Python数据可视化:Seaborn入门与实践
Seaborn入门与实践
- Seaborn
- 概述
- 环境准备
- Seaborn基本使用
- 环境准备
- 数据说明
- 绘制散点图(Scatter Plot)
- 绘制折线图(Line Plot)
- 绘制柱状图(Bar Plot)
- 绘制直方图(Histogram)
- Seaborn进阶使用
- 多图绘制(FacetGrid)
- 样式设置
- 回归图(Regression Plot)
- 直方图(Histogram)
- 核密度估计图(Kernel Density Estimate, KDE)
- 箱线图(Box Plot)
- 小提琴图(Violin Plot)
- 热力图(Heatmap)
- 计数图(Count Plot)
- 联合分布图(Joint Plot)
- 多变量分布图(Pair Plot)
- 分析泰坦尼克号数据集(titanic)
- 环境准备
- 数据说明
- 乘客生存率的柱状图
- 不同舱位的票价分布
- 年龄与生存率的关系
- 分析鸢尾花数据集(iris)
- 环境准备
- 数据说明
- 不同种类的花瓣长度分布
- 花萼长度与花瓣长度的关系
- 数据集中特征的相关性
Seaborn
概述
Seaborn是一个基于 Matplotlib 的 Python 数据可视化库,专注于统计图表的绘制。它提供了更高级的接口和更美观的默认样式,非常适合用于数据分析和探索性数据分析(EDA)。
官方文档:Seaborn
中文文档:Seaborn
环境准备
安装Seaborn和Matplotlib:
pip install seaborn matplotlib
安装Pandas和NumPy:
pip install pandas numpy
Seaborn基本使用
从Seaborn的核心功能和基本图表开始,了解Seaborn的基本语法以及掌握常用图表的绘制方法
环境准备
Seaborn自带一些示例数据集,非常适合练习。
import seaborn as sns
import matplotlib.pyplot as plt# 加载示例数据集
tips = sns.load_dataset("tips")
# 打印前5行数据
print(tips.head())
数据说明
tips是Seaborn 提供的一个示例数据集,记录了餐厅顾客的小费数据。
total_bill tip sex smoker day time size
0 16.99 1.01 Female No Sun Dinner 2
1 10.34 1.66 Male No Sun Dinner 3
2 21.01 3.50 Male No Sun Dinner 3
3 23.68 3.31 Male No Sun Dinner 2
4 24.59 3.61 Female No Sun Dinner 4
数据列说明
| 列名 | 类型 | 说明 |
|---|---|---|
total_bill | 数值型(float) | 账单总金额(美元) |
tip | 数值型(float) | 顾客支付的小费金额(美元) |
sex | 分类变量(字符串) | 顾客的性别,取值为 Male(男性)或 Female(女性) |
smoker | 分类变量(字符串) | 顾客是否吸烟,取值为 Yes(吸烟)或 No(不吸烟) |
