多模态学习路线(3)——MLLMs主流大模型
目录
前言
Reference
一、视觉基础大模型
1. VIT (2021)
2. MoCo (v1-2020,v3-2021)
3. SimCLR (2020)
4. MAE (2022)
5. DINO (2021)
6. SAM (2023, 2024)
6.1. Segment Anything (2023)
6.2. SAM 2: Segment Anything in Images and Videos (2024)
二、多模态主流大模型
1. CLIP
1.1. CLIP (2021)
1.2. CN-CLIP / Chinese-CLIP(2023)
1.3. SigLIP (2023)
1.4. EVA-CLIP (2023)
2. BLIP
2.1. BLIP (2022)
2.2. BLIP2 (2023)
2.3. Instruct-BLIP (2023)
3. ALBEF (2021)
4. Flamingo (2022)
5. CogVLM
5.1. CogVLM (2023)
5.2. CogVLM2 (2024)
5.3. CogVLM v.s. CogVLM2
7. LIaVA系列
8. Llama系列
8.0. LLama 3(前言)
8.1. Llama 3.2 (2024.9)
8.2. Llama 4 (2025.4)
8.3. LLaVA,Llama 3.2和Llama 4对比
9. Qwen-VL系列
9.1. Qwen-VL 1.0(2023.10)
9.2. Qwen2-VL(2024.8)
9.3. Qwen2.5-VL(2025)
10. InternVL系列
10.1. InternVL 1.0(2023)
10.2. InternVL 1.5(2024)
10.3. InternVL 2.0(2024.9)
10.4. InternVL 2.5(2025)
11. Deepseek系列
11.1. DeepSeek VL系列
(1)DeepSeek VL (2024.3)
(2)DeepSeek VL2 (2024.12)
(3)DeepSeek-VL和DeepSeek-VL2对比
11.2. Janus系列
(1)Janus (2024.10)
(2)JanusFlow (2025.3)
(3)Janus-Pro (2025.6)
(4)Janus系列对比(Janus,JanusFlow,Janus-Pro)
三、Others
1. ImageBind (2023)
2. PandaGPT
3. Grouding DINO
前言
一、视觉基础大模型:VIT、MoCo、SimCLR、MAE、DINO、SAM;
二、多模态主流大模型:CLIP(CLIP,CN-CLIP,SigLIP,EVA-CLIP),BLIP(BLIP,BLIP2,Instruct-BLIP),ALBEF,Flamingo,CogVLM(CogVLM,CogVLM2),LIaVA系列,Llama系列(LLama 3.2,Llama 4),Qwen-VL系列,InternVL系列,Deepseek系列(DeepseekVL系列,Janus系列);
三、Others:ImageBind,PandaGPT,Grouding DINO。
注:(1)全文约3万字,写文耗时大约5天,慎点!!!(2)仅用于个人学习笔记(侵删)。
Reference
1. (27 封私信) 多模态大模型 CLIP, BLIP, BLIP2, LLaVA, miniGPT4, InstructBLIP 系列解读 - 知乎
2. VIT (Vision Transformer)深度讲解_哔哩哔哩_bilibili
3. 不愧是前科大讯飞工程师!1小时讲透【多模态大模型】从 CLIP 到 blip2模型!比刷狂飙还爽!_哔哩哔哩_bilibili
4. AI视觉大模型教程(LLM+多模态+SAM+视觉Prompt+CV+学习路线图)从入门到实战简直配享太庙!_哔哩哔哩_bilibili
5. 论文解读(SimCLR)《A Simple Framework for Contrastive Learning of Visual Representations》 - 别关注我了,私信我吧 - 博客园
一、视觉基础大模型
1. VIT (2021)
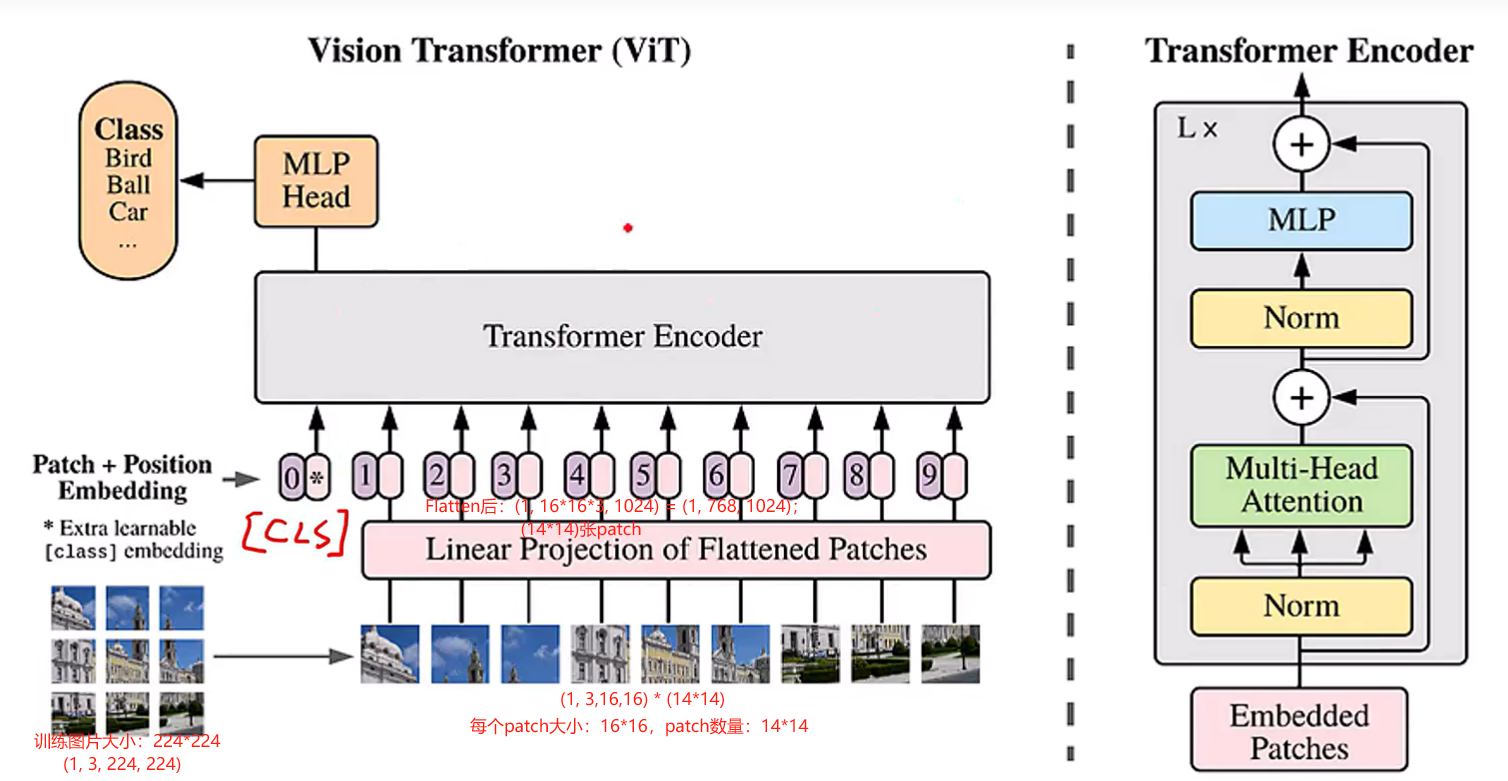
paper: [2010.11929] An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
github: deep-learning-for-image-processing/pytorch_classification/vision_transformer/vit_model.py at master · WZMIAOMIAO/deep-learning-for-image-processing · GitHub
图像转化为Embedding序列两种实现方式:训练图片大小为224*224,patch大小为16*16,patch数量为14*14。Transformer里的特征维度(Hidden Size)为1024。如下两个操作是完全等价的。
- 线性映射:将原始图片拆分为多个patch,对于每个patch,shape为(16,16,3),展开为一个长度为768的一维向量,然后通过一个共享的(768,1024)的线性层进行编码。
- 卷积操作:nn.Conv2d(in_c, embed_dim, kernel_size=patch_size, stride=patch_size)。[B, c_in, H, W]-->[B, embed_dim, H/patch_size, W/patch_size],embed_dim = c_in * patch_size * patch_size。
2. MoCo (v1-2020,v3-2021)
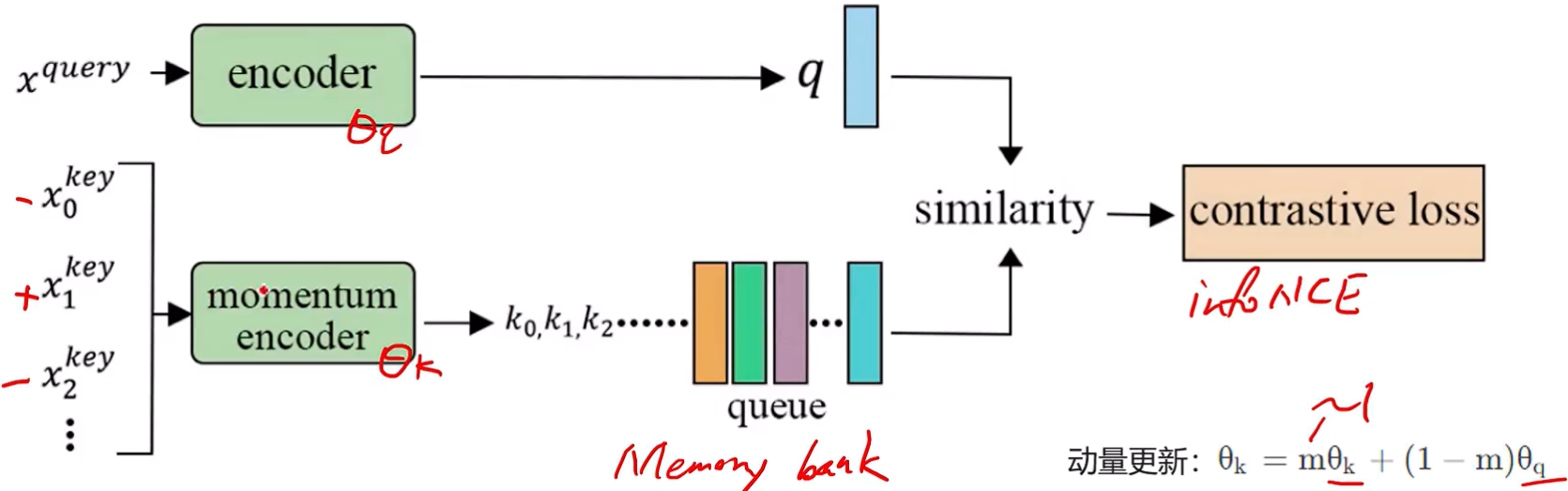
图2.1 MoCO v1
paper: [1911.05722] Momentum Contrast for Unsupervised Visual Representation Learning
github: GitHub - facebookresearch/moco: PyTorch implementation of MoCo: https://arxiv.org/abs/1911.05722
基本思想 (v1):MoCo(Momentum Contrast) v1是基于对比学习的无监督视觉表示学习方法,通过构建动态Memory Queue和动量编码器,实现高效的无监督预训练,为后续的视觉任务提供了强大的特征提取能力。在这个框架中:(1)输入图像经过数据增强后生成查询(query)样本;(2)字典中存储着键(key)样本及其特征表示;(3)模型的目标是使查询与其匹配的键(正样本)在特征空间中尽可能接近,同时与其他键(负样本)尽可能远离;
模型结构 (v1):
- 数据增强模块:对每张输入图像x,分别应用两种不同的随机增强得到x_q(查询)和x_k(键),构成正样本对。随机增强方法包括:随机裁剪并调整回原始大小、随机颜色失真、随机高斯模糊(GaussianBlur)。
- 编码器:查询编码器Encoder(q),动量编码器Momentum Encoder(k)。Encoder(k)采用Encoder(q)的动量更新版本,更新公式如下:
![]()
- 动态Memory Queue:存储历史batch的键特征k遵循FIFO原则,新特征入队时最老的特征出队,提供大量负样本用于对比学习。
- 损失函数:InfoNCE Loss,其中q是查询特征,k+是正样本键特征(同一图像的不同增强),k-是负样本键特征(队列中的其他图像特征),τ是温度参数,控制分布的尖锐程度。
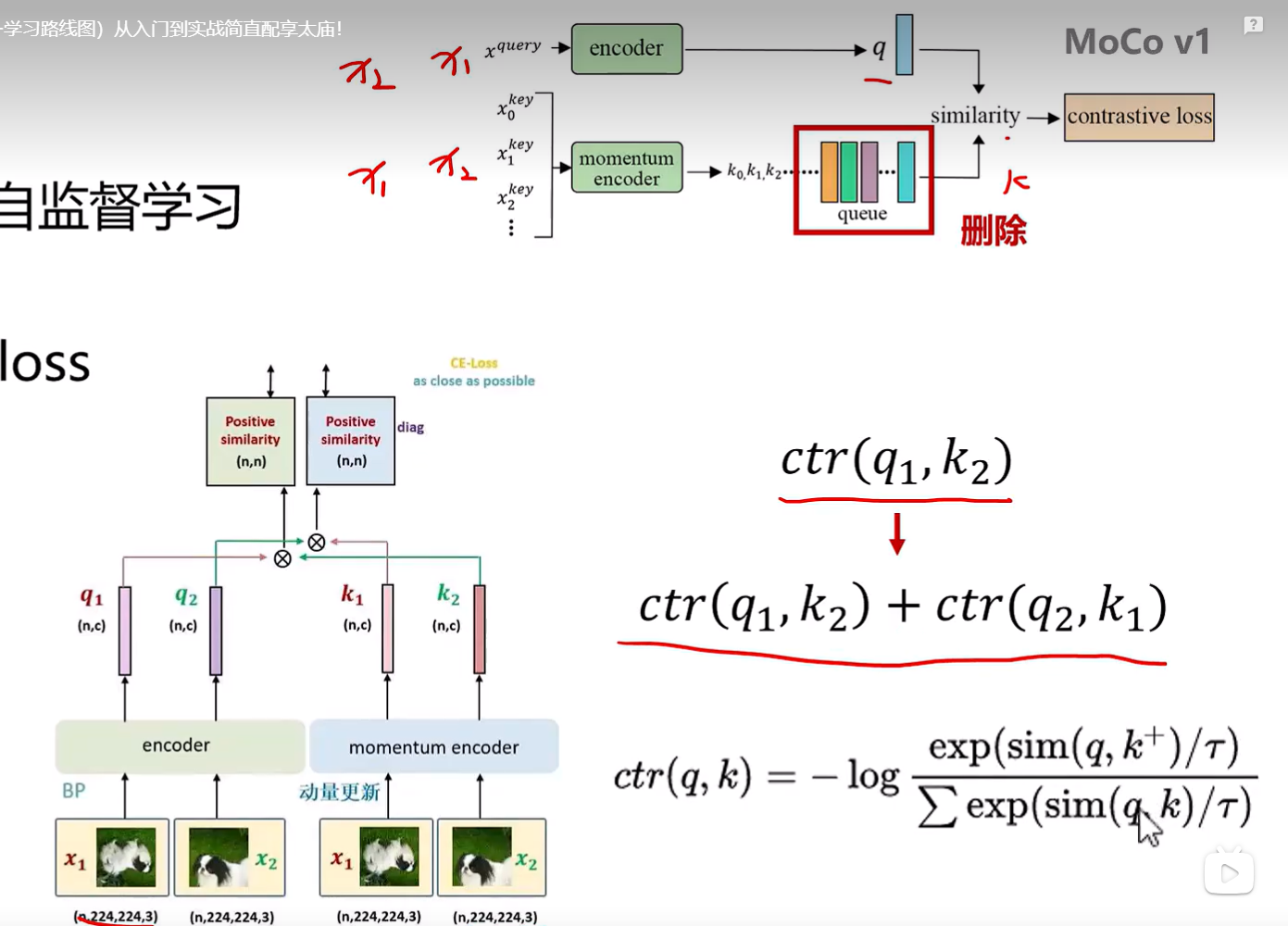
图2.2 MoCO v3
