氛围编码(Vice Coding)的工具选择方式
一、前言
在写作过程中,我受益于若干优秀的博客分享,它们给予我宝贵的启发:
- 《5分钟选对AI编辑器,每天节省2小时开发时间让你早下班!》:https://mp.weixin.qq.com/s/f0Zm3uPTcNz30oxKwf1OQQ
二、AI编辑的代表
关于AI编辑器的种类和选择,目前我挑选出来有代表性的三种类型的编辑器
1、Cursor
- Tab独一档的存在
- 中型项目可以
2、Agument
-
架构设计很特别
- 上下文理解能力:在处理大型项目时表现最为出色
- ACE引擎:上下文理解能力更强,可以理解更复杂的上下文
- 项目记忆:可以记住项目AI生成的聊天记录,方便后续回顾。
- 使用限制较少:相比其他工具的各种限制,使用比较流畅
-
大型项目可以
3、Claude Code
- 是终端cli,无Tab
- 所有项目都可以,效果很不错
三、使用场景分析
场景一、后端开发和算法优化
在后端开发的过程中,业务逻辑的梳理编写是最为主要的,编写健壮且逻辑安全的代码。开发者在AI编辑器使用上有两种选择
第一种:如果复杂的业务逻辑想完全交给Agent或大模型来实现的话,那或许Agument和Claude Code更合适,因为它能独自获取到更多且有用的上下文能力
第二种: 如果自己和o3或Genimi 2.5pro等高级模型先梳理一下大概的业务逻辑,这样的话你自己是有一个清晰的上下文的,对于这个需求的开发,从某种程度上来说可以降低对编辑器的要求,Cursor、ClaudeCode+K2、rooCode+Genimi2.5Pro等,或许都可以考虑一下
场景二、大型项目和架构设计
当代码量达到万行以上,普通的工具被上下文限制,上下文中的相关信息变得“模糊”,这个时候大模型拿到的上下文大部分都可能是对问题的解决没有帮助的,还空耗费Token,一般这种情况的限制大概有两种(模型上下文的限制、AI编辑器本身索引能力的限制),以下三款工具可以考虑Augement、ClaudeCode+Claude
四、模型能力评估
以下的评估是我结合自己的使用经历+一些分析博客整理的,经供参考!!
4.1、模型开发能力
第一梯队:Claude 4、O3、Claude3.7、Genimi2.5pro
第二梯队:Claude3.5、DeepSeekR1、K2
第三梯队:GPT-4o、DeepSeekV3
4.2、UI能力
第一梯队:Claude4、O3、Claude3.7
第二梯队:DeepSeekV3、Claude3.5、DeepSeekR1
第三梯队:Gemini2.5Pro
第四梯队:GPT-4o
五、AI编码工具的关键点
其实一个AI编码工具是否好用,有如下几点的占比分析
- 能检索到最大上下文是多少 - 最大性(10%)
- 检索功能相关上下文是否准确 - 准确性(40%)
- 能使用到的模型能力是多少 - 模型能力(50%)
我们在编码的过程中,就是在解决一个一个问题, 本身最关键的只有两点对于模型来说:
- 上下文的精准性和相关性
- 模型自身的推理能力和理解水平
5.1、上下文的精准性和相关性
关于上下文的精准性和相关性有两种说法:
第一种是:极致暴力美学
第二种是:灵巧优雅美学
这两种方式就像在图书馆找一本书,有的人会直接一本一本书的对比找,而有的人会利用索引,定位区域,定位书架,缩小范围的找
还有点像你喜欢吃鱼,你要获取鱼,有点人会直接选择抽干水,有的人则会选择技法钓鱼
所以从这个角度出发,模型厂商提高上下文限制是有意义的,但不是必要的,模型更应该提高推理、理解等真正的底层能力
我们假设一下智能时代的到来,智能可以解决一个现实的问题,难道要暴力的将世界信息塞入分析吗?
我觉得当然不行,应该塞入相关的记忆即可,这便是工程化的意义,这个领域才是工程化应该大展身手的地方,这个时代是很需要工程创新的能力的
但是不可否认,适当的增强模型的上下文是需要的,但是不可一味的追求,这不是长久之计
六、分析总结
经过上述的分析,我们可以得出一个公式出来或者说是一个模型出来

我自己还根据自己的使用经历,给出自己理解的大概范围的波动影响,以下是一个不太严谨的数据分析
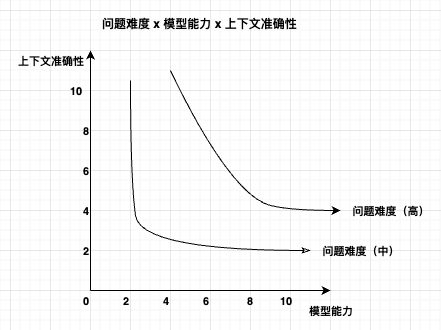
上图是一张问题难度x模型能力x上下文准确性之间,其中一个升降如何影响其他两个的
-
横轴:模型能力,从0(很弱)到10(很强),越右代表模型越聪明
-
枞轴:上下文准确性,从0(粗糙)到10(精准),越上代表喂给模型的背景越严谨
-
曲线:问题的等势线
- 问题难度(高):要想搞定这类的硬茬,组合点必须落在实线之上
- 问题难度(中):要解决这类问题,只有点落在实线之上,才可能轻松解决
在问题难度高的情况下,模型能力必须要大于4-5左右,太“笨”的模型,上下文再相关都是无事于补
在问题难度低的情况下,或许对于模型能力要求不高,但是上下文不太无关,牛头不对马嘴
所以都是会有一个阈值出现的,或许我理解的这个阈值是不太准确的,但是我确定的是一定会有
所以大家可以结合自身的想法和情况来选择AI编辑器,没有最好的,只有适合自己才是最好的, 我之前看一本小说,雪中悍刀行中的江湖中,没有最强的人,只有最强时,这个时间这个人才是最强的
🍻 如果你是一位只想快速构建项目原型,或者快速高效的解决这个需求的开发者,那么选择工具要站在模型能力强,编辑器能准确检索足够相关的上下文
🍻 如果你是一位成长型的开发者,想自己参与需求的开发,想足够掌握自己代码,那么你的选择工具范围目前会很大,模型方面你可以考虑中等模型即可,编辑器检索能力中等,不过最重要的你需要一位“经验十足”的模型和你配合,例如:O3、Genimi2.5Pro
七、一点看法
我很欣赏Kiro,原因是它为开发者与模型在上下文整理检索方面都提供了一个共同的操作空间
开发者研发一个项目会因时间产生一系列的研发行为,这组成了这个需求的研发记忆,今天研发了多少功能,或者该功能研发多少时间,这个功能的设计和具体的逻辑是如何的
之前大家只能通过散乱的记忆整理,思考阅读,但是现在开发者与模型都有一个文档空间,对双方都友好,模型适合检索,开发者适合阅读回忆,甚至间接的降低了问题的难度的阈值