误差阈值(如95%分位数)
- 数据增强:从标准正态分布 N(0,I)\mathcal{N}(0, I)N(0,I) 中随机采样潜在变量 zzz,然后输入到解码器生成新样本,以扩充训练集,提升模型泛化能力(如医学图像稀缺场景);也可以在潜在空间的两点间线性插值,生成语义连续的过渡样本(如人脸表情渐变)。
-
异常检测
- 正常数据在潜在空间中聚集于高概率区域(接近标准正态分布中心),异常数据因偏离该区域,解码器重构时会产生显著误差。工业质检中,缺陷产品图像的重构误差远高于正常产品,因此可以计算输入数据重建误差 ∥x−x^∥2\left \| x-\hat{x} \right \| ^2∥x−x^∥2 ,误差大于阈值则为异常。适用领域:金融欺诈检测、工业设备故障诊断。
-
数据压缩与恢复
- 压缩时输入 xxx 经编码器得到分布参数 μμμ 和 σσσ 实现数据降维,恢复时用 z=μ+ϵ⋅σz=μ+ϵ⋅σz=μ+ϵ⋅σ 实现数据重建,其中 ϵϵϵ 通过标准正太分布采样(测试时可直接用 μμμ 避免随机性,不同的 ϵϵϵ 采样会使重建结果在细节(如纹理、边缘)上存在微小差异)。
4 Diffusion Model
Diffusion Model(扩散模型)是一种基于概率图模型和统计物理学原理的生成式人工智能模型,通过模拟数据的渐进噪声化与去噪过程生成高质量样本。其核心思想源于非平衡热力学,通过系统的扩散与逆扩散过程学习数据分布,广泛应用于图像、音频、文本等多模态生成任务。
4.1 核心原理:前向扩散与逆向生成
-
前向扩散(Forward Diffusion):
-
将原始数据(如图像)通过马尔可夫链逐步添加高斯噪声,每一步的加噪公式为:
q(xt∣xt−1)=N(xt;1−βtxt−1,βtI)q(\mathbf{x}_t | \mathbf{x}_{t-1}) = \mathcal{N}(\mathbf{x}_t; \sqrt{1-\beta_t} \mathbf{x}_{t-1}, \beta_t \mathbf{I}) q(xt∣xt−1)=N(xt;1−βtxt−1,βtI)
N(…)\mathcal{N}(\dots)N(…): 表示一个多元高斯分布,分号;通常用于分隔随机变量和分布的参数,后面第一个参数是均值,第二个参数是协方差矩阵,这里协方差矩阵是对角阵,说明维度间不相关。简言之,上式表示 xt\mathbf{x}_txt 服从一个均值为 1−βtxt−1\sqrt{1-\beta_t} \mathbf{x}_{t-1}1−βtxt−1、标准差为 βt\sqrt{\beta_t}βt 的正态分布,其中 βt\beta_tβt 控制噪声强度,TTT 步后数据退化为纯高斯噪声 xT∼N(0,I)\mathbf{x}_T \sim \mathcal{N}(0, \mathbf{I})xT∼N(0,I)。从 xt−1\mathbf{x}_{t-1}xt−1 生成 xt\mathbf{x}_txt 并不是完全随机的,均值 1−βtxt−1\sqrt{1-\beta_t} \mathbf{x}_{t-1}1−βtxt−1 表示 xt\mathbf{x}_txt 的中心点朝着缩小的 xt−1\mathbf{x}_{t-1}xt−1 靠近,缩放因子 1−βt\sqrt{1-\beta_t}1−βt 保留了大部分 xt−1\mathbf{x}_{t-1}xt−1 的信息。βt\beta_tβt 控制着这一步要添加的噪声量,通常很小(如 0.01),因此大部分信号保留,只添加少量噪声。β1\beta_1β1, β2\beta_2β2, … , βt\beta_tβt 这样的一个序列被称为 variance schedule 或者 noise schedule。
