【论文阅读 | CVPR 2023 |CDDFuse:基于相关性驱动的双分支特征分解的多模态图像融合】
论文阅读 | CVPR 2023 |CDDFuse:基于相关性驱动的双分支特征分解的多模态图像融合
- 1&&2. 摘要&&引言
- 3. CDDFuse 模型设计
- 3.1 模型概述
- 3.2 编码器:多尺度特征提取与分解
- 3.2.1 共享特征编码器(SFE)
- 3.2.2 基础 Transformer 编码器(BTE)
- 3.2.3 细节 CNN 编码器(DCE)
- 3.3 融合层:多频率特征融合
- 3.4 解码器:特征重建与融合生成
- 3.5 两阶段训练策略与损失函数
- 3.5.1 训练阶段 I:特征分解与原图重建
- 3.5.2 训练阶段 II:融合图像生成
- 4. 红外与可见光图像融合(IVF)
- 4.1 数据集与实验设置
- 数据集
- 评估指标
- 实现细节
- 4.2 与最先进方法的比较
- 定性比较
- 定量比较
- 特征分解可视化
- 4.3 消融研究
- 实验I:分解损失形式验证
- 实验II:移除分解损失
- 实验III:基础特征用INN块
- 实验IV:细节特征用LT块
- 实验V:放弃两阶段训练
- 5. 医学图像融合(MIF)
- 5.1 实验设置
- 5.2 与最先进方法的比较
- 定性结果(图6)
- 定量结果(表5)
- 6. 结论

题目:CDDFuse: Correlation-Driven Dual-Branch Feature Decomposition for Multi-Modality Image Fusion
会议:Computer Vision and Pattern Recognition(CVPR)
论文:paper
代码:https://github.com/Zhaozixiang1228/MMIF-CDDFuse.
年份:2023
1&&2. 摘要&&引言
多模态图像融合旨在生成兼具不同模态优势的融合图像,例如功能性高亮信息和细节纹理。
为解决跨模态特征建模以及分解理想的模态特异性特征和模态共享特征这一挑战,我们提出了一种新颖的相关性驱动特征分解融合(CDDFuse)网络。
首先,CDDFuse 采用 Restormer 块提取跨模态浅层特征。随后,我们引入双分支 Transformer-CNN 特征提取器,其中轻量级 Transformer(LT)块利用长程注意力处理低频全局特征,可逆神经网络(INN)块专注于提取高频局部信息。
我们进一步提出一种相关性驱动损失,基于嵌入信息使低频特征具有相关性,同时使高频特征不相关。然后,基于 LT 的全局融合层和基于 INN 的局部融合层输出融合图像。
大量实验表明,我们的 CDDFuse 在包括红外 - 可见光图像融合和医学图像融合在内的多个融合任务中取得了优异结果。
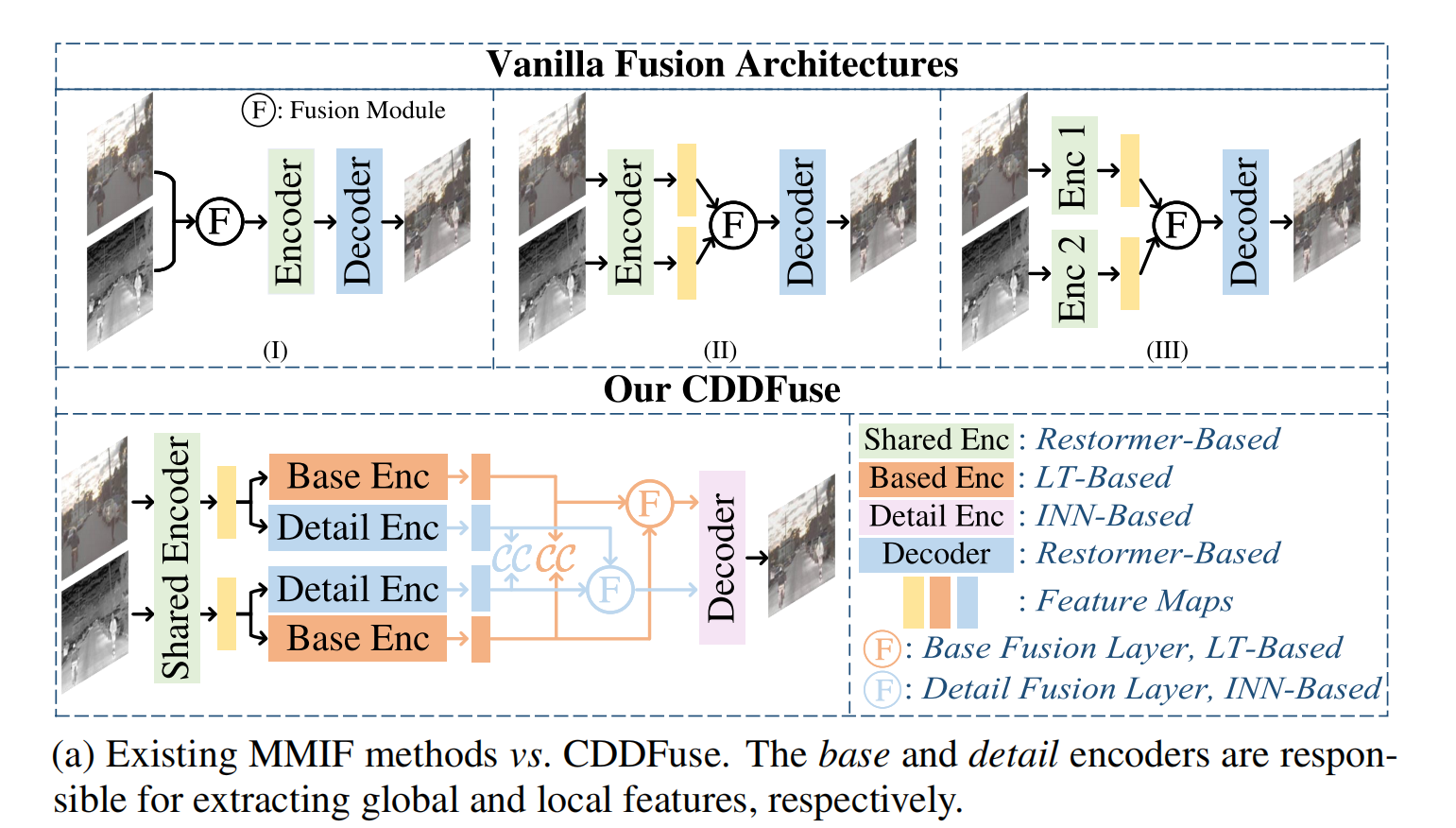
