基于统计检验与机器学习模型对牛油果数据的分析与预测
1.项目背景
牛油果(Avocado)作为全球广受欢迎的水果之一,其成熟度直接影响口感、营养和市场价值。Hass牛油果因其独特的外皮和细腻的果肉成为最常见的商业品种,牛油果的成熟过程伴随着果实硬度、颜色、重量、体积等物理特性的变化,准确判断成熟度对于供应链管理、消费者体验和自动化分拣具有重要意义。
本项目通过统计检验识别判断牛油果的成熟度的因素,并且通过构建机器学习模型,能够准确预测牛油果的成熟度,虽然数据是合成数据,但是分析的过程是可以复现的。
2.数据说明
| 字段 | 说明 |
|---|---|
| firmness | 果实硬度,穿透阻力(牛油果的硬度,单位N) |
| hue | 果皮主色调(色相,0-360°) |
| saturation | 色彩饱和度(0-100%) |
| brightness | 亮度(0-100%) |
| color_category | 视觉颜色分类(如深绿、紫色、黑色等) |
| sound_db | 敲击声学响应(分贝,30-80dB) |
| weight_g | 果实质量(克,150-300g) |
| size_cm3 | 果实体积(立方厘米,100-300cm³) |
| ripeness | 成熟度分级标签(hard(生硬), pre-conditioned(预熟), breaking(转熟), firm-ripe(硬熟), ripe(成熟)) |
3.Python库导入及数据读取
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from scipy.stats import mannwhitneyu,chi2_contingency,kruskal
import itertools
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import classification_report, confusion_matrix, ConfusionMatrixDisplay
from sklearn.model_selection import cross_val_score, StratifiedKFold
from sklearn.svm import SVC
from sklearn.ensemble import RandomForestClassifier
data = pd.read_csv('/home/mw/input/data3657/avocado_ripeness_dataset.csv')
4.数据预览及预处理
data.head()
| firmness | hue | saturation | brightness | color_category | sound_db | weight_g | size_cm3 | ripeness | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 14.5 | 19 | 40 | 26 | black | 34 | 175 | 261 | ripe |
| 1 | 71.7 | 53 | 69 | 75 | green | 69 | 206 | 185 | pre-conditioned |
| 2 | 88.5 | 60 | 94 | 46 | dark green | 79 | 220 | 143 | hard |
| 3 | 93.8 | 105 | 87 | 41 | dark green | 75 | 299 | 140 | hard |
| 4 | 42.5 | 303 | 58 | 32 | purple | 63 | 200 | 227 | breaking |
print('查看数据信息:')
data.info()
查看数据信息:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 250 entries, 0 to 249
Data columns (total 9 columns):# Column Non-Null Count Dtype
--- ------ -------------- ----- 0 firmness 250 non-null float641 hue 250 non-null int64 2 saturation 250 non-null int64 3 brightness 250 non-null int64 4 color_category 250 non-null object 5 sound_db 250 non-null int64 6 weight_g 250 non-null int64 7 size_cm3 250 non-null int64 8 ripeness 250 non-null object
dtypes: float64(1), int64(6), object(2)
memory usage: 17.7+ KB
print(f'查看重复值:{data.duplicated().sum()}')
查看重复值:0
characteristic = ['color_category','ripeness']
print('数据中颜色和成熟度标签的唯一值情况:')
for i in characteristic:print(f'{i}:')print(f'共有:{len(data[i].unique())}条唯一值')print(data[i].unique())print('-'*50)
数据中颜色和成熟度标签的唯一值情况:
color_category:
共有:4条唯一值
['black' 'green' 'dark green' 'purple']
--------------------------------------------------
ripeness:
共有:5条唯一值
['ripe' 'pre-conditioned' 'hard' 'breaking' 'firm-ripe']
--------------------------------------------------
颜色的话分别是:黑色、绿色、深绿色、紫色;成熟标签的话分别是成熟、预熟、生硬、转熟、硬熟,我查阅了一下,牛油果分为五个阶段,如下图所示(图片来源于:https://mbd.baidu.com/newspage/data/dtlandingsuper?nid=dt_3977908945549881010&sourceFrom=search_a)

在数据集中,顺序为:hard ➡pre-conditioned➡breaking➡firm-ripe➡ripe,这些分级有助于供应链管理、自动分拣和消费者选购。