paper: [2104.02057] An Empirical Study of Training Self-Supervised Vision Transformers
github: GitHub - facebookresearch/moco-v3: PyTorch implementation of MoCo v3 https//arxiv.org/abs/2104.02057
MoCo v3改进:1)v3取消内存银行(Memory Bank/Memory Queue),使用更大的batch_size(4096)替代;2)双向对比Loss; 3) v1 Encoder使用ResNet-50,v3 Encoder使用VIT;4)v3数据输入不再是完整图片,而是被分割为image patches;5)v1训练关注点在构建大字典,v3训练关注点通过ViT适配+稳定性改进来解决不稳定性。
3. SimCLR (2020)
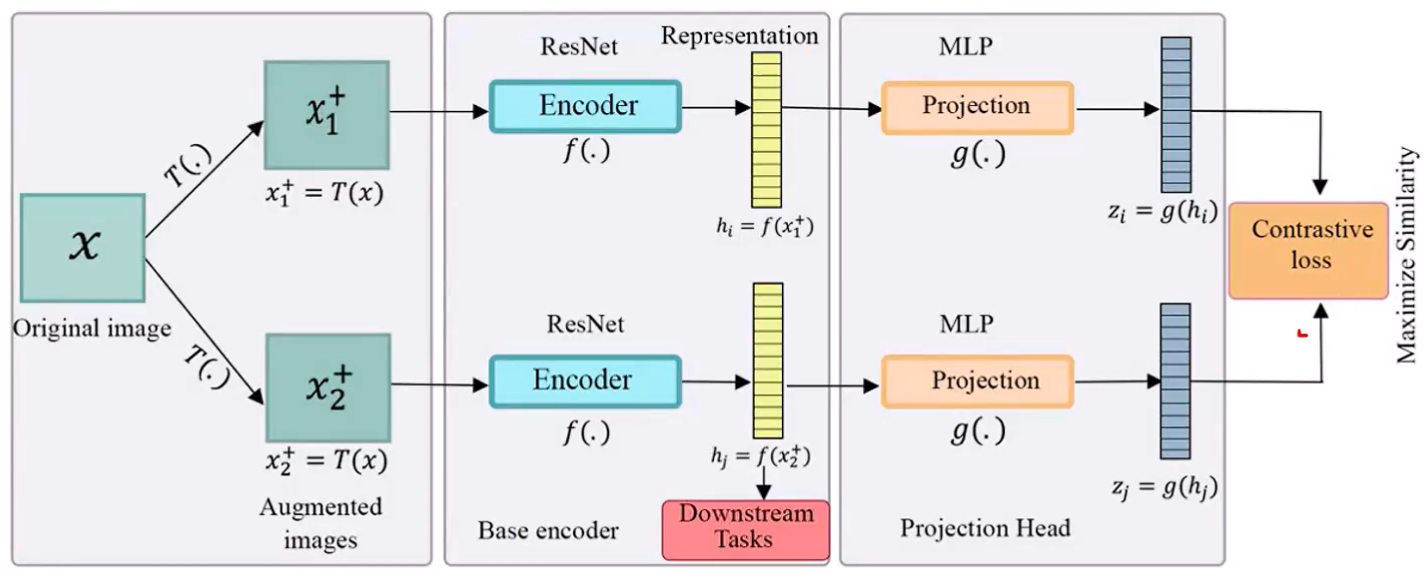
图3
paper: A Simple Framework for Contrastive Learning of Visual Representations
github: GitHub - google-research/simclr: SimCLRv2 - Big Self-Supervised Models are Strong Semi-Supervised Learners
基本思想:SimCLR 的核心思想是对比学习,即通过比较不同实例之间的相似性和差异性来进行学习。对比学习中,输入数据被分为正样本对(同一batch的同一图片数据经过不同的数据增强)和负样本对(同一batch的其他图片),通过比较样本之间的差异来提取特征。
如图3所示,(1)通过对每张输入图片 x 进行随机数据增强 T(.),生成两个不同的数据增强后的图x1,x2;(2)通过Encoder(ResNet-50)操作 f(.) 提取图x1,x2的特征表示hi,hj(hi,hj的特征表示用于Downsteam Tasks);(3)hi,hj通过MLP操作 g(.) 线性投影为zi, zj,然后使用对比损失函数(InfoNCE Loss)最大化正样本对(x1,x2)的相似度,最小化负样本对(同一batch的其他图片)的相似度。
模型结构: SimCLR框架由以下四个主要组件构成。
-
随机数据增强模块:随机裁剪并调整回原始大小(random cropping and resize back)、随机颜色失真(color distortions,亮度、对比度、饱和度和色调的变化)、随机高斯模糊(random Gaussian blur)。实验证明,随机裁剪和颜色失真的数据最好。
-
编码器(Encoder):编码器 f(·) 通常使用ResNet-50,负责从增强后的数据样本中提取representation vector。公式中,hᵢ ∈ ℝᵈ是平均池化层的输出。编码器将输入图像映射到一个潜在表示空间,捕获图像的高级特征。
![]()
-
投影头(Projection Head):投影头 g(·) 是一个小型神经网络,通常是一个带有一个隐藏层的MLP,用于将表示映射到对比损失应用的空间。其计算过程为:
![]()
- 对比损失函数(Contrastive Loss):使用InfoNCE Loss最大化正样本对(x1,x2)的相似度,最小化负样本对(同一batch的其他图片)的相似度。InfoNCE Loss代码手撕详见:多模态学习路线(2)——DL基础系列-CSDN博客
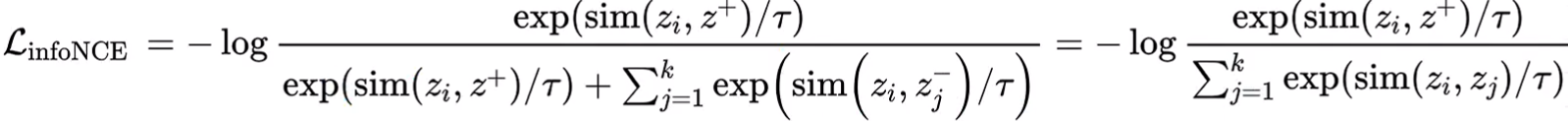
![]()
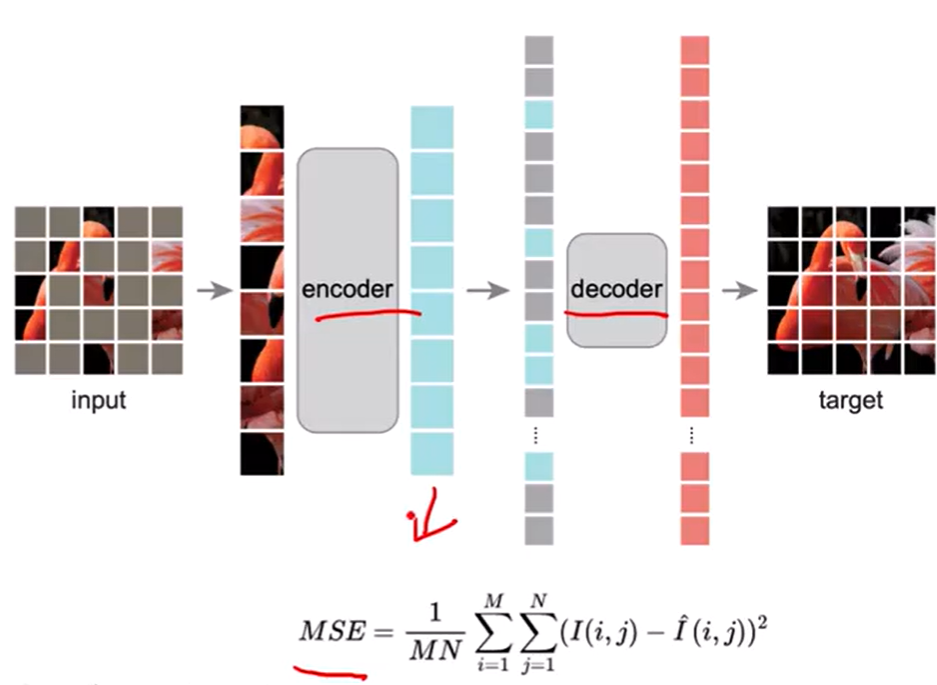
4. MAE (2022)
paper: [2111.06377] Masked Autoencoders Are Scalable Vision Learners
github: GitHub - facebookresearch/mae: PyTorch implementation of MAE https//arxiv.org/abs/2111.06377
基本思想:MAE(Masked AutoEncoders)为自监督学习,通过高比例随机Mask(75%)图像块并重建缺失像素来学习有效的视觉特征表示。预训练流程:输入图像→随机Mask 75%块→编码器处理25%可见块→解码器重建全部像素。损失函数:像素空间的Mask Area的MSE Loss并反向传播。
模型结构:MAE采用非对称的编码器-解码器架构。
- 遮蔽模块(随机Mask):将输入图像分割为规则的不重叠图像块(如16×16像素)按,均匀分布随机采样25%的块保留,其余75%被随机Mask,遮蔽策略是完全的,避免引入中心偏置等偏差;
- 编码器(Encoder):Encoder使用VIT架构,仅处理未被遮蔽的25%图像块,显著减少计算量;
- 解码器(Decoder):重建全部像素。Decoder输入为latent space编码器输出的可见图像块(patches)的特征表示+可学习的掩码标记(mask tokens);输出为重建后的图像(pixel space)。
- 重建目标:通过预测每个被遮蔽块的像素值来重建输入图像,损失函数采用像素空间中的均方误差(MSE),仅在被遮蔽块上计算。
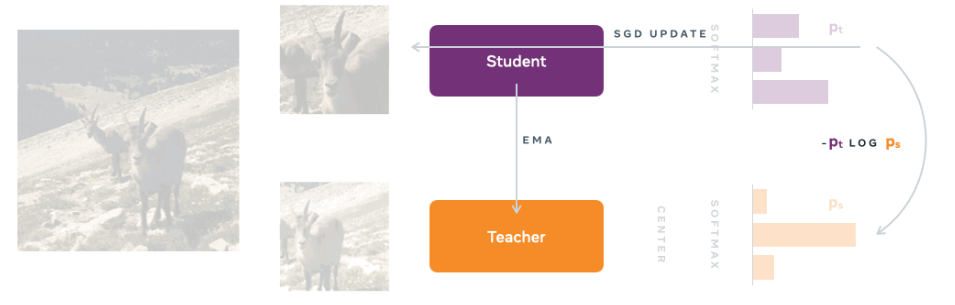
5. DINO (2021)
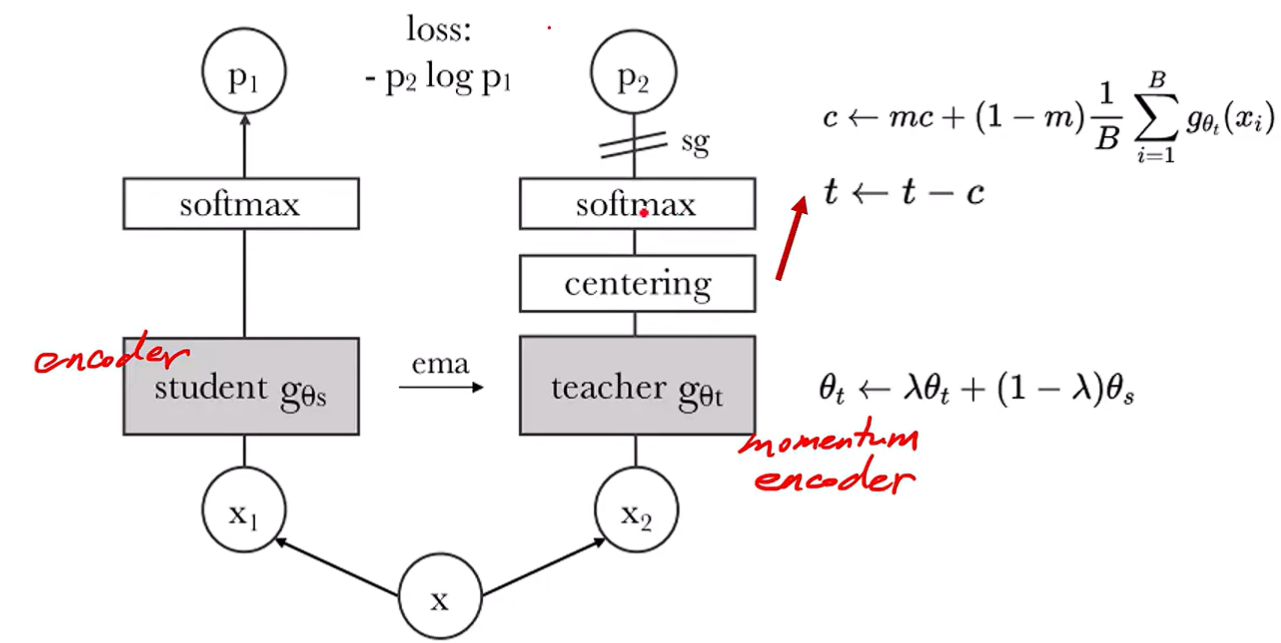
paper: 2104.14294
github: GitHub - facebookresearch/dino: PyTorch code for Vision Transformers training with the Self-Supervised learning method DINO
基本思想:DINO(Knowledge Distillation with No Labels)是一种创新的自监督知识蒸馏框架。通过反向传播让Student网络学习Teacher网络的特征表示,Teacher网络又通过EMA(θₜ ← λθₜ + (1-λ)θₛ)更新参数,无需任何人工标注。关键机制:
-
自蒸馏:同一图像的不同增强视图分别输入Student和Teacher网络,最小化二者输出的交叉熵损失(等价于KL散度)。
-
动态Teacher网络:Teacher网络参数通过Student网络的EMA(θₜ ← λθₜ + (1-λ)θₛ)更新,保持稳定性。
-
防坍塌设计:通过中心化(Centering)和锐化(Sharpening)避免所有输出收敛到相同向量。
模型结构:
-
双分支架构:(1)Student网络:VIT架构,输入为强数据增强图像;(2)Teacher网络:VIT架构,输入为弱数据增强图像。参数更新:EMA从学生网络同步参数(θₜ ← λθₜ + (1-λ)θₛ)
-
处理流程:(1)特征提取:两网络均使用ViT或ResNet提取特征;(2)概率分布:特征经投影头(MLP)和softmax(带温度参数τ)输出概率分布(p₁和p₂);(3)损失计算:最小化交叉熵损失-p2 * log(p1)(数学等价KL散度优化)。
-
关键组件:(1)中心化:教师输出减去滑动平均均值(防止特征坍塌,保持模型稳定性);(3)温度参数:教师τₜ < 学生τₛ,使教师分布更尖锐。
6. SAM (2023, 2024)
6.1. Segment Anything (2023)
paper: 2304.02643
github: GitHub - facebookresearch/segment-anything: The repository provides code for running inference with the SegmentAnything Model (SAM), links for downloading the trained model checkpoints, and example notebooks that show how to use the model.
