Spring AI 系列之十四 - RAG-ETL之一
之前做个几个大模型的应用,都是使用Python语言,后来有一个项目使用了Java,并使用了Spring AI框架。随着Spring AI不断地完善,最近它发布了1.0正式版,意味着它已经能很好的作为企业级生产环境的使用。对于Java开发者来说真是一个福音,其功能已经能满足基于大模型开发企业级应用。借着这次机会,给大家分享一下Spring AI框架。
注意:由于框架不同版本改造会有些使用的不同,因此本次系列中使用基本框架是 Spring AI-1.0.0,JDK版本使用的是19。
代码参考: https://github.com/forever1986/springai-study
目录
- 1 ETL Pipeline
- 2 DocumentReaders说明
- 3 DocumentReaders示例演示
- 3.1 JsonReader
- 3.2 TextReader
- 3.3 JsoupDocumentReader
- 3.4 MarkdownDocumentReader
- 3.5 PagePdfDocumentReader
- 3.6 ParagraphPdfDocumentReader
- 3.7 TikaDocumentReader
如果你熟悉或者读过我之前写的《RAG实践》,应该知道RAG有一段非常重要的步骤,就是文档解析。在我之前写的《检索增强生成RAG系列3–RAG优化之文档处理》中详细的讲述了不同解析工具以及RAG中对文档分块技术。接下来几章将对Spring AI 中的文档解析技术使用进行讲解,在Spring AI中叫做:ETL Pipeline
1 ETL Pipeline
从文档到向量数据库是RAG的前置条件,而文档到数据库有几个步骤非常重要。
- 1)文档读取:文档可能包括pdf、Excel、图片等等各种各样的内容,而这些内容中包括很多不同的格式,比如pdf中可能还包括表格和图片,因此选择哪些文档读取的工具非常重要。
- 2)文档分块:由于大模型有token长度限制同时过长的token其实对于大模型的理解和推理会变慢或者不准确,因此需要将文档分块。对于如何分块,如何不会将原本有关联的语句分隔开也是文档向量化的重要步骤。
- 3)文档embedding:对于不同语言,不同的embedding模型有着不同效果,这一块参照我之前写的文章《检索增强生成RAG系列3–RAG优化之文档处理》提到的实战经验选择适合自己的embedding模型。
- 4)向量数据库:向量数据库的存储和相似度查询的准确性也可能会影响RAG最终的结果。
那么在这一套流程中,Spring AI称为ETL Pipeline,流程如下图:

- DocumentReader:实现 Supplier<List> 接口;用于读取文档。
- DocumentTransformer :实现 Function<List和List>接口;用于文档的分块转换。
- DocumentWriter :实现Consumer<List>接口;用于将转换后的文档写入存储(包括向量数据库)。
2 DocumentReaders说明
之前使用Python语言的Pytorch框架中各种各样的文档解析工具,特别羡慕。现在有了Spring AI,也集成了很多不同文档解析工具,使用起来非常方便。以下是已经支持的文档读取器
| DocumentReaders | 描述 | 需要引入依赖 |
|---|---|---|
| JsonReader | 用于读取Json格式的数据,并将其转换为一系列Document对象。 | 内置 |
| TextReader | 处理纯文本文档,并将其转换为一系列Document对象。 | 内置 |
| JsoupDocumentReader | 用于处理 HTML 文档,并利用 JSoup 库将这些文档转换为一系列的 Document 对象。 | spring-ai-jsoup-document-reader |
| MarkdownDocumentReader | 会处理 Markdown格式文档,并将其转换为一系列的 Document 对象。 | spring-ai-markdown-document-reader |
| PagePdfDocumentReader | 使用 Apache PdfBox 库来解析 PDF 文档。 | spring-ai-pdf-document-reader |
| ParagraphPdfDocumentReader | 同样也是基于 Apache PdfBox 库,但是不同的是ParagraphPdfDocumentReader 会利用 PDF 目录(例如目录)中的信息将输入的 PDF 文件拆分成文本段落,并为每个段落生成一个单独的文档(注意:并非所有 PDF 文件都包含 PDF 目录)。 | spring-ai-pdf-document-reader |
| TikaDocumentReader | 通过使用 Apache Tika 技术从各种文档格式(如 PDF、DOC/DOCX、PPT/PPTX 和 HTML)中提取文本。 | spring-ai-tika-document-reader |
3 DocumentReaders示例演示
以下示例代码参考lesson13子模块的com.demo.lesson13.reader包下代码
3.1 JsonReader
1)pom中引入commons插件
<dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-commons</artifactId>
</dependency>
2) json文件内容
[{ "id": 1, "name": "小王", "age": 25 },{ "id": 2, "name": "小李", "age": 24 }
]
3)代码
import org.springframework.ai.document.Document;
import org.springframework.ai.reader.JsonReader;
import org.springframework.core.io.ClassPathResource;