feature_map = {'firmness': '果实硬度','hue': '色相','saturation': '饱和度','brightness': '亮度','sound_db': '敲击声分贝','weight_g': '重量','size_cm3': '体积'
}unit_map = {'firmness': '(N)','hue': '(°)', 'saturation': '(%)', 'brightness': '(%)', 'sound_db': '(dB)','weight_g': '(g)','size_cm3': '(cm$^3$)'
}# 子图标签
labels = ['(a)', '(b)', '(c)', '(d)', '(e)', '(f)', '(g)']fig = plt.figure(figsize=(20, 10))boxprops = {'edgecolor': 'black', 'facecolor': 'white', 'linewidth': 1.5}
whiskerprops = {'color': 'black', 'linewidth': 1.5}
capprops = {'color': 'black', 'linewidth': 1.5}
medianprops = {'color': 'black', 'linewidth': 2}
flierprops = {'marker': 'o', 'markerfacecolor': 'white', 'markeredgecolor': 'black', 'markersize': 6}for i, (col, col_name) in enumerate(feature_map.items(), 1):ax = fig.add_subplot(2, 4, i)# 使用自定义样式绘制箱线图sns.boxplot(y=data[col], ax=ax,boxprops=boxprops,whiskerprops=whiskerprops,capprops=capprops,medianprops=medianprops,flierprops=flierprops,width=0.5)ax.set_title(f'{labels[i-1]} {col_name}的分布')ax.set_ylabel(f'{col_name}{unit_map[col]}')# 设置网格线ax.grid(axis='y', linestyle='--', alpha=0.3)# 移除上边框和右边框ax.spines['top'].set_visible(False)ax.spines['right'].set_visible(False)# 加粗剩余的边框ax.spines['bottom'].set_linewidth(1.5)ax.spines['left'].set_linewidth(1.5)# 为整个图添加一个总标题
fig.suptitle('图 1 牛油果特征的异常值检验', fontsize=16, y=0.98)# 调整布局,确保图表不重叠
plt.tight_layout(rect=[0, 0, 1, 0.96]) # rect参数留出顶部空间给总标题
plt.show()
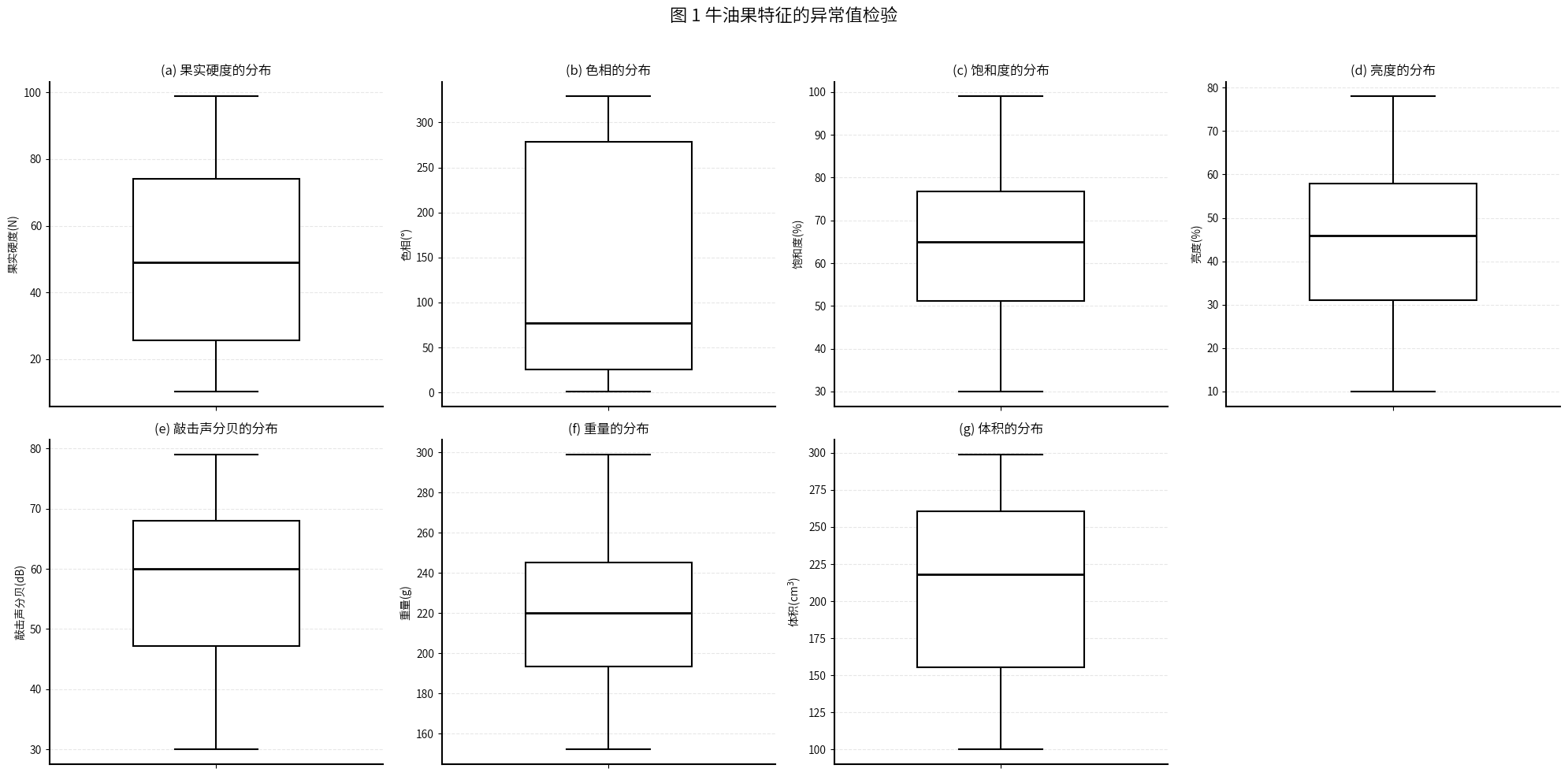
数据比较干净,可以直接开始分析了。
5.描述性分析
data.describe(include='all')
| firmness | hue | saturation | brightness | color_category | sound_db | weight_g | size_cm3 | ripeness | |
|---|---|---|---|---|---|---|---|---|---|
| count | 250.000000 | 250.00000 | 250.000000 | 250.00000 | 250 | 250.000000 | 250.000000 | 250.000000 | 250 |
| unique | NaN | NaN | NaN | NaN | 4 | NaN | NaN | NaN | 5 |
| top | NaN | NaN | NaN | NaN | black | NaN | NaN | NaN | ripe |
| freq | NaN | NaN | NaN | NaN | 75 | NaN | NaN | NaN | 50 |
| mean | 50.618400 | 125.94400 | 64.356000 | 45.07200 | NaN | 58.016000 | 220.188000 | 208.644000 | NaN |
| std | 27.277678 | 117.13767 | 17.377144 | 19.11629 | NaN | 13.838126 | 34.405225 | 55.940564 | NaN |
| min | 10.300000 | 1.00000 | 30.000000 | 10.00000 | NaN | 30.000000 | 152.000000 | 100.000000 | NaN |
| 25% | 25.750000 | 25.25000 | 51.250000 | 31.00000 | NaN | 47.250000 | 193.250000 | 155.250000 | NaN |
| 50% | 48.950000 | 77.00000 | 65.000000 | 46.00000 | NaN | 60.000000 | 220.000000 | 218.000000 | NaN |
| 75% | 74.050000 | 278.75000 | 76.750000 | 58.00000 | NaN | 68.000000 | 245.000000 | 260.500000 | NaN |
| max | 98.800000 | 329.00000 | 99.000000 | 78.00000 | NaN | 79.000000 | 299.000000 | 299.000000 | NaN |
fig = plt.figure(figsize=(20, 10))# 子图标签列表 - 使用标准格式
labels = ['(a)', '(b)', '(c)', '(d)', '(e)', '(f)', '(g)', '(h)']# 1. 果实硬度分布 (1,1)
ax1 = fig.add_subplot(2, 4, 1)
ax1.hist(data['firmness'], bins=15, edgecolor='black', color='white', linewidth=1.5)
ax1.set_title(f'{labels[0]} 果实硬度的频率分布')