day | 分类变量(字符串) | 顾客用餐的星期几,取值为 Thur(星期四)、Fri(星期五)、Sat(星期六)或 Sun(星期日) |
time | 分类变量(字符串) | 用餐时间,取值为 Lunch(午餐)或 Dinner(晚餐) |
size | 数值型(int) | 用餐人数 |
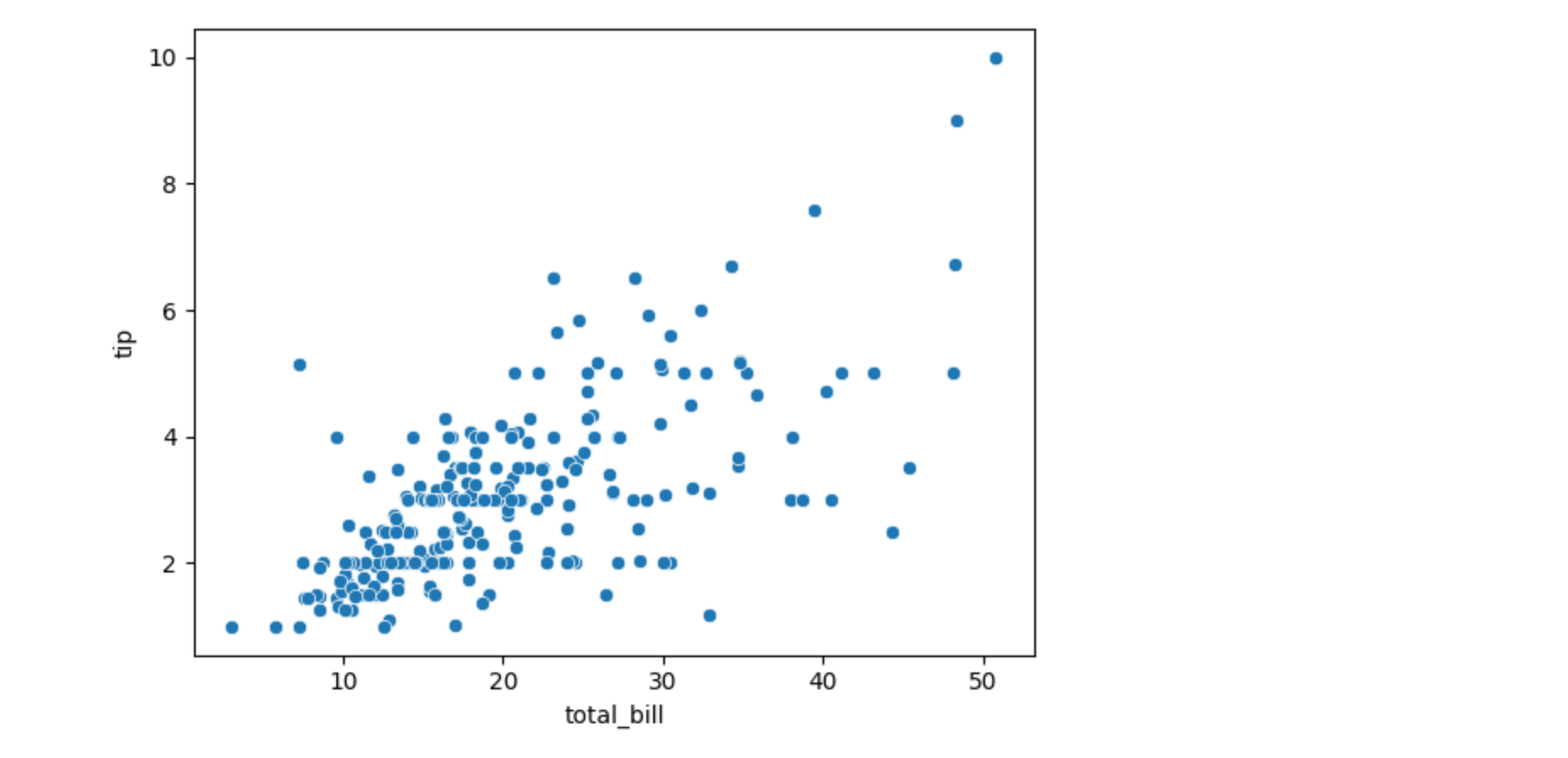
绘制散点图(Scatter Plot)
散点图用于显示两个连续变量之间的关系,适合观察变量之间的趋势、聚类或异常值。
sns.scatterplot(x="total_bill", y="tip", data=tips)
plt.show()
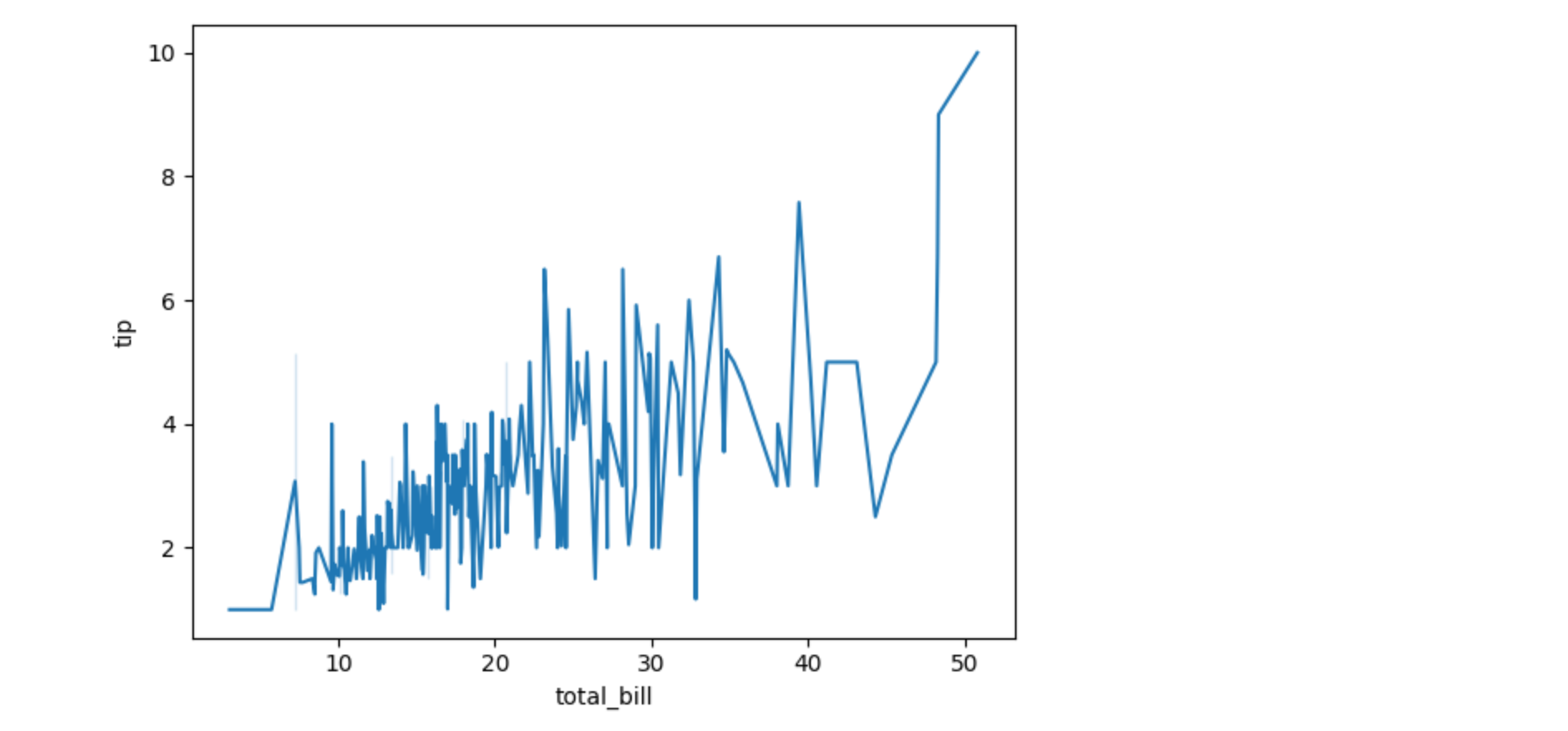
绘制折线图(Line Plot)
折线图用于显示数据随时间的变化趋势。
sns.lineplot(x="total_bill", y="tip", data=tips)
plt.show()
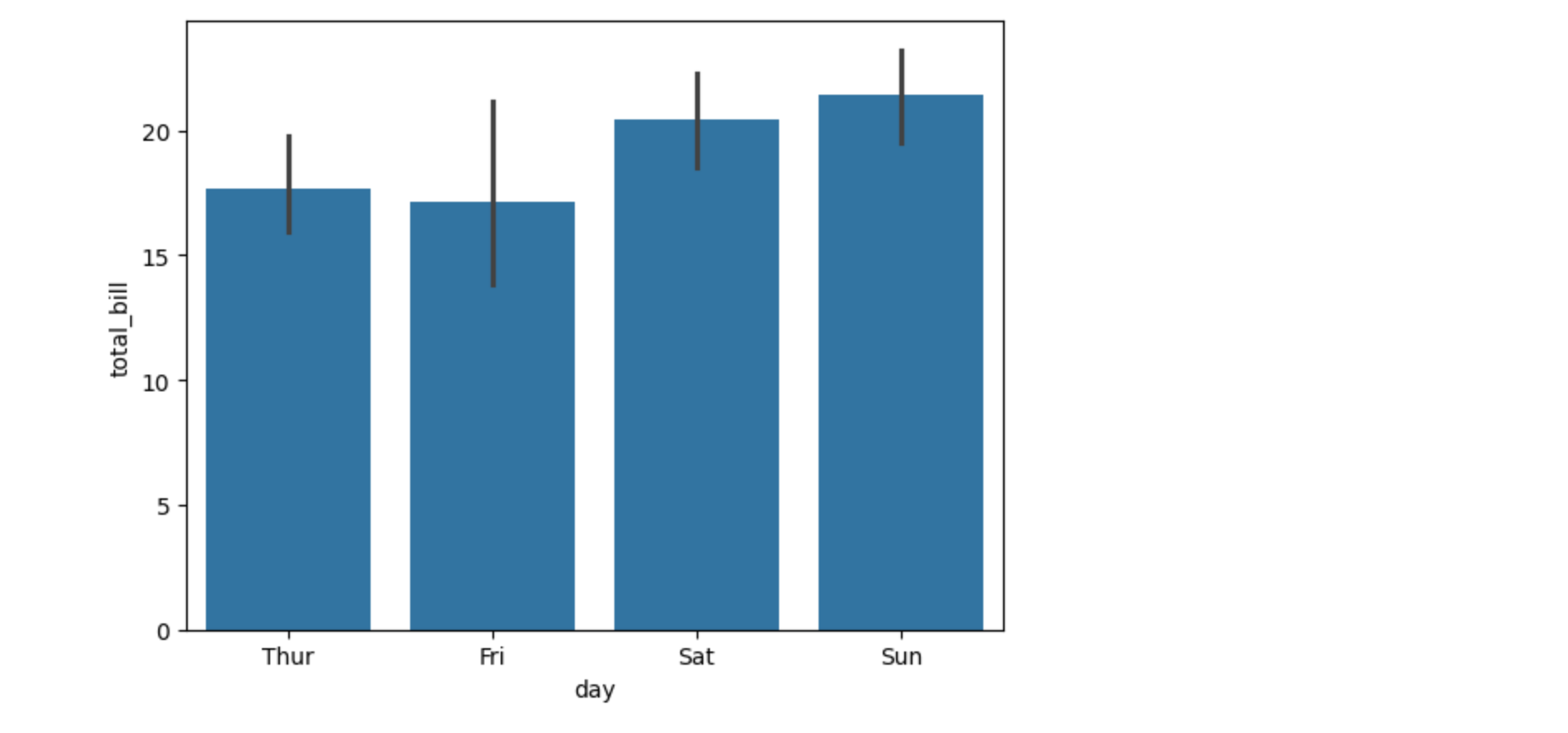
绘制柱状图(Bar Plot)
柱状图用于比较不同类别的数据。
sns.barplot(x="day", y="total_bill", data=tips)
plt.show()
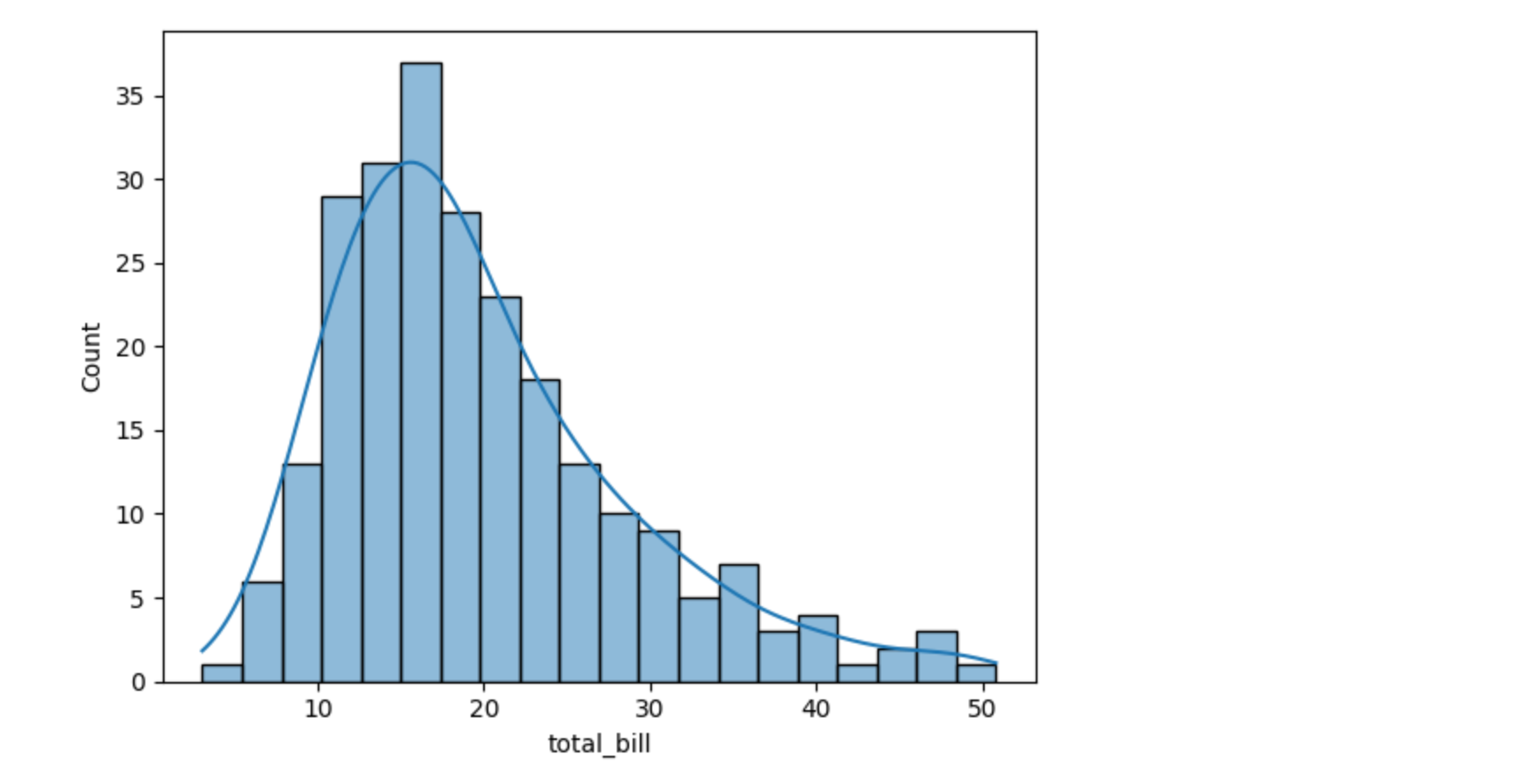
绘制直方图(Histogram)
直方图用于显示数据的分布。
sns.histplot(tips["total_bill"], bins=20, kde=True)
plt.show()
Seaborn进阶使用
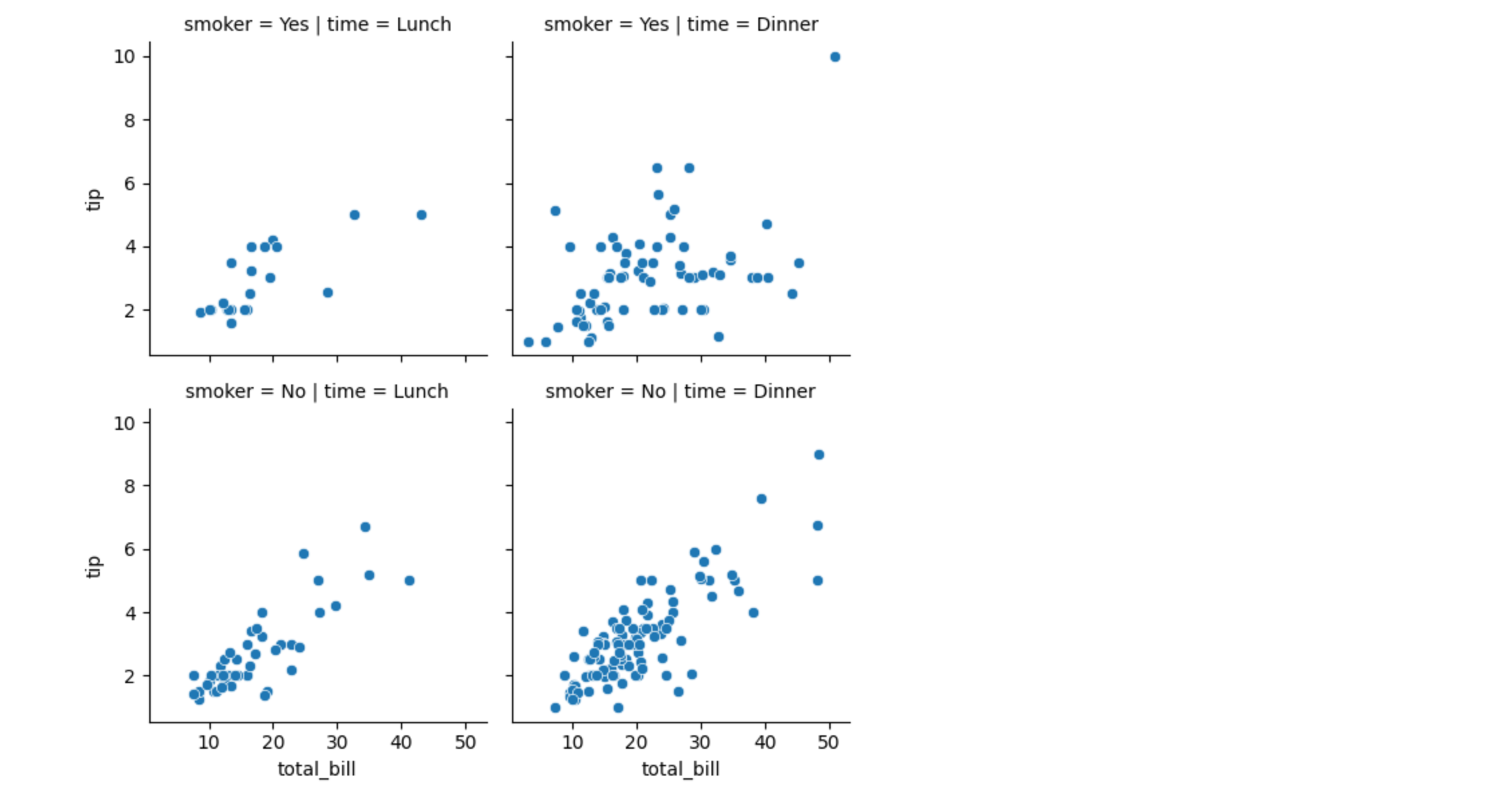
多图绘制(FacetGrid)
用于在同一画布上绘制多个子图。
g = sns.FacetGrid(tips, col="time", row="smoker")
g.map(sns.scatterplot, "total_bill", "tip")
plt.show()
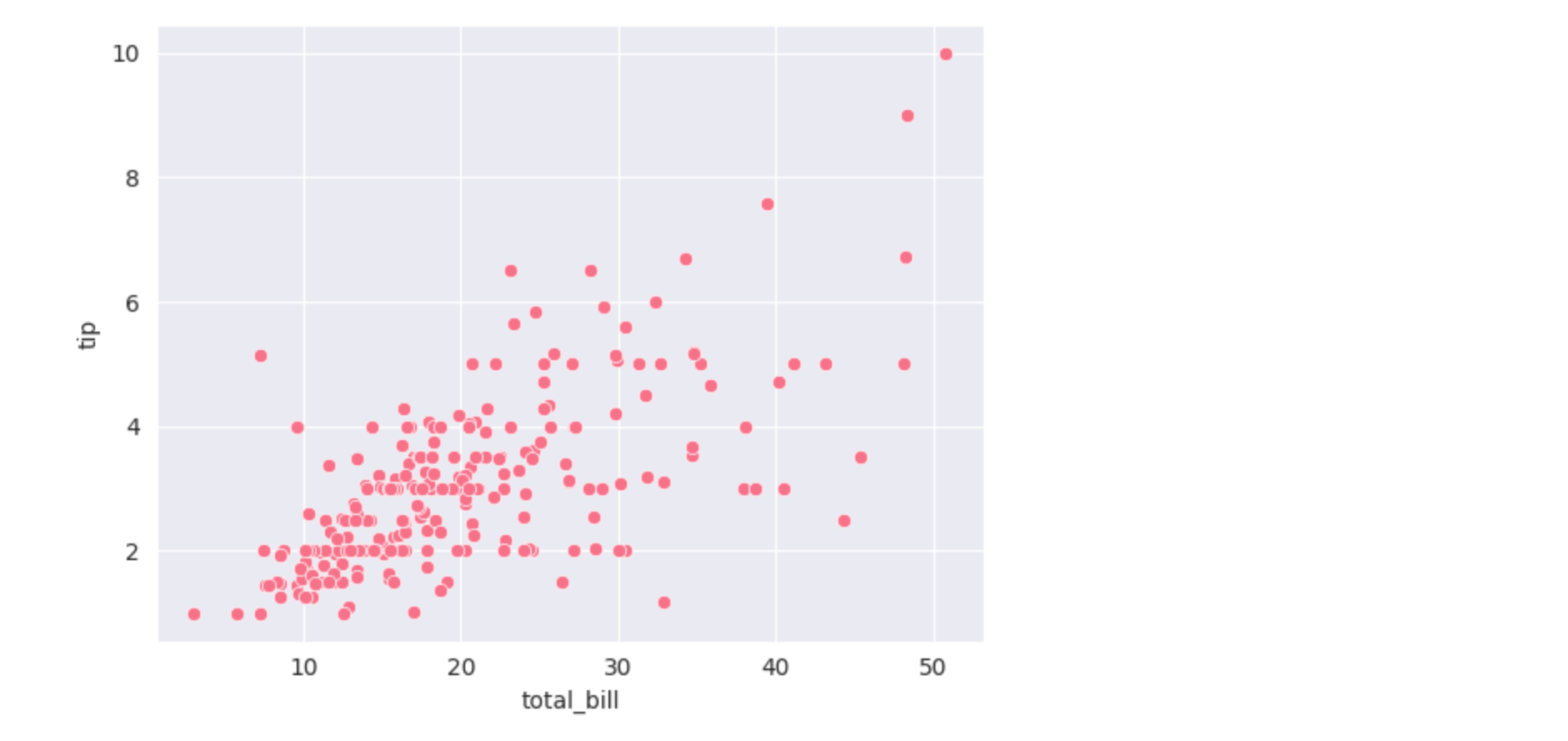
样式设置
Seaborn 提供了多种内置主题和颜色方案。
sns.set_style("darkgrid") # 设置样式
sns.set_palette("husl") # 设置颜色
sns.scatterplot(x="total_bill", y="tip", data=tips)
plt.show()
回归图(Regression Plot)
回归图在散点图的基础上添加了一条回归线,用于显示变量之间的线性关系。
# 设置画布大小
plt.figure(figsize=(8, 6))# 绘制回归图
sns.regplot(x="total_bill", y="tip", data=tips, scatter_kws={"s": 50}, line_kws={"color": "red"})# 添加标题和标签
plt.title("Regression Plot: Total Bill vs Tip", fontsize=14)
plt.xlabel("Total Bill ($)", fontsize=12)
plt.ylabel("Tip ($)", fontsize=12)# 显示图表
plt.show()
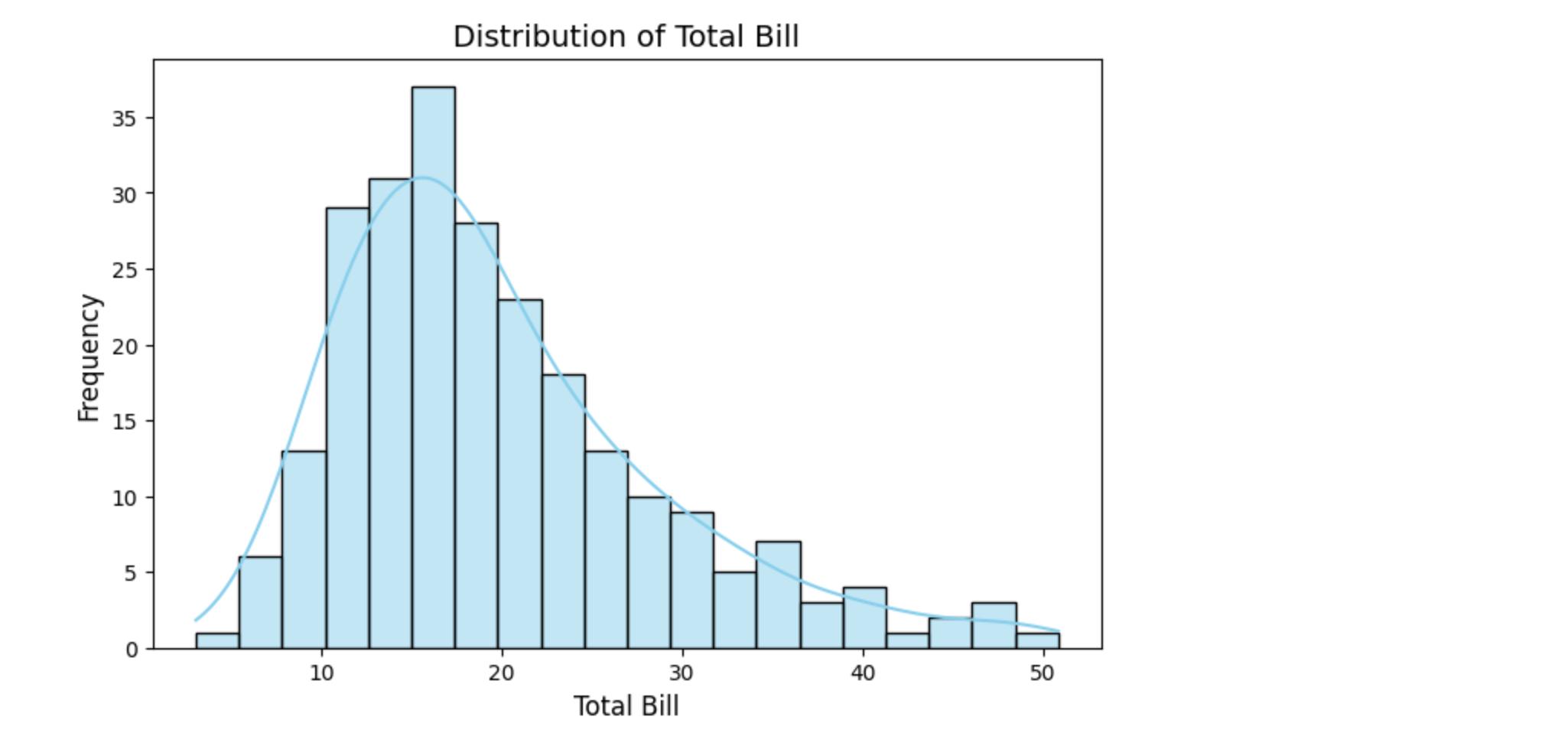
