DAY 20 奇异值分解(SVD)
知识点回顾:
- 线性代数概念回顾(可不掌握)
- 奇异值推导(可不掌握)
- 奇异值的应用
- 特征降维:对高维数据减小计算量、可视化
- 数据重构:比如重构信号、重构图像(可以实现有损压缩,k 越小压缩率越高,但图像质量损失越大)
- 降噪:通常噪声对应较小的奇异值。通过丢弃这些小奇异值并重构矩阵,可以达到一定程度的降噪效果。
- 推荐系统:在协同过滤算法中,用户-物品评分矩阵通常是稀疏且高维的。SVD (或其变种如 FunkSVD, SVD++) 可以用来分解这个矩阵,发现潜在因子 (latent factors),从而预测未评分的项。这里其实属于特征降维的部分。
在机器学习中,如果对训练集进行 SVD 降维后训练模型,而测试集的特征数量与降维后的训练集不一致(测试集仍保持原始特征数量),该如何处理?
1. 问题分析
- 训练集降维:假设训练集有 1000 个样本,50 个特征,通过 SVD 降维后保留k=10个特征,得到形状为 (1000, 10) 的新数据。模型基于这 10 个特征进行训练。
- 测试集问题:测试集假设有 200 个样本,仍然是 50 个特征。如果直接输入测试集到模型中,特征数量不匹配(模型期望 10 个特征,测试集有 50 个),会导致错误。
- 核心问题:如何确保测试集也能被正确地降维到与训练集相同的k个特征空间
2. 解决方案:对测试集应用相同的变换

3. 为什么不能对测试集单独做 SVD?
- 如果对测试集单独进行 SVD,会得到不同的 V^T 矩阵,导致测试集和训练集的低维空间不一致,模型无法正确处理测试数据。
- 训练集的 V^T 矩阵代表了训练数据的特征映射规则,测试集必须遵循相同的规则,否则会引入数据泄漏或不一致性问题。
4. 实际操作中的注意事项
1. 标准化数据:在进行 SVD 之前,通常需要对数据进行标准化(均值为 0,方差为 1),以避免某些特征的量纲差异对降维结果的影响。可以使用 sklearn.preprocessing.StandardScaler。
from sklearn.preprocessing import StandardScalerscaler = StandardScaler()X_train_scaled = scaler.fit_transform(X_train)X_test_scaled = scaler.transform(X_test)注意:scaler 必须在训练集上 fit,然后对测试集只用 transform,以避免数据泄漏。
2. 选择合适的 k:可以通过累计方差贡献率(explained variance ratio)选择 k,通常选择解释 90%-95% 方差的 k 值。代码中可以计算:
explained_variance_ratio = np.cumsum(sigma_train**2) / np.sum(sigma_train**2)print(f"前 {k} 个奇异值的累计方差贡献率: {explained_variance_ratio[k-1]}")3. 使用 sklearn 的 TruncatedSVD:sklearn 提供了 TruncatedSVD 类,专门用于高效降维,尤其适合大规模数据。它直接计算前 k 个奇异值和向量,避免完整 SVD 的计算开销。
from sklearn.decomposition import TruncatedSVDsvd = TruncatedSVD(n_components=k, random_state=42)X_train_reduced = svd.fit_transform(X_train)X_test_reduced = svd.transform(X_test)print(f"累计方差贡献率: {sum(svd.explained_variance_ratio_)}")作业:尝试利用svd来处理心脏病预测,看下精度变化
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score# 准备特征和标签
X = data.drop('target', axis=1).values
y = data['target'].values# 设置随机种子以便结果可重复
np.random.seed(42)# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
print(f"训练集形状: {X_train.shape}")
print(f"测试集形状: {X_test.shape}")# 对训练集进行 SVD 分解
U_train, sigma_train, Vt_train = np.linalg.svd(X_train, full_matrices=False)
print(f"Vt_train 矩阵形状: {Vt_train.shape}")# 选择保留的奇异值数量 k
k = 13
Vt_k = Vt_train[:k, :]
print(f"保留 k={k} 后的 Vt_k 矩阵形状: {Vt_k.shape}")# 降维训练集:X_train_reduced = X_train @ Vt_k.T
X_train_reduced = X_train @ Vt_k.T
print(f"降维后训练集形状: {X_train_reduced.shape}")# 使用相同的 Vt_k 对测试集进行降维:X_test_reduced = X_test @ Vt_k.T
X_test_reduced = X_test @ Vt_k.T
print(f"降维后测试集形状: {X_test_reduced.shape}")# 训练模型(以随机森林为例)
model = RandomForestClassifier(random_state=42)
model.fit(X_train_reduced, y_train)# 预测并评估
y_pred = model.predict(X_test_reduced)
accuracy = accuracy_score(y_test, y_pred)
print(f"测试集准确率: {accuracy}")# 计算训练集的近似误差(可选,仅用于评估降维效果)
X_train_approx = U_train[:, :k] @ np.diag(sigma_train[:k]) @ Vt_k
error = np.linalg.norm(X_train - X_train_approx, 'fro') / np.linalg.norm(X_train, 'fro')
print(f"训练集近似误差 (Frobenius 范数相对误差): {error}")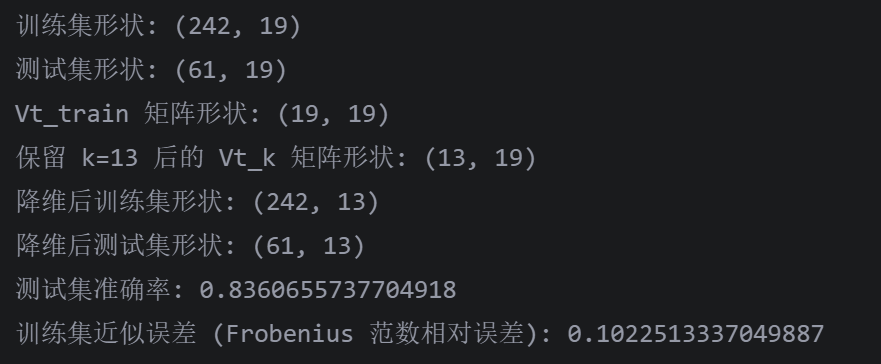
模型评估指标
- 测试集准确率:测试集准确率为
0.8360655737704918,表示模型在测试集上的预测结果中,正确预测的比例约为 83.6%。对于一些对精度要求不是极高的场景,这个准确率还算可以接受;但如果是医疗诊断、金融风险评估等对准确性要求极高的场景,这个准确率还有提升的空间。 - 训练集近似误差(Frobenius 范数相对误差):值为
0.1022513337049887,Frobenius 范数相对误差衡量的是降维后的训练集与原始训练集之间的差异程度。该误差值为 0.102 左右,意味着降维后的训练集与原始训练集相比,存在大约 10.2% 的差异 。这个误差不算太大,说明降维在一定程度上较好地保留了训练集的信息,但仍有优化的余地。
整体总结
- 数据降维成功减少了特征维度,降低了数据复杂性。
- 模型在测试集上的准确率处于中等水平,训练集的近似误差也在可接受范围内,但无论是降维效果还是模型性能,都还有进一步优化提升的空间。比如,可以尝试调整降维时保留的特征数量
k,或者对模型进行调参、更换更合适的模型等操作,来提高准确率并降低误差。
@浙大疏锦行