ax1.set_xlabel('果实硬度 (N)')
ax1.set_ylabel('频数')
ax1.spines['top'].set_visible(False)
ax1.spines['right'].set_visible(False)
ax1.spines['bottom'].set_linewidth(1.5) # 加粗下边框
ax1.spines['left'].set_linewidth(1.5) # 加粗左边框# 2. 色相分布 - 使用极坐标 (1,2)
ax2 = fig.add_subplot(2, 4, 2, projection='polar')
hue_rad = np.deg2rad(data['hue'])
hist, bins = np.histogram(hue_rad, bins=36)
bin_centers = (bins[:-1] + bins[1:]) / 2
ax2.bar(bin_centers, hist, width=np.diff(bins), color='white', edgecolor='black', linewidth=1.5)
ax2.set_title(f'{labels[1]} 色相的极坐标分布')
# 为极坐标图添加角度标签
angles = np.arange(0, 360, 30)
ax2.set_thetagrids(angles, labels=[f'{angle}°' for angle in angles])
ax2.grid(True, linestyle='--', alpha=0.5)# 3. 饱和度分布 (1,3)
ax3 = fig.add_subplot(2, 4, 3)
ax3.hist(data['saturation'], bins=15, edgecolor='black', color='white', linewidth=1.5)
ax3.set_title(f'{labels[2]} 饱和度的频率分布')
ax3.set_xlabel('饱和度 (%)')
ax3.set_ylabel('频数')
ax3.spines['top'].set_visible(False)
ax3.spines['right'].set_visible(False)
ax3.spines['bottom'].set_linewidth(1.5)
ax3.spines['left'].set_linewidth(1.5)# 4. 亮度分布 (1,4)
ax4 = fig.add_subplot(2, 4, 4)
ax4.hist(data['brightness'], bins=15, edgecolor='black', color='white', linewidth=1.5)
ax4.set_title(f'{labels[3]} 亮度的频率分布')
ax4.set_xlabel('亮度 (%)')
ax4.set_ylabel('频数')
ax4.spines['top'].set_visible(False)
ax4.spines['right'].set_visible(False)
ax4.spines['bottom'].set_linewidth(1.5)
ax4.spines['left'].set_linewidth(1.5)# 5. 敲击声分贝分布 (2,1)
ax5 = fig.add_subplot(2, 4, 5)
ax5.hist(data['sound_db'], bins=15, edgecolor='black', color='white', linewidth=1.5)
ax5.set_title(f'{labels[4]} 敲击声分贝的频率分布')
ax5.set_xlabel('分贝值 (dB)')
ax5.set_ylabel('频数')
ax5.spines['top'].set_visible(False)
ax5.spines['right'].set_visible(False)
ax5.spines['bottom'].set_linewidth(1.5)
ax5.spines['left'].set_linewidth(1.5)# 6. 体积-质量散点图 (2,2)
ax6 = fig.add_subplot(2, 4, 6)
ax6.scatter(data['weight_g'], data['size_cm3'], edgecolor='black', facecolor='white', linewidth=1.5, alpha=0.7)
ax6.set_title(f'{labels[5]} 质量与体积的相关性')
ax6.set_xlabel('质量 (g)')
ax6.set_ylabel('体积 (cm$^3$)')
# 添加趋势线
z = np.polyfit(data['weight_g'], data['size_cm3'], 1)
p = np.poly1d(z)
ax6.plot(data['weight_g'], p(data['weight_g']), "r--", linewidth=1.5, alpha=0.7)
ax6.spines['top'].set_visible(False)
ax6.spines['right'].set_visible(False)
ax6.spines['bottom'].set_linewidth(1.5)
ax6.spines['left'].set_linewidth(1.5)# 7. 颜色类别分布 (2,3)
ax7 = fig.add_subplot(2, 4, 7)
color_counts = data['color_category'].value_counts().sort_index() # 排序以保持一致
bars = ax7.bar(color_counts.index, color_counts.values, edgecolor='black', linewidth=1.5)
for bar in bars:bar.set_facecolor('white')
# 添加数值标签
for bar in bars:height = bar.get_height()ax7.text(bar.get_x() + bar.get_width()/2., height,f'{int(height)}', ha='center', va='bottom')
ax7.set_title(f'{labels[6]} 颜色类别的频率分布')
plt.setp(ax7.get_xticklabels(), rotation=90)
ax7.set_xlabel('颜色类别')
ax7.set_ylabel('频数')
ax7.spines['top'].set_visible(False)