import org.springframework.core.io.Resource;import java.util.List;public class JsonReaderTest {public static void main(String[] args){Resource resource = new ClassPathResource("data/jsonreaderdata.json");// 1.获取全部数据JsonReader jsonReader1 = new JsonReader(resource);List<Document> documents1 = jsonReader1.get();int i =0;for (Document document : documents1){System.out.println("--------"+(++i)+"--------");System.out.println(document.getText());}System.out.println("=======================");// 2.获取其中某些字段JsonReader jsonReader2 = new JsonReader(resource,"id","name");List<Document> documents2 = jsonReader2.get();i =0;for (Document document : documents2){System.out.println("--------"+(++i)+"--------");System.out.println(document.getText());}System.out.println("=======================");// 3.路径+值获取某一条数据List<Document> documents3 = jsonReader2.get("/0"); //获取第一条i =0;for (Document document : documents3){System.out.println("--------"+(++i)+"--------");System.out.println(document.getText());}}
}
4)演示效果:

说明:从上图可以看到
1)JsonReader会根据数组转换为多个文档
2)可以指定返回的key,则是返回一个key-value的数据,而非json
3)指定返回某个文档,同样也是返回一个key-value的数据,而非json
3.2 TextReader
1)pom中引入commons插件
<dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-commons</artifactId>
</dependency>
2)文件内容
The Spring AI project aims to streamline the development of applications that incorporate artificial intelligence functionality without unnecessary complexity.
3)代码
import org.springframework.ai.document.Document;
import org.springframework.ai.reader.TextReader;
import org.springframework.core.io.ClassPathResource;
import org.springframework.core.io.Resource;import java.util.List;public class TextReaderTest {public static void main(String[] args) {String fileName = "data/textreaderdata.txt";Resource resource = new ClassPathResource(fileName);// 获取全部数据TextReader textReader = new TextReader(resource);// 设置Metadata数据,可用于检索后确认来自哪个文档textReader.getCustomMetadata().put("filename", fileName);List<Document> documents = textReader.get();for (Document document : documents){System.out.println(document.getMetadata().get("filename"));System.out.println(document.getText());}}
}
4)演示效果

说明:从上图可以看到
1)第一行输出的是metadata(元数据)的内容,这个是代码中用户自己加入的。这个元数据对于后续RAG非常重要,可以溯源,也可以作为检索关键标签
2)TextReader会将整个text作为一个文档输出
3.3 JsoupDocumentReader
1)pom中引入jsoup插件
<dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-jsoup-document-reader</artifactId>
</dependency>
2)文件内容
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><title>My Web Page</title><meta name="description" content="A sample web page for Spring AI"><meta name="keywords" content="spring, ai, html, example"><meta name="author" content="John Doe"><meta name="date" content="2024-01-15"><link rel="stylesheet" href="style.css">