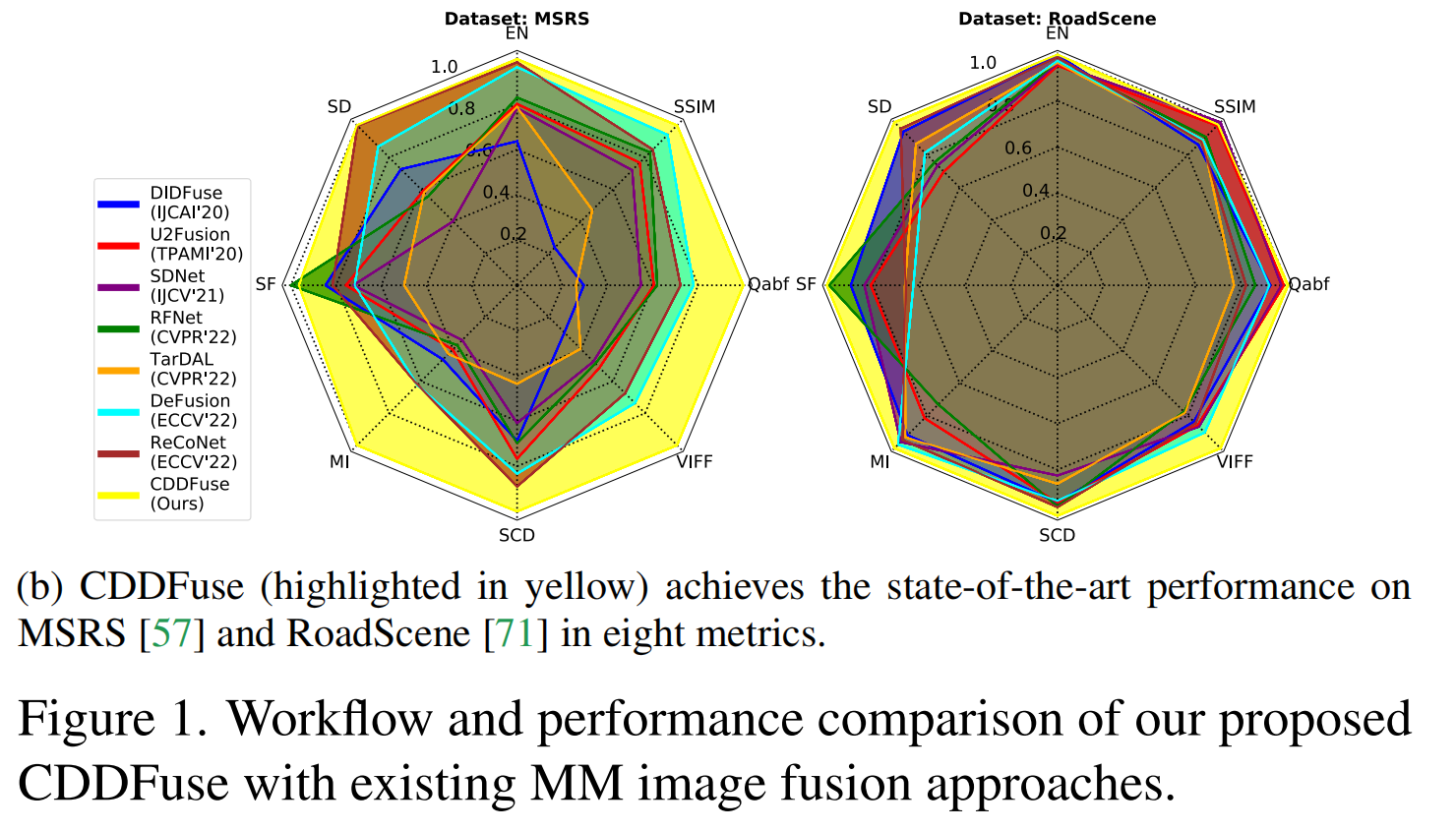
其工作流程如图 1a 和图 2 所示。我们的贡献可总结为四个方面:
- 我们提出了一种双分支 Transformer-CNN 框架,用于提取和融合全局和局部特征,更能体现不同的模态特异性和模态共享特征。
- 我们改进了 CNN 和 Transformer 块,使其更好地适应 MMIF 任务。具体而言,我们首次利用 INN 块实现无损信息传输,并利用 LT 块平衡融合质量和计算成本。
- 我们提出了一种相关性驱动的分解损失函数,用于强化模态共享 / 特异性特征的分解,使跨模态基础特征具有相关性,同时使不同模态中的详细高频特征不相关。
- 我们的方法在 IVF 和 MIF 中均实现了领先的图像融合性能。我们还提出了一个统一的测量基准,以证明 IVF 融合图像如何促进下游多模态目标检测和语义分割任务。
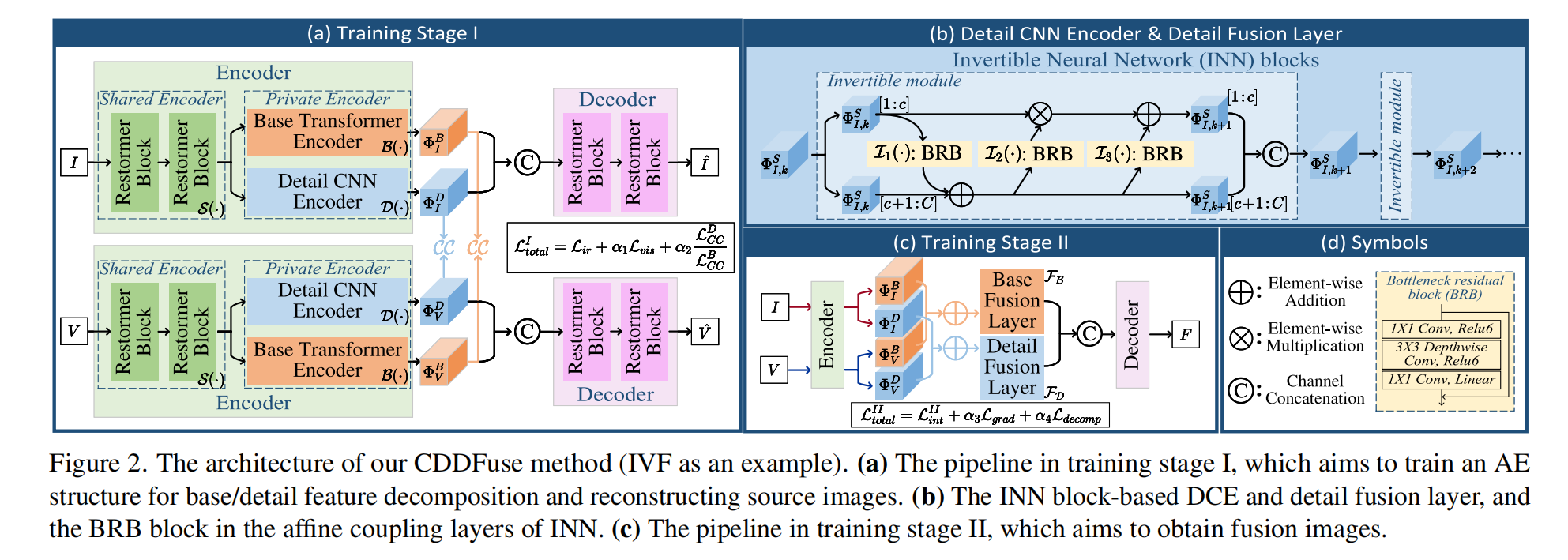
图2. 我们提出的CDDFuse方法的架构(以红外-可见光图像融合为例)。(a)训练阶段I的流程,旨在训练一个自编码器结构用于基础/细节特征分解和源图像重建。(b)基于可逆神经网络块的细节CNN编码器和细节融合层,以及可逆神经网络仿射耦合层中的瓶颈残差块。(c)训练阶段II的流程,旨在获得融合图像。
3. CDDFuse 模型设计
3.1 模型概述
CDDFuse 是一种通用的多模态图像融合网络,以红外-可见光融合(IVF)任务为例说明其工作原理。模型包含四大核心模块:
- 双分支编码器:用于特征提取与分解,包括共享特征编码器(SFE)、基础 Transformer 编码器(BTE)和细节 CNN 编码器(DCE);
- 基础/细节融合层:分别融合低频基础特征与高频细节特征;
- 解码器:根据训练阶段重建原始图像或生成融合图像;
- 两阶段训练策略:解决多模态融合任务中缺乏真值的挑战,通过分阶段优化提升融合性能。
3.2 编码器:多尺度特征提取与分解
编码器由三部分组成,分别负责浅层特征提取、低频基础特征提取和高频细节特征提取,具体设计如下:
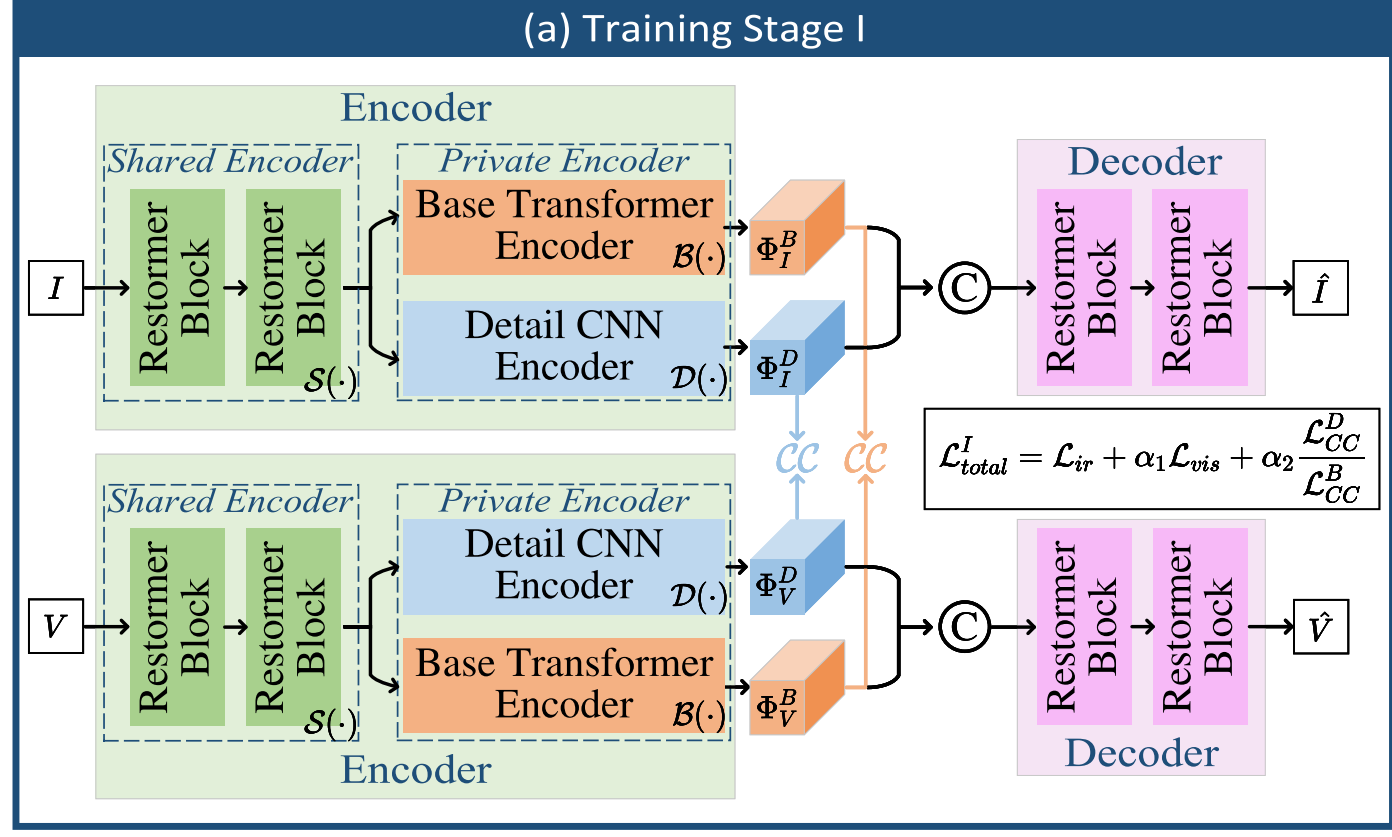
3.2.1 共享特征编码器(SFE)
- 结构:基于 Restormer 块构建,输入为红外图像 I∈RH×WI \in \mathbb{R}^{H \times W}I∈RH×W 和可见光图像 V∈RH×W×3V \in \mathbb{R}^{H \times W \times 3}V∈RH×W×3。
- 功能:提取跨模态浅层特征 {ΦIS,ΦVS}\{\Phi_I^S, \Phi_V^S\}{ΦIS,ΦVS},公式为:
ΦIS=S(I),ΦVS=S(V)(1)\Phi_I^S = \mathcal{S}(I), \quad \Phi_V^S = \mathcal{S}(V) \tag{1} ΦIS=S(I),ΦVS=S(V)(1) - 设计动机:Restormer 块通过在特征维度应用自注意力,能在高分辨率输入中提取全局特征,且计算量可控,适合跨模态浅层特征提取。
3.2.2 基础 Transformer 编码器(BTE)
- 结构:基于轻量级 Transformer(LT)块构建,输入为 SFE 输出的浅层特征 {ΦIS,ΦVS}\{\Phi_I^S, \Phi_V^S\}{ΦIS,ΦVS}。
- 功能:提取低频基础特征 {ΦIB,ΦVB}\{\Phi_I^B, \Phi_V^B\}{ΦIB,ΦVB},公式为:
ΦIB=B(ΦIS),ΦVB=B(ΦVS)(2)\Phi_I^B = \mathcal{B}(\Phi_I^S), \quad \Phi_V^B = \mathcal{B}(\Phi_V^S) \tag{2} ΦIB=B(ΦIS),ΦVB=B(ΦVS)(2) - 设计动机:LT 块通过扁平化 Transformer 的前馈网络结构,在缩小嵌入维度的同时保持性能,平衡了长距离依赖捕捉与计算效率。
3.2.3 细节 CNN 编码器(DCE)
- 结构:基于可逆神经网络(INN)块构建,输入为 SFE 输出的浅层特征 {ΦIS,ΦVS}\{\Phi_I^S, \Phi_V^S\}{ΦIS,ΦVS}。
- 功能:提取高频细节特征 {ΦID,ΦVD}\{\Phi_I^D, \Phi_V^D\}{ΦID,ΦVD},公式为(以红外图像为例):
ΦI,k+1S[c+1:C]=ΦI,kS[c+1:C]+I1(ΦI,kS[1:c]),ΦI,k+1S[1:c]=ΦI,kS[1:c]⊙exp(I2(ΦI,k+1S[c+1:C]))+I3(ΦI,k+1S[c+1:C]),ΦI,k+1S=CAT(ΦI,k+1S[1:c],ΦI,k+1S[c+1:C]),(3-5)\begin{aligned} \Phi_{I, k+1}^S[c+1:C] &= \Phi_{I, k}^S[c+1:C] + \mathcal{I}_1(\Phi_{I, k}^S[1:c]), \\ \Phi_{I, k+1}^S[1:c] &= \Phi_{I, k}^S[1:c] \odot \exp(\mathcal{I}_2(\Phi_{I, k+1}^S[c+1:C])) + \mathcal{I}_3(\Phi_{I, k+1}^S[c+1:C]), \\ \Phi_{I, k+1}^S &= \mathcal{CAT}(\Phi_{I, k+1}^S[1:c], \Phi_{I, k+1}^S[c+1:C]), \end{aligned} \tag{3-5} ΦI,k+1S[c+1:C]ΦI,k+1S[1:c]ΦI,k+1S=ΦI,kS[c+1:C]+I1(ΦI,kS[1:c]),=ΦI,kS[1:c]⊙exp(I2(ΦI,k+1S[c+1:C]))+I3(ΦI,k+1S[c+1:C]),=CAT(ΦI,k+1S[1:c],ΦI,k+1S[c+1:C]),(3-5)