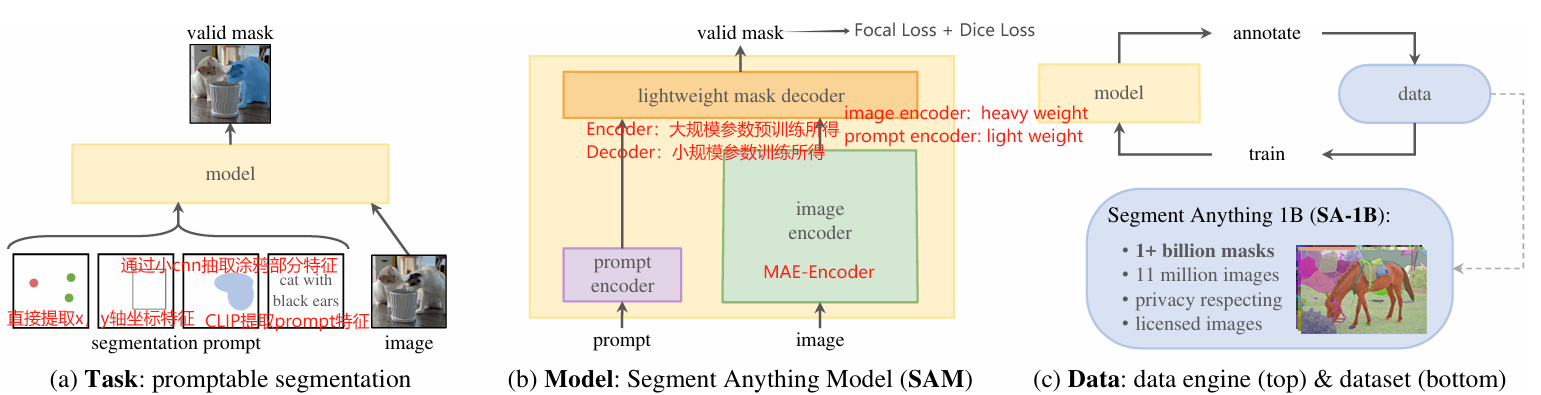
基本思想:SAM(Segment Anything Model)构建通用的"提示式分割"模型,能够根据各种形式的提示(点、框、文本等)分割图像中的对象;通过大规模预训练实现zero-shot迁移到新任务和新领域。
模型结构:
- Image Encoder:Heavy Weight,基于MAE预训练的Encoder(ViT架构)。输入为1024×1024分辨率的图像,输出为64×64×256的特征图(16*16个patch块)。
- Prompt Encoder:Light Weight,处理多种提示类型,包括点、框提示(位置嵌入)、掩码/涂鸦提示(卷积嵌入)、文本提示(CLIP编码)。
- LightWeight Mask Decoder:将图像特征和提示特征映射到分割掩码,包含2层Transformer解码器。输出为256×256分辨率的掩码。
- 损失函数:Focal Loss + Dice Loss。
- Focal Loss数学公式如下,用于解决不平衡的二类别问题,输出通过Sigmoid压缩到[0,1]概率。通过权重α和聚焦参数γ,减少易分类样本的损失贡献,解决类别不平衡问题。
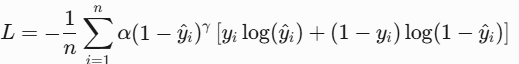
- Dice Loss(类似IOU)数学公式如下,其中pi是第i个像素的预测概率(经过sigmoid或softmax),gi是第i个像素的真实标签(0或1),ϵ是平滑项(通常取1e-5到1e-7),防止分母为零。
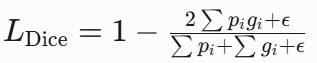
- Focal Loss数学公式如下,用于解决不平衡的二类别问题,输出通过Sigmoid压缩到[0,1]概率。通过权重α和聚焦参数γ,减少易分类样本的损失贡献,解决类别不平衡问题。
- 实时计算:图像编码只需计算一次,不同提示可实时生成对应分割结果。
6.2. SAM 2: Segment Anything in Images and Videos (2024)
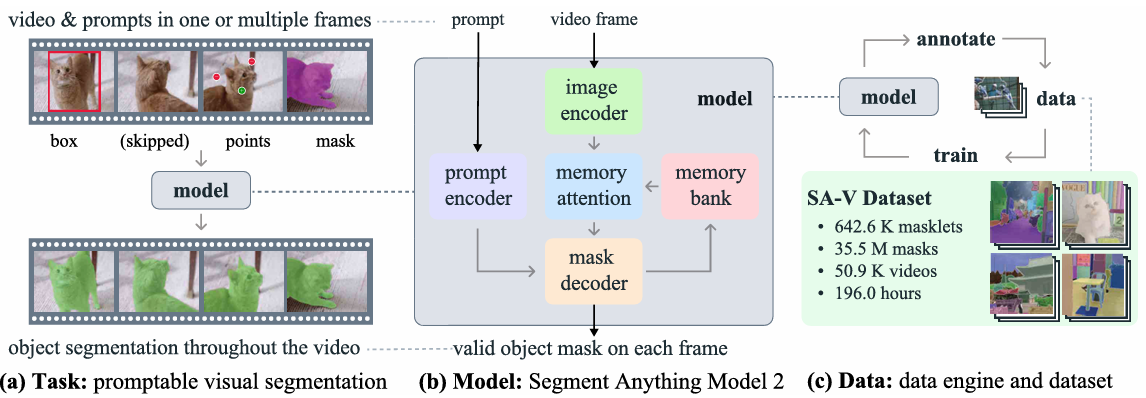
paper: arxiv.org/pdf/2408.00714
github: GitHub - facebookresearch/sam2: The repository provides code for running inference with the Meta Segment Anything Model 2 (SAM 2), links for downloading the trained model checkpoints, and example notebooks that show how to use the model.
基本思想:
SAM 2(Segment Anything in Images and Videos)在保留SAM所有能力基础上,通过内存机制实现了视频分割的时序一致性,是通用分割模型的重要演进。两者都体现了"基础模型"的设计理念,通过大规模预训练实现强大的zero-shot能力。
核心改进:(1)将SAM扩展到视频领域,通过memory attention实现时序一致的分割;(2)引入memory bank处理视频中的长程依赖。关键创新:(1)跨帧注意力(memory attention),通过内存库传播分割信息;(2)时序提示传播,自动将首帧提示传播到后续帧。训练目标:保持SAM的图像分割能力,新增视频时序一致性约束
模型结构:
- 基础组件继承自SAM:Prompt Encoder、Image Encoder(ViT)、LightWeight Mask Decoder;
- 新增视频处理模块:(1)Memory Attention,存储历史帧的特征,通过注意力机制实现跨帧信息传播;(2)Memory Bank:动态更新机制,支持长视频处理(>100帧);
- 时序处理流程:首帧完整SAM处理流程;后续帧提取当前帧特征,从内存库检索相关特征,融合历史信息生成分割;
- 效率优化:关键帧策略减少计算量;内存压缩技术。
二、多模态主流大模型
1. CLIP
1.1. CLIP (2021)

图1. CLIP结构
paper: [2103.00020] Learning Transferable Visual Models From Natural Language Supervision
github 1: GitHub - mlfoundations/open_clip: An open source implementation of CLIP.
https://github.com/openai/CLIP
github 2: https://github.com/openai/CLIP
基本思想:通过大规模图-文对进行对比学习,学习在特征空间中对齐文本和图像,从而理解图像内容和文本描述之间的关联。
模型结构:
- 图像编码器:通常使用Vision Transformer (ViT) 或者其他卷积神经网络 (CNN) 如ResNet作为backbone。
- 文本编码器:通常采用BERT或类似基于Transformer的模型。
- 特征提取后,图像和文本特征通过归一化处理,然后通过点积计算余弦相似度,使用对比损失(InfoNCE loss)进行训练。
1.2. CN-CLIP / Chinese-CLIP(2023)
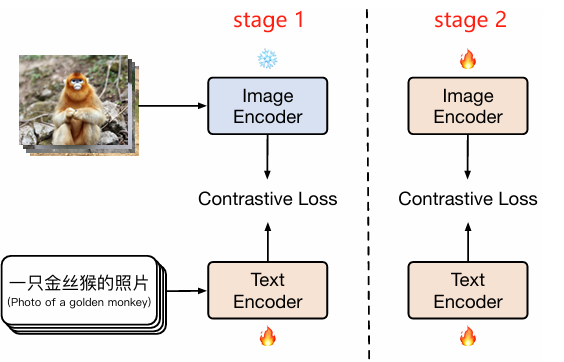
paper:[2211.01335] Chinese CLIP: Contrastive Vision-Language Pretraining in Chinese
github:GitHub - OFA-Sys/Chinese-CLIP: Chinese version of CLIP which achieves Chinese cross-modal retrieval and representation generation.
基本思想:CN-CLIP基于CLIP原始架构改进,改进点:
-
文本编码器:CLIP——使用基于Transformer的文本编码器(GPT,BERT),输入限长为77个token;CN-CLIP——采用中文优化的预训练模型(RoBERTa-wwm-ext,RBT3),支持更长的文本输入(max_len = 512 token),并通过Embeddings层动态处理截断和填充;
-
训练数据和数据清洗:CN-CLIP使用中文多模态数据进行训练,包括Laion-5B-CN、WuKong、翻译的MSCOCO、Visual Genome和私有数据集;CN-CLIP对训练数据进行了严格的清洗,包括clip score过滤、标题黑名单过滤以及caption长度过滤;
-
模型结构和训练策略:CN-CLIP采用两阶段训练策略,第一阶段锁住图像编码器,仅训练微调文本编码器;第二阶段解冻全部模型,继续训练 / 联合微调。
-
跨语言泛化能力和应用场景优化:CN-CLIP具有跨语言泛化能力,虽然主要针对中文数据训练,但仍保留了一定的英文能力;且做了应用场景优化,更适合中文多模态任务。
模型结构:
- 图像编码器:VIT(Base / Large / Huge)或者RN50;
- 文本编码器:RoBERTa(Base / Large)或者RBT3。
1.3. SigLIP (2023)
paper: [2303.15343] Sigmoid Loss for Language Image Pre-Training
github: https://github.com/google-research/big_vision
基本思想:SigLIP(Sigmoid Loss for Language-Image Pre-training)是Google提出的一种改进CLIP的多模态模型,其核心创新在于损失函数设计和训练策略优化。和CLIP的区别:
| 特性 | CLIP | SigLIP |
|---|---|---|
| 监督 | 无监督 / 自监督(依赖自然配对数据) | 二分类任务(正/负样本对,1/0 label) |
| 任务目标 | 批次内对比学习 | 单样本二分类 |
| 损失函数 | Softmax + InfoNCE | Sigmoid + BCE |
| 损失函数公式 |
其中si,j为t2i或i2t余弦相似度,τ为温度参数 |
其中σ为Sigmoid函数,yi∈{0,1} 为标签 |
| 计算效率 | 依赖大批次,内存开销高 | 支持小批次,并行计算更高效 |
| 特点 | 零样本泛化能力;对批次大小敏感,处理噪声数据时鲁棒性较低 | 鲁棒性与可扩展性;零样本能力略弱于CLIP |
| 适用场景 | 零样本分类、跨模态检索、VQA、创意生成 | 超大规模数据训练、长尾分布数据任务、实时图像检索 |
模型结构:
- 图像编码器:通常采用Vision Transformer(ViT)或ResNet,提取图像特征;
- 文本编码器:基于Transformer(如BERT),输出与图像特征同维度的文本嵌入;
- 特征对齐:将图像和文本映射到同一语义空间,通过余弦相似度计算匹配得分。
1.4. EVA-CLIP (2023)
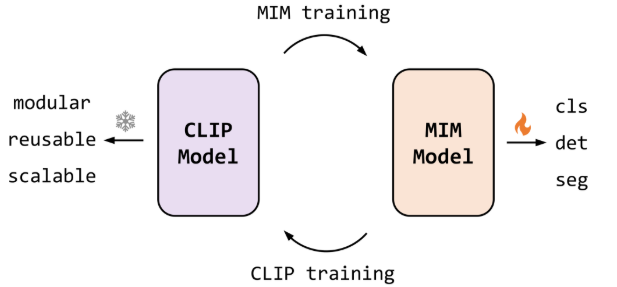
paper: [2303.15389] EVA-CLIP: Improved Training Techniques for CLIP at Scale
github: GitHub - baaivision/EVA: EVA Series: Visual Representation Fantasies from BAAI
基于CLIP的改进:
- EVA(Enhanced Visual Architecture):基于ViT改进的纯视觉基础预训练模型,通过掩码图像建模(Masked Image Modeling, MIM)学习图像特征表示,核心目标是提升视觉编码器的表征能力。EVA-02通过重建CLIP特征来融合语义与结构信息,也可以理解为CLIP是教师模型、EVA(VIT + MIM)是学生模型,损失函数为负余弦相似度-cos(f_eva_image, f_clip_image) or -cos(f_teacher, f_student) =