</head>
<body>
<header><h1>Welcome to My Page</h1>
</header>
<nav><ul><li><a href="/">Home</a></li><li><a href="/about">About</a></li></ul>
</nav>
<article><h2>Main Content</h2><p>This is the main content of my web page.</p><p>It contains multiple paragraphs.</p><a href="https://www.example.com">External Link</a>
</article>
<footer><p>© 2024 John Doe</p>
</footer>
</body>
</html>
3)代码
import org.springframework.ai.document.Document;
import org.springframework.ai.reader.jsoup.JsoupDocumentReader;
import org.springframework.ai.reader.jsoup.config.JsoupDocumentReaderConfig;
import org.springframework.core.io.ClassPathResource;
import org.springframework.core.io.Resource;import java.util.List;public class JsoupReaderTest {public static void main(String[] args) {Resource resource = new ClassPathResource("data/jsoupreaderdata.html");JsoupDocumentReaderConfig config = JsoupDocumentReaderConfig.builder().selector("article p") // 通过selector,标记只获取什么标签内容,这里是提取<article>标签的p(p在html代表段落).charset("ISO-8859-1") // 使用 ISO-8859-1 编码.includeLinkUrls(true) // 在metadata(元数据)中包括LinkURL.metadataTags(List.of("author", "date")) // 提取author和date到metadata(元数据).additionalMetadata("source", "data/jsoupreaderdata.html") // 添加一个用户自定义的metadata(元数据),这把文件名放入.build();JsoupDocumentReader jsoupDocumentReader = new JsoupDocumentReader(resource, config);List<Document> documents = jsoupDocumentReader.get();int i =0;for (Document document : documents){System.out.println("--------"+(++i)+"--------");System.out.println(document.getMetadata().keySet());System.out.println(document.getText());}}
}
4)演示效果

说明:从上图可以看到
1)第一行打印的是metadata(元数据),包括前面author、date等,还有自己加入的source
2)解析了html的article标签下的所有p段落
3.4 MarkdownDocumentReader
1)pom中引入markdown插件
<dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-markdown-document-reader</artifactId>
</dependency>
2)文件内容
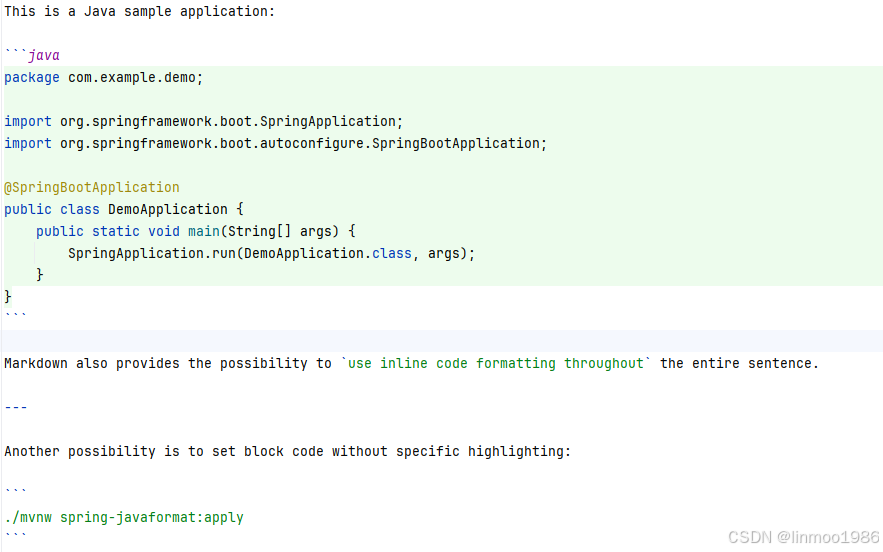
3)代码
import org.springframework.ai.document.Document;
import org.springframework.ai.reader.markdown.MarkdownDocumentReader;
import org.springframework.ai.reader.markdown.config.MarkdownDocumentReaderConfig;
import org.springframework.core.io.ClassPathResource;
import org.springframework.core.io.Resource;import java.util.List;public class MarkdownReaderTest {public static void main(String[] args) {Resource resource = new ClassPathResource("data/markdownreaderdata.md");MarkdownDocumentReaderConfig config = MarkdownDocumentReaderConfig.builder().withHorizontalRuleCreateDocument(true) //当设置为 true 时,Markdown中的水平分隔线"---",将创建新的 Document 对象。.withIncludeCodeBlock(false) //当设置为 true 时,代码块将包含在与周围文本相同的文档中。