其中 Ii\mathcal{I}_iIi 为 MobileNetV2 的瓶颈残差块(BRB),CAT\mathcal{CAT}CAT 为通道拼接操作。 - 设计动机:INN 块通过可逆变换(输入与输出相互生成)实现无损特征提取,适合保留边缘、纹理等高频细节信息。
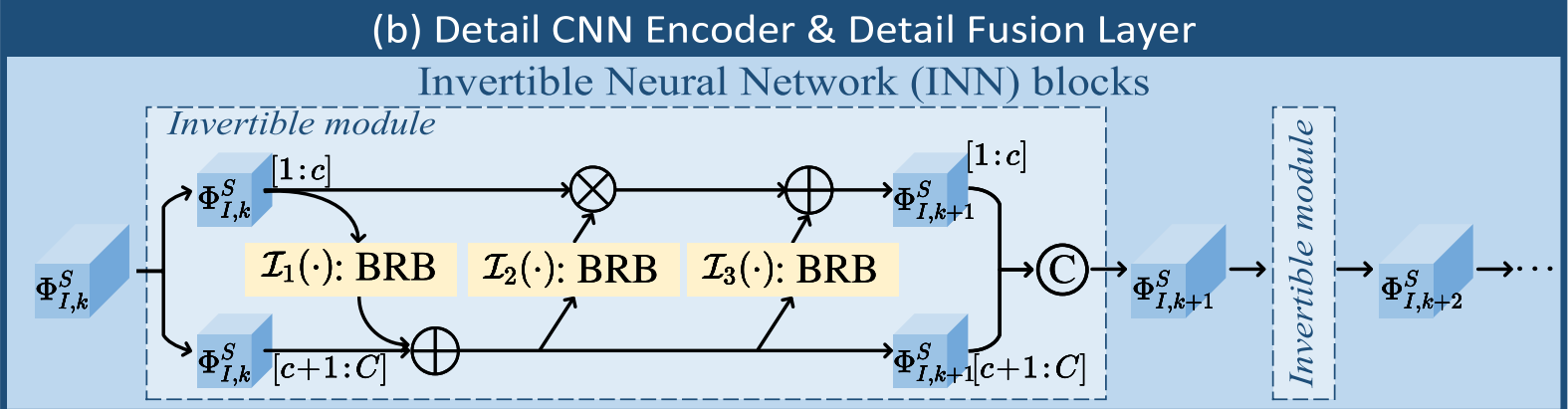
3.3 融合层:多频率特征融合
基础/细节融合层分别采用与编码器对应的 LT 块和 INN 块,确保融合过程的归纳偏置与特征提取一致:
- 基础融合层:融合低频基础特征 ΦIB\Phi_I^BΦIB 和 ΦVB\Phi_V^BΦVB,输出 ΦB\Phi^BΦB;
- 细节融合层:融合高频细节特征 ΦID\Phi_I^DΦID 和 ΦVD\Phi_V^DΦVD,输出 ΦD\Phi^DΦD。
3.4 解码器:特征重建与融合生成
解码器以 Restormer 块为基本单元,输入为拼接后的多频率特征,输出根据训练阶段不同而变化:
- 训练阶段 I:输入红外或可见光的低频+高频特征(ΦIB,ΦID\Phi_I^B, \Phi_I^DΦIB,ΦID 或 ΦVB,ΦVD\Phi_V^B, \Phi_V^DΦVB,ΦVD),输出重建的原图 I^\hat{I}I^ 或 V^\hat{V}V^;
- 训练阶段 II:输入融合后的低频+高频特征(ΦB,ΦD\Phi^B, \Phi^DΦB,ΦD),输出融合图像 FFF。
3.5 两阶段训练策略与损失函数
针对多模态融合任务缺乏真值的挑战,CDDFuse 采用两阶段训练方案,逐步优化编码器、融合层和解码器。
3.5.1 训练阶段 I:特征分解与原图重建
目标:训练编码器提取可分解的特征,并确保解码器能准确重建原图。
输入:成对的红外与可见光图像 {I,V}\{I, V\}{I,V}。
流程:
- 编码器提取浅层特征 {ΦIS,ΦVS}\{\Phi_I^S, \Phi_V^S\}{ΦIS,ΦVS};
- BTE 和 DCE 分别提取低频基础特征 {ΦIB,ΦVB}\{\Phi_I^B, \Phi_V^B\}{ΦIB,ΦVB} 和高频细节特征 {ΦID,ΦVD}\{\Phi_I^D, \Phi_V^D\}{ΦID,ΦVD};
- 红外或可见光的低频+高频特征输入解码器,重建原图 I^\hat{I}I^ 或 V^\hat{V}V^。
总损失:
LtotalI=Lir+α1Lvis+α2Ldecomp(6)\mathcal{L}_{\text{total}}^I = \mathcal{L}_{\text{ir}} + \alpha_1 \mathcal{L}_{\text{vis}} + \alpha_2 \mathcal{L}_{\text{decomp}} \tag{6} LtotalI=Lir+α1Lvis+α2Ldecomp(6)