在缩放的 xt−1\mathbf{x}_{t-1}xt−1 基础上,我们从均值为 0、方差为 βt\beta_tβt 的各向同性高斯分布中采样噪声 ϵ∼N(0,I)\boldsymbol{\epsilon} \sim \mathcal{N}(0, \mathbf{I})ϵ∼N(0,I) 并添加进去。
最终生成步骤可以理解为:
xt=1−βtxt−1+βtϵ\mathbf{x}_t = \sqrt{1-\beta_t} \mathbf{x}_{t-1} + \sqrt{\beta_t} \boldsymbol{\epsilon}xt=1−βtxt−1+βtϵ
这正是从定义 N(xt;1−βtxt−1,βtI)\mathcal{N}(\mathbf{x}_t; \sqrt{1-\beta_t} \mathbf{x}_{t-1}, \beta_t \mathbf{I})N(xt;1−βtxt−1,βtI) 中采样 xt\mathbf{x}_txt 的过程。 -
关键性质:从上面的推导来看,任意时刻 ttt 的数据可直接从 x0\mathbf{x}_0x0 采样:
xt=αˉtx0+1−αˉtϵ,αˉt=∏i=1t(1−βi)\mathbf{x}_t = \sqrt{\bar{\alpha}_t} \mathbf{x}_0 + \sqrt{1-\bar{\alpha}_t} \boldsymbol{\epsilon}, \quad \bar{\alpha}_t = \prod_{i=1}^t (1-\beta_i) xt=αˉtx0+1−αˉtϵ,αˉt=i=1∏t(1−βi)
-
-
逆向生成(Reverse Process):
-
训练神经网络(如U-Net)学习从噪声中逐步恢复数据。逆过程定义为:
pθ(xt−1∣xt)=N(xt−1;μθ(xt,t),Σθ(xt,t))p_\theta(\mathbf{x}_{t-1} | \mathbf{x}_t) = \mathcal{N}(\mathbf{x}_{t-1}; \boldsymbol{\mu}_\theta(\mathbf{x}_t, t), \boldsymbol{\Sigma}_\theta(\mathbf{x}_t, t)) pθ(xt−1∣xt)=N(xt−1;μθ(xt,t),Σθ(xt,t))
其中,均值 μθ(xt,t)\boldsymbol{\mu}_\theta(\mathbf{x}_t, t)μθ(xt,t) 的尺寸(shape)和 xt\mathbf{x}_{t}xt 完全一致,按下式计算:
μθ=1αt(xt−βt1−αˉtϵθ(xt,t))\boldsymbol{\mu}_\theta = \frac{1}{\sqrt{\alpha_t}} \left( \mathbf{x}_t - \frac{\beta_t}{\sqrt{1-\bar{\alpha}_t}} \boldsymbol{\epsilon}_\theta(\mathbf{x}_t, t) \right)μθ=αt1(xt−1−αˉtβtϵθ(xt,t))
这里 αt=1−βt\alpha_t = 1 - \beta_tαt=1−βt,ϵθ\boldsymbol{\epsilon}_\thetaϵθ 是神经网络预测的噪声(稍后介绍完模型架构后就能理解),这样就可以直接预测噪声 ϵθ\boldsymbol{\epsilon}_\thetaϵθ 而非均值 μθ\boldsymbol{\mu}_\thetaμθ,简化了优化目标。协方差的计算可以根据DDPM(Denoising Diffusion Probabilistic Models)的策略,Σθ(xt,t)=σt2I\boldsymbol{\Sigma}_\theta(\mathbf{x}_t, t) = \sigma_t^2 \mathbf{I}Σθ(xt,t)=σt2I,其中σt\sigma_tσt 取预定义值:
- Option 1: σt2=βt\sigma_t^2 = \beta_tσt2=βt(前向过程方差)
- Option 2: σt2=β~t=1−αˉt−11−αˉtβt\sigma_t^2 = \tilde{\beta}_t = \frac{1-\bar{\alpha}_{t-1}}{1-\bar{\alpha}_t} \beta_tσt2=β~t=1−αˉt1−αˉt−1βt
-
实验表明两者效果接近,固定方差可减少训练不稳定性和计算复杂度。
-
-
过程示意图
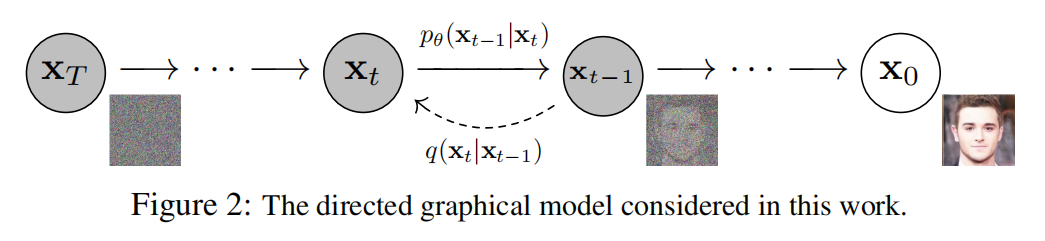
从右到左为前向扩散,从左到右为逆向生成。
从图中可以看到,扩散的时候,每一步只对当前数据做微小改动(保留大部分信息 + 添加少量各向同性高斯噪声),但经过 T 步(T 通常很大)后,原始数据就被完全破坏成了随机噪声。而逆向生成,则是逆转这个过程。
4.2 模型架构:改进的U-Net网络
扩散模型的前向过程是固定且确定性的数学过程,通过预定义的马尔可夫链逐步向数据添加高斯噪声,该过程仅依赖预设的噪声参数 noise schedule,即 βt{\beta_t}βt,无需任何神经网络或可训练参数。
逆向过程使用的是改进的U-Net结构(就是图像分割的那个U-Net,具体改进措施这里不展开,只需要记住,改进之后,输入的不只有图像,还有时间步),它的输入是噪声图像 xtx_txt 和时间步 ttt,输出的是残差噪声 εθ(xt,t)ε_θ(x_t, t)εθ(xt,t),噪声与输入图像维度相同。
拿到噪声后,计算均值 μθ(xt,t)\boldsymbol{\mu}_\theta(\mathbf{x}_t, t)μθ(xt,t) 和标准差 Σθ(xt,t)\boldsymbol{\Sigma}_\theta(\mathbf{x}_t, t)Σθ(xt,t),然后生成新样本:
xt−1∼N(μθ(xt,t),Σθ(xt,t))x_{t-1} \sim \mathcal{N}(\boldsymbol{\mu}_\theta(\mathbf{x}_t, t), \boldsymbol{\Sigma}_\theta(\mathbf{x}_t, t))xt−1∼N(μθ(xt,t),Σθ(xt,t))
所有时间步 t 共享同一模型参数 θθθ,而非为每个 t 训练独立模型,这是扩散模型的核心设计,显著降低了计算成本。
4.3 数学基础:优化目标与损失函数
-
损失函数:通过变分下界(ELBO)最大化对数似然,推导出简化目标:
L=Et,x0,ϵ[∥ϵ−ϵθ(xt,t)∥2]\mathcal{L} = \mathbb{E}_{t, \mathbf{x}_0, \boldsymbol{\epsilon}} \left[ \| \boldsymbol{\epsilon} - \boldsymbol{\epsilon}_\theta(\mathbf{x}_t, t) \|^2 \right] L=Et,x0,ϵ[∥ϵ−ϵθ(xt,t)∥2]
其中 ϵ\boldsymbol{\epsilon}ϵ 为前向过程真实噪声,ϵ∼N(0,I)\boldsymbol{\epsilon} \sim \mathcal{N}(0, I)ϵ∼N(0,I),ϵθ\boldsymbol{\epsilon}_\thetaϵθ 为模型预测的噪声。Et,x0,ϵ\mathbb{E}_{t, \mathbf{x}_0, \boldsymbol{\epsilon}}Et,x0,ϵ 表示对三个随机变量的联合期望(符号不理解没关系,太复杂了),训练目标简化为噪声预测的均方误差(MSE),即对每个样本的每个时间步算一次MSE,然后取平均。