当设置为 false 时,代码块会创建单独的文档对象。.withIncludeBlockquote(false) //当设置为 true 时,引用块将与周围的文本包含在同一个文档中。当设置为 false 时,引用块将创建单独的文档对象。.withAdditionalMetadata("filename", "markdownreaderdata.md")//允许您向所有创建的“文档”对象添加自定义元数据。.build();MarkdownDocumentReader markdownDocumentReader = new MarkdownDocumentReader(resource, config);List<Document> documents = markdownDocumentReader.get();int i = 0;for (Document document : documents){System.out.println("--------"+(++i)+"--------");System.out.println(document.getMetadata().keySet());System.out.println(document.getText());}}
}
4)演示效果
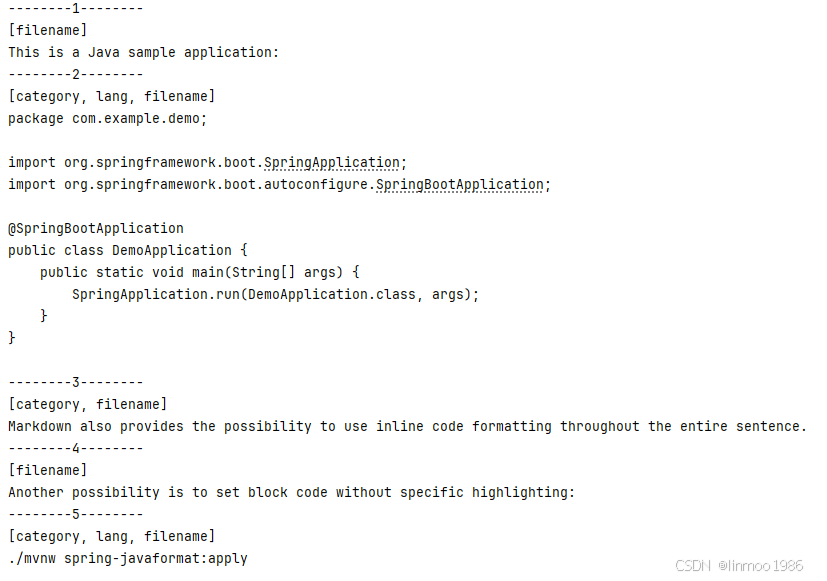
说明:从上图可以看到
1)代码模块被分割为一个独立文档,因为withIncludeCodeBlock(false)设置为false,所以代码模块会被新起一个文档
2)第3和第4个文档是通过分割线“—”隔开,因为withHorizontalRuleCreateDocument(true)设置为true,遇到分割线"—"就会新起一个文档
3)最后第5个文档是引用模块,因为withIncludeBlockquote(false)设置为false,所以引用模块会被新起一个文档
4)除了增加的metadata(元数据)之外,MarkdownDocumentReader会根据文本类型自动加入一些metadata(元数据)
3.5 PagePdfDocumentReader
1)pom中引入pdf插件
<dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-pdf-document-reader</artifactId>
</dependency>
2)文件内容:参考resources/data目录下的pagepdfreaderdata.pdf附件
3)代码
import org.springframework.ai.document.Document;
import org.springframework.ai.reader.ExtractedTextFormatter;
import org.springframework.ai.reader.pdf.PagePdfDocumentReader;
import org.springframework.ai.reader.pdf.config.PdfDocumentReaderConfig;
import org.springframework.core.io.ClassPathResource;
import org.springframework.core.io.Resource;import java.util.List;public class PagePdfReaderTest {public static void main(String[] args) {Resource resource = new ClassPathResource("data/pagepdfreaderdata.pdf");PagePdfDocumentReader pdfReader = new PagePdfDocumentReader(resource,PdfDocumentReaderConfig.builder().withPageTopMargin(0).withPageExtractedTextFormatter(ExtractedTextFormatter.builder().withNumberOfTopTextLinesToDelete(0).build()).withPagesPerDocument(1) // 如果设置为0,则表示所有页都变成一个文档.build());List<Document> documents = pdfReader.get();int i = 0;for (Document document : documents){System.out.println("--------"+(++i)+"--------");System.out.println(document.getMetadata().keySet());System.out.println(document.getText());}}}
4)演示效果

说明:从上图可以看到
1)第一行是metadata(元数据)
2)pdf中每一页都会被解析为一个document。这是因为withPagesPerDocument(1)设置为1,表示一页一个文档,如果设置为0,则所有页都在一个文档中
3)在pdf第一页中有一张图片,但是没有解析出来。
4)PagePdfDocumentReader 是基于[Apache PDFBox,具体使用方式可以参考《Apache PDFBox官方网站》。关于PDF的解析,是一个比较复杂的,也有各种各样的解析方式,主要还需参考自己的PDF格式,没有一种工具可以很好的解析所有PDF。
3.6 ParagraphPdfDocumentReader
1)pom中引入pdf插件
<dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-pdf-document-reader</artifactId>
</dependency>
2)文件内容:参考resources/data目录下的paragraphpdfreaderdata.pdf附件
3)代码