-
重建损失(Lir,Lvis\mathcal{L}_{\text{ir}}, \mathcal{L}_{\text{vis}}Lir,Lvis):确保编码-解码过程信息无丢失,公式为:
Li=Linti+μLSSIMi,i∈{I,V}(7)\mathcal{L}_i = \mathcal{L}_{\text{int}}^i + \mu \mathcal{L}_{\text{SSIM}}^i, \quad i \in \{I, V\} \tag{7} Li=Linti+μLSSIMi,i∈{I,V}(7)
其中 Linti=∥I−I^∥22\mathcal{L}_{\text{int}}^i = \|I - \hat{I}\|_2^2Linti=∥I−I^∥22 为像素级 L2 损失,LSSIMi=1−SSIM(I,I^)\mathcal{L}_{\text{SSIM}}^i = 1 - \text{SSIM}(I, \hat{I})LSSIMi=1−SSIM(I,I^) 为结构相似性损失(SSIM 衡量结构一致性)。 -
特征分解损失(Ldecomp\mathcal{L}_{\text{decomp}}Ldecomp):引导基础特征(模态共享,高相关性)与细节特征(模态特异,低相关性)分离,公式为:
Ldecomp=(CC(ΦID,ΦVD))2CC(ΦIB,ΦVB)+ϵ(8)\mathcal{L}_{\text{decomp}} = \frac{(\mathcal{C}\mathcal{C}(\Phi_I^D, \Phi_V^D))^2}{\mathcal{C}\mathcal{C}(\Phi_I^B, \Phi_V^B) + \epsilon} \tag{8} Ldecomp=CC(ΦIB,ΦVB)+ϵ(CC(ΦID,ΦVD))2(8)
其中 CC(⋅,⋅)\mathcal{C}\mathcal{C}(\cdot, \cdot)CC(⋅,⋅) 为相关系数算子,ϵ=1.01\epsilon = 1.01ϵ=1.01 确保分母为正。该损失通过梯度下降使 CCD→0\mathcal{C}\mathcal{C}^D \to 0CCD→0(细节特征低相关)、CCB→大值\mathcal{C}\mathcal{C}^B \to \text{大值}CCB→大值(基础特征高相关)。
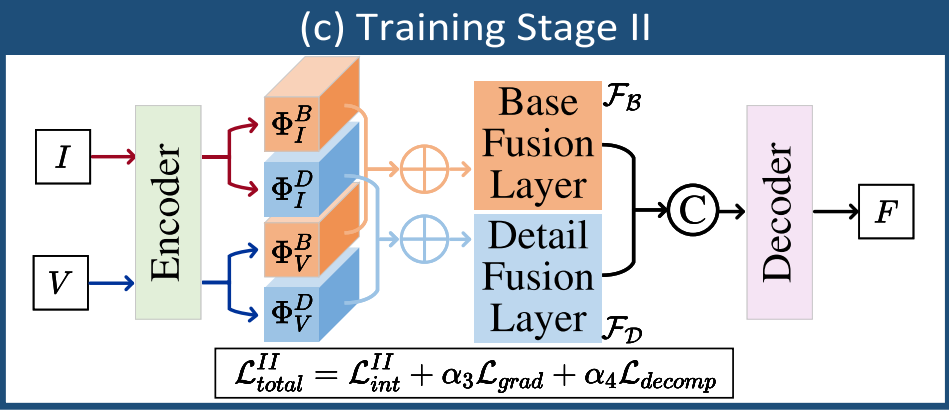
3.5.2 训练阶段 II:融合图像生成
目标:基于已训练的编码器,优化融合层以生成高质量的融合图像。
输入:成对的红外与可见光图像 {I,V}\{I, V\}{I,V}(编码器参数冻结)。
流程:
