论文略读:Personality Alignment of Large Language Models
ICLR 2025 558
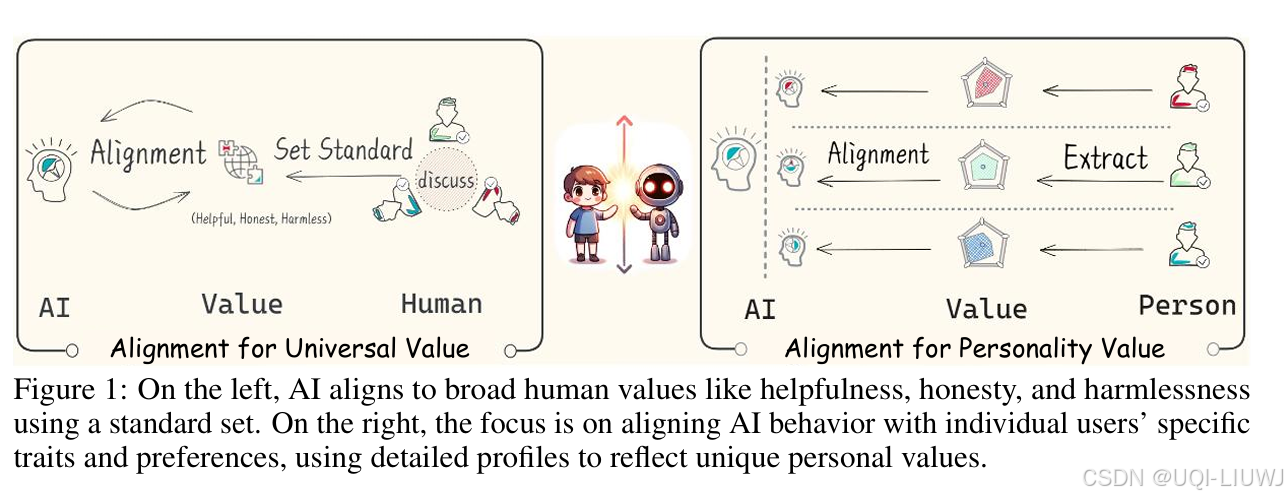
当前的大语言模型(LLMs)在对齐时,通常旨在反映普遍的人类价值观与行为模式,但却常常无法捕捉到个体用户的独特特征与偏好。
为填补这一空白,本文提出了**“人格对齐(Personality Alignment)”的新概念。该方法旨在使LLM的回答和决策过程能够贴合具体用户或相关群体的个性化偏好**。
受心理测量学(psychometrics)启发,我们构建了PAPI 数据集(Personality Alignment with Personality Inventories),该数据集包含来自超过32万名真实用户的个性测试数据,涵盖了:
-
大五人格(Big Five Personality Factors)
-
“黑暗三性格”特质(Dark Triad Traits)
这一全面的数据集,使我们能够量化评估LLMs在正面人格维度与潜在问题人格维度上的对齐能力。
考虑到人格对齐面临的挑战(如个人数据有限、偏好多样、对可扩展性要求高),我们提出了一种名为**激活干预优化(activation intervention optimization)**的方法,能够在仅需极少数据与计算资源的条件下,有效提升LLMs对个体行为偏好的对齐能力。
我们的方法PAS在实验中展现出卓越性能,且所需优化时间仅为现有方法 DPO 的 1/5,在实用性与效率方面具有显著优势。
我们的研究为未来AI系统实现人格化决策与推理提供了全新路径,使AI交互更具相关性、个性化与人本价值。
数据集与代码已开源,地址为:https://github.com/zhu-minjun/PAlign。