-
噪声调度策略:
βt\beta_tβt 的值由选定的噪声调度策略(如线性调度、余弦调度)直接计算得出,以下是两种常见的调度策略:- 线性调度:βt\beta_tβt 随 ttt 线性增加,实现简单但可能生成质量受限。
- 余弦调度:βt=cos(tT⋅π2)\beta_t = \cos\left(\frac{t}{T} \cdot \frac{\pi}{2}\right)βt=cos(Tt⋅2π),在中间阶段加速加噪,保留更多细节,适合复杂数据。
4.4 训练与推理流程
-
训练过程:
训练并不是严格按照损失函数的表达式来计算损失函数,而是蒙特卡洛模拟:- 从训练集分布 q(x0)q(\mathbf{x}_0)q(x0) 中采样数据 x0\mathbf{x}_0x0, 从均匀分布中,采样时间步,即 t∼Uniform[1,T]t \sim \text{Uniform}[1, T]t∼Uniform[1,T]。
- 生成噪声 ϵ∼N(0,I)\boldsymbol{\epsilon} \sim \mathcal{N}(0, I)ϵ∼N(0,I) 和加噪样本 xt=αˉtx0+1−αˉtϵ\mathbf{x}_t = \sqrt{\bar{\alpha}_t} \mathbf{x}_0 + \sqrt{1-\bar{\alpha}_t} \boldsymbol{\epsilon}xt=αˉtx0+1−αˉtϵ。
- 输入 xt\mathbf{x}_txt 和 ttt 至U-Net,预测噪声 ϵθ\boldsymbol{\epsilon}_\thetaϵθ。
- 计算 ϵ\boldsymbol{\epsilon}ϵ 和 ϵθ\boldsymbol{\epsilon}_\thetaϵθ 的 MSE 损失并反向传播更新参数。
也就是说,并非所有样本都参与了损失函数计算,也不是每个时间步都参与了计算。
-
推理过程(采样):
- 初始化随机噪声 xT∼N(0,I)\mathbf{x}_T \sim \mathcal{N}(0, \mathbf{I})xT∼N(0,I)。
- 从 t=Tt=Tt=T 到 t=1t=1t=1 逐步去噪:
xt−1=1αt(xt−βt1−αˉtϵθ(xt,t))+σtz,z∼N(0,I)\mathbf{x}_{t-1} = \frac{1}{\sqrt{\alpha_t}} \left( \mathbf{x}_t - \frac{\beta_t}{\sqrt{1-\bar{\alpha}_t}} \boldsymbol{\epsilon}_\theta(\mathbf{x}_t, t) \right) + \sigma_t \mathbf{z}, \quad \mathbf{z} \sim \mathcal{N}(0, \mathbf{I}) xt−1=αt1(xt−1−αˉtβtϵθ(xt,t))+σtz,z∼N(0,I)
其中 σt\sigma_tσt 控制随机性(DDPM引入随机噪声;DDIM则为确定性采样)。 - 输出 x0\mathbf{x}_0x0 为生成结果。
4.5 应用与前沿发展
- 图像生成:DALL·E 2、Stable Diffusion 支持文本到图像生成,效果逼真。
- 图像编辑:GLIDE 实现局部修复、风格迁移。
- 跨模态生成:扩散模型扩展至视频(生成连续帧)、音频(音乐合成)、分子结构设计等领域。
Diffusion Model 凭借训练稳定性(避免GAN的模式崩溃)和生成质量优势,成为生成式AI的主流框架,其核心挑战在于采样速度慢与计算成本高。
5 总结
本文是为了给后续讲解多模态模型打基础的,其中 VAE 模型和 Diffusion 模型涉及的数学公式较多,如果理解不了就算了,但模型的结构,推理过程要理解。