- 编码器提取分解后的低频+高频特征 {ΦIB,ΦID,ΦVB,ΦVD}\{\Phi_I^B, \Phi_I^D, \Phi_V^B, \Phi_V^D\}{ΦIB,ΦID,ΦVB,ΦVD};
- 基础融合层和细节融合层分别融合低频与高频特征,得到 ΦB\Phi^BΦB 和 ΦD\Phi^DΦD;
- 解码器输入 ΦB\Phi^BΦB 和 ΦD\Phi^DΦD,生成融合图像 FFF。
总损失:
LtotalII=LintII+α3Lgrad+α4Ldecomp(9)\mathcal{L}_{\text{total}}^{\text{II}} = \mathcal{L}_{\text{int}}^{\text{II}} + \alpha_3 \mathcal{L}_{\text{grad}} + \alpha_4 \mathcal{L}_{\text{decomp}} \tag{9} LtotalII=LintII+α3Lgrad+α4Ldecomp(9)
- 结构相似性损失(LintII\mathcal{L}_{\text{int}}^{\text{II}}LintII):衡量融合图像与原图的最大强度一致性,公式为:
LintII=1HW∥If−max(Iir,Ivis)∥1(10)\mathcal{L}_{\text{int}}^{\text{II}} = \frac{1}{HW} \|I_f - \max(I_{\text{ir}}, I_{\text{vis}})\|_1 \tag{10} LintII=HW1∥If−max(Iir,Ivis)∥1(10) - 梯度损失(Lgrad\mathcal{L}_{\text{grad}}Lgrad):保持融合图像的边缘清晰度,公式为:
Lgrad=1HW∥∣ablaIf∣−max(∣ablaIir∣,∣ablaIvis∣)∥1(11)\mathcal{L}_{\text{grad}} = \frac{1}{HW} \left\| | abla I_f| - \max(| abla I_{\text{ir}}|, | abla I_{\text{vis}}|) \right\|_1 \tag{11} Lgrad=HW1∥∣ablaIf∣−max(∣ablaIir∣,∣ablaIvis∣)∥1(11)
其中 ∇\nabla∇ 为索贝尔梯度算子,max(∣∇Iir∣,∣∇Ivis∣)\max(|\nabla I_{\text{ir}}|, |\nabla I_{\text{vis}}|)max(∣∇Iir∣,∣∇Ivis∣) 表示原图边缘强度的最大值。
4. 红外与可见光图像融合(IVF)
4.1 数据集与实验设置
数据集
实验使用三个主流基准数据集验证模型性能:
- MSRS:训练集(1083对),测试集(361对);
- RoadScene:验证集(50对),测试集(50对);
- TNO:测试集(25对)。
所有数据集均未微调,以验证模型泛化能力。
评估指标
采用8个定量指标衡量融合质量(值越高越好):