import org.springframework.ai.document.Document;
import org.springframework.ai.reader.ExtractedTextFormatter;
import org.springframework.ai.reader.pdf.ParagraphPdfDocumentReader;
import org.springframework.ai.reader.pdf.config.PdfDocumentReaderConfig;
import org.springframework.core.io.ClassPathResource;
import org.springframework.core.io.Resource;import java.util.List;public class ParagraphPdfReaderTest {public static void main(String[] args) {Resource resource = new ClassPathResource("data/paragraphpdfreaderdata.pdf");ParagraphPdfDocumentReader pdfReader = new ParagraphPdfDocumentReader(resource,PdfDocumentReaderConfig.builder().withPageTopMargin(0).withPageExtractedTextFormatter(ExtractedTextFormatter.builder().withNumberOfTopTextLinesToDelete(0).build()).withPagesPerDocument(1) // 如果设置为0,则表示所有页都变成一个文档.build());List<Document> documents = pdfReader.get();int i = 0;for (Document document : documents){System.out.println("--------"+(++i)+"--------");System.out.println(document.getMetadata().keySet());System.out.println(document.getText());}}}
4)演示效果
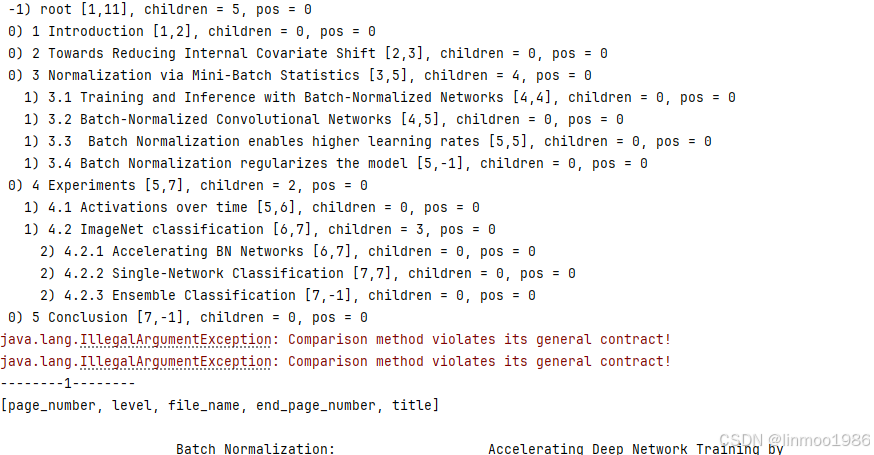
说明:从上图可以看到
1)可以看到其会先输出PDF的整体目录情况
2)按照段落一页一页的解析,这个是更为精确的,类似python中的pdfplumer。更合适格式化较好的论文解析
3)ParagraphPdfDocumentReader是基于[Apache PDFBox,具体使用方式可以参考《Apache PDFBox官方网站》
3.7 TikaDocumentReader
1)pom中引入tika插件
<dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-tika-document-reader</artifactId>
</dependency>
2)文件内容:参考resources/data目录下的tikareaderdata.docx附件
3)代码
import org.springframework.ai.document.Document;
import org.springframework.ai.reader.ExtractedTextFormatter;
import org.springframework.ai.reader.pdf.ParagraphPdfDocumentReader;
import org.springframework.ai.reader.pdf.config.PdfDocumentReaderConfig;
import org.springframework.ai.reader.tika.TikaDocumentReader;
import org.springframework.core.io.ClassPathResource;
import org.springframework.core.io.Resource;import java.util.List;public class TikaReaderTest {public static void main(String[] args) {Resource resource = new ClassPathResource("data/tikareaderdata.docx");TikaDocumentReader tikaDocumentReader = new TikaDocumentReader(resource);List<Document> documents = tikaDocumentReader.get();int i = 0;for (Document document : documents){System.out.println("--------"+(++i)+"--------");System.out.println(document.getMetadata().keySet());System.out.println(document.getText());}}}
4)演示效果

说明:从上图可以看到
1)解析doc文档,是整个一起解析的
2)Tika是基于 Apache Tika的,其可以解析很多类型的文档,这一块参考《Apache Tika官方网站》
结语:本章介绍了Spring AI的ETL框架,其很好支持RAG的开发。并着重对DocumentReaders部分的各个插件进行示例演示。下一章将继续讲解Spring AI的ETL框架中的Transformers和Writers模块
Spring AI系列上一章:《Spring AI 系列之十三 - RAG-加载本地嵌入模型》
Spring AI系列下一章:《Spring AI 系列之十五 - RAG-ETL之二》