ax7.spines['right'].set_visible(False)
ax7.spines['bottom'].set_linewidth(1.5)
ax7.spines['left'].set_linewidth(1.5)# 8. 成熟度分布 (2,4)
ax8 = fig.add_subplot(2, 4, 8)
ripeness_counts = data['ripeness'].value_counts()
# 按成熟度级别排序
ripeness_order = ['hard', 'pre-conditioned', 'breaking', 'firm-ripe', 'ripe']
ripeness_sorted = pd.Series({k: ripeness_counts.get(k, 0) for k in ripeness_order})
bars = ax8.bar(ripeness_sorted.index, ripeness_sorted.values, edgecolor='black', linewidth=1.5)
for bar in bars:bar.set_facecolor('white')
# 添加数值标签
for bar in bars:height = bar.get_height()ax8.text(bar.get_x() + bar.get_width()/2., height,f'{int(height)}', ha='center', va='bottom')
ax8.set_title(f'{labels[7]} 成熟度级别的频率分布')
plt.setp(ax8.get_xticklabels(), rotation=90)
ax8.set_xlabel('成熟度级别')
ax8.set_ylabel('频数')
ax8.spines['top'].set_visible(False)
ax8.spines['right'].set_visible(False)
ax8.spines['bottom'].set_linewidth(1.5)
ax8.spines['left'].set_linewidth(1.5)fig.suptitle('图 2 牛油果特征分布与关联性分析', fontsize=16, y=0.98)
plt.tight_layout(rect=[0, 0, 1, 0.96])
plt.show()
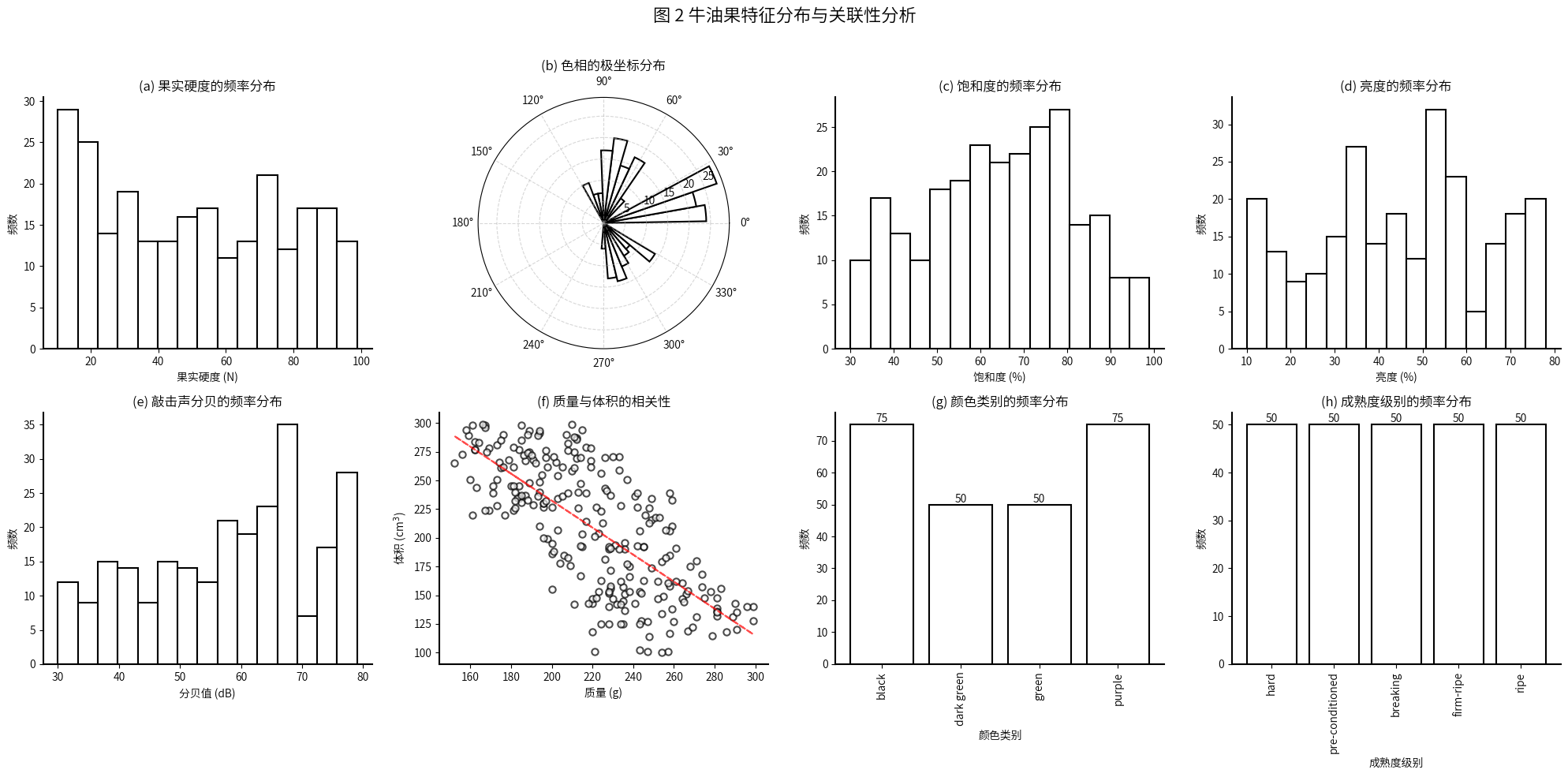
数值特征分布:
- 果实硬度: 平均50.6 N,主要分布在25.8-74.1 N区间
- 色相: 平均125.9°,分布不均匀,四分位差较大(25.3-278.8°)
- 饱和度: 平均64.4%,大部分集中在51.3-76.8%之间
- 亮度: 平均45.1%,分布范围为10-78%
- 敲击声分贝: 平均58.0 dB,主要分布在47.3-68.0 dB区间
- 重量: 平均220.2 g,四分位范围为193.3-245.0 g
- 体积: 平均208.6 cm³,分布范围较广(100-299 cm³)
分类特征分布:
- 颜色类别: black(75个)、dark green(50个)、green(50个)、purple(75个)
- 成熟度级别: 5个成熟度等级均为50个样本(hard、pre-conditioned、breaking、firm-ripe、ripe)
数据是虚拟合成的数据,存在比较不合理的地方,就是质量越大,体积越小,这明显是异常的,这明显是数据作者没考虑周到导致的。
6.统计检验
6.1Mann-Whitney U检验
plt.rcParams['font.size'] = 13
plt.rcParams['axes.titlesize'] = 14
plt.rcParams['axes.labelsize'] = 13
plt.rcParams['xtick.labelsize'] = 12
plt.rcParams['ytick.labelsize'] = 12# 删除色相
features = [k for k in feature_map.keys() if k != 'hue']
labels = ['(a)', '(b)', '(c)', '(d)', '(e)', '(f)']
n = len(features)
ncols = 3
nrows = 2fig, axes = plt.subplots(nrows, ncols, figsize=(20, 15))
axes = axes.flatten()for idx, feature in enumerate(features):ax = axes[idx]sns.boxplot(x='ripeness', y=feature, data=data, showfliers=True,order=ripeness_order,boxprops=dict(facecolor='white', edgecolor='black', linewidth=1.5),medianprops=dict(color='red', linewidth=1.5),whiskerprops=dict(color='black', linewidth=1.5),capprops=dict(color='black', linewidth=1.5),flierprops=dict(marker='o', color='black', alpha=0.5, markersize=5),linewidth=1.5,ax=ax)# 显著性标注unique_groups = ripeness_order pairs = list(itertools.combinations(unique_groups, 2))y_max = data[feature].max()y_min = data[feature].min()y_offset = (y_max - y_min) * 0.08 if y_max > y_min else 1for i, (g1, g2) in enumerate(pairs):data1 = data[data['ripeness'] == g1][feature].dropna()data2 = data[data['ripeness'] == g2][feature].dropna()# 跳过无数据的分组if len(data1) == 0 or len(data2) == 0:continuestat, p = mannwhitneyu(data1, data2, alternative='two-sided')x1, x2 = unique_groups.index(g1), unique_groups.index(g2)y = y_max + y_offset * (i+1)ax.plot([x1, x1, x2, x2], [y, y+0.5, y+0.5, y], lw=1.5, c='black')# 星号表示法if p < 0.0001:stars = '****'elif p < 0.001:stars = '***'elif p < 0.01:stars = '**'elif p < 0.05:stars = '*'else:stars = 'ns'ax.text((x1 + x2) / 2, y + 0.5, stars, ha='center', va='bottom', color='black', fontsize=13)# 设置标签和标题ax.set_xlabel('成熟度', fontsize=13)ax.set_ylabel(f"{feature_map[feature]} {unit_map[feature]}", fontsize=13)ax.set_title(f"{labels[idx]} 不同成熟度下{feature_map[feature]}分布", fontsize=14)ax.spines['top'].set_visible(False)ax.spines['right'].set_visible(False)ax.spines['bottom'].set_linewidth(1.5)ax.spines['left'].set_linewidth(1.5)ax.tick_params(axis='x', labelrotation=90)# 多余的子图隐藏
for j in range(n, nrows*ncols):fig.delaxes(axes[j])fig.suptitle('图 3 牛油果特征不同成熟度下分布及Mann-Whitney U检验', fontsize=16, y=0.98)
plt.tight_layout(rect=[0, 0, 1, 0.96])
plt.show()
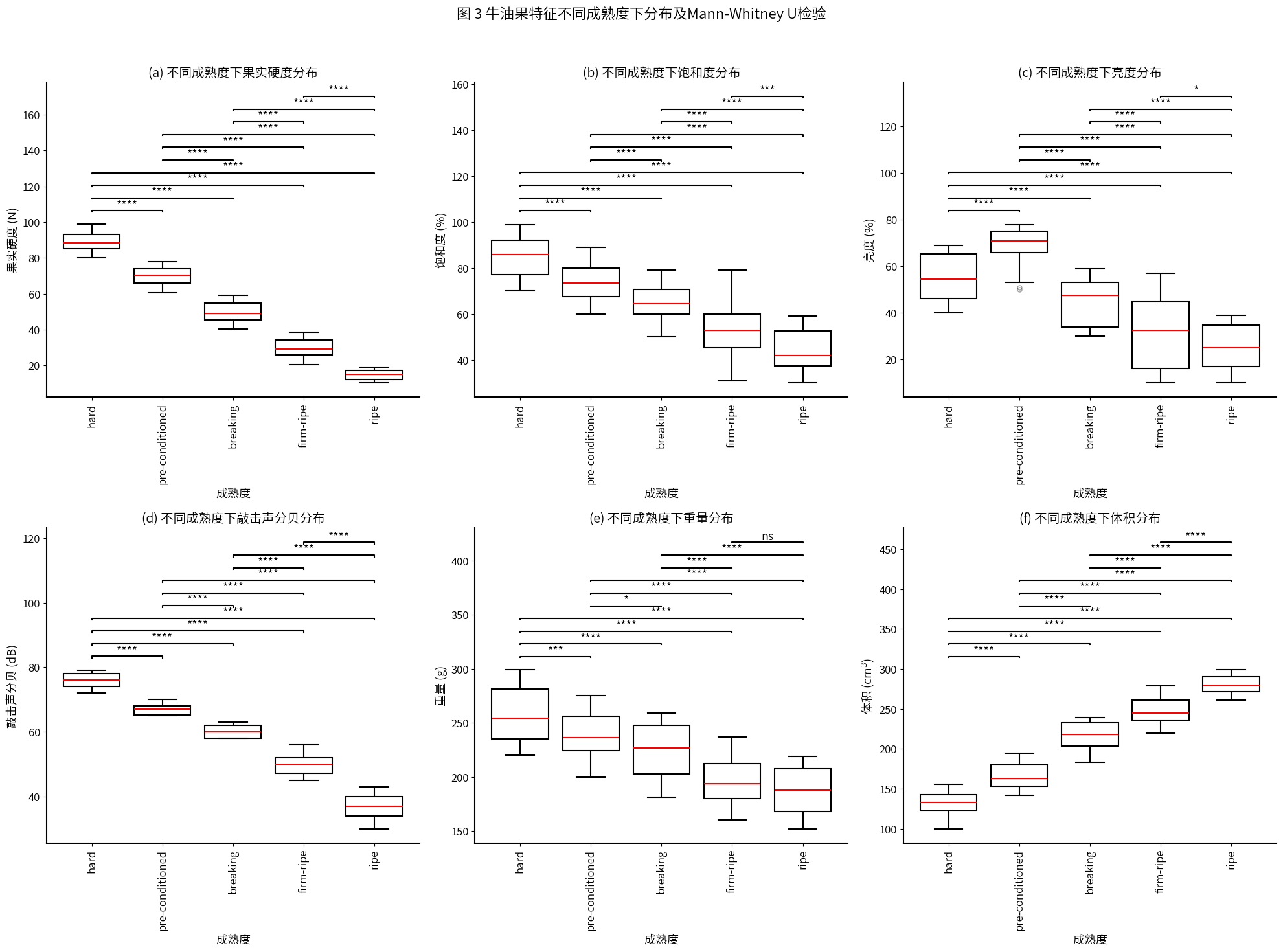
- 果实硬度:果实硬度在不同成熟度分级间存在极显著差异,随着成熟度的增加,果实硬度逐渐降低。
- 饱和度:饱和度在不同成熟度分级间存在极显著差异,随着成熟度的增加,饱和度逐渐降低。
- 亮度:饱和度在不同成熟度分级间存在显著差异,预熟的时候亮度最高,随着成熟度增加,亮度逐渐降低。
- 敲击声分贝:敲击声分贝在不同成熟度分级间存在极显著差异,随着成熟度增加,敲击声分贝越低,与果实硬度有关。
- 重量:重量在不同成熟度分级间存在显著差异,随着成熟度增加,重量越低,硬熟期和成熟期的差异不显著。
- 体积:体积在不同成熟度分级间存在极显著差异,随着成熟度增加,体积越大。
这里色相不能使用Mann-Whitney U检验,因为是环状变量,0°和360°等价,不能直接用普通的线性统计方法,通过询问AI,AI给了我一个方法:圆形统计(Circular Statistics)。
圆形统计是专门用于分析方向性数据或周期性数据(如角度、时间、方位、色相等)的统计分支,它与常规的线性统计方法有本质区别,因为圆形数据的“头尾相接”特性(如0°和360°是同一个点)。
1. 圆形数据的典型场景
- 角度:风向、动物迁徙方向、地震方位等
- 时间:一天24小时(0点和24点是同一时刻)
- 色相:色轮上的色相(0°和360°等价)
- 生物节律:如昼夜节律、季节性变化
2. 圆形统计的基本概念
(1)均值和方差
- 圆形均值:不是简单的算术平均,而是将每个角度转为单位向量(sin/cos分量),求向量和的方向。
- 圆形方差/标准差:反映数据在圆上的分散程度。
(2)距离和差异
- 圆形距离:两个角度的最短弧长(如5°和355°的距离是10°,不是350°)。
(3)分布
- 常见分布:如均匀分布、von Mises分布(圆形上的“正态分布”)。
3. 圆形统计的常用指标
- 圆形均值方向(mean direction):
θ ˉ = arctan 2 ( ∑ sin θ i , ∑ cos θ i ) \bar{\theta} = \arctan2(\sum \sin\theta_i, \sum \cos\theta_i) θˉ=arctan2(∑sinθi,∑cosθi) - 均向长度(mean resultant length, R):
R = ( ∑ cos θ i ) 2 + ( ∑ sin θ i ) 2 / n R = \sqrt{(\sum \cos\theta_i)^2 + (\sum \sin\theta_i)^2} / n R=(∑cosθi)2+(∑sinθi)2/n
R越接近1,数据越集中;越接近0,数据越分散。 - 圆形方差: 1 − R 1 - R 1−R
- 圆形标准差: − 2 ln R \sqrt{-2 \ln R} −2lnR
4. 圆形统计的常用检验方法
- Rayleigh检验:检验数据是否均匀分布在圆上(无偏向性)。
- Watson-Williams检验:多组均值方向的方差分析(要求分布近似von Mises)。
- Mardia-Watson-Wheeler检验:多组分布的非参数检验(类似Kruskal-Wallis,但针对圆形数据)。
- Kuiper检验、Watson U²检验:分布一致性检验,类似于Kolmogorov-Smirnov检验但适用于圆形数据。
一般使用R的circular包来实现,Python库都存在局限性,这里AI给了我平替的方法:Kruskal-Wallis 检验,后续会展开介绍。
5. 圆形统计与线性统计的区别
| 线性统计 | 圆形统计 |
|---|---|
| 0和最大值不相等 | 0和最大值相等 |
| 均值=算术平均 | 均值=向量平均 |
| 距离=绝对差 | 距离=最短弧长 |
| 方差=平方差平均 | 方差=1-R |
6. 参考资料
- R包文档:circular: Circular Statistics
6.2Kruskal-Wallis 检验
Kruskal-Wallis 检验在色相(Hue)分析中的应用
1. Kruskal-Wallis 检验简介
- Kruskal-Wallis 检验是非参数的方差分析(ANOVA),用于比较三个及以上独立样本的中位数是否有显著差异。
- 适用于不服从正态分布的数据。
- 其本质是将所有数据排序后,比较各组的秩和。
2. 色相的Kruskal-Wallis检验思路
因为色相是环状的,直接用角度会导致0°和360°被人为拉远,失去真实的距离关系,所以将色相角度(度)转为弧度,然后分别计算其正弦(sin) 和余弦(cos) 分量,色相的环状特性就被保留在sin/cos的周期性变化中,对sin分量和cos分量分别做Kruskal-Wallis检验,如果任一分量有显著差异,说明组间色相分布有差异。