直方图(Histogram)
直方图是显示数据分布的最常用方法之一。它将数据分成若干区间(bin),并统计每个区间内的数据数量。
import seaborn as sns
import matplotlib.pyplot as plt# 加载示例数据集
tips = sns.load_dataset("tips")# 设置画布大小
plt.figure(figsize=(8, 5))# 绘制直方图
# color="orange":设置曲线的颜色
# kde=True:添加核密度估计曲线,显示数据分布的平滑趋势
# color="skyblue":设置直方图的颜色
sns.histplot(tips["total_bill"], bins=20, kde=True, color="skyblue")# 添加标题和标签
plt.title("Distribution of Total Bill", fontsize=14)
plt.xlabel("Total Bill", fontsize=12)
plt.ylabel("Frequency", fontsize=12)# 显示图表
plt.show()
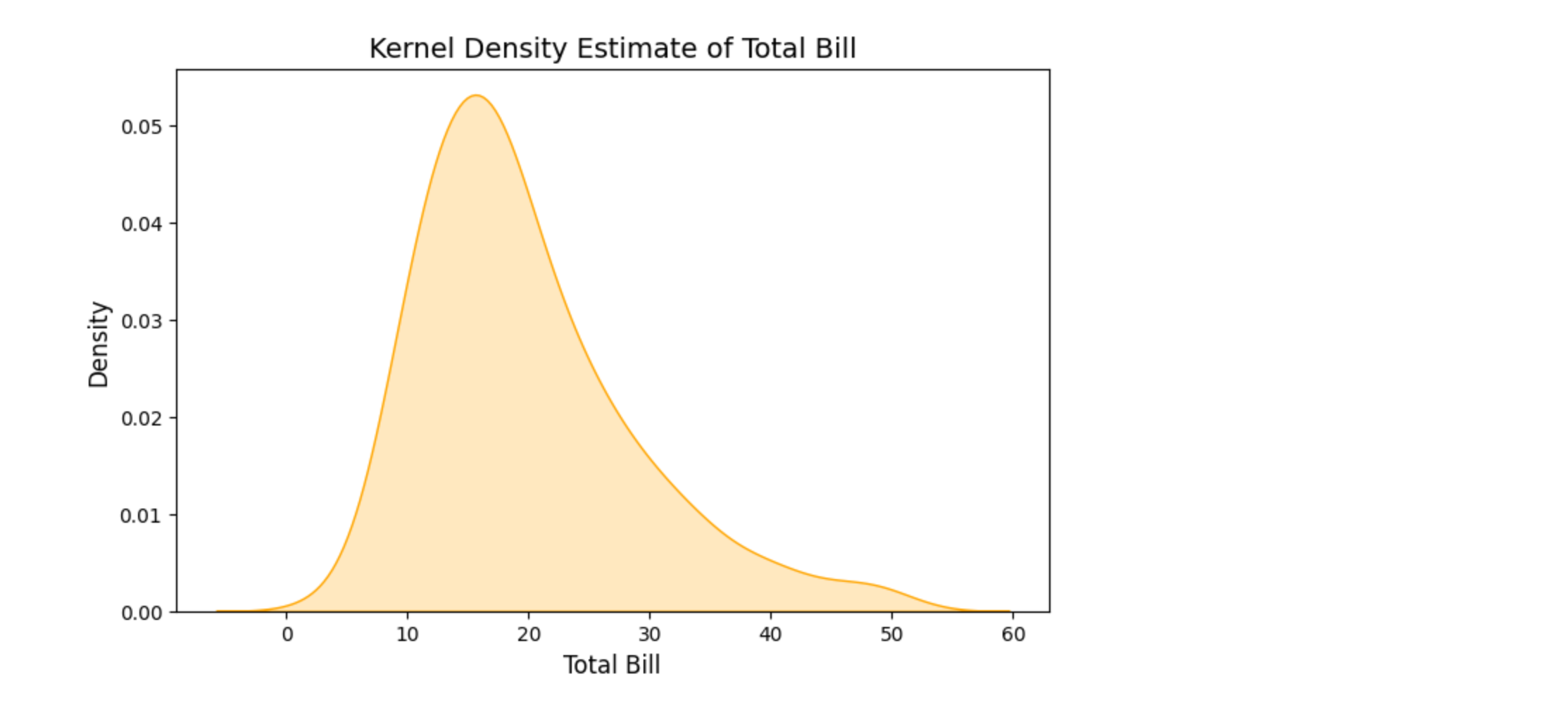
核密度估计图(Kernel Density Estimate, KDE)
KDE 是一种非参数方法,用于估计数据的概率密度函数。它比直方图更平滑,适合显示数据的整体分布。
# 设置画布大小
plt.figure(figsize=(8, 5))# 绘制 KDE 图
# shade=True:填充曲线下方的区域
# color="orange":设置曲线的颜色
sns.kdeplot(tips["total_bill"], color="orange", shade=True)# 添加标题和标签
plt.title("Kernel Density Estimate of Total Bill", fontsize=14)
plt.xlabel("Total Bill", fontsize=12)
plt.ylabel("Density", fontsize=12)# 显示图表
plt.show()
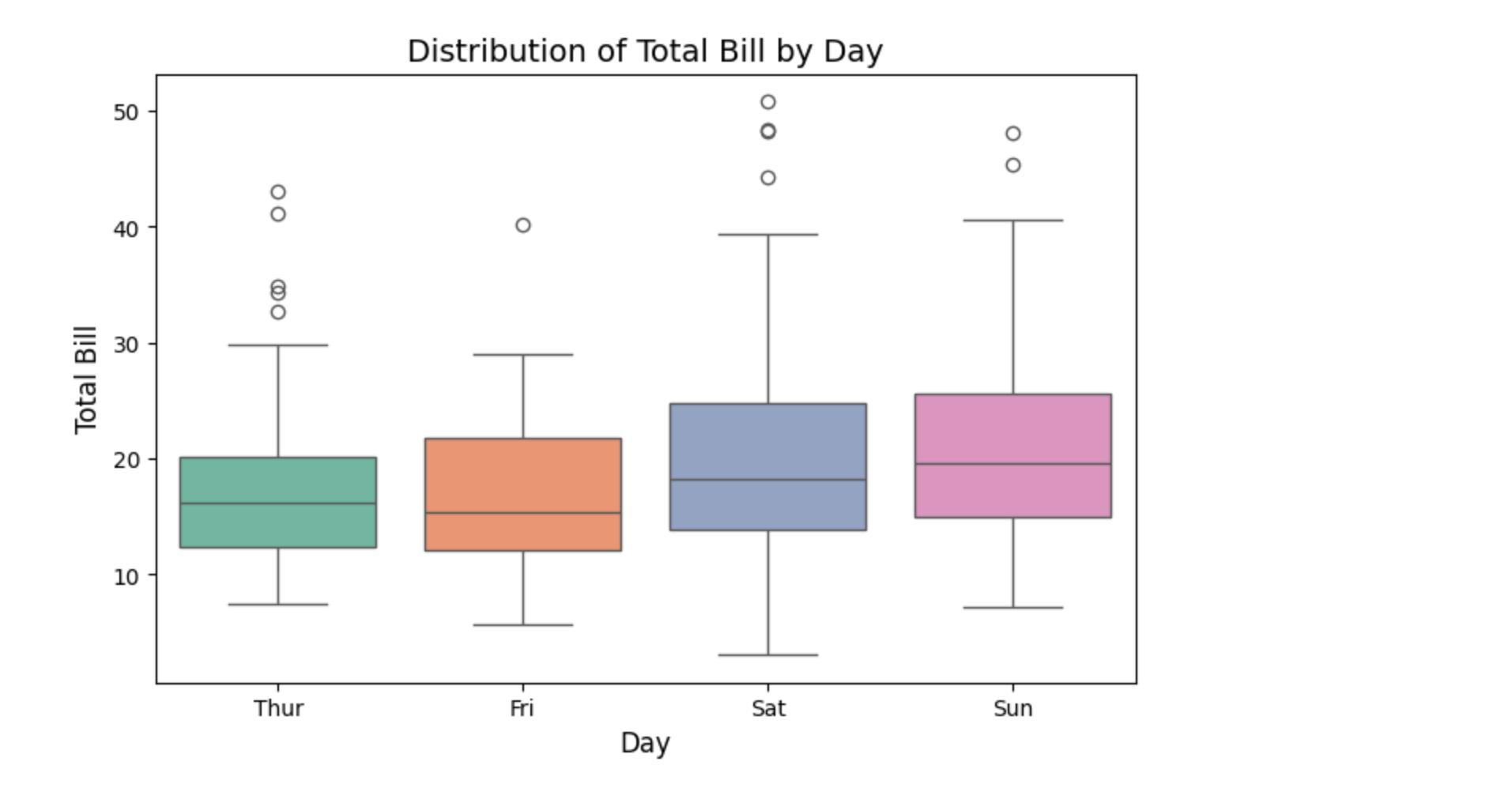
箱线图(Box Plot)
箱线图用于显示一个分类变量和一个连续变量之间的关系,适合比较不同类别的数据分布。
# 设置画布大小
plt.figure(figsize=(8, 5))# 绘制箱线图
# x="day":指定 x 轴为星期几
# y="total_bill":指定 y 轴为总账单金额
# palette="Set3":设置颜色方案
sns.boxplot(x="day", y="total_bill", data=tips, palette="Set2")# 添加标题和标签
plt.title("Distribution of Total Bill by Day", fontsize=14)
plt.xlabel("Day", fontsize=12)
plt.ylabel("Total Bill", fontsize=12)# 显示图表
plt.show()
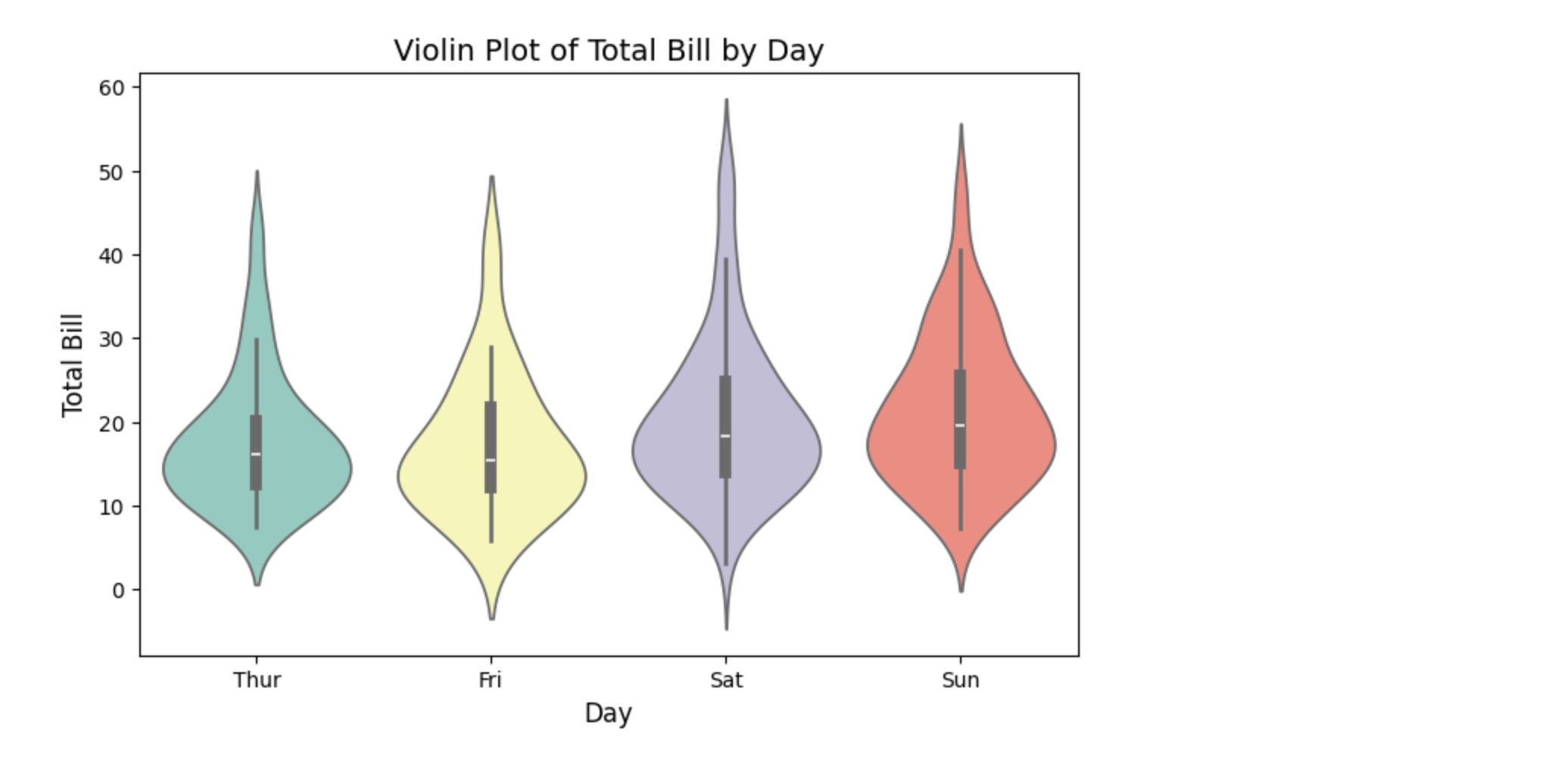
小提琴图(Violin Plot)
小提琴图结合了箱线图和核密度估计图的优点,能够更直观地显示数据的分布和密度。
