企业级日志分析系统ELK
1.什么是 Elastic Stack
如果系统和应用出现异常和问题,相关的开发和运维人员想要排查原因,就要先登录到应用运行所相应的主机,找到上面的相关日志文件再进行查找和分析,所以非常不方便,此外还会涉及到权限和安全问题,而ELK的出现就很好的解决这一问题。
ELK 是由一家 Elastic 公司开发的三个开源项目的首字母缩写,即是三个相关的项目组成的系统。
2.Elasticsearch 索引是什么?
Elasticsearch 索引指相互关联的文档集合。Elasticsearch 会以 JSON 文档的形式存储数据。每个文档都会在一组键(字段或属性的名称)和它们对应的值(字符串、数字、布尔值、日期、数值组、地理位置或其他类型的数据)之间建立联系。
Elasticsearch 使用的是一种名为倒排索引的数据结构,这一结构的设计可以允许十分快速地进行全文本搜索。倒排索引会列出在所有文档中出现的每个特有词汇,并且可以找到包含每个词汇的全部文档。
在索引过程中,Elasticsearch 会存储文档并构建倒排索引,这样用户便可以近实时地对文档数据进行搜索。索引过程是在索引 API 中启动的,通过此 API 您既可向特定索引中添加 JSON 文档,也可更改特定索引中的 JSON 文档。
3.Logstash 的用途是什么?
Logstash 是 Elastic Stack 的核心产品之一,可用来对数据进行聚合和处理,并将数据发送到 Elasticsearch。Logstash 是一个开源的服务器端数据处理管道,允许您在将数据索引到Elasticsearch 之前同时从多个来源采集数据,并对数据进行充实和转换。
4.Kinbana的用途是什么?
是适用于 Elasticsearch 的数据可视化和管理工具,可提供实时直方图、线形图、饼状图和地图 ;包含 Canvas(允许用户基于自身数据创建定制动态信息图表 )、Elastic Maps(对地理空间数据可视化 )等高级应用程序 。
总结如下:
①Elasticsearch 是一个实时的全文搜索,存储库和分析引擎。
②Logstash 是数据处理的管道,能够同时从多个来源采集数据,转换数据,然后将数据发送到诸如Elasticsearch 等存储库中。
③Kibana 则可以让用户在 Elasticsearch 中使用图形和图表对数据进行可视化。
5.Elasticsearch集群安装
cluster.name: my-application
node.name: node-1 #不唯一。在其他主机上需要更改不一样的名字 其他的都不变
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
network.host: 0.0.0.0
discovery.seed_hosts: ["10.0.0.101", "10.0.0.102", "10.0.0.103"]
cluster.initial_master_nodes: ["10.0.0.101", "10.0.0.102", "10.0.0.103"]
xpack.security.enabled: false
xpack.security.enrollment.enabled: true
xpack.security.http.ssl:enabled: truekeystore.path: certs/http.p12
xpack.security.transport.ssl:enabled: trueverification_mode: certificatekeystore.path: certs/transport.p12truststore.path: certs/transport.p12
http.host: 0.0.0.0
curl 'http://127.0.0.1:9200/_cat/health' #查看es集群状态
创建索引
curl -XPUT '127.0.0.1:9200/index1' #简单输出
curl -XPUT '127.0.0.1:9200/index2?pretty' #格式化输出
curl -XPUT '127.0.0.1:9200/index2?pretty' #格式化输出
查看索引
curl 'http://127.0.0.1:9200/_cat/indices?v' #查看所有索引
删除索引
curl -XDELETE 'http://127.0.0.1:9200/index1' #删除索引index1
在索引index1上创建3个分片和2个副本的索引