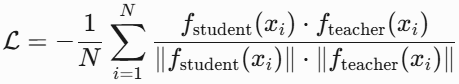 。
。 - EVA-CLIP:CLIP框架的多模态模型,将EVA作为其视觉编码器的初始化或组成部分,结合对比学习对齐图像-文本特征。例如,EVA-CLIP-18B使用EVA-18B作为视觉编码器初始化
- 初始化:采用预训练的EVA模型来初始化EVA-CLIP的图像编码器,改善特征表示并加速CLIP模型的收敛。
- 优化器:使用LAMB(Layer-wise Adaptive Moments optimizer for Batch training)优化器进行EVA-CLIP模型的训练,自适应的元素级更新和层级学习率提高了训练效率并加速了收敛速度。
- 掩码策略:利用随机掩码策略FLIP技术提高训练CLIP模型的时间效率。训练期间随机掩码50%的图像标记,显著降低了时间复杂度。
- 内存和训练加速:使用DeepSpeed优化库、ZeRO阶段1优化器、梯度检查点和Flash Attention技术来节省内存并加速训练过程。
2. BLIP
2.1. BLIP (2022)
paper: https://arxiv.org/abs/2201.12086
github: https://github.com/salesforce/BLIP
基本思想:BLIP将自然语言理解和自然语言生成任务进行融合,形成多模态通用模型。此外,BLIP还可用于弱监督图文数据清洗。
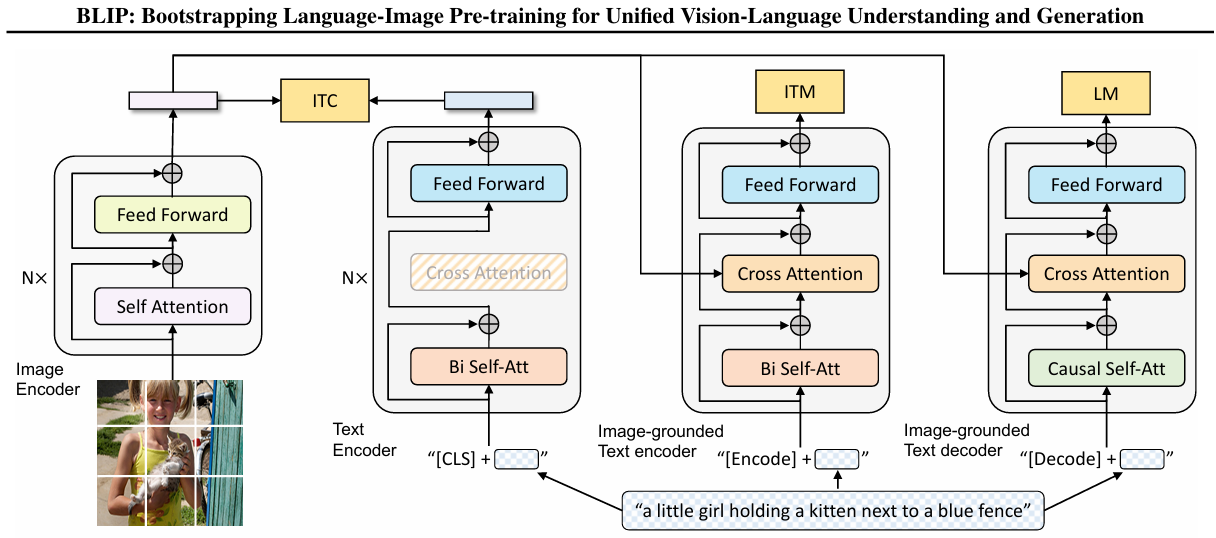
模型结构: BLIP模型采用了多模态混合编码器-解码器(Multimodal Mixture of Encoder-Decoder, MED)架构,该架构可以作为单模态编码器、图像引导的文本编码器或图像引导的文本解码器来操作。MED模型通过三种视觉-语言目标进行联合预训练:图像-文本对比学习(image-text contrastive learning)、图像-文本匹配(image-text matching)和图像条件语言建模(image-conditioned language modeling)。
- 图像编码器:使用视觉Transformer(如ViT)作为图像编码器,将输入图像分割成多个小块(patches),并将其编码为一系列嵌入向量,同时使用额外的 [CLS] 标记来表示整个图像的特征,和文本编码器抽取的文本特征共同完成 ITC 任务。
- 文本编码器:采用BERT或类似的基于Transformer的模型作为文本编码器,在文本输入的开始处附加[CLS]标记,以汇总句子的表示。
- 图像引导的文本编码器:在文本编码器的基础上,使用额外的 [Encoder],并在双向注意力和Feed Forward之间插入交叉注意力(cross-attention)层来注入视觉信息,完成 ITM 任务。
- 图像引导的文本解码器:把图像引导的文本编码器中的双向自注意力层替换为因果自注意力(causal self-att)层,并使用 [Decode] 标记来指示序列的开始和结束,完成 LM 任务。
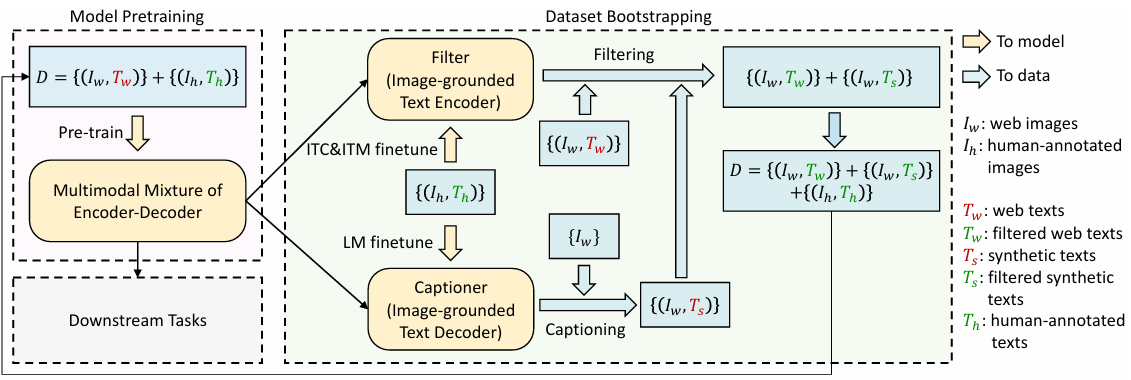
BLIP的数据清洗能力:训练初始BLIP模型并用人工标注图文对数据微调BLIP,保留ITC&ITM效果好的图文对,以及对部分图片生成更好的文本标注(caption)、扔入Filter重新过滤、获取干净的图文对。整理所获的干净图文对数据集,重新训练BLIP模型,这样有效地利用了网络上收集的噪声图像-文本对。
2.2. BLIP2 (2023)
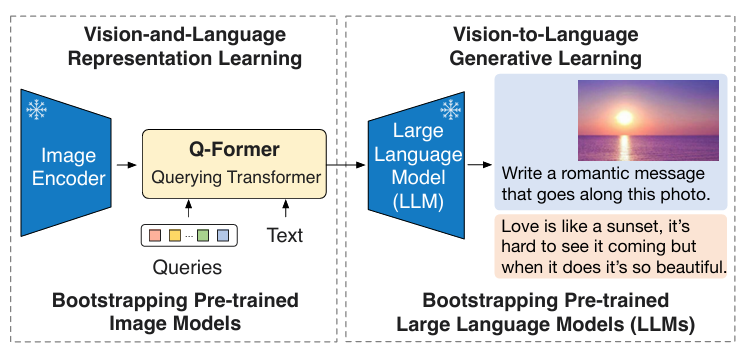
图2.2.1
paper: BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
github: https://github.com/salesforce/LAVIS/tree/main
基本思想:利用现成的冻结预训练模型(冻结的图像编码器和冻结的大模型),引入轻量级Q-Former,通过训练轻量级的Q-Former来实现视觉与语言模态的高效对齐。模型采用两阶段训练策略,第一阶段对齐视觉-语言表示,第二阶段适配视觉-语言生成任务。
模型结构:BLIP-2 由预训练的Image Encoder,预训练的Large Language Model(LLM),和一个可学习的 Q-Former 组成,如图2.2.1所示。
- Image Encoder:从输入图片中提取视觉特征,尝试了两种网络结构,CLIP 训练的 ViT-L/14和EVA-CLIP训练的 ViT-g/14(去掉了最后一层)。
- LLM:大语言模型进行文本生成,如图2.2.3所示,可接入Decoder-only LLM 或 Encoder-decoder LLM 两种结构。Q-Former输出通过全连接层投影到LLM文本嵌入空间,作为"软视觉提示"前置到输入文本前,引导LLM生成相关内容。
- Q-Former:如图2.2.2所示,是一个轻量级的BERT结构模型(约188M参数),弥补视觉和语言两种模态的modality gap,可以理解为固定图像编码器和固定LLM之间的信息枢纽,选取最有用的视觉特征给LLM来生成文本。
-
可学习查询嵌入(Learned Queries):32个768维的查询token作为图像transformer的输入,通过训练逐步捕获与文本相关的视觉信息。Learned Queries初始embedding为随机初始化,通过cross attention学习image信息。
- 共享自注意力层的双transformer:(1)图像transformer:查询嵌入与图像特征通过交叉注意力交互;(2)文本transformer:查询嵌入与文本嵌入通过共享的自注意力层交互
- Q-Former训练任务:ITC + ITM + ITG。
- 图文对比学习(ITC):最大化匹配图像-文本对的相似度,最小化不匹配对的相似度。计算时取32个查询输出与文本 [CLS] token的最高相似度作为图像-文本相似度;
- 图文匹配(ITM):二分类任务判断图像-文本对是否匹配,使用双向注意力掩码让查询和文本完全可见。采用hard negatives(ITC任务里,最难区分 / 相似度最高的负样本对)提高ITM能力;
- 图像引导文本生成(ITG):基于图像内容生成文本描述,使用因果注意力掩码确保自回归生成。
-
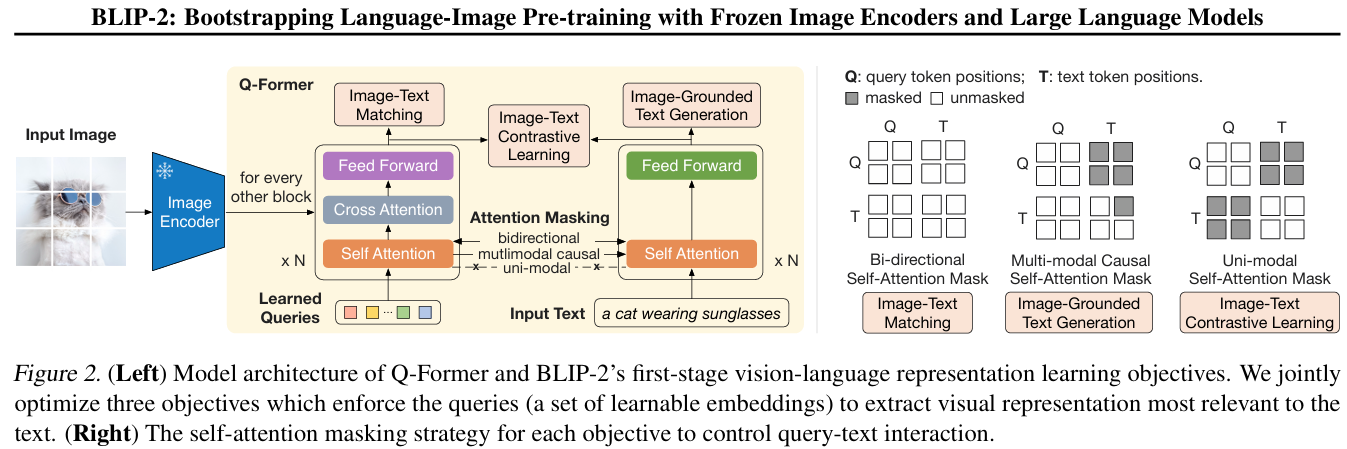
图2.2.2
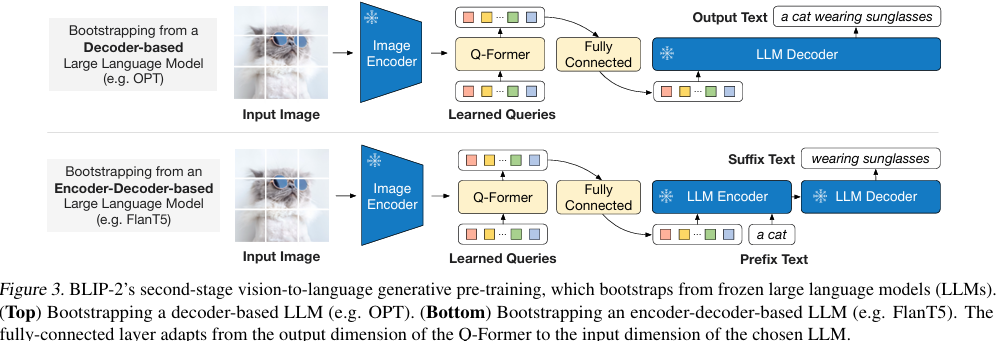
图2.2.3
VisualGLM:BLIP2的汉化版。基于BLIP2的浅层对齐,图像编码器:Pretrained VIT-G + Lora微调;LLM:ChatGLM + Lora微调。
2.3. Instruct-BLIP (2023)
paper: https://arxiv.org/abs/2305.06500
github: https://github.com/salesforce/LAVIS/tree/main/projects/instructblip
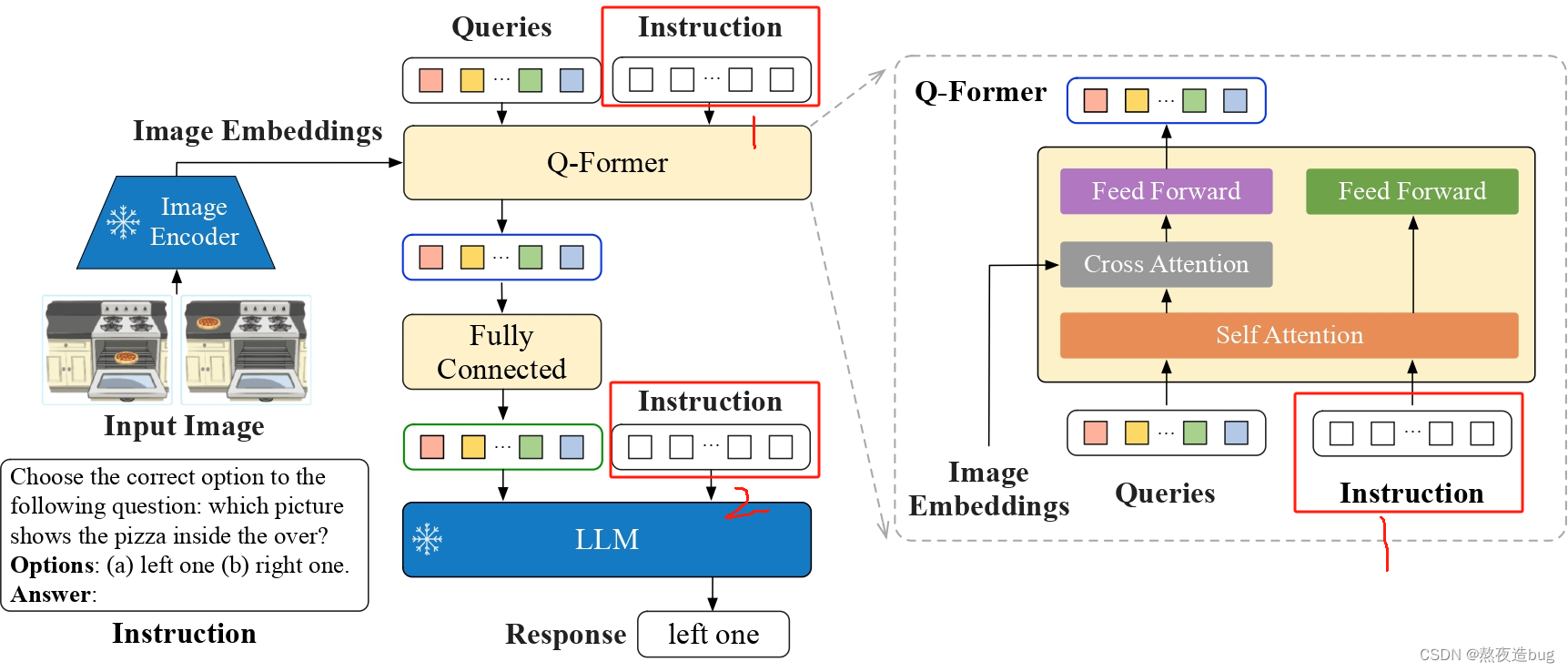
模型结构:InstructBLIP的模型结构基于BLIP2,进行两阶段训练,分别为vision-to-vector表示学习阶段和第二个vision-to-vector生成学习阶段。
模型包含以下关键组件。
- 图像编码器(Image Encoder):使用预训练的图像编码器(如ViT-g/14)来提取图像特征。
- 大语言模型(LLM):采用预训练的大型语言模型(如FlanT5或Vicuna),这些模型在指令调整过程中保持冻结状态。
- 查询转换器(Q-Former):一个轻量级的Transformer结构,用于从图像编码器中提取视觉特征。Q-Former包含一组可学习的查询嵌入,通过交叉注意力与图像编码器的输出进行交互。
- 指令感知机制:InstructBLIP提出了一个新颖的指令感知视觉特征提取机制。文本指令不仅提供给冻结的LLM,还提供给Q-Former,使其能够根据给定指令从冻结的图像编码器中提取视觉特征。
- 平衡采样策略:为了同步跨数据集的学习进度,InstructBLIP提出了一种平衡采样策略,根据数据集的大小的平方根或训练样本数量进行采样。
3. ALBEF (2021)
paper: 2107.07651
github: GitHub - salesforce/ALBEF: Code for ALBEF: a new vision-language pre-training method
基本思想:
- 现存问题:
- (1)图片的嵌入特征和单词的嵌入特征各自在各自的空间,难以交互;
- (2)目标检测器计算代价较高;
- (3)图文数据集来自网上,存在大量噪声。
- 解决方案:
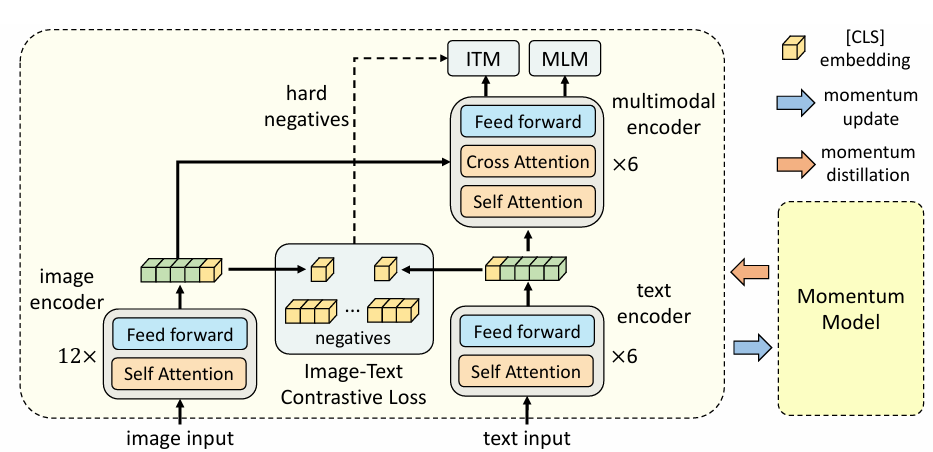
- (1)先对齐后融合(Align Before Fuse,ALBEF),通过图文对比学习(Image-Text Contrastive,ITC)进行表征对齐,再通过图文匹配任务(Image-Text Matching,ITM)、掩码语言建模(Masked Language Modeling,MLM)的Cross Attention进行表征融合;
- (2)ALBEF的视觉编码器和文本编码器均不再使用目标检测器;
- (3)动量蒸馏(Momentum Distillation, MoD)更新生成伪标签,减少噪声数据的影响,提升鲁棒性。下图为动量蒸馏实验:

模型结构:ALBEF由图像编码器、文本编码器、多模态编码器三部分组成。图像编码器体量(12层)大于文本(6层),一方面是因为data bias;另一方面是因为,相对text经过embedding后本身能反映较多的token和语义信息,image经过embedding后每个像素所包含的信息量和语义信息过少,所以需要较大体量的图像编码器学习表征。