# 设置画布大小
plt.figure(figsize=(8, 5))# 绘制小提琴图
# x="day":指定 x 轴为星期几
# y="total_bill":指定 y 轴为总账单金额
# palette="Set3":设置颜色方案
sns.violinplot(x="day", y="total_bill", data=tips, palette="Set3")# 添加标题和标签
plt.title("Violin Plot of Total Bill by Day", fontsize=14)
plt.xlabel("Day", fontsize=12)
plt.ylabel("Total Bill", fontsize=12)# 显示图表
plt.show()
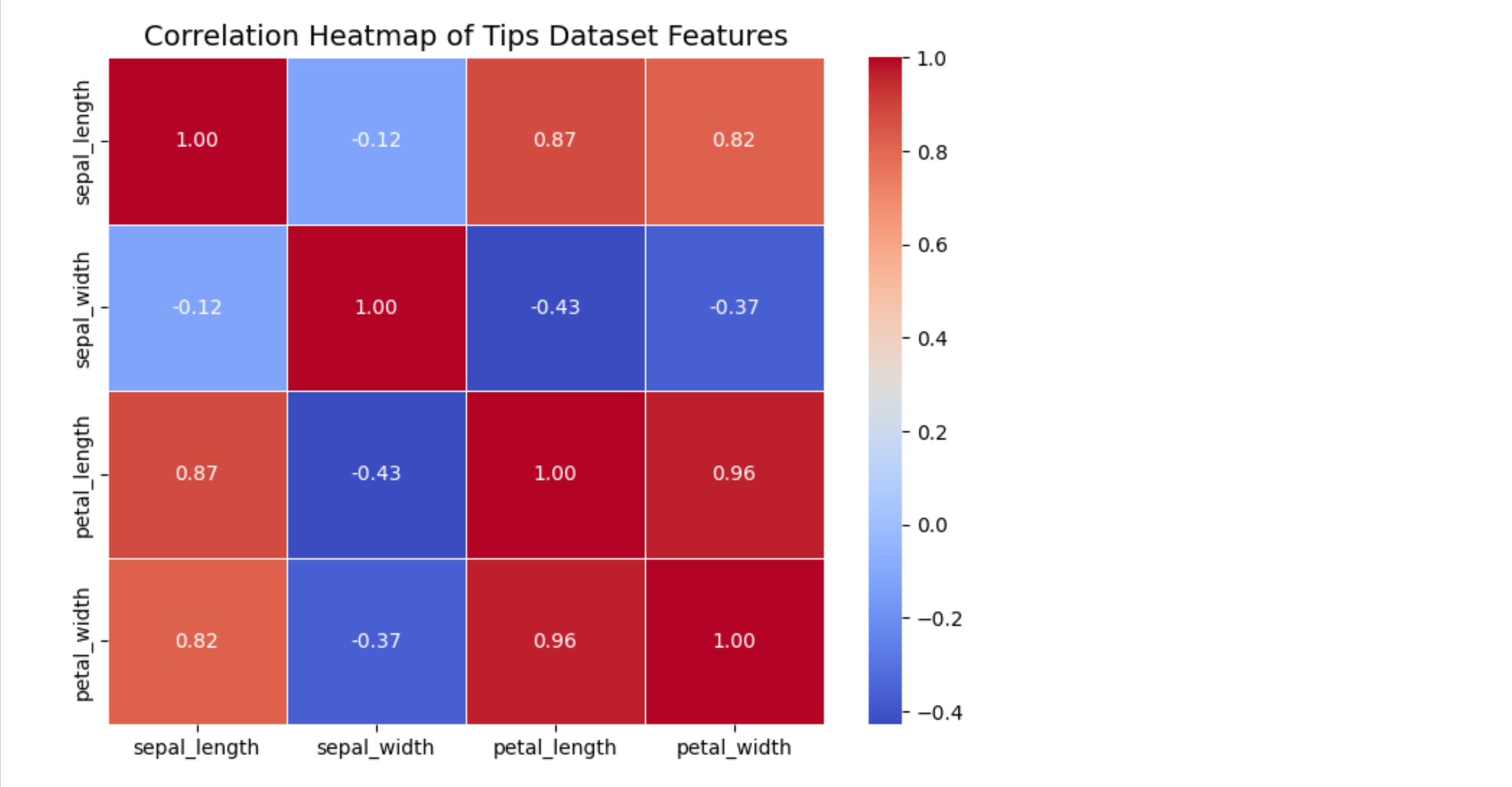
热力图(Heatmap)
热力图用于显示两个分类变量之间的关系,或者数值特征之间的相关性。
# 使用 drop() 方法删除非数值列 'species',因为相关性计算只能针对数值数据
correlation = iris.drop(columns=["species"])
# 使用 corr() 方法计算剩余数值特征之间的相关性矩阵
correlation = correlation.corr()# 设置画布大小
plt.figure(figsize=(8, 6))# 绘制热力图
sns.heatmap(correlation, annot=True, cmap="coolwarm", fmt=".2f", linewidths=0.5)# 添加标题
plt.title("Correlation Heatmap of Tips Dataset Features", fontsize=14)# 显示图表
plt.show()
计数图(Count Plot)
计数图用于显示分类变量的频数分布。
# 设置画布大小
plt.figure(figsize=(8, 6))# 绘制计数图
sns.countplot(x="class", data=titanic, palette="Set3")# 添加标题和标签
plt.title("Passenger Count by Class", fontsize=14)
plt.xlabel("Passenger Class", fontsize=12)
plt.ylabel("Count", fontsize=12)# 显示图表
plt.show()
联合分布图(Joint Plot)
联合分布图可以同时显示两个变量的散点图和各自的分布(直方图或 KDE 图)。
# 绘制联合分布图
# x="total_bill":指定 x 轴为总账单金额
# y="tip":指定 y 轴为小费金额
# kind="scatter":指定图表类型为散点图(其他选项包括 "kde" 和 "hex")
# height=6:设置图表的高度
sns.jointplot(x="total_bill", y="tip", data=tips, kind="scatter", height=6)# 显示图表
plt.show()
多变量分布图(Pair Plot)
Pair Plot 可以显示数据集中多个变量之间的分布和关系,适合用于探索性数据分析。
# 绘制多变量分布图
# hue="sex":按性别分组,用不同颜色表示
# palette="Set1":设置颜色方案
sns.pairplot(tips, hue="sex", palette="Set1")# 显示图表