# 角度转弧度
data['hue_rad'] = np.deg2rad(data['hue'])groups = ['hard', 'pre-conditioned', 'breaking', 'firm-ripe', 'ripe']
hue_rad_groups = [data.loc[data['ripeness'] == g, 'hue_rad'].dropna() for g in groups]# 对sin分量做Kruskal-Wallis检验
sin_groups = [np.sin(g) for g in hue_rad_groups]
stat_sin, p_sin = kruskal(*sin_groups)# 对cos分量做Kruskal-Wallis检验
cos_groups = [np.cos(g) for g in hue_rad_groups]
stat_cos, p_cos = kruskal(*cos_groups)print(f"Kruskal-Wallis检验(sin分量)p值: {p_sin:.4g}")
print(f"Kruskal-Wallis检验(cos分量)p值: {p_cos:.4g}")if p_sin < 0.05 or p_cos < 0.05:print("不同成熟度组的色相分布存在显著差异。")
else:print("不同成熟度组的色相分布无显著差异。")
Kruskal-Wallis检验(sin分量)p值: 7.903e-44
Kruskal-Wallis检验(cos分量)p值: 3.366e-34
不同成熟度组的色相分布存在显著差异。
6.3卡方检验
对于最后的颜色特征,这里采用的是卡方检验,卡方检验是一种用于分类变量之间关系分析的统计方法,主要用于判断两个(或多个)分类变量是否独立无关。
contingency_table = pd.crosstab(data['color_category'], data['ripeness'])
print(contingency_table)
ripeness breaking firm-ripe hard pre-conditioned ripe
color_category
black 0 25 0 0 50
dark green 0 0 50 0 0
green 0 0 0 50 0
purple 50 25 0 0 0
chi2, p, dof, expected = chi2_contingency(contingency_table)
print(f"Chi2统计量: {chi2:.3f}")
print(f"p值: {p:.4f}")
print(f"自由度: {dof}")
print("理论频数表:\n", pd.DataFrame(expected, index=contingency_table.index, columns=contingency_table.columns))
Chi2统计量: 666.667
p值: 0.0000
自由度: 12
理论频数表:ripeness breaking firm-ripe hard pre-conditioned ripe
color_category
black 15.0 15.0 15.0 15.0 15.0
dark green 10.0 10.0 10.0 10.0 10.0
green 10.0 10.0 10.0 10.0 10.0
purple 15.0 15.0 15.0 15.0 15.0
理论频数表(expected counts table)是指:
在卡方检验中,假设两个变量(如color_category和ripeness)完全独立,那么每个单元格“理论上”应该出现多少个样本。
计算方法
对于某一单元格(第i行第j列):
E i j = ( 第i行总和 ) × ( 第j列总和 ) 总样本数 E_{ij} = \frac{(\text{第i行总和}) \times (\text{第j列总和})}{\text{总样本数}} Eij=总样本数(第i行总和)×(第j列总和)
- 例如,如果某行总和是100,某列总和是50,总样本数是200,那么该单元格的理论频数就是 100 × 50 200 = 25 \frac{100 \times 50}{200} = 25 200100×50=25。
作用
- 卡方检验就是比较“实际观测频数”(表里的数字)和“理论频数”之间的差异。
- 如果差异很大,说明变量之间有关联;如果差异很小,说明变量独立。
7.预测牛油果成熟度
7.1数据预处理
data['hue_sin'] = np.sin(data['hue_rad'])
data['hue_cos'] = np.cos(data['hue_rad'])
features = ['firmness','hue_sin','hue_cos', 'saturation', 'brightness', 'sound_db', 'weight_g', 'size_cm3', 'color_category']
target = 'ripeness'
new_data = data[features + [target]].copy()
new_data = pd.get_dummies(new_data, columns=['color_category'], prefix='color', dtype=int)
x = new_data.drop(columns=[target])
y = new_data[target]
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=15, stratify=y)
scaler = StandardScaler()
num_cols = ['firmness', 'saturation', 'brightness', 'sound_db', 'weight_g', 'size_cm3']
x_train[num_cols] = scaler.fit_transform(x_train[num_cols])
x_test[num_cols] = scaler.transform(x_test[num_cols])
这里补充两个点:
- 数据预处理的时候,我之前总是喜欢先标准化后再进行数据划分,这样实际上有数据泄露的风险。
stratify=y的作用是分层抽样,即保证训练集和测试集中的各类别比例与原始数据一致。
7.2 多分类逻辑回归
# solver='lbfgs' 支持多分类,multi_class='multinomial' 表示用softmax
log_clf = LogisticRegression(multi_class='multinomial', solver='lbfgs', max_iter=1000, random_state=15)