curl -XPUT '127.0.0.1:9200/index1' \
-H 'Content-Type: application/json' \
-d '{"settings": {"index": {"number_of_shards": 3,"number_of_replicas": 2}}
}'
调整索引index1副本数为1,但不能调整分片数
curl -XPUT '127.0.0.1:9200/index1/_settings' \
-H 'Content-Type: application/json' \
-d '{"settings": {"number_of_replicas": 1}
}'6.Elasticsearch 插件
ES集群状态:
green 绿色状态:表示集群各节点运行正常,而且没有丢失任何数据,各主分片和副本分片都运行正
常。
yellow 黄色状态:表示由于某个节点宕机或者其他情况引起的,node节点无法连接、所有主分片都
正常分配,有副本分片丢失,但是还没有丢失任何数据。
red 红色状态:表示由于某个节点宕机或者其他情况引起的主分片丢失及数据丢失,但仍可读取数据
和存储 监控下面两个条件都满足才是正常的状态。
集群状态为 green 所有节点都启动。
Cerebro 插件
Cerebro 是开源的 elasticsearch 集群 Web 管理程序,此工具应用也很广泛,此项目升级比 Head 频繁。Cerebro v0.9.4 版本更高版本需要 Java11。
相关下载链接:wget https://githubfast.com/lmenezes/cerebro/releases/download/v0.9.4/cerebro_0.9.4_all.deb
#访问下面链接地址
http://10.0.0.101:9000 #我是在101主机上安装的cerebro插件
#在Node address输入框中输入任意ES集群节点的地址
http://10.0.0.102:9200
7.ES 文档路由
ES 文档路由原理
ES文档是分布式存储,当在ES集群访问或存储一个文档时,由下面的算法决定此文档到底存放在哪个主分片中,再结合集群状态找到存放此主分片的节点主机。
shard = hash(routing) % number_of_primary_shards
hash #哈希算法可以保证将数据均匀分散在分片中
routing #用于指定用于hash计算的一个可变参数,默认是文档id,也可以自定义
number_of_primary_shards #主分片数
#注意:该算法与主分片数相关,一旦确定后便不能更改主分片,因为主分片数的变化会导致所有分片需要重新分配
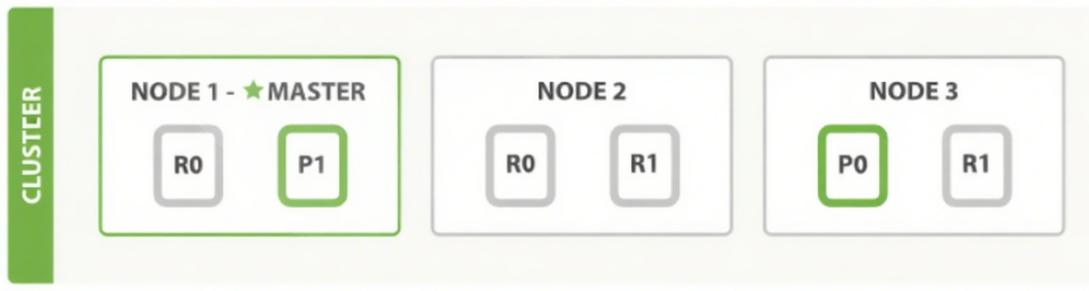
可以发送请求到集群中的任一节点。每个节点都知道集群中任一文档位置, 每个节点都有能力接收请求, 再接将请求转发到真正存储数据的节点上
ES 文档创建删除流程
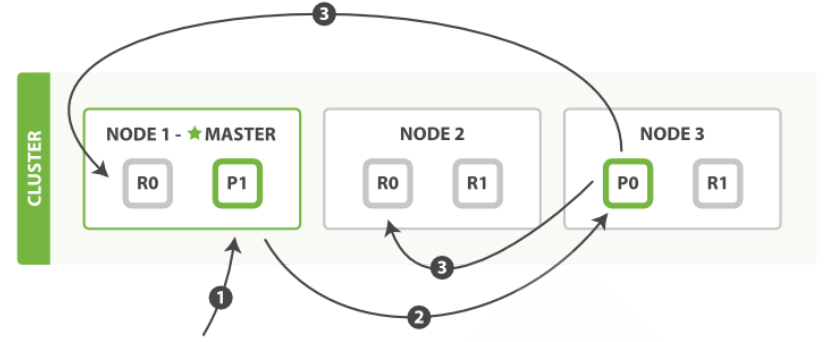
客户端向集群中某个节点 Node1 发送新建索引文档或者删除索引文档请求
Node1节点使用文档的 _id 通过上面的算法确定文档属于分片 0
因为分片 0 的主分片目前被分配在 Node3 上,请求会被转发到 Node3
Node3 在主分片上面执行创建或删除请求
Node3 执行如果成功,它将请求并行转发到 Node1 和 Node2 的副本分片上
Node3 将向协调节点Node1 报告成功
协调节点Node1 客户端报告成功。
ES 文档读取流程
可以从主分片或者从其它任意副本分片读取文档 ,读取流程如下图所示 :
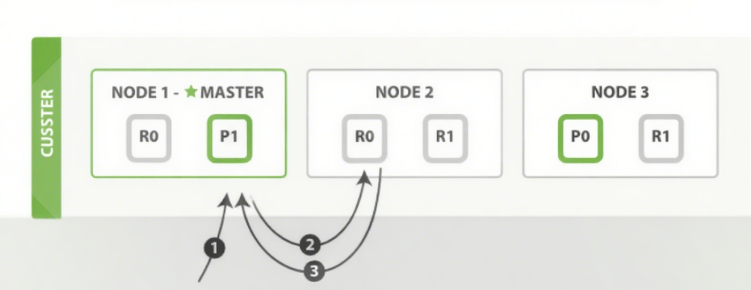
·客户端向集群中某个节点 Node1 发送读取请求。
·节点使用文档的 _id 来确定文档属于分片 0 。分片 0 的主副本分片存在于所有的三个节点上。
·在处理读取请求时,协调节点在每次请求的时候都会通过轮询所有的主副本分片来达到负载均衡,此次它将请求转发到 Node2。
·Node2 将文档返回给 Node1 ,然后将文档返回给客户端。
8.集群的扩缩容
扩容:在两个新主机上安装 ES。配置文件只更改node.name和添加discovery.seed_hosts 的ip。
缩容:删除ES或者停止ES服务。
注意:停止服务前,要观察索引的情况,按一定顺序关机,即先关闭一台主机,等数据同步完成后,再关闭第二台主机,防止数据丢失。