【Elasticsearch】文档(一):新增 删除
文档(一):新增 & 删除
- 1.文档的关键特性
- 2.新增文档
- 2.1 指定 ID 新增文档
- 2.2 不指定 ID 新增文档
- 2.3 指定索引批量插入数据
- 2.4 批量执行多种操作
- 2.5 关键说明
- 3.删除文档
- 3.1 删除单个文档
- 3.2 批量文档删除
- 3.2.1 方法 1:使用 _bulk 删除多个指定 ID 的文档
- 3.2.2 方法 2:使用 _delete_by_query 删除符合查询条件的文档
- 3.2.3 关键区别
- 3.3 最佳实践
在 Elasticsearch 中,文档(Document)是 最小的可索引数据单元,也是信息存储和检索的基本单位。它是 Elasticsearch 的核心概念之一,类似于关系型数据库中的一行记录或 NoSQL 数据库中的一个 JSON 对象。
1.文档的关键特性
-
JSON 格式:文档是一个 JSON 对象,由键值对(字段和值)组成。例如:
{"_index": "books", // 所属索引"_id": "1", // 文档ID"_source": { // 文档原始内容"title": "Elasticsearch 指南","author": "John Doe","publish_date": "2023-10-01"} } -
唯一标识:每个文档有一个唯一的
_id(可自定义或由 Elasticsearch 自动生成),用于在索引中唯一标识该文档。 -
归属于索引:文档必须存储在某个 索引(
Index)中(类似关系型数据库的 “表”)。例如,一个书籍文档可能存储在books索引中。 -
可扩展字段:文档的字段是动态的,无需预先定义结构(除非使用显式映射)。字段类型(如文本、数字、日期等)会自动推断或通过映射(
Mapping)指定。 -
支持嵌套和复杂结构:文档可以包含嵌套对象、数组等复杂结构。例如:
{"user": {"name": "Alice","address": {"city": "Beijing","postcode": "100000"}} }
2.新增文档
2.1 指定 ID 新增文档
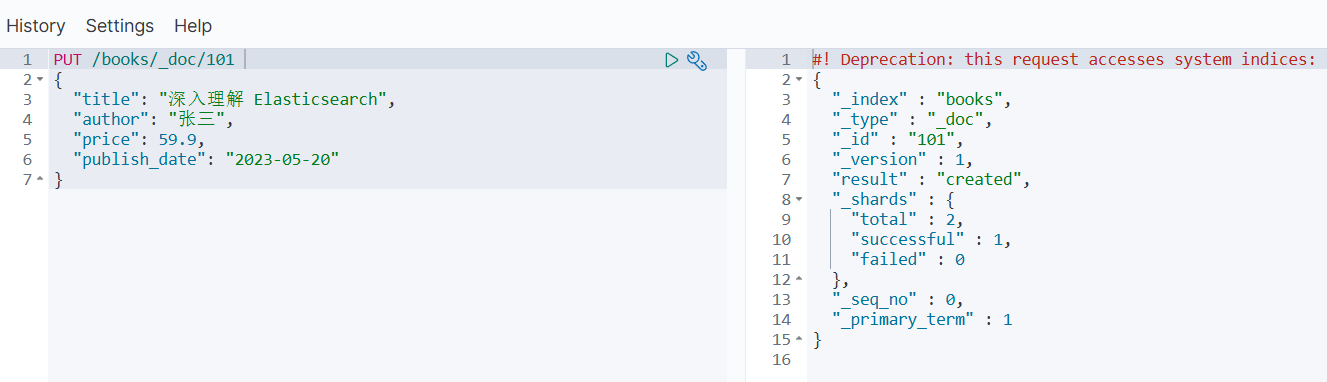
场景:明确指定文档的 _id(如书籍 ISBN 作为唯一标识)。
PUT /books/_doc/101 # 索引名: books, 文档ID: 101
{"title": "深入理解 Elasticsearch","author": "张三","price": 59.9,"publish_date": "2023-05-20"
}
2.2 不指定 ID 新增文档
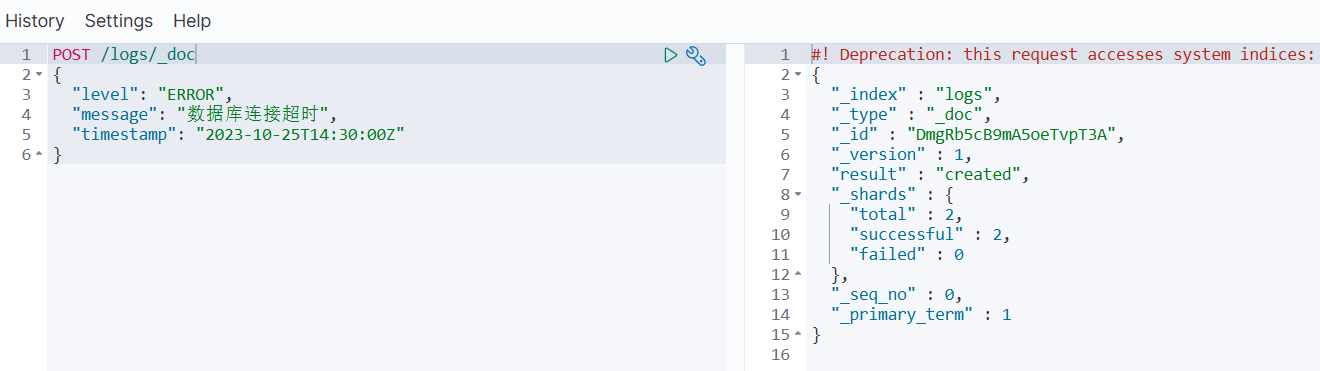
场景:让 Elasticsearch 自动生成唯一 _id(如日志场景)。
POST /logs/_doc # 索引名: logs, 不提供ID
{"level": "ERROR","message": "数据库连接超时","timestamp": "2023-10-25T14:30:00Z"
}
2.3 指定索引批量插入数据
场景:一次性插入多条文档到同一索引(如商品批量导入)。
POST /products/_bulk
{ "index": {} } # 不指定ID,自动生成
{ "name": "无线鼠标", "price": 99, "category": "电子产品" }
{ "index": { "_id": "1001" } } # 指定ID为1001
{ "name": "机械键盘", "price": 299, "category": "电子产品" }

2.4 批量执行多种操作
场景:混合插入、更新、删除操作(如订单系统数据处理)。
POST /orders/_bulk
{ "index": { "_id": "O20230999" } } # 新增订单
{ "order_id": "O20230999", "amount": 1500, "status": "paid" }
{ "index": { "_id": "O20230998" } } # 新增订单
{ "order_id": "O20230998", "amount": 1500, "status": "paid" }
POST /orders/_bulk
{ "index": { "_id": "O20231001" } } # 新增订单
{ "order_id": "O20231001", "amount": 1500, "status": "paid" }
{ "update": { "_id": "O20230999" } } # 更新订单状态