- 图像编码器:12层ViT-B/16,输入图像编码为{vcls,v1,...,vN}。
- 文本编码器:BERT-base的前6层,输出文本嵌入{wcls,w1,...,wN}。
- 多模态编码器:BERT-base的后6层,通过交叉注意力融合图像和文本特征
损失函数:
- ITC Loss:其中
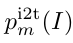 ,
,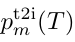 分别表示Softmax归一化后的 i2t 和 t2i相似性概率;
分别表示Softmax归一化后的 i2t 和 t2i相似性概率;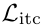 表示图文对比损失函数(ITC Loss);
表示图文对比损失函数(ITC Loss);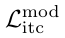 表示动量蒸馏后的ITC Loss。
表示动量蒸馏后的ITC Loss。
![]()
![]()
![]()
- ITM Loss:二分类任务,判断图文是否匹配,采用难负样本采样。
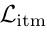 表示图文匹配损失(ITM Loss),y_itm表示最难区分的负样本对的label[正样本,负样本],为one-hot二维编码,p_itm(I, T)表示最难区分的负样本对(hard negatives)被模型预测为[正样本, 负样本]的概率,为二维概率输出(e.g. [正样本=0.9, 负样本=0.1]),ITM的优化目标是最小化交叉熵损失。
表示图文匹配损失(ITM Loss),y_itm表示最难区分的负样本对的label[正样本,负样本],为one-hot二维编码,p_itm(I, T)表示最难区分的负样本对(hard negatives)被模型预测为[正样本, 负样本]的概率,为二维概率输出(e.g. [正样本=0.9, 负样本=0.1]),ITM的优化目标是最小化交叉熵损失。
![]()
- MLM Loss:随机掩码15%文本token,预测被掩码词。
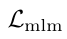 表示掩码语言建模损失(MLM Loss),T'表掩码文本(masked text), p_msk(I, T)表示模型预测掩码Token的概率(多分类任务),MLM的优化目标是最小化交叉熵损失;
表示掩码语言建模损失(MLM Loss),T'表掩码文本(masked text), p_msk(I, T)表示模型预测掩码Token的概率(多分类任务),MLM的优化目标是最小化交叉熵损失;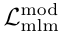 表示动量蒸馏后的MLM Loss。
表示动量蒸馏后的MLM Loss。
![]()
![]()
- Total Loss:ITC Loss(MoD后)、ITM Loss、MLM Loss(MoD后)的综合。
![]()
4. Flamingo (2022)
paper: [2204.14198] Flamingo: a Visual Language Model for Few-Shot Learning
github: https://github.com/mlfoundations/open_flamingo
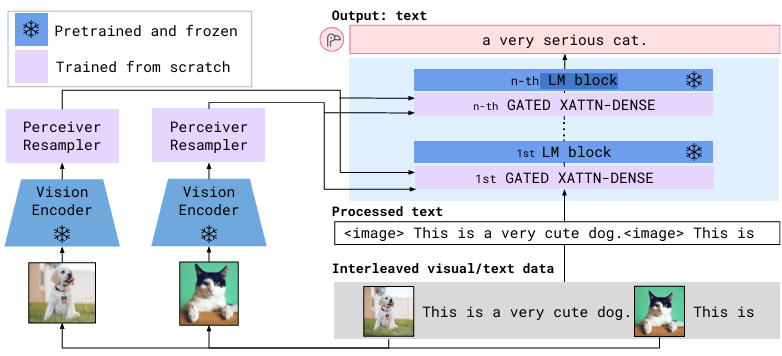
基本思想:利用现成的冻结预训练模型(冻结的视觉编码器和冻结的大语言模型),引入感知器重采样器(Perceiver Resampler)和门控交叉注意力层(Gated XATTN-DENSE)进行Few-Shot Learning。根BLIP2很像,BLIP2的Q-Former更轻量化,但不适合大型复杂任务,对视觉信息学习欠佳;Flamingo在冻结的视觉编码器和大语言模型基础上,引入Perceiver Resampler和Gated XATTN-DENSE,优于Q-Former的浅层对齐,学习了更多视觉特征,更适合少样本场景。Perceiver Resampler将任意数量的图像/视频特征压缩为固定数量的视觉token(默认64个),解决传统方法因输入尺寸可变导致的计算效率问题;Gated Cross-Attention通过可学习的门控参数逐步引入视觉信息,平衡模态融合与语言能力保留。
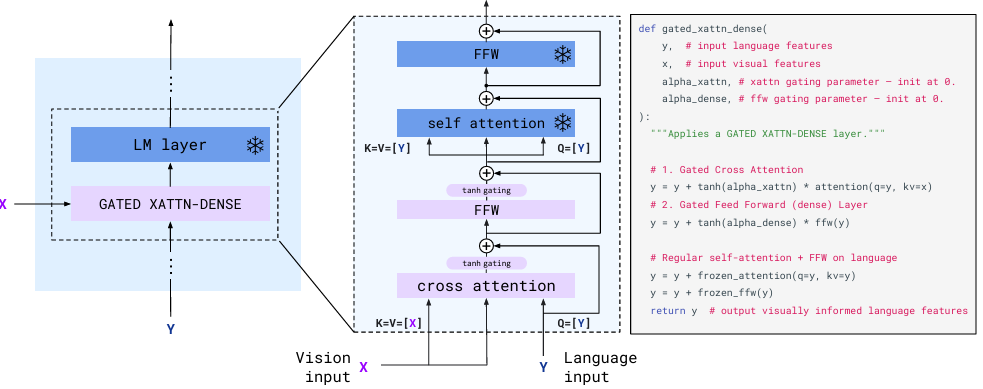
模型结构:
-
冻结的视觉编码器(Vision Encoder):预训练视觉模型NFNet(Normalizer-Free ResNet),将图像或视频转换为特征表示[T, S, D]。
-
冻结的大语言模型(Frozen Language Model):一个大型的预训练语言模型,例如 Chinchilla 模型。
-
感知器重采样器(Perceiver Resampler):输入为[T*S, D],经过多层Cross Attention和FFN将Vision Encoder的不定长特征映射为64个固定长度的可学习的视觉token,方便后续处理。
-
门控交叉注意力层(Gated XATTN-DENSE):
-
交叉注意力(Masked Cross Attention):以语言特征为Q,固定长度的视觉token为K、V,实现模态交互;
-
门控机制(Tanh Gating)和Feed Forward:通过tanh(α)控制新层输出的权重(α初始为0,逐步增大),避免破坏语言模型的原始能力;
-
分层插入:在语言模型的每一层之间插入该模块,实现深度融合。
-
5. CogVLM
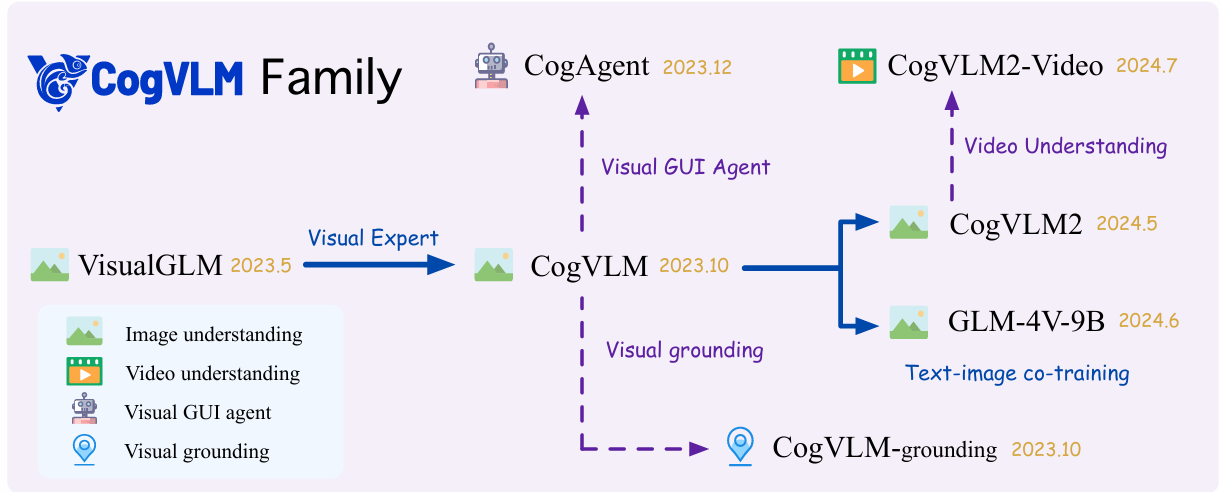
图5.1. CogVLM Family
 图5.2. Comparison of different model architectures. CA denotes cross attention
图5.2. Comparison of different model architectures. CA denotes cross attention
CogVLM系列遵循"视觉优先"理念,通过创新的视觉专家模块和深度融合策略,成功解决了多模态模型中视觉语言特征对齐的难题,在保持LLM原有NLP能力的同时,实现了卓越的视觉理解性能。CogVLM2的推出进一步扩展了模型的应用边界,特别是高分辨率图像理解和视频时序处理能力。(考点:VisualGLM和 CogVLM的区别)
5.1. CogVLM (2023)
paper: [2311.03079] CogVLM: Visual Expert for Pretrained Language Models
github: GitHub - THUDM/CogVLM: a state-of-the-art-level open visual language model | 多模态预训练模型
基本思想:CogVLM是针对传统多模态模型"浅层对齐"(shallow alignment)方法的局限性而提出的创新解决方案。传统方法如BLIP-2通过可训练的Q-Former或线性层将冻结的预训练视觉编码器和语言模型连接起来,将图像特征简单映射到语言模型的输入嵌入空间中。这种方法虽然收敛快,但存在两个主要问题:视觉语言特征融合不足,NLP能力受损。
CogVLM的核心创新是提出了"视觉优先"的设计理念和"视觉专家模块",实现了视觉语言特征的深度融合,同时不牺牲原始语言模型的NLP能力。其灵感来源于高效微调方法中LoRA与P-Tuning的比较——LoRA通过调整每层权重表现更好,类比到VLM中,图像特征需要在每层进行深度处理而非仅作为输入前缀。
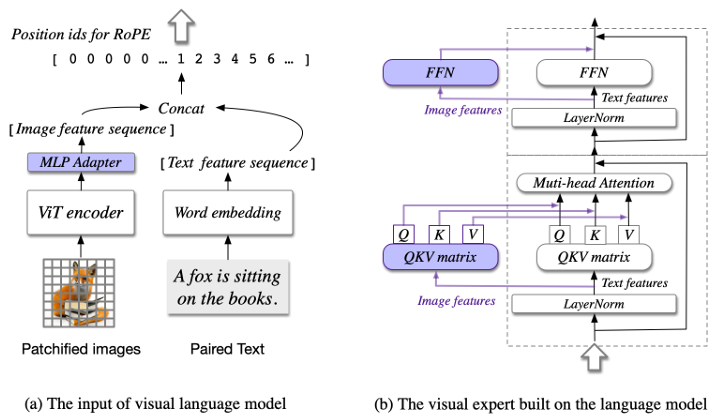
模型结构:CogVLM模型包含四个基本组件。
-
ViT编码器(MLP adapter):采用预训练的EVA2-CLIP-E作为视觉编码器,移除了最后一层(因其专用于对比学习的[CLS]特征聚合)。该编码器有5B参数,负责将图像转换为特征表示。
-
MLP适配器(MLP adapter):一个两层的MLP(使用SwiGLU激活函数),用于将ViT的输出映射到与词嵌入文本特征相同的空间。所有图像特征共享相同的位置ID。
-
预训练大语言模型(Pretrained large language model):兼容各种GPT风格的LLM,CogVLM-17B采用Vicuna-7B-v1.5进行进一步训练。对所有注意力操作(包括图像特征间)应用因果掩码。
-
视觉专家模块(Visual expert module):该模块是CogVLM实现"视觉优先"和深度多模态融合的核心。在每一Transformer层添加,由QKV矩阵和MLP组成,形状与预训练语言模型相同并从中初始化。视觉专家将参数数量增加一倍但保持FLOPs不变。其工作流程为:
-
隐藏状态X被拆分为图像隐藏状态X_I和文本隐藏状态X_T,维度为B×H×(L_I+L_T)×D(B:批大小,L_I:图像序列长,L_T:文本序列长,H:注意力头数,D:隐藏层大小);
-
注意力计算公式如下。其中W_I^Q/K/V是视觉专家的QKV矩阵,W_T^Q/K/V是原始语言模型的矩阵。
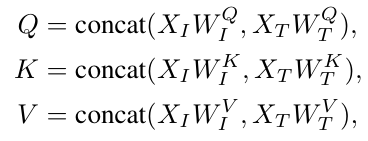
-
特征融合:通过上述方式,语言模型中的每个注意力头捕捉语义信息的不同方面,而视觉专家将图像特征转换以与不同头部对齐,实现深度融合。
-
位置编码(ROPE):所有visual tokens共享一个位置ID(因ViT已编码位置信息),缓解LLM中token间远程注意力衰减问题。
-
-
位置编码(Position embedding):使用ROPE赋予模型外推能力。同时,视觉token共享位置ID,使得避免远程衰减,保留ViT位置信息;文本token正常递增。
训练策略:CogVLM采用多阶段训练策略。
- 预训练阶段1:在15亿清洗后的图像-文本对(来自LAION-2B和COYO-700M)上,使用图像描述损失(文本部分的下一个token预测),batch size 8192,训练120,000步;