plt.show()
分析泰坦尼克号数据集(titanic)
环境准备
# 导入必要的库
import seaborn as sns
import matplotlib.pyplot as plt# 加载泰坦尼克号数据集
titanic = sns.load_dataset("titanic")
print(titanic.head()) # 查看数据集的前几行,了解数据结构
数据说明
titanic是Seaborn 提供的另一个经典示例数据集,记录了泰坦尼克号上乘客的信息,包括他们的生存状态、年龄、性别、舱位等级等。
survived pclass sex age sibsp parch fare embarked class \
0 0 3 male 22.0 1 0 7.2500 S Third
1 1 1 female 38.0 1 0 71.2833 C First
2 1 3 female 26.0 0 0 7.9250 S Third
3 1 1 female 35.0 1 0 53.1000 S First
4 0 3 male 35.0 0 0 8.0500 S Third who adult_male deck embark_town alive alone
0 man True NaN Southampton no False
1 woman False C Cherbourg yes False
2 woman False NaN Southampton yes True
3 woman False C Southampton yes False
4 man True NaN Southampton no True
数据列说明
| 列名 | 类型 | 说明 |
|---|---|---|
survived | 数值型(int) | 是否生存,取值为 0(未生存)或 1(生存)。 |
pclass | 数值型(int) | 舱位等级,取值为 1(头等舱)、2(二等舱)或 3(三等舱)。 |
sex | 分类变量(字符串) | 乘客性别,取值为 male(男性)或 female(女性)。 |
age | 数值型(float) | 乘客年龄(岁)。 |
sibsp | 数值型(int) | 乘客在船上的兄弟姐妹或配偶的数量。 |
parch | 数值型(int) | 乘客在船上的父母或子女的数量。 |
fare | 数值型(float) | 乘客票价(英镑)。 |
embarked | 分类变量(字符串) | 乘客登船港口,取值为 C(Cherbourg)、Q(Queenstown)、S(Southampton)。 |
class | 分类变量(字符串) | 舱位等级(与 pclass 相同,但为字符串形式),取值为 First、Second、Third。 |
who | 分类变量(字符串) | 乘客类别,取值为 man(男性成人)、woman(女性成人)、child(儿童)。 |
adult_male | 布尔型(bool) | 是否为成年男性,取值为 True 或 False。 |
deck | 分类变量(字符串) | 乘客所在甲板(A-G),部分数据缺失。 |
embark_town | 分类变量(字符串) | 乘客登船港口(与 embarked 相同,但为完整名称)。 |