cv = StratifiedKFold(n_splits=5, shuffle=True, random_state=15)
log_cv_scores = cross_val_score(log_clf, x_train, y_train, cv=cv, scoring='accuracy')
print("逻辑回归 5折交叉验证准确率:", log_cv_scores)
print("逻辑回归 平均交叉验证准确率:", log_cv_scores.mean())
逻辑回归 5折交叉验证准确率: [1. 0.925 0.975 1. 1. ]
逻辑回归 平均交叉验证准确率: 0.9800000000000001
- 每一折的准确率分别为:100%、92.5%、97.5%、100%、100%。 平均准确率为98%。
- 模型在不同训练子集上的表现都非常好,准确率都很高,且波动很小,说明特征对成熟度的预测能力很强,模型泛化能力也很不错。
log_clf.fit(x_train, y_train)
log_y_pred = log_clf.predict(x_test)
print("逻辑回归模型分类报告:\n", classification_report(y_test, log_y_pred))
逻辑回归模型分类报告:precision recall f1-score supportbreaking 0.91 1.00 0.95 10firm-ripe 1.00 0.90 0.95 10hard 1.00 1.00 1.00 10
pre-conditioned 1.00 1.00 1.00 10ripe 1.00 1.00 1.00 10accuracy 0.98 50macro avg 0.98 0.98 0.98 50weighted avg 0.98 0.98 0.98 50
log_cm = confusion_matrix(y_test, log_y_pred, labels=ripeness_order)
log_disp = ConfusionMatrixDisplay(confusion_matrix=log_cm, display_labels=ripeness_order)
fig, ax = plt.subplots(figsize=(10, 8))
log_disp.plot(ax=ax, cmap='Blues', colorbar=True)
plt.title("图 4 逻辑回归多分类混淆矩阵", fontsize=16)
plt.xlabel("预测标签")
plt.ylabel("真实标签")
plt.show()
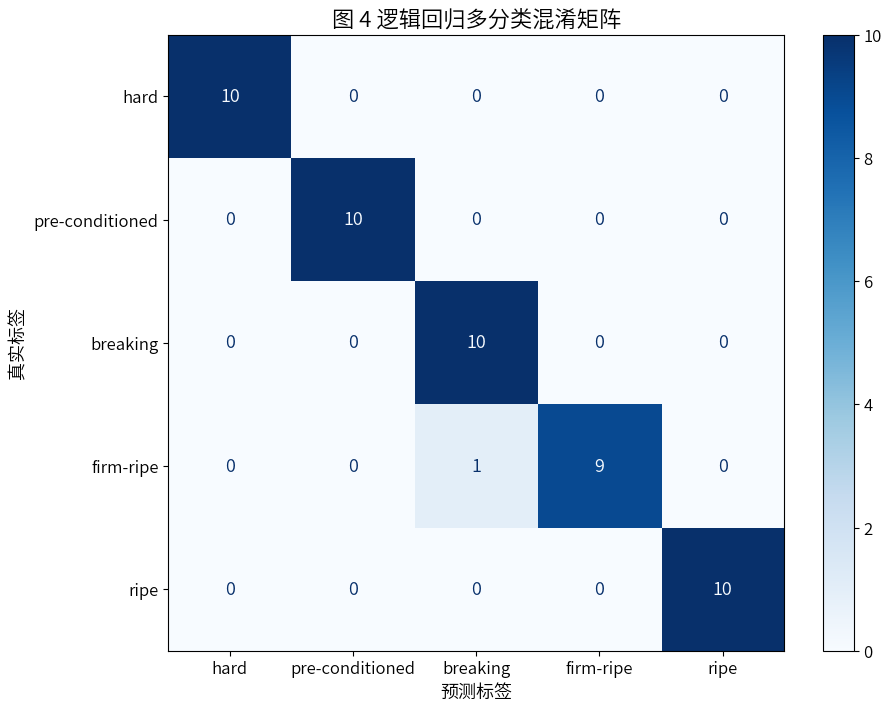
- 准确率 (accuracy):0.98,即50个样本中有49个被正确分类。
- macro avg / weighted avg:都为0.98,说明各类别表现均衡,没有某一类被“牺牲”。
- 根据混淆矩阵发现,绝大多数样本都被正确分类(对角线上的数字为10,只有一个“硬熟”被误分为“转熟”)。
7.3支持向量机
# 建立SVM模型(多分类,RBF核)
svm_clf = SVC(kernel='rbf', decision_function_shape='ovr', probability=True, random_state=15)
svm_cv_scores = cross_val_score(svm_clf, x_train, y_train, cv=cv, scoring='accuracy')
print("SVM 5折交叉验证准确率:", svm_cv_scores)
print("SVM 平均交叉验证准确率:", svm_cv_scores.mean())
SVM 5折交叉验证准确率: [1. 0.975 0.975 1. 1. ]
SVM 平均交叉验证准确率: 0.99
- 每一折的准确率分别为:100%、97.5%、97.5%、100%、100%。 平均准确率为99%。
- 模型在不同训练子集上的表现都非常好,准确率都很高,且波动很小,说明特征对成熟度的预测能力很强,模型泛化能力也很不错。
svm_clf.fit(x_train, y_train)
svm_y_pred = svm_clf.predict(x_test)
print("SVM 分类报告:\n", classification_report(y_test, svm_y_pred))
SVM 分类报告:precision recall f1-score supportbreaking 1.00 1.00 1.00 10firm-ripe 1.00 1.00 1.00 10hard 1.00 1.00 1.00 10
pre-conditioned 1.00 1.00 1.00 10ripe 1.00 1.00 1.00 10accuracy 1.00 50macro avg 1.00 1.00 1.00 50weighted avg 1.00 1.00 1.00 50
svm_cm = confusion_matrix(y_test, svm_y_pred, labels=ripeness_order)
svm_disp = ConfusionMatrixDisplay(confusion_matrix=svm_cm, display_labels=ripeness_order)
fig, ax = plt.subplots(figsize=(10, 8))
svm_disp.plot(ax=ax, cmap='Blues', colorbar=True)
plt.title("图 5 SVM 多分类混淆矩阵", fontsize=16)
plt.xlabel("预测标签")
plt.ylabel("真实标签")
plt.show()
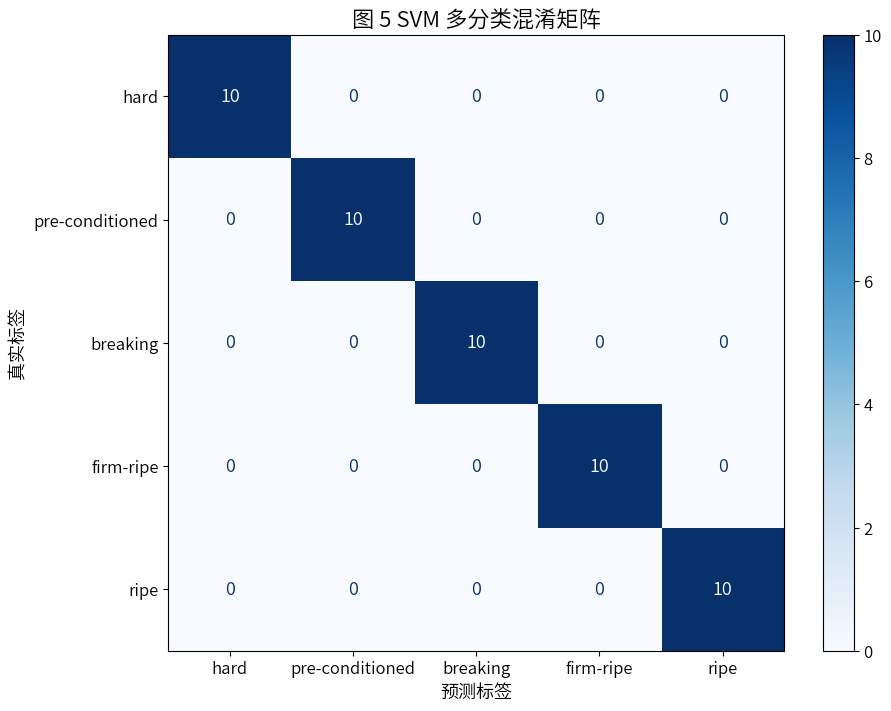
- 每个类别的精确率、召回率、F1分数都是1.00。
- 整体准确率100%,macro avg和weighted avg也都是1.00。
- 根据混淆矩阵发现对角线全为10,其他全为0,说明每个类别的10个样本全部被正确分类,没有任何误分。
7.4随机森林
rf_clf = RandomForestClassifier(n_estimators=100, random_state=15)
rf_cv_scores = cross_val_score(rf_clf, x_train, y_train, cv=cv, scoring='accuracy')
print("随机森林 5折交叉验证准确率:", rf_cv_scores)
print("随机森林 平均交叉验证准确率:", rf_cv_scores.mean())
随机森林 5折交叉验证准确率: [1. 1. 1. 1. 1.]
