2011肠衣问题
1 D类竞赛题目---具体题目
D题 天然肠衣搭配问题
天然肠衣(以下简称肠衣)制作加工是我国的一个传统产业,出口量占世界首位。肠衣经过清洗整理后被分割成长度不等的小段(原料),进入组装工序。
传统的生产方式依靠人工,边丈量原料长度边心算,将原材料按指定根数和总长度组装出成品(捆)。
原料按长度分档,通常以0.5米为一档,如:3-3.4米按3米计算,3.5米-3.9米按3.5米计算,其余的依此类推。表1是几种常见成品的规格,长度单位为米,∞表示没有上限,但实际长度小于26米。
表1 成品规格表
| 最短长度 | 最大长度 | 根数 | 总长度 |
| 3 | 6.5 | 20 | 89 |
| 7 | 13.5 | 8 | 89 |
| 14 | ∞ | 5 | 89 |
为了提高生产效率,公司计划改变组装工艺,先丈量所有原料,建立一个原料表。表2为某批次原料描述。
表2 原料描述表
| 长度 | 3-3.4 | 3.5-3.9 | 4-4.4 | 4.5-4.9 | 5-5.4 | 5.5-5.9 | 6-6.4 | 6.5-6.9 |
| 根数 | 43 | 59 | 39 | 41 | 27 | 28 | 34 | 21 |
| 长度 | 7-7.4 | 7.5-7.9 | 8-8.4 | 8.5-8.9 | 9-9.4 | 9.5-9.9 | 10-10.4 | 10.5-10.9 |
| 根数 | 24 | 24 | 20 | 25 | 21 | 23 | 21 | 18 |
| 长度 | 11-11.4 | 11.5-11.9 | 12-12.4 | 12.5-12.9 | 13-13.4 | 13.5-13.9 | 14-14.4 | 14.5-14.9 |
| 根数 | 31 | 23 | 22 | 59 | 18 | 25 | 35 | 29 |
| 长度 | 15-15.4 | 15.5-15.9 | 16-16.4 | 16.5-16.9 | 17-17.4 | 17.5-17.9 | 18-18.4 | 18.5-18.9 |
| 根数 | 30 | 42 | 28 | 42 | 45 | 49 | 50 | 64 |
| 长度 | 19-19.4 | 19.5-19.9 | 20-20.4 | 20.5-20.9 | 21-21.4 | 21.5-21.9 | 22-22.4 | 22.5-22.9 |
| 根数 | 52 | 63 | 49 | 35 | 27 | 16 | 12 | 2 |
| 长度 | 23-23.4 | 23.5-23.9 | 24-24.4 | 24.5-24.9 | 25-25.4 | 25.5-25.9 | ||
| 根数 | 0 | 6 | 0 | 0 | 0 | 1 |
根据以上成品和原料描述,设计一个原料搭配方案,工人根据这个方案“照方抓药”进行生产。
公司对搭配方案有以下具体要求:
这个直接就是表达式
(1) 对于给定的一批原料,装出的成品捆数越多越好;
(2) 对于成品捆数相同的方案,最短长度最长的成品越多,方案越好;
(3) 为提高原料使用率,总长度允许有± 0.5米的误差,总根数允许比标准少1根;
(4) 某种规格对应原料如果出现剩余,可以降级使用。如长度为14米的原料可以和长度介于7-13.5米的进行捆扎,成品属于7-13.5米的规格;
请建立上述问题的数学模型,给出求解方法,并对表1、表2给出的实际数据进行求解,给出搭配方案
2 第一条思路--打药方
我们看到题目有这么这个字眼
对于成品捆数相同的方案,最短长度最长的成品越多,方案越好
这个是解决这个题目的关键,最后一个方案越多,方案越好
| 14 | ∞ | 5 | 89 |
就是这个方案越多越好,那么我们就要想办法,怎么得出这个方案越多的方法,那么我们就可以想到用0-1变量,为什么我们会想到0-1变量来解决这个问题呢?
我们可以看到题目有这么个字眼
设计一个原料搭配方案,工人根据这个方案“照方抓药”进行生产
这个代表什么呢?就是我们要得到关于14~25.5的这些肠衣里面去挑选,我们要列举去这全部的挑选方案,什么是挑选方案呢?我们可以看到每一个方案后面都会有一个最大长度,那么14~∞这个的最大长度就是89,那么我们只需要挑选的时候,得到这个全部的挑选的方案在88.5~89.5长度里面,那么我们就可以用dfs算法来进行排列枚举,在24种肠衣里面进行挑选就好了,那么就是dfs的组合型枚举
我们利用C++里面的文件输出流和输入流来进行解决这个问题
#include<iostream>
#include<vector>
#include<cstring>
#include<fstream>
using namespace std;long long res4, res5;
const int n = 24;
int ans1[25], ans2[25];double a[25] = {0,14,14.5,15,15.5,16,16.5,17,17.5,18,18.5,19,19.5,20,20.5,21,21.5,22,22.5,23,23.5,24,24.5,25,25.5
};ofstream outFile("output3.csv");void printPattern(int* selected) {double sum = 0;for (int i = 1; i <= 24; i++) {if (selected[i] > 0) sum += a[i] * selected[i];}outFile << sum << ",";for (int i = 1; i <= 24; i++) {outFile << selected[i];if (i < 24) outFile << ",";}outFile << endl;
}void dfs4(int x, int start) {if (x > 4) {double sum = 0;for (int i = 1; i <= 24; i++) {sum += a[i] * ans1[i];}if (sum >= 88.5 && sum <= 89.5) {res4++;printPattern(ans1);}return;}for (int i = start; i <= 24; i++) {ans1[i]++;dfs4(x + 1, i);ans1[i]--;}
}void dfs5(int x, int start) {if (x > 5) {double sum = 0;for (int i = 1; i <= 24; i++) {sum += a[i] * ans2[i];}if (sum >= 88.5 && sum <= 89.5) {res5++;printPattern(ans2);}return;}for (int i = start; i <= 24; i++) {ans2[i]++;dfs5(x + 1, i);ans2[i]--;}
}int main() {memset(ans1, 0, sizeof(ans1));memset(ans2, 0, sizeof(ans2));dfs4(1, 1);dfs5(1, 1);cout << res4 + res5 << endl;outFile.close();return 0;
}我们来理解一下这个dfs的思路
void dfs5(int x, int start) {if (x > 5) {double sum = 0;for (int i = 1; i <= 24; i++) {sum += a[i] * ans2[i];}if (sum >= 88.5 && sum <= 89.5) {res5++;printPattern(ans2);}return;}for (int i = start; i <= 24; i++) {ans2[i]++;dfs5(x + 1, i);ans2[i]--;}
}
这个是我们在可以选择重复的,其实这个start不用也是可以的,思路就是我们这个数字的状态就是选择和未选择,当到达5种的时候就直接进行return,然后我们就加上这个对应的数组,然后这个ans是可以代表这个种类选择了多少,然后如果成立的话就输出这个ans就好了
这个时候我们就可以输出到xlx表格上面了,输出文件对应的函数是outFile这方法,输出到表格上面,输出,是表示换到下一列去进行输出
3 按药方进行抓药
这个时候我们有xlsx表格里面存储着这个药房的种类,那么我们就进行按药房抓药就好了,我们还可以很据上面的程序得出这个总的方案数为4286,然后我根据这些药房进行抓取就好了
我们有这么多的方案数,那么就是我们要在这些方案里面的出更多的捆数,因为这就是所有的捆的方案了,我们只需要进行最大值,就是在这么多捆里面得出最大值就好了
所以我们可以写出一个表达式为

这里的2783改为4286,然后我们就要进行约束变量
我们在进行捆的时候,我们捆的是不可以超过他原本给的肠衣的数量的,所以我们就可以建立一个这样的约束条件

模型的学习
这里的bij表示的这个表示这第i种方案的第j种的肠衣的数量,我们把4286所挑选的同一个肠衣的数量进行相加,那么就可以得到这个每一个肠衣数量,然后根这歌aj进行比较也就是对应的肠衣的数量,这样我们就可以得到这歌最大的捆数,这样后面的捆数也是是十分简单就可以进行求解的
4 总结
1 0-1变量的模型构建
1 0-1变量什么时候使用?
当我们在建立最短或者最多这种类型问题的时候,一般都要考虑要用0-1变量,为什么呢?就比如这一个题目,就是我们在进行挑选出最多的捆数的时候,我们只要把所有的捆数进行捆出来,因为这些药材只可以这么捆,得到了这些捆数的方案的话,那么就可以进行对于这么多种类的捆数进行挑选,我们只需要找到最多的的捆数就好了,这个时候就可以用0-1变量,因为只可以捆这么多,我们在最大值加1就好了
2 0-1变量新的构建方法
构建0-1变量模型的时候,我们会遇到类似于这歌题目的情况,例如我们每一个方案里面有多个数据,但是这个数据又有约束
我们根据LINGO编程的技巧来想,求和为sum,后面的约束入i =1..128,这种是进行一个循环
那么我们就可以求和对于这么多种的方案,然后循环对于这些24种的
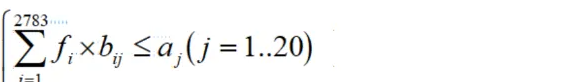
我们就可以获得这样的约束条件,这就是一个循环一个sum,这样我们就可以进行不断地进行比较了
2 组合
这个直接用我们dfs算法就可以解决了