{ "doc": { "status": "shipped" } }
{ "delete": { "_id": "O20230998" } } # 删除订单

2.5 关键说明
- 批量操作(
_bulk):- 每两行为一个操作:首行声明动作(
index/update/delete),次行为数据或参数。 - 需确保 JSON 格式严格换行(末尾换行符不可省略)。
- 每两行为一个操作:首行声明动作(
- 自动生成 ID:
- 不指定
_id时,Elasticsearch 会生成类似x5F6Z4wB3Kp2YvE1的唯一字符串。
- 不指定
- HTTP 方法:
- 新增单条文档:
PUT(指定 ID)或POST(不指定 ID)。 - 批量操作:
POST /_bulk。
- 新增单条文档:
实际应用中,建议使用 Elasticsearch 客户端(如 Python 的 elasticsearch-py)简化操作。
3.删除文档
3.1 删除单个文档
场景:删除指定 _id 的文档(例如删除某本书)。
DELETE /books/_doc/101 # 删除索引 `books` 中 `_id=101` 的文档
响应:
{"_index": "books","_id": "101","_version": 2, # 版本号递增"result": "deleted", # 删除成功"_shards": {"total": 2,"successful": 2,"failed": 0}
}
说明:
- 如果文档不存在,返回
"result": "not_found"。 - 删除操作是 逻辑删除(文档不会立即从磁盘移除,而是在后续段合并时清理)。
3.2 批量文档删除
场景:批量删除符合特定条件的文档(例如删除所有 status="expired" 的订单)。
3.2.1 方法 1:使用 _bulk 删除多个指定 ID 的文档
POST /orders/_bulk
{ "delete": { "_id": "O20231001" } }
{ "delete": { "_id": "O20231002" } }
{ "delete": { "_id": "O20231003" } }
响应:
{"took": 10,"errors": false,"items": [{ "delete": { "_id": "O20231001", "status": 200 } },{ "delete": { "_id": "O20231002", "status": 200 } },{ "delete": { "_id": "O20231003", "status": 200 } }]
}
3.2.2 方法 2:使用 _delete_by_query 删除符合查询条件的文档
POST /orders/_delete_by_query
{"query": { "term": { "status": "expired" } # 删除所有 status=expired 的文档}
}
响应:
{"took": 100,"timed_out": false,"total": 5, # 共删除5条"deleted": 5,"batches": 1
}
说明:
_delete_by_query适用于 按条件删除,但会触发索引刷新,可能影响性能。- 大数据量删除时,建议添加
"conflicts": "proceed"参数(跳过冲突)和"scroll_size": 1000(分批处理)。
3.2.3 关键区别
| 操作类型 | 适用场景 | 性能影响 |
|---|---|---|
单条删除(DELETE) | 精确删除指定 _id 的文档 | 低开销,但多次调用效率低 |
批量删除(_bulk) | 删除多个已知 _id 的文档 | 网络和 I/O 优化,高效 |
条件删除(_delete_by_query) | 删除符合查询条件的文档 | 触发查询和刷新,大数据量时较慢 |
3.3 最佳实践
- 优先使用
_bulk:批量删除已知 ID 的文档时,_bulk比单条删除快 10-100 倍。 - 慎用
_delete_by_query:大数据量删除时,建议在低峰期执行,或使用slices并行化:POST /orders/_delete_by_query?conflicts=proceed&slices=5 {"query": { "range": { "create_time": { "lte": "2023-01-01" } } } } - 强制物理删除:删除后执行
_forcemerge清理磁盘空间:POST /orders/_forcemerge?only_expunge_deletes=true