- 预训练阶段2:图像描述生成和指代表达式理解(REF)混合训练,batch size=1024,iterations=60,000步,后30,000 iterations将分辨率从224×224提升到490×490;
- 对齐阶段:
- CogVLM-Chat:整合LLaVA-Instruct(人工校正)、LRV-Instruction等VQA数据集,统一指令微调,batch size=640,lr=1e-5;
- CogVLM-Grounding:四种定位数据训练,赋予交互式视觉语义定位能力。
5.2. CogVLM2 (2024)
paper: [2408.16500] CogVLM2: Visual Language Models for Image and Video Understanding
github: GitHub - THUDM/CogVLM2: GPT4V-level open-source multi-modal model based on Llama3-8B
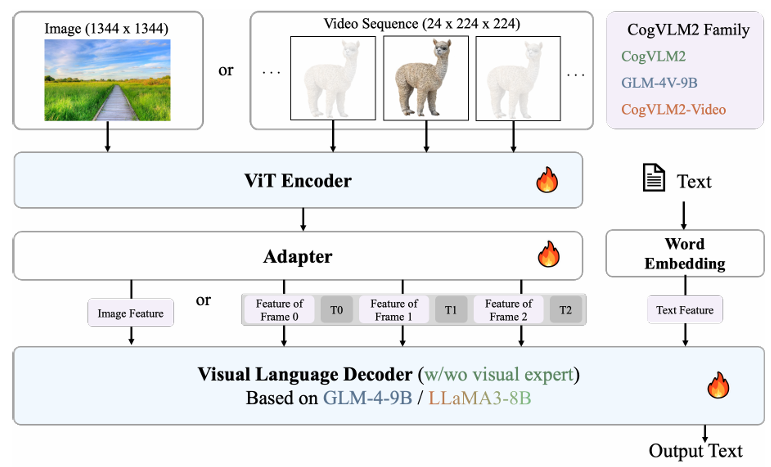
基本思想:CogVLM2在CogVLM基础上进行了多方面优化,形成了包括CogVLM2、CogVLM2-Video和GLM-4V的模型家族。CogVLM2在CogVLM基础上进行了多方面优化,主要改进 / 创新包括:
- 视觉专家模块增强(Enhanced vision-language fusion):采用多层视觉专家结构,实现更精细的跨模态融合;视觉专家参数增至7B(总视觉编码器达50B参数)。
- 架构优化,输入支持更高分辨率(Higher input resolution with efficient architecture):采用LLaMA 3-8B作为LLM骨干(CogVLM2-19B);引入2×2下采样模块,支持高达1344×1344分辨率的输入;适配器改为2×2卷积层+SwiGLU模块,提升计算效率。
- 更多模态扩展和场景应用(Broader modalities and applications):视频理解扩展,CogVLM2-Video支持带时间戳的多帧输入,理解时间顺序信息。
模型结构:
- 视觉编码器:使用更先进的EVA-CLIP模型;
- 适配器:采用2×2卷积层+SwiGLU模块,几乎无损地转换特征,保留关键图像信息的同时提高效率;
- 语言模型:Meta-Llama-3-8B-Instruct;
- 视觉专家模块:保留并优化了CogVLM的深度融合策略。
- 训练数据与策略:Pre-Training & Post-Training
- Pre-Training:Iterative Refinement & Synthetic Data Generation;
- Post-Training:Image Supervised Fine-tuning & Video Supervised Fine-tuning。
5.3. CogVLM v.s. CogVLM2
| 对比维度 | CogVLM | CogVLM2 |
|---|---|---|
| 架构理念 | 两套独立子网络处理多模态 | 共享底层特征提取的一体化建模 |
| 视觉专家 | 单层视觉专家模块 | 多层视觉专家结构 |
| 适配器 | 两层MLP(SwiGLU) | 2×2卷积+SwiGLU |
| LLM骨干 | Vicuna-7B/GLM-12B | LLaMA 3-8B |
| 分辨率 | 最高490×490 | 1344×1344 |
| 训练数据 | 15亿图文对 | 更海量多样化数据 |
| 视频支持 | 不支持 | CogVLM2-Video支持 |
7. LIaVA系列
paper: 2304.08485
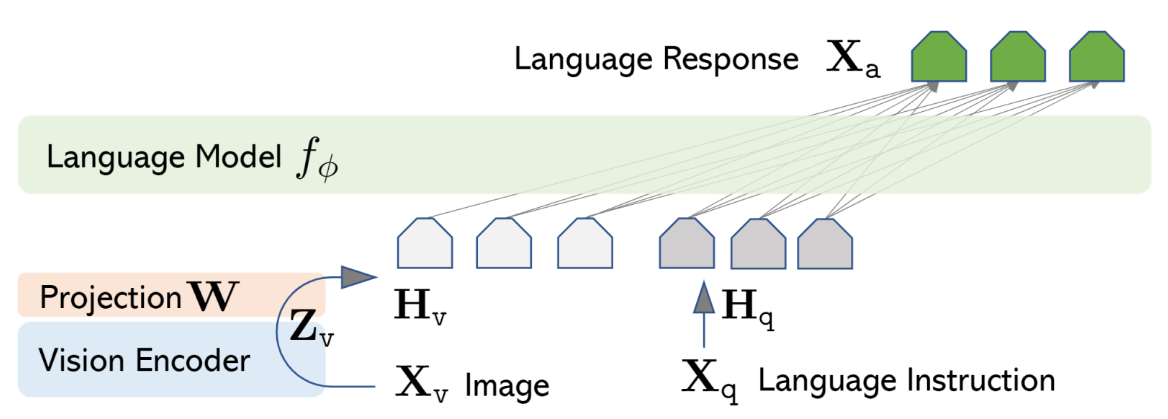
github: GitHub - haotian-liu/LLaVA: [NeurIPS'23 Oral] Visual Instruction Tuning (LLaVA) built towards GPT-4V level capabilities and beyond.基本思想:LLaVA(Large Language and Vision Assistant)是一个端到端训练的多模态模型,旨在通过结合视觉编码器和大语言模型的能力,实现图像与文本的联合理解和生成。工作流程:图像 → CLIP编码 → 投影层 → 视觉标记 → 与文本指令拼接 → Vicuna生成输出。LLaVA系列技术演进:LLaVA(2023)——> LLaVA 1.5(2023.10)——>LLaVA-NeXT(2023.10)——> LLaVA-OneVision(2023.10)。更多细节见:LLaVA技术演进
模型结构:
- 视觉编码器:采用CLIP的ViT-L/14或ViT-L/336px变体,提取图像特征。
- 投影层:可训练的线性矩阵(W),将视觉特征映射到语言模型的词嵌入空间(如Vicuna的嵌入维度)。轻量级设计(相比交叉注意力或Q-former),计算高效。
- 大语言模型:基于Vicuna(LLaMA的指令微调版本),负责文本生成与推理。输入为拼接后的视觉标记(Hv = W·Zv)和文本指令,通过自回归生成响应。
- 训练流程:采用两阶段指令微调方案。通过一个简单的投影矩阵连接预训练CLIP ViT-L/14视觉编码器与Vicuna大语言模型。
- Pre-training for Feature Alignment. 仅更新投影矩阵,基于CC3M数据集子集进行训练。
- Fine-tuning End-to-End. 针对针对视觉对话和科学问答两种应用场景,联合微调投影矩阵和大语言模型。
特点:
- 数据驱动:依赖GPT-4生成的动态指令数据,提升模型对复杂任务的适应性。
- 轻量级设计:仅需简单投影层连接视觉与语言模块,和QFormer相对,训练效率更高、更轻量。
8. Llama系列
8.0. LLama 3(前言)
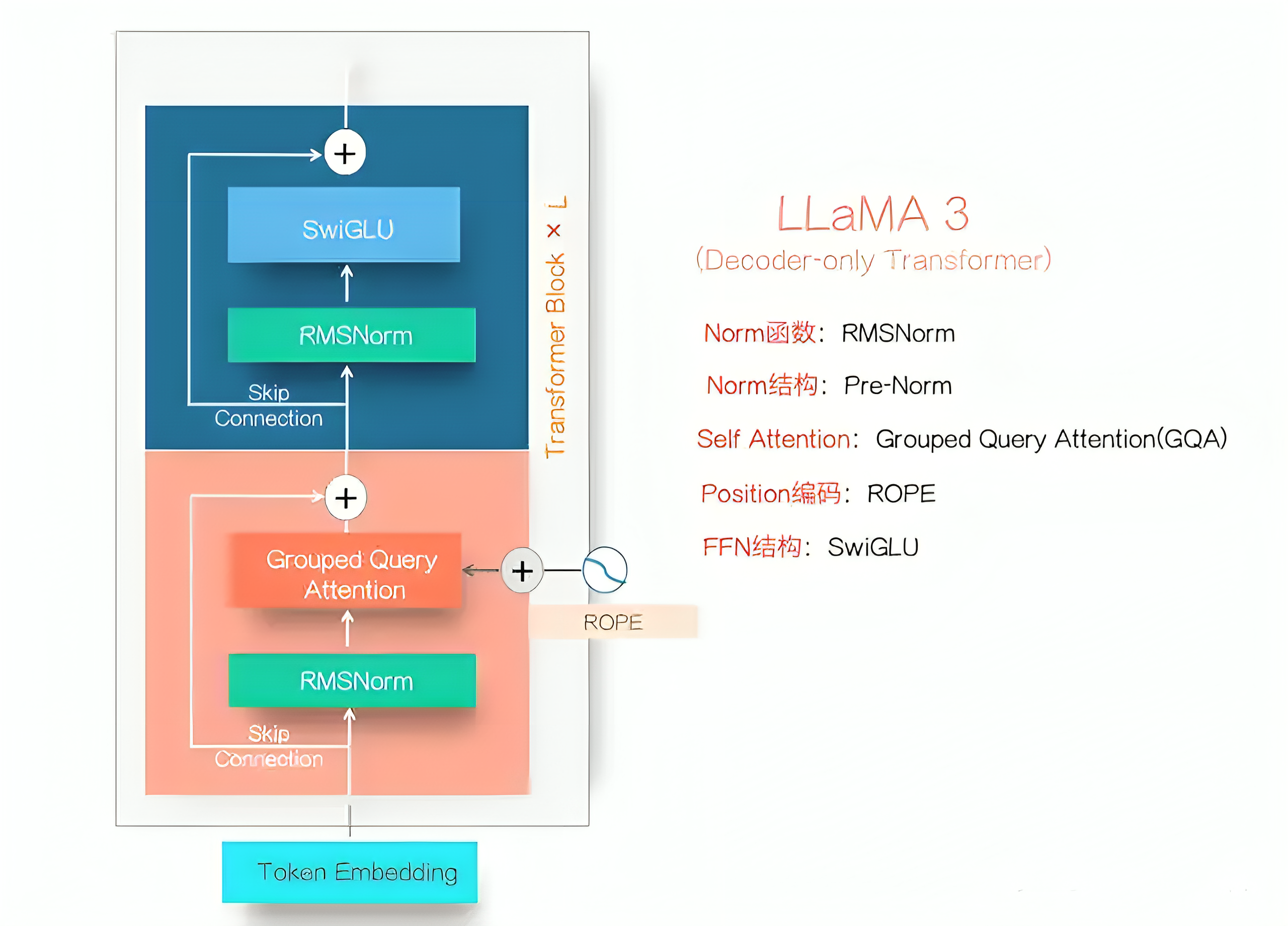
图8.1. LlaMa 3:Decoder-Only,应用经典Transformer的Decoder部分并加以改造,也被称为Dense LLM。细节改进:Norm函数(LN->RMSNorm)、Norm结构(Post-Norm->Pre-Norm)、Self Attention(MHA->GQA)、PE(正余弦PE->ROPE)、FFN(Gelu->SwiGlU)。更多细节参考:LLama模型架构解析。
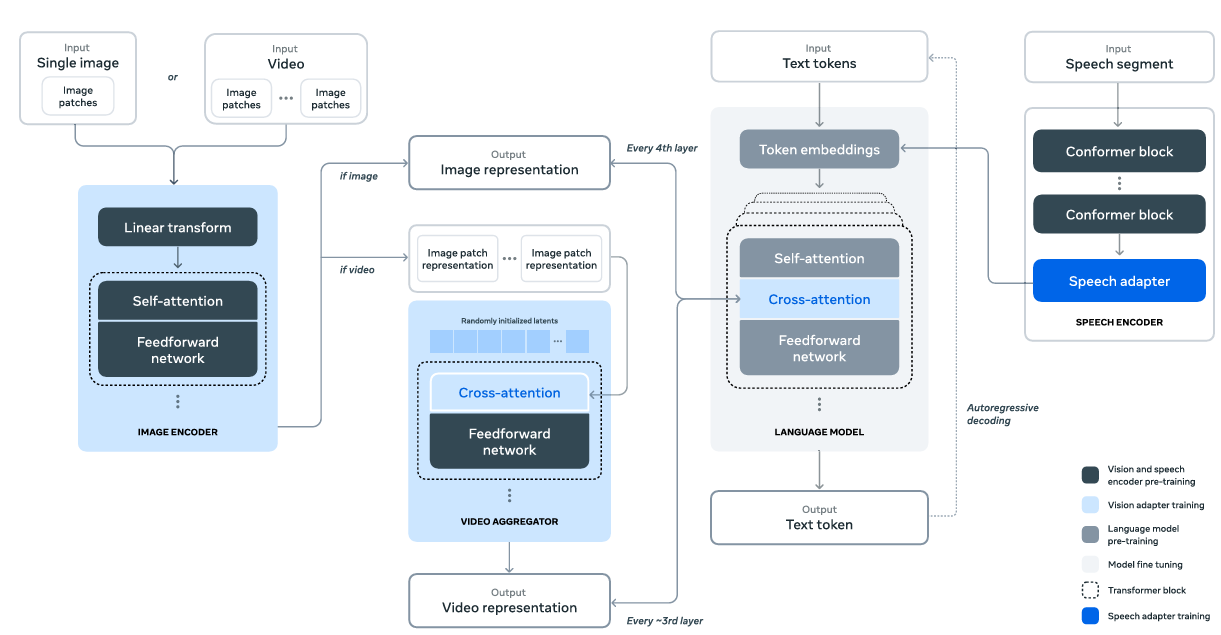
图8.2. LlaMa 3多模态实验性扩展。分五个阶段训练:(1) 语言模型预训练;(2) 视觉适配器训练;(3) 语音适配器训练;(4) 多模态编码器预训练;(5) 模型微调。
paper: 2407.21783
github: GitHub - meta-llama/llama3: The official Meta Llama 3 GitHub site
paper解读:Llama 3解读
LLama演进:Llama 系列模型最初是由 Meta(原 Facebook)开发的纯文本大语言模型(如 Llama 1,Llama 2 和 Llama 3),它们本身并不支持多模态(即无法直接处理图像、音频等非文本输入)。Llama 3针对多模态进行了实验性扩展,非正式发布的多模态版本。Llama 3.2 是首个发布的支持多模态的版本,但采用适配器方式整合视觉能力。Llama 4 是首个原生多模态 & MOE架构 版本,直接从底层架构支持文本+图像+视频联合训练,性能更强。
关键技术:预训练(Pre-Training)和后训练(Post-Training)。
- 预训练(Pre-Training)
- Pre-Train Data
- 网络数据治理(Web Data Curation):个人身份信息和安全过滤(PII and safety filtering)、文本内容抽取和清洗(Text extraction andcleaning)、数据去重(De-duplication)、启发式过滤(Heuristic filtering):使用n-gram、“dirty word” counting、token-distribution KL散度等技术去重低质文件、离群数据和过多重复的文档、基于模型的质量过滤(Model-based quality filtering):使用大模型筛选高质tokens、代码和推理数据获取(Code and reasoning data)、多语言数据转换(Multilingual data);
- 混合数据比例确定(Determining the Data Mix):知识分类器(Knowledge classification)、数据混合的Scaling laws(Scaling laws for data mix.)、数据混合比例总结(Data mix summary);
- 退火数据(Annealing Data).
- 模型架构(Model Architecture).
- Infrastructure, Scaling and Efficiency.
- 训练方法(Training Recipe):三个阶段式. (1) 初始预训练;(2) 长上下文预训练;(3) 退火.
- Pre-Train Data
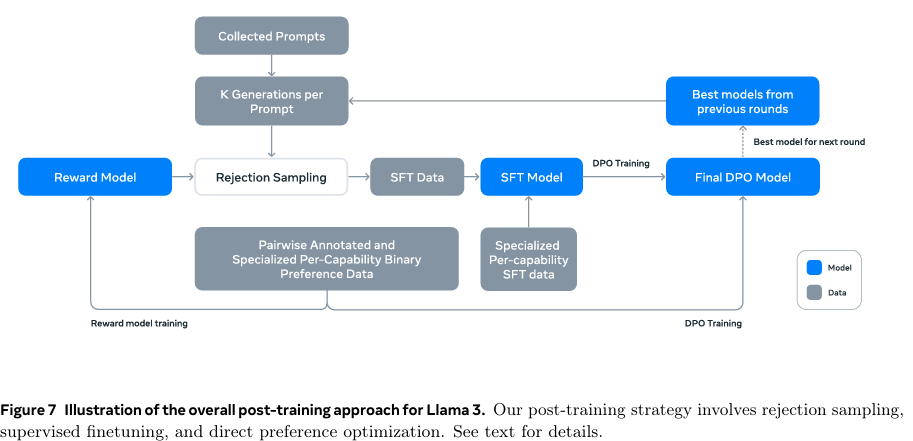
- 后训练(Post-Training)
- Post-training Data:Preference Data、SFT Data、Data Processing andQuality Control;
- ModelingChat Dialog Format:Reward Modeling(RM)、Supervised Finetuning(SFT)、Direct Preference Optimization(DPO)、Model Averaging、lterative Rounds.