随机森林 平均交叉验证准确率: 1.0
- 每一折的准确率都是100%!
- 模型在不同训练子集上的表现可以用夸张来形容。
rf_clf.fit(x_train, y_train)
rf_y_pred = rf_clf.predict(x_test)
print("\n随机森林 分类报告:\n", classification_report(y_test, rf_y_pred))
随机森林 分类报告:precision recall f1-score supportbreaking 1.00 1.00 1.00 10firm-ripe 1.00 1.00 1.00 10hard 1.00 1.00 1.00 10
pre-conditioned 1.00 1.00 1.00 10ripe 1.00 1.00 1.00 10accuracy 1.00 50macro avg 1.00 1.00 1.00 50weighted avg 1.00 1.00 1.00 50
rf_cm = confusion_matrix(y_test, rf_y_pred, labels=ripeness_order)
rf_disp = ConfusionMatrixDisplay(confusion_matrix=rf_cm, display_labels=ripeness_order)
fig, ax = plt.subplots(figsize=(10, 8))
rf_disp.plot(ax=ax, cmap='Blues', colorbar=True)
plt.title("图 6 随机森林多分类混淆矩阵", fontsize=16)
plt.xlabel("预测标签")
plt.ylabel("真实标签")
plt.show()
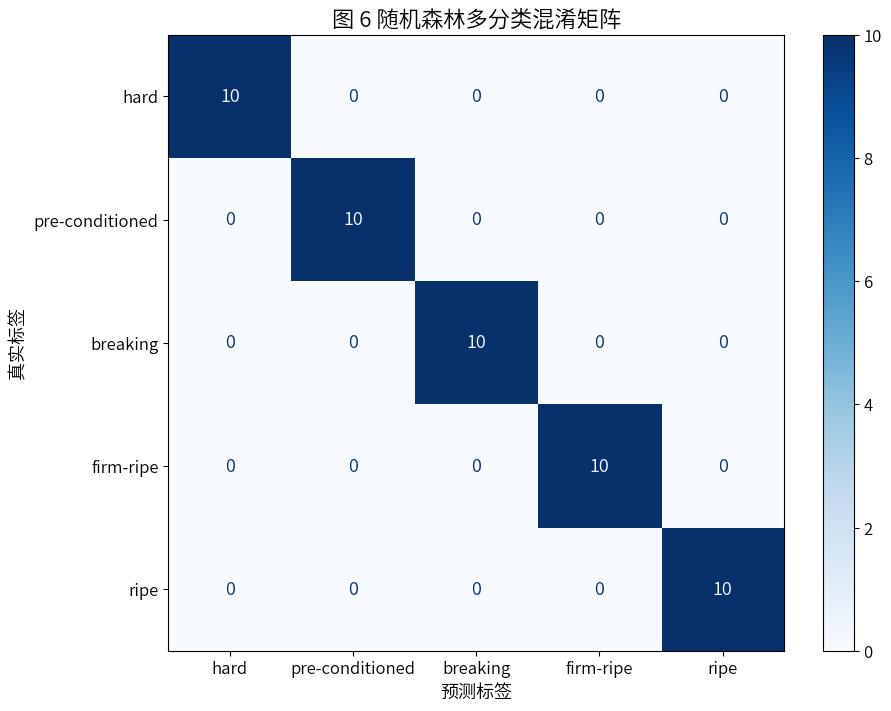
- 每个类别的精确率、召回率、F1分数都是1.00。
- 整体准确率100%,macro avg和weighted avg也都是1.00。
- 根据混淆矩阵发现对角线全为10,其他全为0,说明每个类别的10个样本全部被正确分类,没有任何误分。
8.总结
本项目基于对牛油果合成数据的系统分析,得出以下主要结论:
- 数据特征:果实硬度平均为50.6 N,主要分布在25.8-74.1 N区间;色相平均125.9°,分布不均且四分位差较大(25.3-278.8°);饱和度平均64.4%,大部分集中在51.3-76.8%;亮度平均45.1%,分布范围为10-78%;敲击声分贝平均58.0 dB,主要分布在47.3-68.0 dB;重量平均220.2 g,四分位范围为193.3-245.0 g;体积平均208.6 cm³,分布范围较广(100-299 cm³)。分类特征方面,颜色类别分为black(75个)、dark green(50个)、green(50个)、purple(75个);成熟度级别共5类,每类各50个样本。同时发现存在如“质量越大体积越小”不合理现象,反映了数据生成时的不足。
- 统计检验:通过对数据进行Mann-Whitney U检验、Kruskal-Wallis 检验、卡方检验,发现果实硬度、果皮色相、色彩饱和度、亮度、颜色、敲击声分贝、重量、体积均对果实成熟度的识别有影响。
- 机器学习:构建了逻辑回归模型、支持向量机、随机森林三个模型,预测效果都非常好,其中支持向量机和随机森林甚至达到了100%的准确率,也佐证了这个合成数据的特征差异非常明显。