- 熵(EN):衡量图像信息丰富度;
- 标准差(SD):反映图像灰度分布均匀性;
- 空间频率(SF):评估图像细节丰富度;
- 互信息(MI):衡量融合图像与原图的互补信息保留程度;
- 差异相关和(SCD):评估融合图像与原图的差异相关性;
- 视觉信息保真度(VIF):衡量视觉感知信息保留量;
- QAB/FQ^{AB/F}QAB/F:多模态融合质量指标;
- 结构相似性指数(SSIM):评估结构一致性。
实现细节
- 硬件:配备两块 NVIDIA GeForce RTX 3090 GPU;
- 预处理:训练样本随机裁剪为128×128补丁;
- 训练参数:
- Epoch数:120(阶段I:40 epoch,阶段II:80 epoch);
- 批量大小:16;
- 优化器:Adam(初始学习率 10−410^{-4}10−4,每20 epoch衰减0.5);
- 网络超参数:
- SFE:4个Restormer块(8注意力头,64维度);
- BTE:LT块(64维度,8注意力头);
- 解码器:与编码器结构一致;
- 损失函数参数:α1=1,α2=2,α3=10,α4=2\alpha_1=1, \alpha_2=2, \alpha_3=10, \alpha_4=2α1=1,α2=2,α3=10,α4=2(平衡各损失项量级)。
4.2 与最先进方法的比较
定性比较


图3和图4展示了CDDFuse与DIDFuse、U2Fusion、SDNet、RFNet、TarDAL、DeFusion、ReCoNet的融合结果:
- 优势:CDDFuse更好地融合了红外的热辐射信息与可见光的纹理细节,黑暗区域目标清晰突出,背景细节边缘锐利、轮廓丰富,场景理解性更强。
定量比较
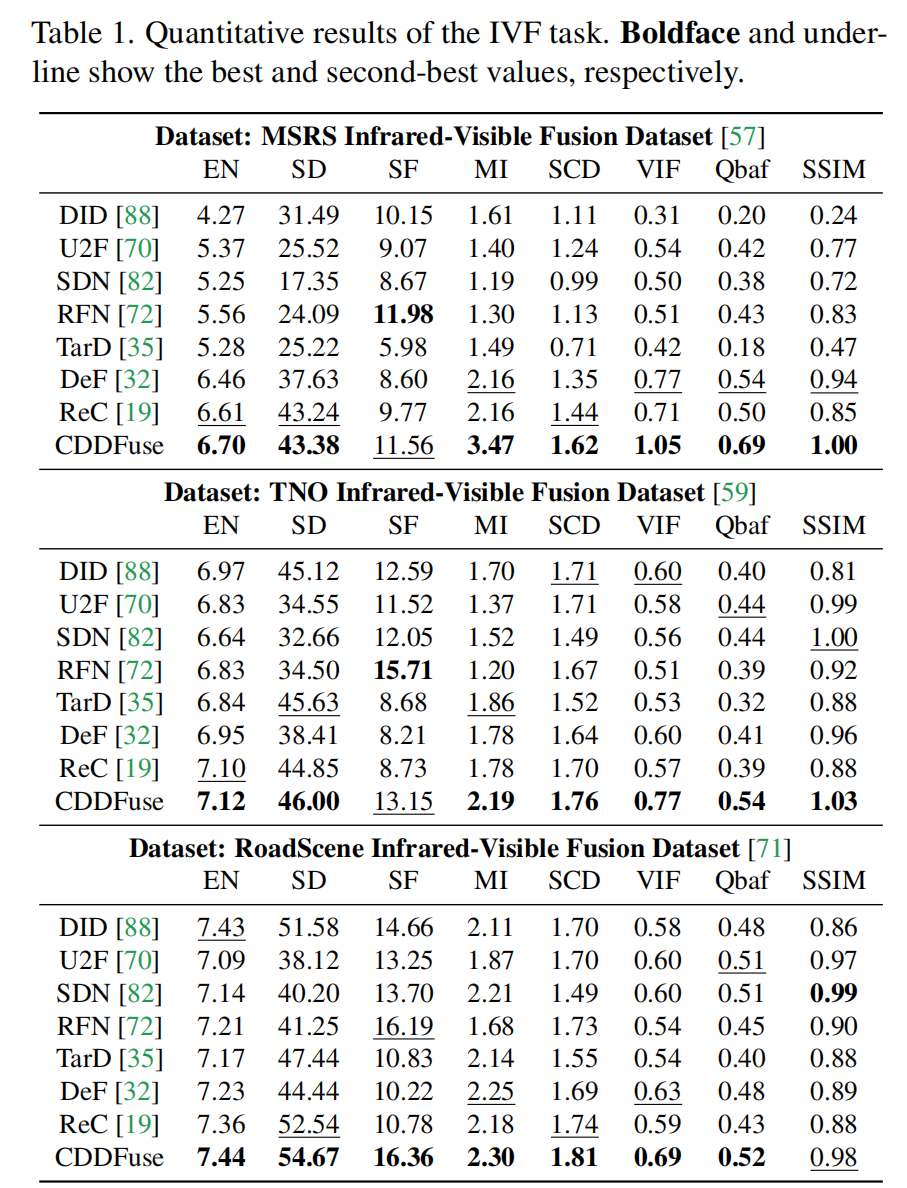
表1显示CDDFuse在MSRS、RoadScene、TNO测试集上的8个指标均表现优异(加粗为最优),验证了其对多光照、多目标场景的普适性。
特征分解可视化

图5可视化分解后的特征:
- 基础特征:背景信息激活区域高度相关(模态共享);
- 细节特征:红外关注高亮区域,可见光关注纹理细节(模态特异性)。
结果与“相关性驱动分解”的设计目标一致。
4.3 消融研究
为验证网络设计的合理性,开展5组消融实验(表2),使用EN、SD、VIF、SSIM评估:
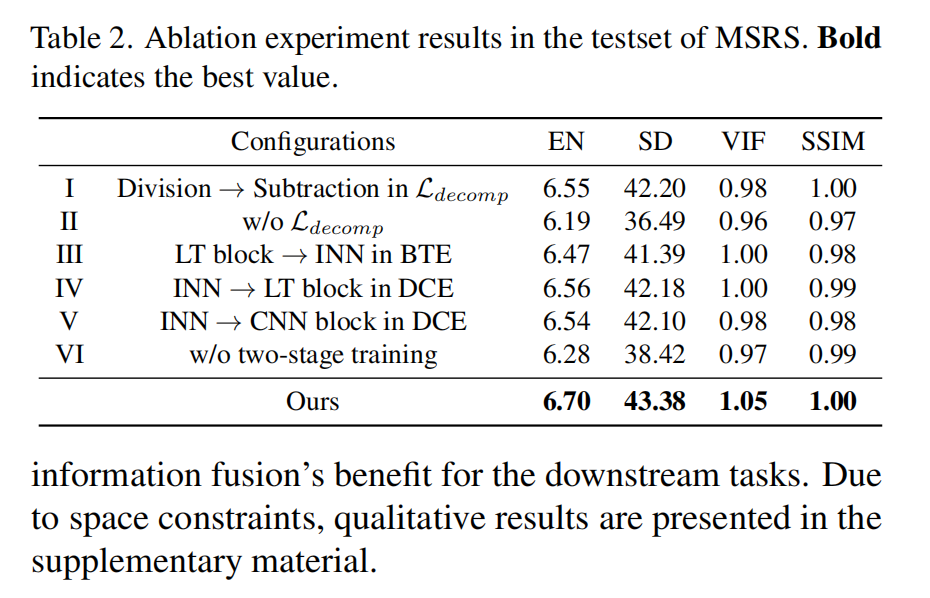
实验I:分解损失形式验证
- 修改:将式(9)的除法损失改为减法(Ldecomp=(LCCD)2−L~CCBL_{\text{decomp}} = (L_{CC}^D)^2 - \tilde{L}_{CC}^BLdecomp=(LCCD)2−L~CCB)。
- 结果:性能略降,说明原损失(除法驱动高相关基础特征、低相关细节特征)更有效。
实验II:移除分解损失
- 修改:不使用 LdecompL_{\text{decomp}}Ldecomp。
- 结果:特征分解失效(BTE与DCE无法学习差异化频率特征),融合性能显著下降。
实验III:基础特征用INN块
- 修改:BTE的LT块替换为INN块。
- 结果:性能略低于原模型(LT块在长距离依赖捕捉上更优)。
实验IV:细节特征用LT块
- 修改:DCE的INN块替换为LT块。
- 结果:信息丢失严重(CNN的局部感知限制了细节保留)。
实验V:放弃两阶段训练
- 修改:直接联合训练编码器、解码器、融合层。
- 结果:训练难度大、鲁棒性差,融合质量显著降低。
结论:消融实验验证了双分支编码器(LT+INN)、相关性驱动分解损失、两阶段训练策略的有效性。
5. 医学图像融合(MIF)
5.1 实验设置
- 数据集:从哈佛医学网站选取286对MRI多模态图像(130训练,20验证;测试集:21对MRI-CT、42对MRI-PET、73对MRI-SPECT);
- 训练策略:与IVF任务相同(数据增强、超参数、损失函数);
- 比较方法:
- 跨任务泛化组:在IVF训练的CDDFuse、TarDAL、RFNet、DeFusion、ReCoNet(未微调);
- 任务专用组:在MIF训练的CDDFuse*、U2Fusion、SDNet、EMFusion(均在MIF数据集训练)。
5.2 与最先进方法的比较
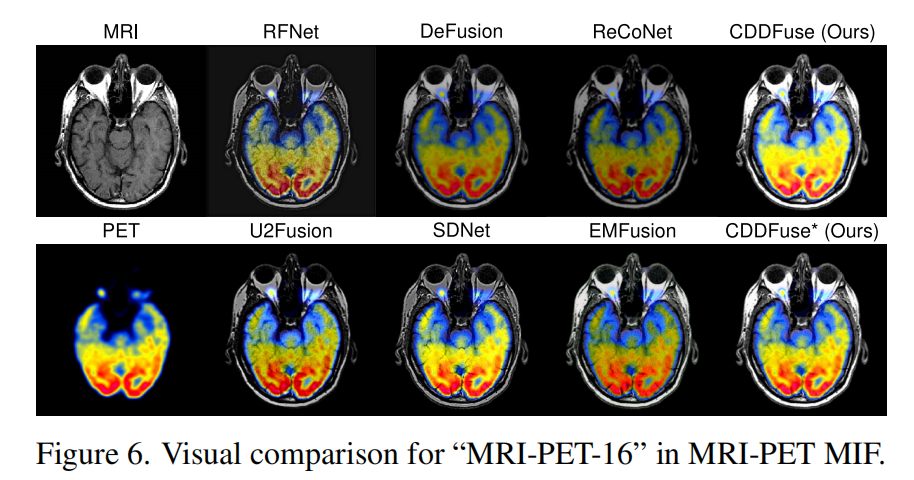
定性结果(图6)
CDDFuse(无论是否在MIF训练)均能保留MRI的解剖细节(如器官边界)与CT/SPECT/PET的功能信息(如代谢活性),纹理清晰、结构准确。
定量结果(表5)
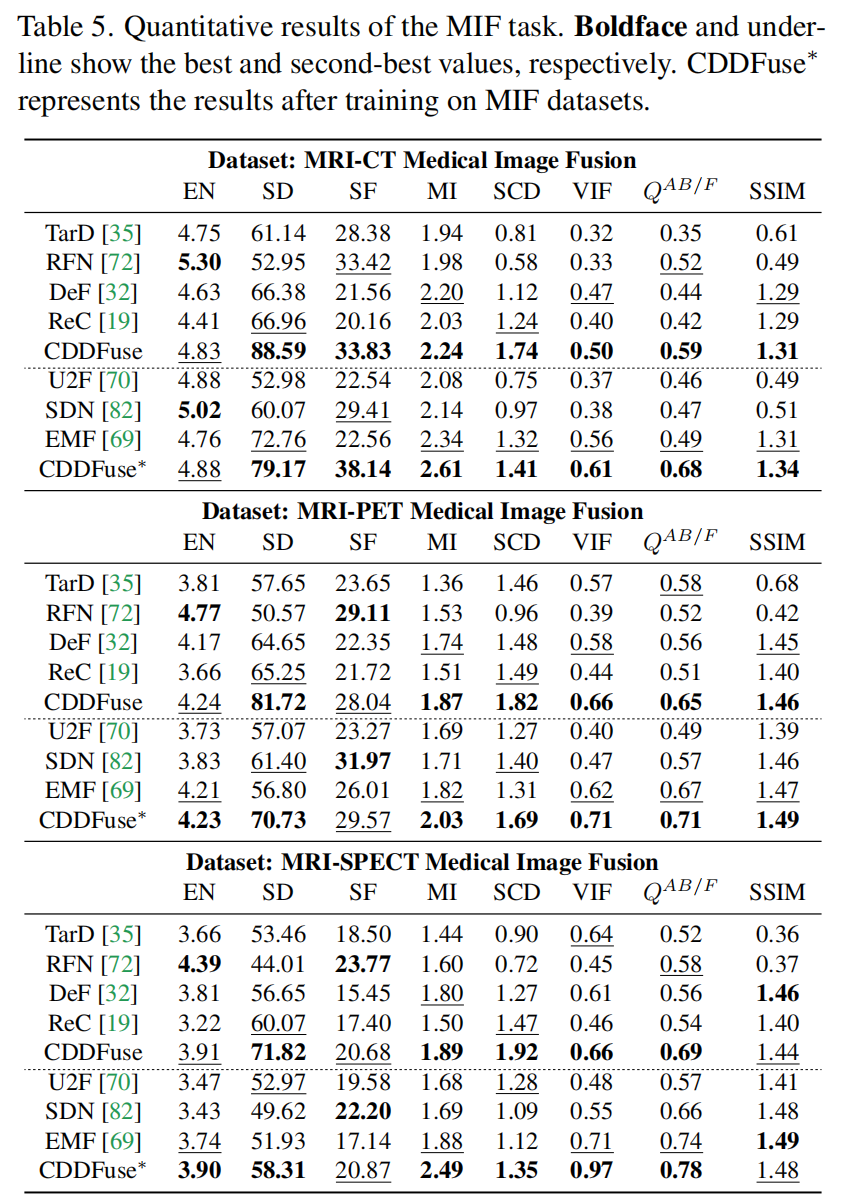
- 跨任务泛化组:CDDFuse在8个指标上均领先(如SSIM比次优方法高3.2%);
- 任务专用组:CDDFuse*进一步优化(如VIF比U2Fusion高5.1%),验证其对医学多模态数据的适配性。
6. 结论
本文提出了一种双分支Transformer-CNN架构(CDDFuse)用于多模态图像融合,核心贡献如下:
- 多尺度特征提取:通过Restormer(浅层)、LT块(低频基础)、INN块(高频细节)协同,实现模态共享与特异性特征的高效分离;
- 相关性驱动分解:利用互信息相关系数损失(LdecompL_{\text{decomp}}Ldecomp),引导基础特征(高相关)与细节特征(低相关)的直观分解;
- 两阶段训练策略:先分解特征后生成融合,降低训练难度并提升鲁棒性。
实验表明,CDDFuse在IVF(MSRS、RoadScene、TNO)和MIF(MRI-CT、MRI-PET等)任务中均表现最优,显著提升了融合图像的信息保留与结构一致性,为下游多模态识别任务提供了高质量输入。