8.1. Llama 3.2 (2024.9)
official blog: Llama 3.2: Revolutionizing edge AI and vision with open, customizable models
github: llama-models/models/llama3_2/MODEL_CARD_VISION.md at main · meta-llama/llama-models · GitHub
基本思想:Llama 3.2 是 Meta 推出的开源大模型系列,旨在平衡性能与硬件适配性,尤其针对边缘设备和移动端优化。其核心思想包括:
- 多模态扩展:首次引入视觉语言模型(11B/90B),通过适配器(adapters,cross-attention)架构将预训练的图像编码器(如 CLIP)与语言模型集成,轻量级实现视觉与语言的特征对齐。
- 轻量化设计:通过剪枝和知识蒸馏技术,从更大的 Llama 3.1 模型(如 8B/70B)中提取知识,生成更小的 1B 和 3B 模型,同时保持较强的性能。
- 高效推理:支持 128K tokens 的超长上下文,并针对高通/联发科芯片优化,实现本地化部署和边缘计算。
模型结构:
- 视觉模型(11B/90B):
- 视觉编码器:独立的CLIP变体或MetaCLIP,与语言模型通过适配器(cross-attention层)集成;
- 语言模型:基于Llama 3.1的Transformer-Decoder Only架构(前言部分),支持128K tokens上下文;
- 文本模型(1B/3B):纯语言模型,优化了本地设备的多语言生成和工具调用能力。
- 训练流程:
- 预训练:在大规模图像-文本对上训练视觉适配器;
- 后训练/微调:采用监督微调(SFT)和直接偏好优化(DPO)提升指令跟随能力。
8.2. Llama 4 (2025.4)
official blog: The Llama 4 herd: The beginning of a new era of natively multimodal AI innovation
github: llama-models/models/llama4/MODEL_CARD.md at main · meta-llama/llama-models · GitHub
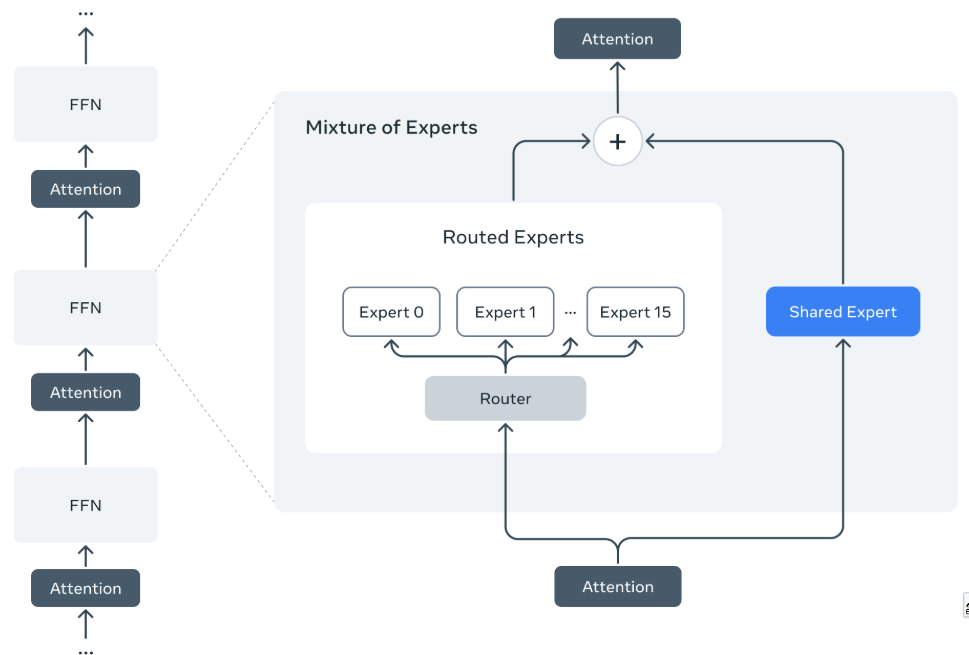
基本思想:Llama 4 是 Meta 的下一代多模态模型,采用混合专家(MoE)架构,目标是与 GPT-4 等闭源模型竞争。其核心创新:
- 混合专家(MoE)架构:通过动态激活部分专家模块(如 Scout 仅激活 17B 参数),降低计算成本,同时支持超大规模参数(如 Behemoth 达 2T 参数)。
- 原生多模态:文本、图像、视频等数据直接作为 token 输入,无需外挂编码器,实现早期融合(Early Fusion)。
- 超长上下文:iROPE位置编码支持超长上下文外推,如Scout专注长上下文处理,适用于代码长文档分析。
模型结构:
- MoE 分层设计:
- Scout(109B 总参数,17B 激活):16 专家,专注长上下文处理;
- Maverick(400B 总参数,17B 激活):128 专家,主打多模态任务;
- Behemoth(2T 总参数,288B 激活):训练专用,用于知识蒸馏。
- 多模态融合:
- 早期融合:视觉 token 与文本 token 统一输入模型,联合训练;
- 改进的视觉编码器:基于 MetaCLIP,与冻结的 Llama 模型协同训练。
- 训练优化:
- iRoPE 位置编码:交错注意力层(无位置嵌入)支持长度外推;
- 三阶段后训练/微调:轻量级 SFT → 在线 RL → 轻量级 DPO,平衡性能与安全性。
关键技术:
- MoE 动态路由:按需激活专家,提升参数效率。
- iRoPE 架构:通过温度缩放注意力增强长上下文泛化能力。
- FP8 训练:高精度计算与低资源消耗的平衡。
8.3. LLaVA,Llama 3.2和Llama 4对比
| 维度 | LLaVA | Llama 3.2 | Llama 4 |
|---|---|---|---|
| 训练技术 | / | 剪枝、蒸馏、适配器 | MoE、iRoPE、早期融合 |
| 核心目标 | 轻量级多模态交互 | 边缘设备多模态推理 | 超长上下文与多模态竞争 |
| 架构 | CLIP+线性投影+Vicuna | 密集模型(Dense)或适配器多模态 | 混合专家(MoE)+ 原生多模态 |
| 训练数据 | GPT-4生成的指令数据 | 大规模图像-文本对 | 合成数据+知识蒸馏 |
| 模态支持 | 图像+文本 | 图像+文本(仅英文,需适配器) | 文本/图像/视频/音频(原生融合) |
| 上下文长度 | 较短(依赖语言模型) | 128K tokens | 最高10M tokens(Scout) |
| 部署场景 | 通用多模态任务 | 边缘设备、移动端 | 云端/高性能计算(如单卡 H100) |
9. Qwen-VL系列
Reference:
(1)Qwen-VL 1.0、Qwen2-VL、Qwen2.5-VL解读(1)
(2)Qwen-VL 1.0、Qwen2-VL、Qwen2.5-VL解读(2
参考Reference,写的有点晕了,该章节不再详述,后续有时间再补充(又挖一坑)。
| Qwen-VL 1.0 | Qwen2-VL | Qwen2.5-VL | |
| Visual Encoder | Openclip’s ViT-bigG | DFN* ViT + 2D RoPE | Dynamic-resolution ViT + Window attention + 2D RoPE |
| LLM | Qwen | Qwen2 | Qwen2.5 |
9.1. Qwen-VL 1.0(2023.10)
paper: 2308.12966
github: GitHub - QwenLM/Qwen-VL: The official repo of Qwen-VL (通义千问-VL) chat & pretrained large vision language model proposed by Alibaba Cloud.
9.2. Qwen2-VL(2024.8)
paper: arxiv.org/pdf/2409.12191
github: GitHub - QwenLM/Qwen2.5-VL: Qwen2.5-VL is the multimodal large language model series developed by Qwen team, Alibaba Cloud.
9.3. Qwen2.5-VL(2025)
paper: arxiv.org/pdf/2502.13923
github: GitHub - QwenLM/Qwen2.5-VL: Qwen2.5-VL is the multimodal large language model series developed by Qwen team, Alibaba Cloud.
10. InternVL系列
Reference:
(1)InternVL、InternVL 1.5、InternVL 2、InternVL 2.5 解读(1)
(2)InternVL、InternVL 1.5、InternVL 2、InternVL 2.5 解读(2)
参考Reference,写的有点晕了,该章节不再详述,后续有时间再补充(又挖一坑)。
10.1. InternVL 1.0(2023)
10.2. InternVL 1.5(2024)
10.3. InternVL 2.0(2024.9)
10.4. InternVL 2.5(2025)
11. Deepseek系列
DeepSeek系列模型从2024.3发布的DeepSeek VL版本开始正式支持多模态能力,后续通过多个版本持续升级。以下是Deepseek关键版本的多模态模型。
11.1. DeepSeek VL系列
(1)DeepSeek VL (2024.3)
paper: 2403.05525
github: GitHub - deepseek-ai/DeepSeek-VL: DeepSeek-VL: Towards Real-World Vision-Language Understanding
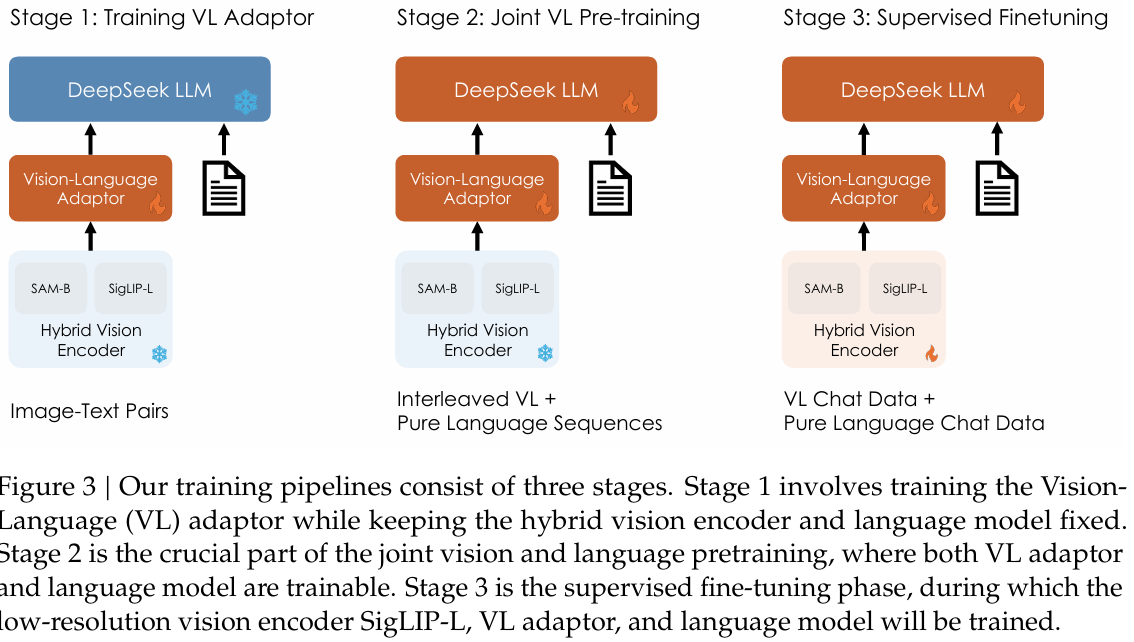
基本思想:DeepSeek-VL 旨在缩小开源多模态模型与闭源模型在现实场景中的性能差距,通过综合性预训练和高分辨率图像处理提升图文理解能力。数据构建包括Vision-Language pretraining Data和Supervised Fine-tuning Data。
模型结构(类似LLaVA的模型架构,视觉编码器+MLP+大语言模型):
- 混合视觉编码器:结合 SigLIP-L(低分辨率语义特征)和 SAM-B(高分辨率细节),支持 1024×1024 图像输入。
- 视觉语言适配器:使用两层 MLP 桥接视觉与文本特征空间。
- 语言模型:基于DeepSeek-LLM,用于生成文本响应。DeepSeek-LLM似 LLaMA 架构:Norm函数(LN->RMSNorm)、Norm结构(Post-Norm->Pre-Norm)、Self Attention(MHA->GQA)、PE(正余弦PE->ROPE)、FFN(Gelu->SwiGlU)。
训练流程:分三阶段,视觉语言适配器训练 → 联合预训练 → 监督微调:
- 视觉语言适配器训练(Training Vision-Language Adaptor):建立视觉特征与语言特征的初步对齐,使语言模型(LLM)能够初步理解图像内容。适配器作为“翻译桥梁”,将视觉特征(如SAM-B的高分辨率局部特征)映射到语言模型的嵌入空间,避免直接微调LLM导致的语言能力退化。
- 联合预训练(Joint Vision-Language pretraining):深度融合视觉与语言表征,提升跨模态理解能力,同时维持语言能力。直接混合训练会导致语言能力下降(“灾难性遗忘”),通过数据比例控制和分阶段引入多模态数据解决。
- 有监督微调(Supervised Fine-tuning,SFT):对齐人类指令偏好,提升任务特定性能(如视觉问答、文档理解)。