alive | 分类变量(字符串) | 是否生存(与 survived 相同,但为字符串形式),取值为 no 或 yes。 |
alone | 布尔型(bool) | 乘客是否独自一人,取值为 True 或 False。 |
乘客生存率的柱状图
绘制一个柱状图,显示乘客的生存率(Survived)分布
# 设置画布大小
plt.figure(figsize=(6, 4))# 绘制柱状图
sns.countplot(x="survived", data=titanic, palette="Set2")# 添加标题和标签
plt.title("Passenger Survival Count (0 = No, 1 = Yes)", fontsize=14)
plt.xlabel("Survived", fontsize=12)
plt.ylabel("Count", fontsize=12)# 显示图表
plt.show()
代码说明:
sns.countplot:用于绘制分类变量的计数柱状图。x="survived":指定 x 轴为生存状态(0 表示未生存,1 表示生存)。palette="Set2":设置颜色方案。plt.title、plt.xlabel、plt.ylabel:添加标题和轴标签
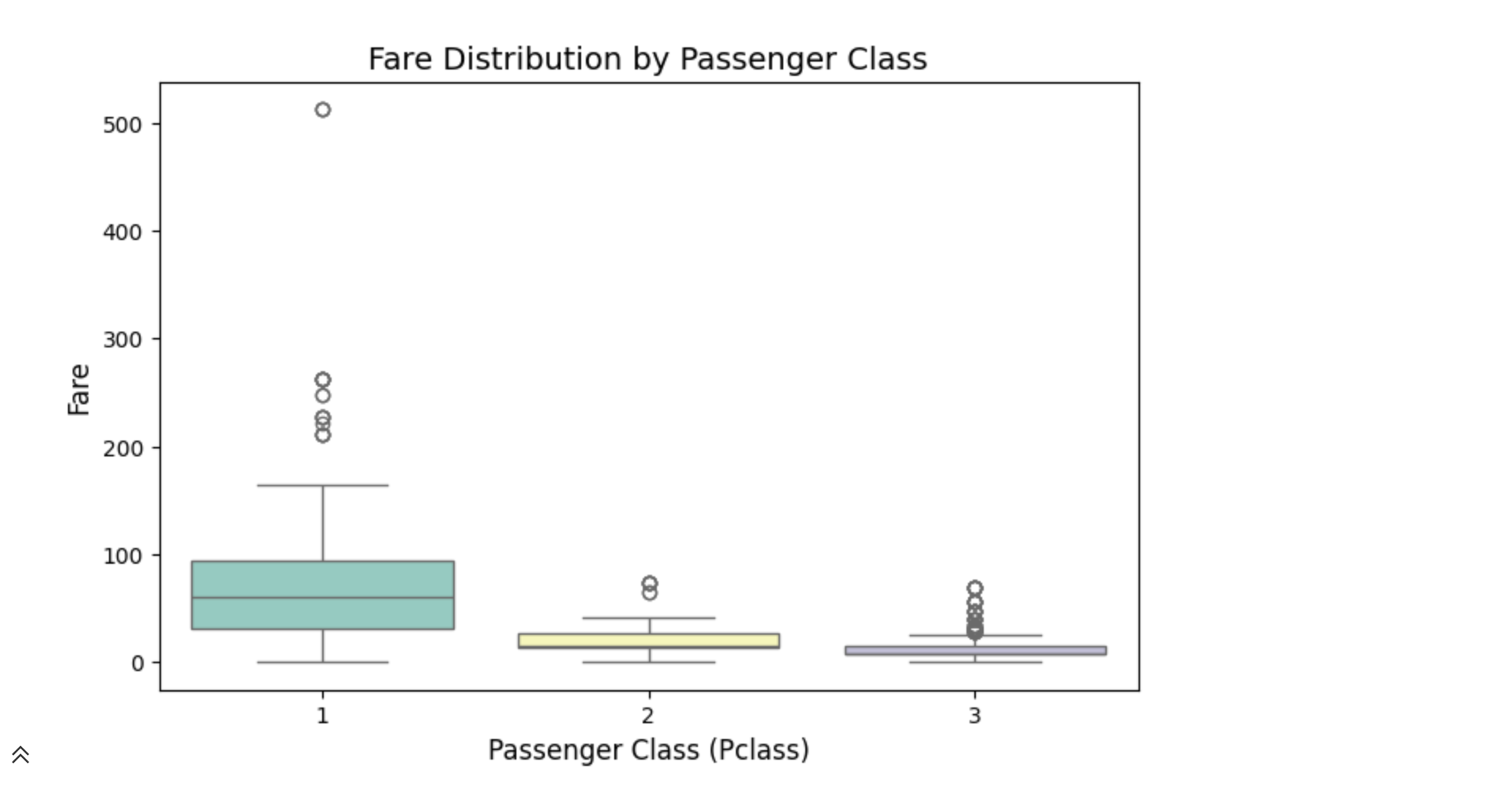
不同舱位的票价分布
绘制一个箱线图,显示不同舱位(Pclass)的票价(Fare)分布
# 设置画布大小
plt.figure(figsize=(8, 5))# 绘制箱线图
sns.boxplot(x="pclass", y="fare", data=titanic, palette="Set3")# 添加标题和标签
plt.title("Fare Distribution by Passenger Class", fontsize=14)
plt.xlabel("Passenger Class (Pclass)", fontsize=12)
plt.ylabel("Fare", fontsize=12)# 显示图表
plt.show()
代码说明:
sns.boxplot:用于绘制箱线图,显示数据的分布和离群值。x="pclass":指定 x 轴为乘客舱位(1 = 头等舱,2 = 二等舱,3 = 三等舱)。y="fare":指定 y 轴为票价。palette="Set3":设置颜色方案。
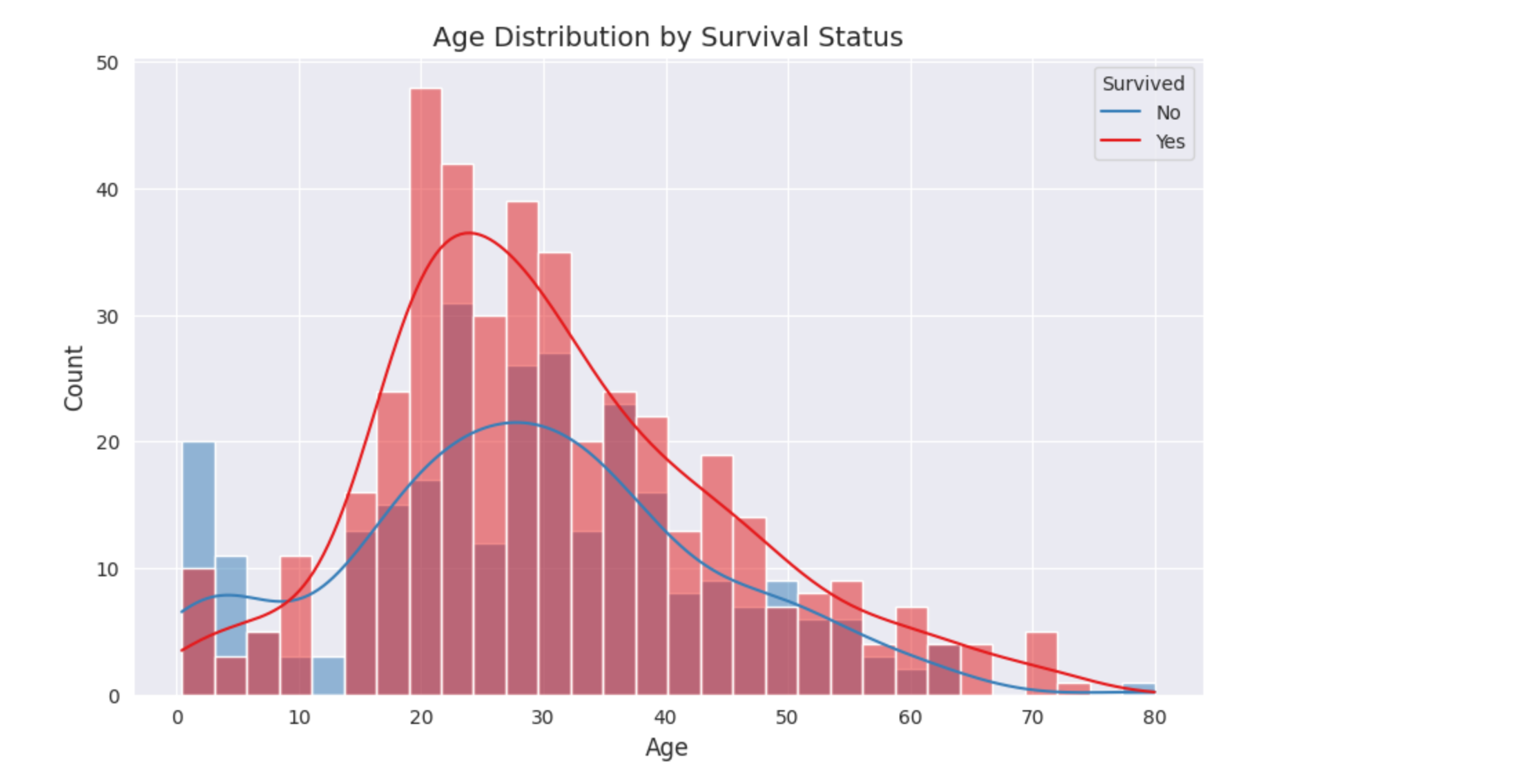
年龄与生存率的关系
绘制一个直方图,显示不同年龄段的乘客生存率。
# 设置画布大小
plt.figure(figsize=(10, 6))# 绘制直方图,按生存状态分组
sns.histplot(data=titanic, x="age", hue="survived", bins=30, kde=True, palette="Set1")# 添加标题和标签
plt.title("Age Distribution by Survival Status", fontsize=14)
plt.xlabel("Age", fontsize=12)
plt.ylabel("Count", fontsize=12)# 显示图例
plt.legend(title="Survived", labels=["No", "Yes"])# 显示图表
plt.show()
代码说明:
sns.histplot:用于绘制直方图,显示数据的分布。x="age":指定 x 轴为年龄。hue="survived":按生存状态分组,用不同颜色表示。bins=30:设置直方图的柱子数量。kde=True:添加核密度估计曲线,显示数据分布的平滑趋势。palette="Set1":设置颜色方案。plt.legend:添加图例,说明颜色对应的生存状态。
分析鸢尾花数据集(iris)
环境准备
# 导入必要的库
import seaborn as sns
import matplotlib.pyplot as plt# 加载鸢尾花数据集
iris = sns.load_dataset("iris")
print(iris.head()) # 查看数据集的前几行,了解数据结构
数据说明
iris数据集(鸢尾花数据集)是机器学习和数据科学领域中最经典的数据集之一。
sepal_length sepal_width petal_length petal_width species
0 5.1 3.5 1.4 0.2 setosa
1 4.9 3.0 1.4 0.2 setosa
2 4.7 3.2 1.3 0.2 setosa
3 4.6 3.1 1.5 0.2 setosa
4 5.0 3.6 1.4 0.2 setosa
数据列说明
| 列名 | 类型 | 说明 |
|---|---|---|
sepal_length | 数值型(float) | 花萼长度(厘米)。 |
sepal_width | 数值型(float) | 花萼宽度(厘米)。 |
petal_length | 数值型(float) | 花瓣长度(厘米)。 |
petal_width | 数值型(float) | 花瓣宽度(厘米)。 |
species | 分类变量(字符串) | 鸢尾花种类,取值为 setosa、versicolor 或 virginica。 |
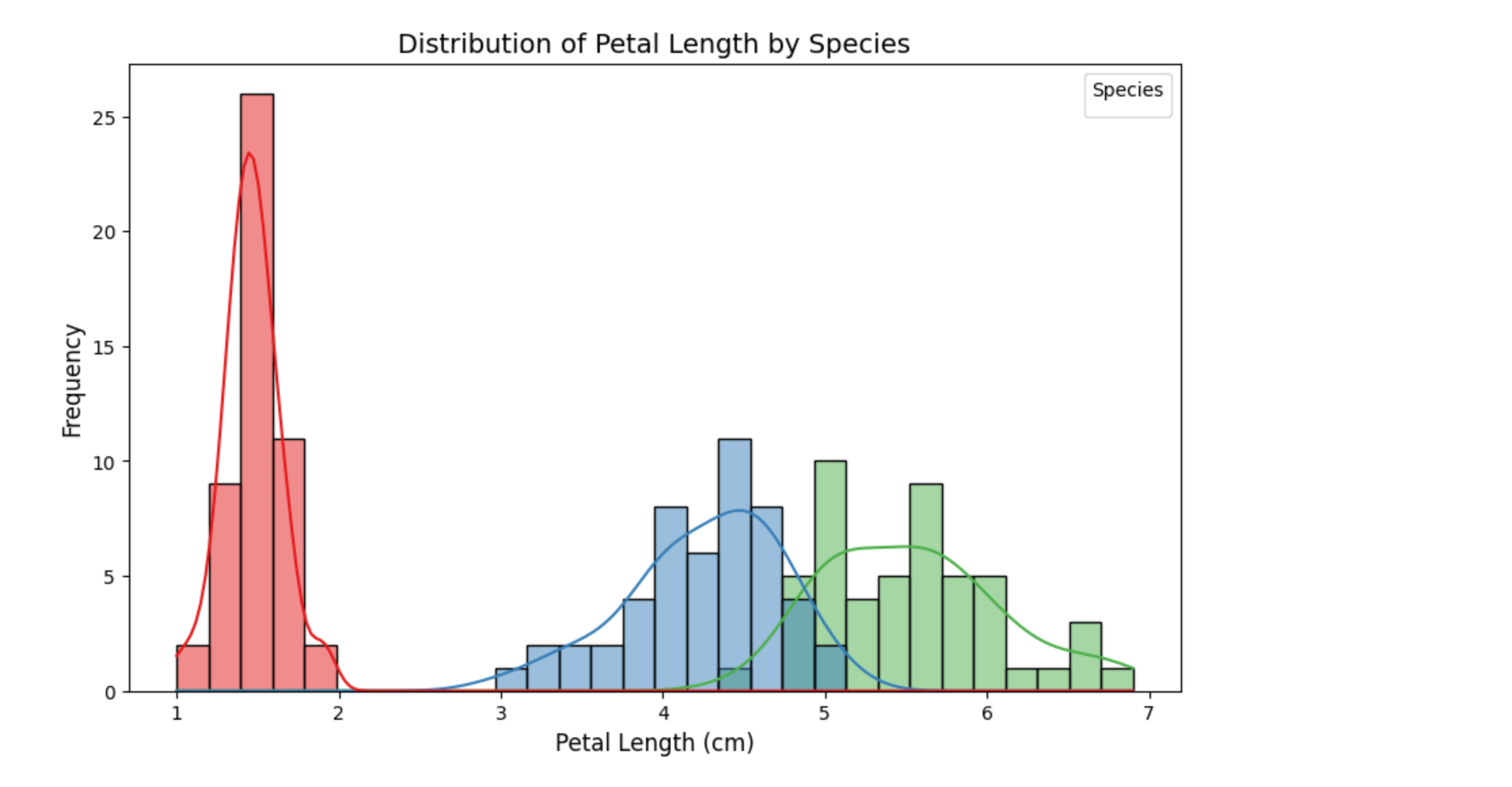
不同种类的花瓣长度分布
绘制一个直方图,显示不同种类(species)的鸢尾花的花瓣长度(petal_length)分布
# 设置画布大小
plt.figure(figsize=(10, 6))# 绘制直方图,按种类分组
sns.histplot(data=iris, x="petal_length", hue="species", bins=30, kde=True, palette="Set1")# 添加标题和标签
plt.title("Distribution of Petal Length by Species", fontsize=14)
plt.xlabel("Petal Length (cm)", fontsize=12)
plt.ylabel("Frequency", fontsize=12)# 显示图例
plt.legend(title="Species")# 显示图表
plt.show()
代码说明:
sns.histplot:绘制直方图。x="petal_length":指定 x 轴为花瓣长度。hue="species":按种类分组,用不同颜色表示。bins=30:将数据分成 30 个区间。kde=True:添加核密度估计曲线,显示数据分布的平滑趋势。palette="Set1":设置颜色方案。plt.legend:添加图例,说明颜色对应的种类。
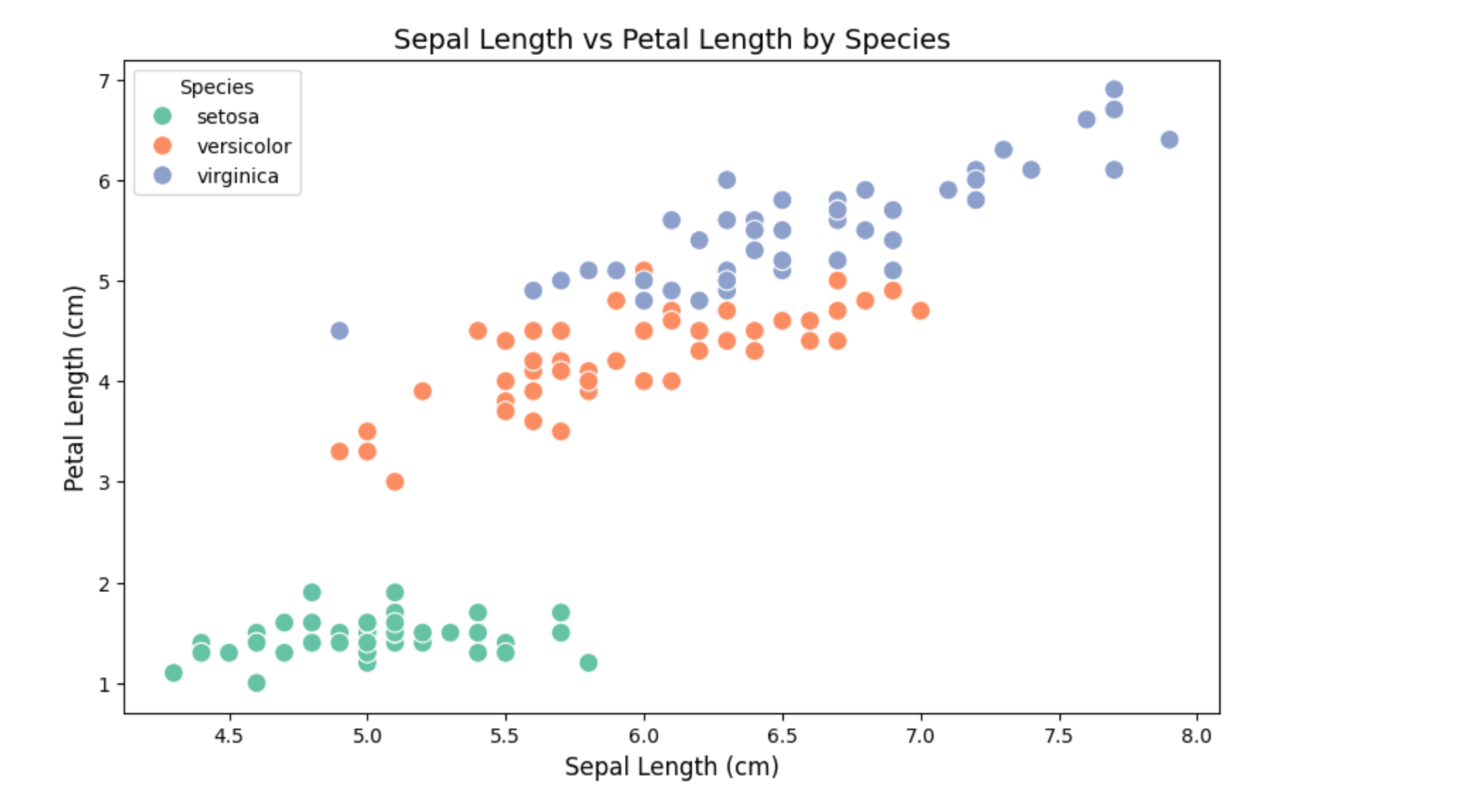
花萼长度与花瓣长度的关系
绘制一个散点图,显示花萼长度(sepal_length)与花瓣长度(petal_length)的关系,并按种类分组。
# 设置画布大小
plt.figure(figsize=(10, 6))# 绘制散点图,按种类分组
sns.scatterplot(x="sepal_length", y="petal_length", hue="species", data=iris, palette="Set2", s=100)# 添加标题和标签
plt.title("Sepal Length vs Petal Length by Species", fontsize=14)
plt.xlabel("Sepal Length (cm)", fontsize=12)
plt.ylabel("Petal Length (cm)", fontsize=12)# 显示图例
plt.legend(title="Species")# 显示图表
plt.show()
代码说明:
sns.scatterplot:绘制散点图。x="sepal_length":指定 x 轴为花萼长度。y="petal_length":指定 y 轴为花瓣长度。hue="species":按种类分组,用不同颜色表示。palette="Set2":设置颜色方案。s=100:设置散点的大小。plt.legend:添加图例,说明颜色对应的种类。
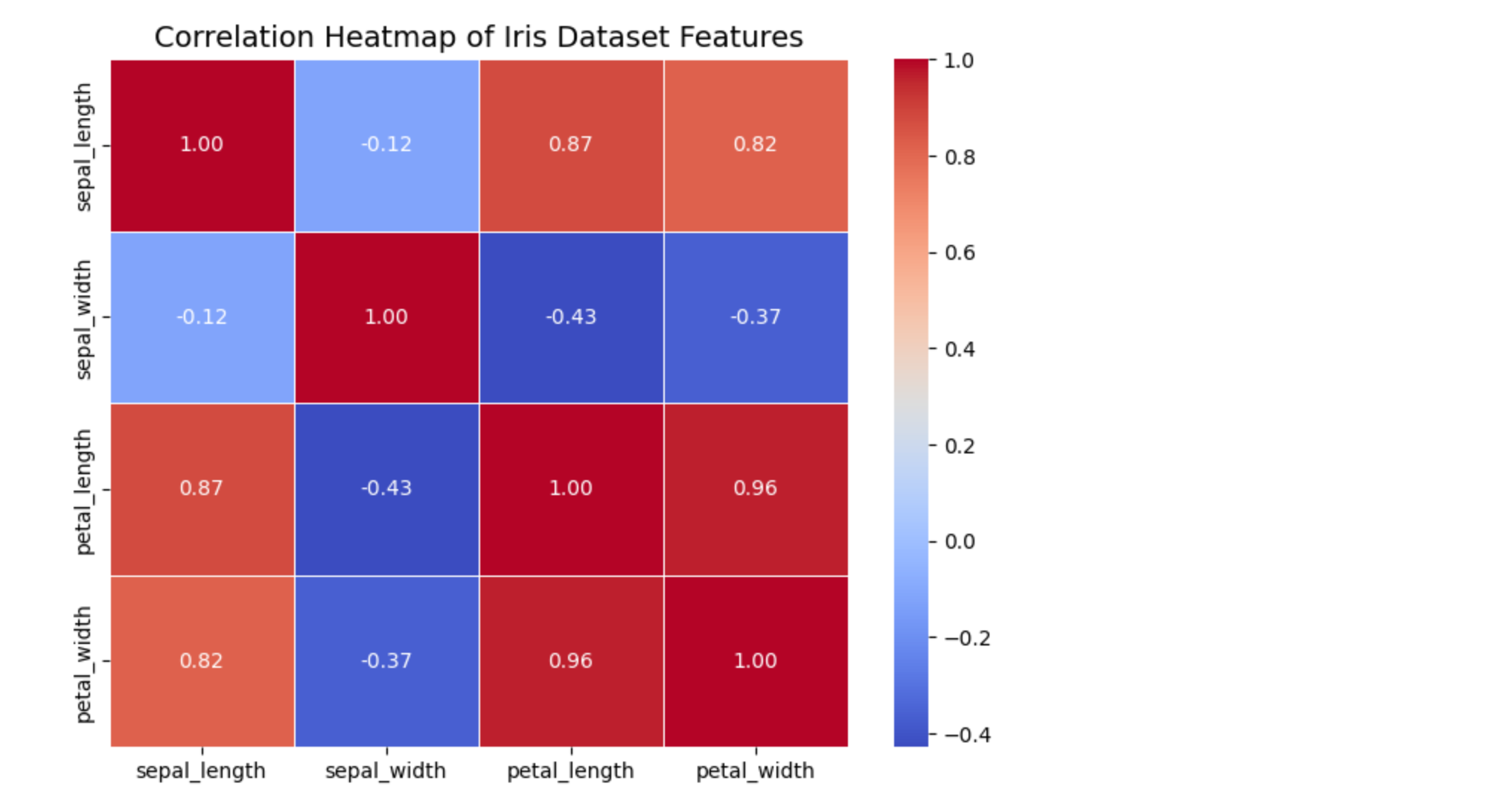
数据集中特征的相关性
绘制一个热力图,显示数据集中各个特征(如花萼长度、花瓣长度等)之间的相关性。
# 使用 drop() 方法删除非数值列 'species',因为相关性计算只能针对数值数据
correlation = iris.drop(columns=["species"])
# 使用 corr() 方法计算剩余数值特征之间的相关性矩阵
correlation = correlation.corr()# 设置画布大小
plt.figure(figsize=(8, 6))# 绘制热力图
# 1. correlation:传入相关性矩阵作为热力图的数据
# 2. annot=True:在热力图的每个单元格中显示具体的数值
# 3. cmap="coolwarm":设置颜色映射为从冷色(蓝色)到暖色(红色)的渐变色
# 4. fmt=".2f":设置数值的显示格式为两位小数
# 5. linewidths=0.5:设置热力图中单元格之间的线条宽度为 0.5
sns.heatmap(correlation, annot=True, cmap="coolwarm", fmt=".2f", linewidths=0.5)# 添加标题
plt.title("Correlation Heatmap of Iris Dataset Features", fontsize=14)# 显示图表
plt.show()
代码说明:
iris.drop(columns=["species"]):排除非数值列 species,只保留数值特征。corr():计算数值特征的相关性矩阵。sns.heatmap:绘制热力图。annot=True:在热力图中显示数值。cmap="coolwarm":设置颜色映射。fmt=".2f":设置数值的显示格式为两位小数。linewidths=0.5:设置热力图中单元格之间的线条宽度。