大模型的分词器——算法及示例
文章目录
- 1. 分词的概述
- 1.1 什么是分词?
- 1.2 分词的重要性
- 1.3 分词方法的演变
- 1.4 分词器的选择
- 2. Byte-Pair Encoding (BPE)
- 2.1 BPE的概述
- 2.2 BPE的工作原理
- 示例:BPE训练
- 示例:BPE分词
- 伪代码:BPE训练
- 2.3 BPE的优缺点
- 2.4 BPE在模型中的应用
- 3. WordPiece
- 3.1 WordPiece的概述
- 3.2 WordPiece的工作原理
- 示例:WordPiece训练
- 示例:WordPiece分词
- 伪代码:WordPiece训练
- 3.3 WordPiece的优缺点
- 3.4 WordPiece在模型中的应用
- 4. Unigram
- 4.1 Unigram的概述
- 4.2 Unigram的工作原理
- 示例:Unigram训练
- 示例:Unigram分词
- 伪代码:Unigram分词
- 4.3 Unigram的优缺点
- 4.4 Unigram在模型中的应用
- 5. SentencePiece
- 5.1 SentencePiece的概述
- 5.2 SentencePiece的工作原理
- 示例:SentencePiece使用
- 伪代码:SentencePiece训练
- 5.3 SentencePiece的优缺点
- 5.4 SentencePiece在模型中的应用
- 6. Byte-level BPE (BBPE)
- 6.1 BBPE的概述
- 6.2 BBPE的工作原理
- 示例:BBPE分词
- 伪代码:BBPE训练
- 6.3 BBPE的优缺点
- 6.4 BBPE在模型中的应用
- 7. 分词器比较
- 8. 实际应用中的考虑
1. 分词的概述
1.1 什么是分词?
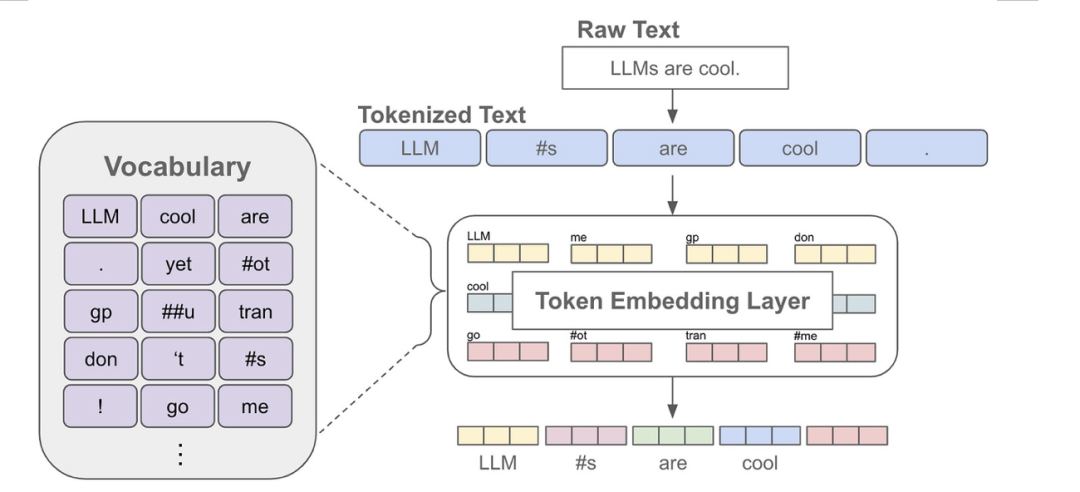
分词(Tokenization)是自然语言处理(NLP)中的基础步骤,将连续的文本分割成离散的单元(tokens),如单词、子词或字符。这些tokens是大型语言模型(LLMs)的输入,模型通过学习tokens之间的关系来理解和生成语言。例如,句子“Hello world”可以被分词为["Hello", "world"](词级分词)或["H", "e", "l", "l", "o", " ", "w", "o", "r", "l", "d"](字符级分词)。
1.2 分词的重要性
分词直接影响LLMs的性能和效率,主要体现在以下几个方面:
- 词汇表大小:词级分词可能导致词汇表过大(例如,英语可能有数十万单词),增加模型的参数量和计算成本。子词分词通过将单词拆分为更小的单元(如“playing”拆为“play”和“##ing”),可以显著减少词汇表大小。
- 未知词汇(OOV):词级分词无法处理训练数据中未出现的词汇,而子词分词可以通过组合已知子词表示新词。例如,“unseen”可以拆为“un”和“seen”。
- 序列长度:字符级分词会导致序列过长,增加计算负担。子词分词在词汇表大小和序列长度之间找到平衡。
- 语言适应性:多语言模型需要处理不同语言的文本,子词分词(如BBPE)可以适应多种语言的字符集。
1.3 分词方法的演变
早期的分词方法包括:
- 词级分词:按空格或标点分割,但词汇表过大,且无法处理OOV词汇。
- 字符级分词:将每个字符作为一个token,解决了OOV问题,但序列长度过长,计算效率低。
子词分词方法(如BPE、WordPiece、Unigram)通过将单词拆分为更小的有意义单元,解决了上述问题。这些方法在现代LLMs中广泛应用。
1.4 分词器的选择
选择分词器取决于任务需求:
- 单语言任务:BPE或WordPiece通常更高效。
- 多语言任务:BBPE或SentencePiece(结合Unigram)更适合。
- 处理未知词汇或噪声:Unigram的子词正则化可以提高模型鲁棒性。
2. Byte-Pair Encoding (BPE)
2.1 BPE的概述
Byte-Pair Encoding(BPE)最初用于数据压缩,后来被应用于NLP分词 Byte-Pair Encoding。它通过迭代合并最频繁的字符对或子词对来构建词汇表,广泛用于GPT、RoBERTa等模型。
2.2 BPE的工作原理
BPE的训练过程如下:
- 初始化词汇表:从训练数据中提取所有唯一字符。例如,对于语料库
["hug", "pug", "pun", "bun", "hugs"],初始词汇表为["h", "u", "g", "p", "n", "b", "s"]。 - 统计字符对频率:遍历语料库,计算连续字符对的频率。例如,在“hug”中,字符对为
("h", "u")和("u", "g")。 - 合并最频繁的字符对:选择频率最高的字符对,合并为新token。例如,如果
("u", "g")频率最高,创建“ug”。 - 更新词汇表:将新token加入词汇表,重新分词语料库,重复步骤2-3,直到达到目标词汇表大小。
示例:BPE训练
语料库:["hug" (10次), "pug" (5次), "pun" (12次), "bun" (4次), "hugs" (5次)]
-
步骤0:初始化
- 词汇表:
["h", "u", "g", "p", "n", "b", "s"] - 语料库分词:
- hug:
["h", "u", "g"] - pug:
["p", "u", "g"] - pun:
["p", "u", "n"] - bun:
["b", "u", "n"] - hugs:
["h", "u", "g", "s"]
- hug:
- 词汇表:
-
步骤1:统计频率
- 字符对:
("h", "u"):15次(hug x10, hugs x5)("u", "g"):20次(hug x10, pug x5, hugs x5)("p", "u"):17次(pug x5, pun x12)("u", "n"):16次(pun x12, bun x4)("b", "u"):4次(bun x4)("g", "s"):5次(hugs x5)
- 最高频率:
("u", "g")(20次) - 合并为“ug”,新词汇表:
["h", "u", "g", "p", "n", "b", "s", "ug"]
- 字符对:
-
步骤2:重新分词
- hug:
["h", "ug"] - pug:
["p", "ug"] - pun:
["p", "u", "n"] - bun:
["b", "u", "n"] - hugs:
["h", "ug", "s"] - 继续统计频率,合并下一个最高频率对,依此类推。
- hug:
示例:BPE分词
假设最终词汇表为:["h", "u", "g", "p", "n", "b", "s", "ug", "un", "hug"]
-
分词“hugs”:
- 从左到右匹配最长子词:
- “h”匹配
- “hu”不匹配
- “hug”匹配
- “s”匹配
- 结果:
["hug", "s"]
- 从左到右匹配最长子词:
-
分词“bugs”:
- “b”匹配
- “bu”不匹配
- “bug”不匹配
- “ugs”不匹配
- “ug”匹配
- “s”匹配
- 结果:
["b", "ug", "s"]
伪代码:BPE训练
from collections import defaultdictdef get_pair_frequencies(corpus, vocab):pairs = defaultdict(int)for word, freq in corpus.items():tokens = word.split() # 假设已分词为字符for i in range(len(tokens) - 1):pairs[(tokens[i], tokens[i + 1])] += freqreturn pairsdef merge_pair(corpus, pair, new_token):new_corpus = {}for word, freq in corpus.items():new_word = word.replace(f"{pair[0]} {pair[1]}", new_token)new_corpus[new_word] = freqreturn new_corpusdef train_bpe(corpus, vocab_size):vocab = set()for word in corpus:for char in word:vocab.add(char)while len(vocab) < vocab_size:pairs = get_pair_frequencies(corpus, vocab)if not pairs:breakbest_pair = max(pairs, key=pairs.get)new_token = best_pair[0] + best_pair[1]corpus = merge_pair(corpus, best_pair, new_token)vocab.add(new_token)return vocab
可视化建议:一个树形图,展示从字符(如“h”, “u”, “g”)到子词(如“ug”, “hug”)的合并过程。节点表示tokens,边表示合并操作,标注频率。
2.3 BPE的优缺点
- 优点:
- 高效词汇表:用较小的词汇表覆盖大量文本。
- 处理OOV:通过子词组合表示未知词汇。
- 语言无关:适用于任何语言。
- 缺点:
- 合并顺序敏感:不同顺序可能导致不同词汇表。
- 形态学限制:可能无法有效捕捉某些语言的词根或词缀。
2.4 BPE在模型中的应用
BPE广泛应用于:
- GPT系列 (OpenAI)
- RoBERTa (Hugging Face)
- BART
- DeBERTa
3. WordPiece
3.1 WordPiece的概述
WordPiece是Google为BERT模型开发的分词算法 WordPiece Tokenization。它与BPE类似,但使用互信息分数选择合并对,倾向于选择更有意义的子词。
3.2 WordPiece的工作原理
WordPiece的训练过程如下:
- 初始化词汇表:包含所有唯一字符,并为非首字符添加“##”前缀(如“hug”拆为
["h", "##u", "##g"])。 - 计算合并分数:对于每对连续token (A, B),计算:分数高的对表示A和B的关联性强。
- 合并最高分对:将分数最高的对合并为新token。
- 重复:直到达到目标词汇表大小。
示例:WordPiece训练
语料库:["hug" (10次), "pug" (5次), "pun" (12次), "bun" (4次), "hugs" (5次)]
-
步骤0:初始化
- 词汇表:
["h", "##u", "##g", "p", "##n", "b", "##s"] - 分词:
- hug:
["h", "##u", "##g"] - hugs:
["h", "##u", "##g", "##s"]
- hug:
- 词汇表:
-
步骤1:计算分数
- 频率:
- freq(“h”) = 15, freq(“##u”) = 36, freq(“##g”) = 20, freq(“##s”) = 5
- freq(“h”, “##u”) = 15, freq(“##u”, “##g”) = 20, freq(“##g”, “##s”) = 5
- 分数:
- score(“h”, “##u”) = 15 / (15 * 36) ≈ 0.0278
- score(“##u”, “##g”) = 20 / (36 * 20) ≈ 0.0278
- score(“##g”, “##s”) = 5 / (20 * 5) = 0.05
- 合并
("##g", "##s")为“##gs”,新词汇表:["h", "##u", "##g", "p", "##n", "b", "##s", "##gs"]
- 频率:
示例:WordPiece分词
假设词汇表为:["h", "##u", "##g", "p", "##n", "b", "##s", "##gs", "hug"]
- 分词“hugs”:
- 匹配“hug” →
["hug", "##s"]
- 匹配“hug” →
- 分词“bugs”:
- 匹配“b” →
["b", "##u", "##g", "##s"]
- 匹配“b” →
伪代码:WordPiece训练
def get_pair_scores(corpus, vocab):pair_freq = defaultdict(int)token_freq = defaultdict(int)for word, freq in corpus.items():tokens = word.split()for token in tokens:token_freq[token] += freqfor i in range(len(tokens) - 1):pair_freq[(tokens[i], tokens[i + 1])] += freqscores = {}for pair in pair_freq:scores[pair] = pair_freq[pair] / (token_freq[pair[0]] * token_freq[pair[1]])return scoresdef train_wordpiece(corpus, vocab_size):vocab = set()for word in corpus:for char in word:vocab.add(char if word.index(char) == 0 else "##" + char)while len(vocab) < vocab_size:scores = get_pair_scores(corpus, vocab)if not scores:breakbest_pair = max(scores, key=scores.get)new_token = best_pair[0] + best_pair[1].lstrip("##")corpus = merge_pair(corpus, best_pair, new_token)vocab.add(new_token)return vocab
可视化建议:树形图,展示合并过程,节点标注分数(如0.05 for “##g”, “##s”)。
3.3 WordPiece的优缺点
- 优点:
- 更有意义的子词:互信息分数优先合并关联性强的子词。
- BERT标准:广泛用于BERT及其变体。
- 缺点:
- 复杂性:分数计算比BPE复杂。
- 非完全开源:Google未公开完整训练算法。
3.4 WordPiece在模型中的应用
- BERT (Google Research)
- DistilBERT
- MobileBERT
- Funnel Transformers
- MPNET
4. Unigram
4.1 Unigram的概述
Unigram是一种从大词汇表开始,通过剪枝优化到目标大小的分词算法 Unigram Tokenization。它使用Unigram语言模型计算损失,选择删除损失增加最少的子词。
4.2 Unigram的工作原理
- 初始化大词汇表:包含所有可能的子词(如“h”, “u”, “g”, “hu”, “ug”, “hug”)。
- 计算损失:使用Unigram语言模型(每个token概率为freq(token)/总频率)计算语料库的负对数似然。
- 剪枝:删除增加损失最少的子词(通常删除10-20%)。
- 重复:直到达到目标词汇表大小。
- 分词:使用Viterbi算法选择概率最高的分词方式。
示例:Unigram训练
语料库:["hug" (10次), "pug" (5次), "pun" (12次), "bun" (4次), "hugs" (5次)]
-
步骤0:初始化
- 词汇表:
["h", "u", "g", "hu", "ug", "p", "pu", "n", "un", "b", "bu", "s", "hug", "gs", "ugs"] - 频率:h=15, u=36, g=20, hu=15, ug=20, p=17, pu=17, n=16, un=16, b=4, bu=4, s=5, hug=15, gs=5, ugs=5,总和210。
- 词汇表:
-
步骤1:计算概率
- P(“h”) = 15/210 ≈ 0.0714, P(“ug”) = 20/210 ≈ 0.0952
-
步骤2:剪枝
- 计算删除每个子词的损失增加,选择最小者(如“ugs”)。
- 新词汇表:
["h", "u", "g", "hu", "ug", "p", "pu", "n", "un", "b", "bu", "s", "hug", "gs"]
示例:Unigram分词
- 分词“pug”:
- 可能分词:
["p", "u", "g"](概率:(17/210)(36/210)(20/210)≈0.00132),["p", "ug"]((17/210)(20/210)≈0.00771),["pu", "g"]((17/210)(20/210)≈0.00771) - 选择最高概率:
["p", "ug"]或["pu", "g"]
- 可能分词:
伪代码:Unigram分词
def viterbi_tokenize(word, vocab, probs):dp = [0.0] * (len(word) + 1)dp[0] = 1.0prev = [None] * (len(word) + 1)for i in range(1, len(word) + 1):for j in range(i):subword = word[j:i]if subword in vocab:prob = probs[subword] * dp[j]if prob > dp[i]:dp[i] = probprev[i] = (j, subword)tokens = []i = len(word)while i > 0:j, subword = prev[i]tokens.append(subword)i = jreturn tokens[::-1]
可视化建议:折线图,展示词汇表大小随剪枝迭代减少的趋势。
4.3 Unigram的优缺点
- 优点:
- 灵活性:初始包含所有子词,覆盖广泛。
- 子词正则化:支持多种分词方式,提高模型鲁棒性。
- 缺点:
- 计算成本高:初始词汇表大,训练复杂。
- 实现复杂:损失计算和Viterbi算法较复杂。
4.4 Unigram在模型中的应用
- XLNet
- ALBERT
- T5
5. SentencePiece
5.1 SentencePiece的概述
SentencePiece是一个支持多种分词算法的框架 SentencePiece,可以直接从原始文本训练,语言无关,广泛用于多语言任务。
5.2 SentencePiece的工作原理
- 训练:使用
spm_train指定算法(如BPE或Unigram)和词汇表大小。 - 编码/解码:使用
spm_encode和spm_decode处理文本。 - 子词正则化:支持随机采样分词方式,增强模型鲁棒性。
示例:SentencePiece使用
-
训练:
spm_train --input=corpus.txt --model_prefix=m --vocab_size=8000 --model_type=bpe -
编码:
echo "Hello world" | spm_encode --model=m.model- 输出:
▁Hello ▁world
- 输出:
-
解码:
echo "▁Hello ▁world" | spm_decode --model=m.model- 输出:
Hello world
- 输出:
伪代码:SentencePiece训练
import sentencepiece as spmdef train_sentencepiece(corpus_file, model_prefix, vocab_size, model_type):spm.SentencePieceTrainer.Train(f'--input={corpus_file} --model_prefix={model_prefix} 'f'--vocab_size={vocab_size} --model_type={model_type}')def encode_sentencepiece(text, model_file):sp = spm.SentencePieceProcessor()sp.Load(model_file)return sp.EncodeAsPieces(text)
可视化建议:流程图,展示SentencePiece从原始文本到分词的处理过程。
5.3 SentencePiece的优缺点
- 优点:
- 语言无关:无需预分词,直接处理原始文本。
- 多算法支持:支持BPE、Unigram等。
- 高效:C++实现,速度快。
- 缺点:
- 依赖库:需要安装SentencePiece。
5.4 SentencePiece在模型中的应用
- 多语言模型(如NLLB)
- 生产系统
6. Byte-level BPE (BBPE)
6.1 BBPE的概述
Byte-level BPE (BBPE)是BPE的变体,在字节级别运行,初始词汇表包含所有256个字节 Byte-level BPE。它特别适合多语言模型。
6.2 BBPE的工作原理
- 初始化:词汇表包含所有字节(0-255)。
- 合并:类似BPE,基于字节对频率合并。
- 分词:将文本转换为字节序列,然后应用BPE。
示例:BBPE分词
- 文本“café”(UTF-8:[99, 97, 102, 233]):
- 可能合并:
[99, 97]→“ca”,[102, 233]→“fé” - 分词结果:
["ca", "fé"]
- 可能合并:
伪代码:BBPE训练
def text_to_bytes(text):return list(text.encode('utf-8'))def train_bbpe(corpus, vocab_size):vocab = set(range(256)) # 所有字节byte_corpus = {''.join(map(chr, text_to_bytes(word))): freq for word, freq in corpus.items()}return train_bpe(byte_corpus, vocab_size)
可视化建议:表格,比较不同语言(如英语、法语)在BBPE下的token数量。
6.3 BBPE的优缺点
- 优点:
- 无OOV:所有字节都包含。
- 多语言支持:适合跨语言任务。
- 缺点:
- 跨语言效率低:对非训练语言可能需要更多tokens。
6.4 BBPE在模型中的应用
- 多语言模型(如Facebook AI的翻译模型)
7. 分词器比较
| 特征 | BPE | WordPiece | Unigram | SentencePiece | BBPE |
|---|---|---|---|---|---|
| 初始词汇表 | 字符 | 字符 | 所有子词 | 依赖算法 | 字节 |
| 合并标准 | 频率 | 互信息分数 | 损失增加 | 依赖算法 | 频率 |
| 处理OOV | 是 | 是 | 是 | 是 | 是(无UNK) |
| 语言独立性 | 是 | 是 | 是 | 是 | 是 |
| 应用于 | GPT, RoBERTa | BERT | XLNet | 多模型 | 多语言模型 |
8. 实际应用中的考虑
- 选择分词器:
- 单语言:BPE或WordPiece。
- 多语言:BBPE或SentencePiece(Unigram)。
- 优化:
- 调整词汇表大小以平衡性能和效率。
- 使用子词正则化(如Unigram)提高鲁棒性。
- 常见问题:
- 确保分词器与模型兼容。
- 注意跨语言性能差异。