(2)DeepSeek VL2 (2024.12)
paper: *2412.10302
github: GitHub - deepseek-ai/DeepSeek-VL2: DeepSeek-VL2: Mixture-of-Experts Vision-Language Models for Advanced Multimodal Understanding
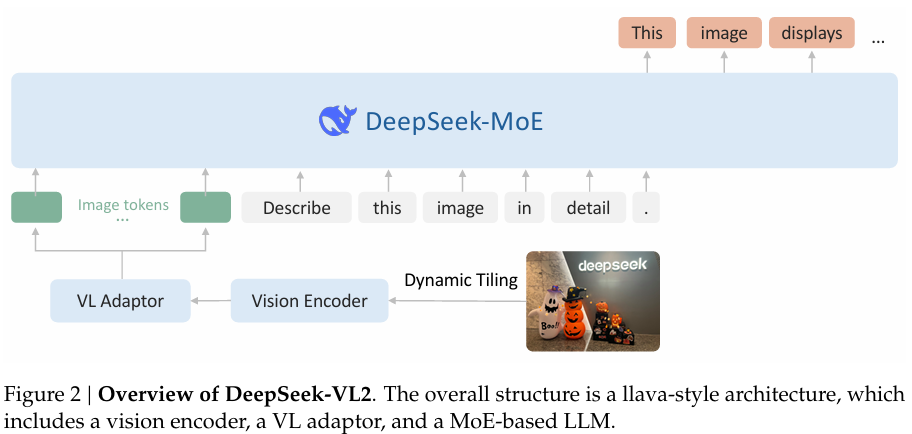
基本思想:在 VL 基础上引入动态切片策略、Pixel Shuffle的Token压缩技术和混合专家(MoE)架构 ,提升高分辨率图像处理效率和跨模态推理能力,同时降低计算成本。数据构建:
- Vision-Language Alignment Data:ShareGPT4V-->initial warmup stage;
- Vision-Language Pretraining Data:VL data : Text-only data=70% : 30%;including Interleaved image-text data, Image captioning data, Optical character recognition data, VQA data, Grounded conversation data;
- Supervised Fine-tuning Data:General visual question-answering, OCR and document understanding,Table and chart understanding, Reasoning, logic, and mathematics, Textbook andacademicquestions, Visual grounding...。
模型结构:
- 动态视觉编码器(Vision Encoder):SigLIP模型。将图像分割为多窗口(如 384×384 块),适应不同长宽比,保留细节;支持 224px~1344px 动态分辨率输入;
- 视觉语言适配器(VL Adaptor):两层MLP投影层;同时,优化 token 压缩(Pixel Shuffle技术,compresseach tile’s visual tokens from 27×27 to14×14=196 tokens)以减少计算量;
- MoE 语言模型(Mixture-of-Experts language model):采用 DeepSeek-MoE,结合多头潜在注意力(MLA)压缩 KV 缓存,提升推理速度;稀疏激活(仅激活部分专家),参数量达4.5B但计算效率更高。
Training Pipeline:Vision-Language Alignment、Vision-Language Pre-training、SupervisedFine-Tuning。
(3)DeepSeek-VL和DeepSeek-VL2对比
| 维度 | DeepSeek-VL | DeepSeek-VL2 |
|---|---|---|
| 核心目标 | 现实世界图文理解 | 高效高分辨率处理 + 跨模态推理 |
| 架构 | Dense 架构 | MoE 架构 + 动态切片 |
| 视觉处理 | 固定分辨率(1024×1024) | 动态分辨率(最高 1344px) |
| 语言模型 | DeepSeek-LLM | DeepSeek-MoE(稀疏激活) |
| 典型应用 | 文档分析、视觉问答 | 科研图表解析、OCR |
| 参数量 | 1.3B/7B | 1B/2.8B/4.5B(激活参数) |
11.2. Janus系列
Janus系列paper:(1)Janus(2024.10):paper;(2)JanusFlow(2025.3):paper ;(3)Janus-Pro(2025.6):paper
Janus系列github:代码
注:以下内容由AI生成(着实写不动了)。
(1)Janus (2024.10)
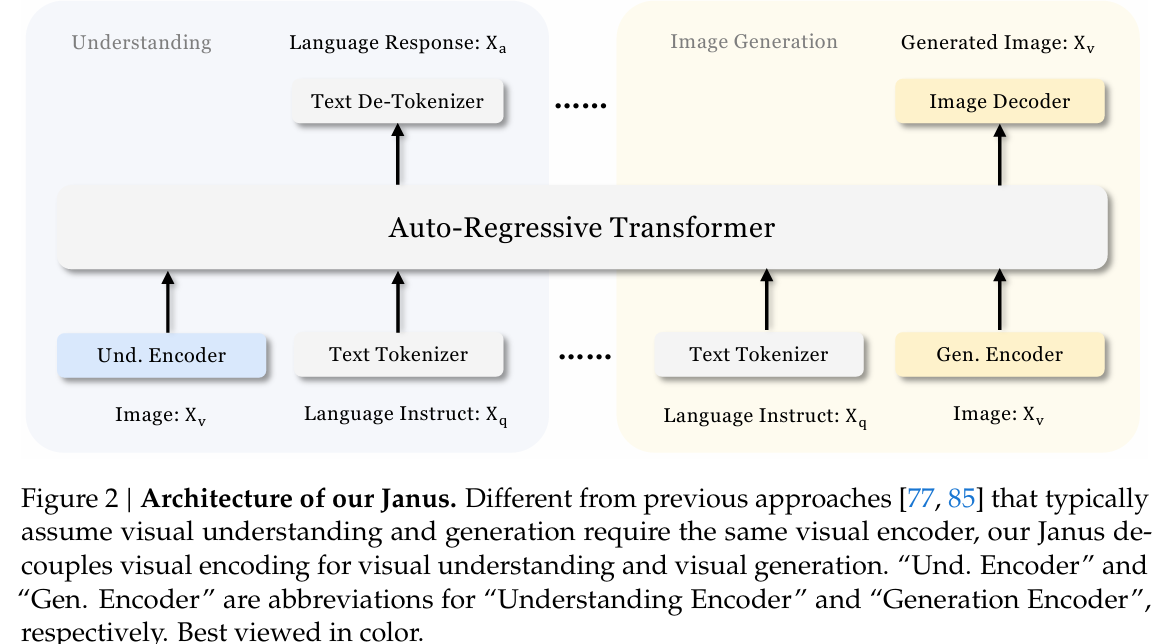
基本思想:Janus 的核心创新在于解耦视觉编码,将多模态理解(如视觉问答)和生成(如文生图)的视觉编码路径分离,双编码器可独立优化,支持替换为其他先进编码器(如点云/音频),避免传统单编码器在两种任务中的冲突,灵活。其设计基于以下原则:
- 任务需求差异:理解任务需要高级语义特征,而生成任务依赖细粒度空间细节。
- 统一 Transformer:保留单一自回归 Transformer 架构处理多模态序列,简化模型设计。
模型结构:双编码器设计+自回归生成,解耦视觉理解(SigLIP编码器)和生成(VQ Tokenizer),通过统一Transformer处理多模态序列。
- 理解编码器(Und. Encoder):使用 SigLIP 提取图像语义特征,映射到语言模型(LLM)输入空间;
- 生成编码器(Gen. Encoder):采用 VQ Tokenizer 将图像离散化为 ID 序列,通过生成适配器对接 LLM;
- 自回归Transformer生成器。
训练策略:三阶段训练策略(适配器预训练→联合预训练→监督微调)。
- 适配器训练:冻结视觉编码器和 LLM,仅训练理解/生成适配器。
- 联合预训练:解冻 LLM,混合多模态数据(ImageNet-1k + 开放域文本-图像对)。
- 监督微调:指令调优增强指令跟随能力。
(2)JanusFlow (2025.3)
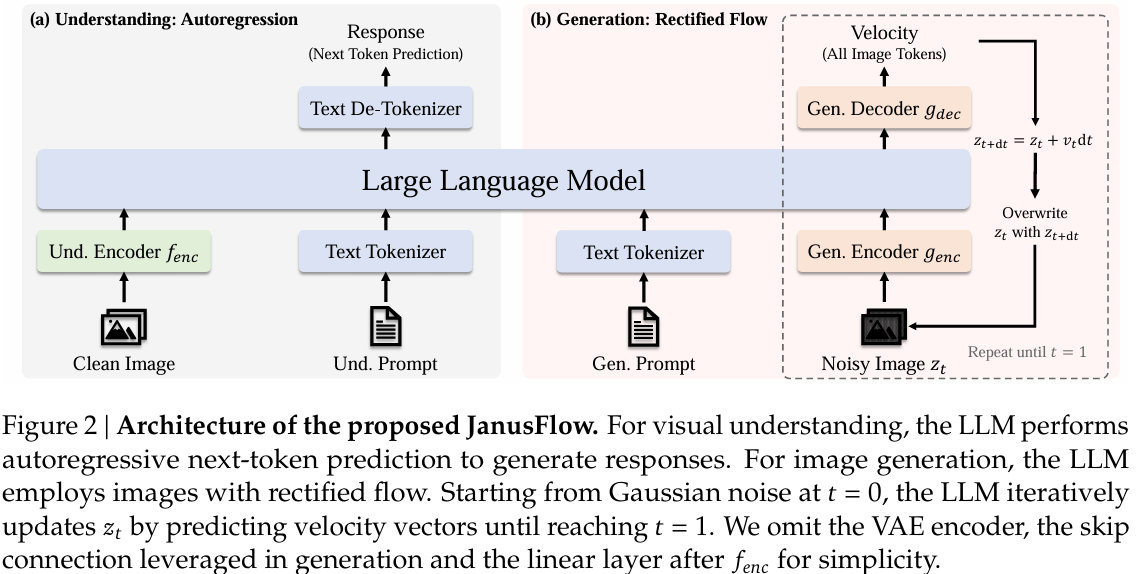
基本思想/原理:JanusFlow 为极简流式生成架构,核心是将自回归语言模型(LLM)与 Rectified Flow(生成流)直接结合,无需额外扩散模型架构,实现高效的多模态流式处理。其设计特点包括:
- 生成流集成:将自回归语言模型(LLM)与Rectified Flow结合,实现高效动态生成,简化生成建模流程。
- 动态数据适配:预训练阶段逐步增加生成数据比例,平衡理解与生成能力。
模型结构
- 视觉编码器:沿用 SigLIP-L(384×384 输入)。
- 生成模块:基于 SDXL-VAE 的 Rectified Flow,生成 384×384 图像。
训练策略:三阶段训练策略
- 第一阶段:随机初始化组件(生成编码器/解码器)适配预训练 LLM。
- 第二阶段:联合训练(冻结视觉编码器),混合多模态理解、生成和纯文本数据。
- 第三阶段:指令微调,解冻视觉编码器。
(3)Janus-Pro (2025.6)
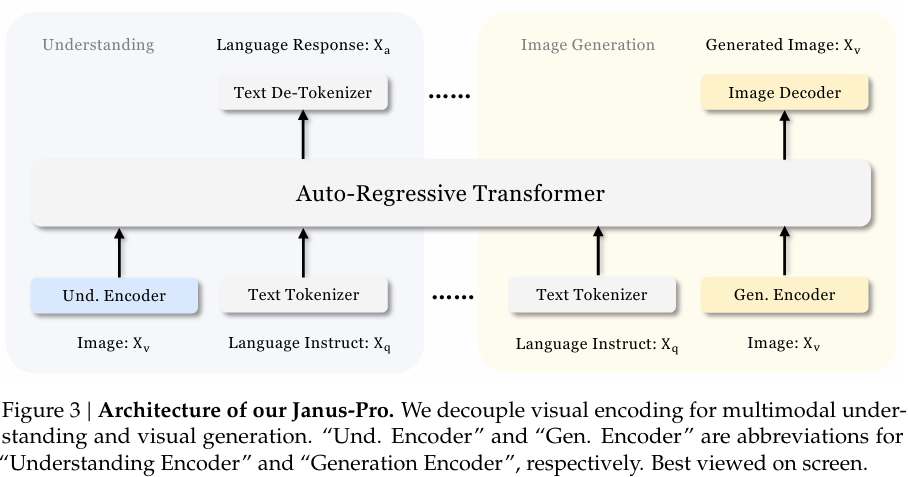
基本思想:是 Janus 的升级版,通过扩大数据规模、优化训练策略和增加模型参数,进一步提升多模态理解和生成的稳定性。
- 支持图文生成(如DALL-E 3风格创作),性能超越Stable Diffusion 3,适用于网文、影视开发等创意领域。
- 提供蒸馏版本(如Janus-Pro-7B),适配本地化部署。
(4)Janus系列对比(Janus,JanusFlow,Janus-Pro)
| 维度 | Janus | JanusFlow | Janus-Pro |
|---|---|---|---|
| 三者均支持文生图和图生文,但Janus-Pro在生成质量和稳定性上最优。 | |||
| 核心思想 | 解耦视觉编码,统一 Transformer | LLM + Rectified Flow 极简生成 | 数据/模型扩展 + 训练策略优化 |
| 视觉编码器 | SigLIP(理解) + VQ Tokenizer(生成) | SigLIP + SDXL-VAE | 升级版 SigLIP-L + VQ Tokenizer |
| 生成技术 | 自回归生成 | Rectified Flow流式生成 | 自回归生成(优化稳定性) |
| 参数量 | 1.3B | 1.3B | 1.5B/7B |
| 延迟(MSCOCO) | 65ms | 28ms | 120ms |
| 典型应用 | 通用多模态任务 | 实时流式处理(如实时金融监控,工业质检) | 专业生成(医疗、广告) |
总结:
-
Janus 奠定了双编码器解耦的基础框架,适合通用多模态任务。
-
JanusFlow 通过生成流实现高效实时处理,适合低延迟场景。
-
Janus-Pro 凭借数据扩展和模型规模化,成为专业领域的旗舰选择。
三、Others
1. ImageBind (2023)

paper: 2305.05665
github: ImageBind
2. PandaGPT
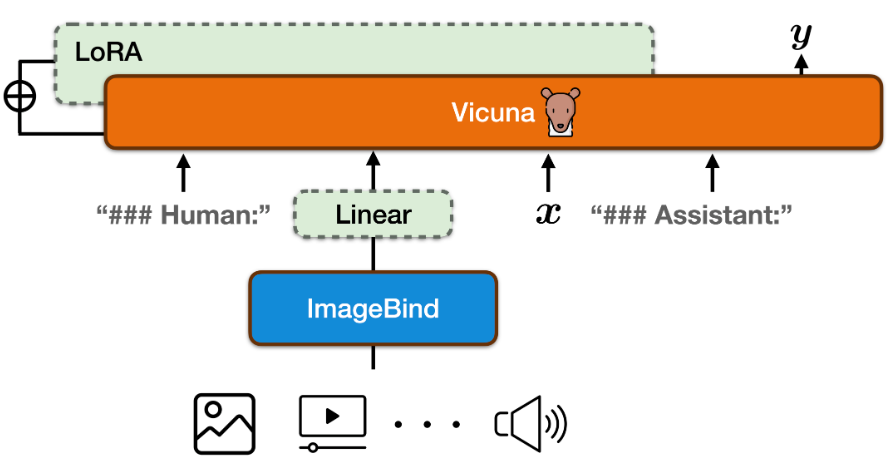
paper: [2305.16355] PandaGPT: One Model To Instruction-Follow Them All
github: GitHub - yxuansu/PandaGPT: [TLLM'23] PandaGPT: One Model To Instruction-Follow Them All
3. Grouding DINO
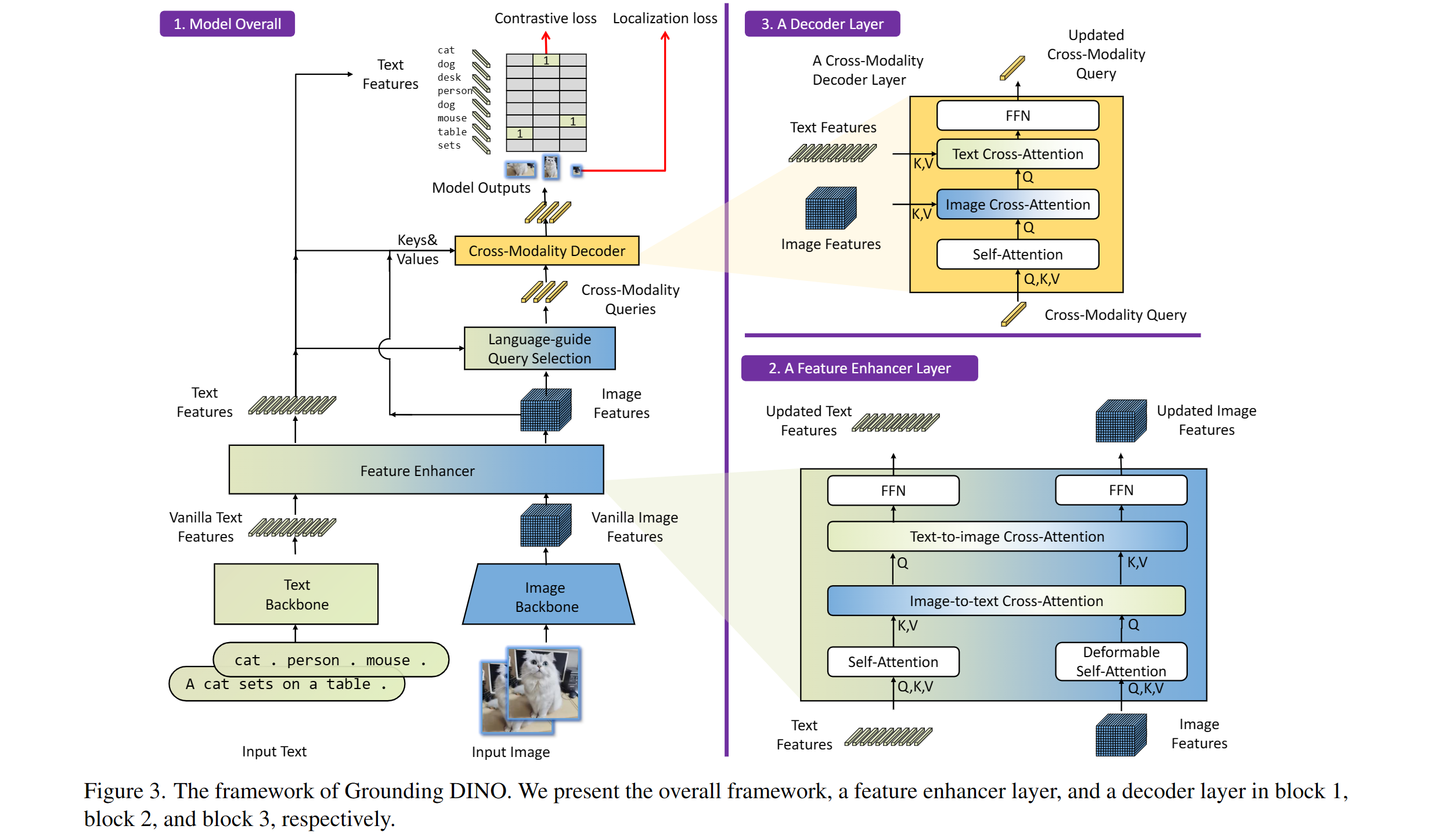
图3. Grouding DINO, including a text backbone, an image backbone, a feature enhancer, a language-guided query selection, and a cross-modality decoder. 发展历程:DINO -> DINO V2 -> Grounding DINO -> Grounding DINO 1.5 -> DINO-X.
paper: [2303.05499] Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection
github: GitHub - IDEA-Research/GroundingDINO: [ECCV 2024] Official implementation of the paper "Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection"