Tailwind CSS 实战:基于 Kooboo 构建 AI 对话框页面(五):语音合成输出与交互增强
Tailwind CSS 实战,基于Kooboo构建AI对话框页面(一)
Tailwind CSS 实战,基于Kooboo构建AI对话框页面(二):实现交互功能
Tailwind CSS 实战,基于 Kooboo 构建 AI 对话框页面(三):实现暗黑模式主题切换
Tailwind CSS 实战,基于 Kooboo 构建 AI 对话框页面(四):语音识别输入功能
继前几篇实现语音识别功能后,本文将聚焦于语音合成输出的落地,结合 Web Speech Synthesis API 与 Tailwind CSS,构建「语音输入→AI 处理→语音输出」的完整交互闭环,并通过 UI 优化增强操作反馈。
一、关于语音合成
语音合成(Text-to-Speech, TTS)就是把文字变成声音。在 AI 对话框里加上这个功能,能让 AI “开口说话”,比如用户打字提问后,AI 不仅显示文字回复,还能读出答案。这对习惯听语音的用户或双手忙碌的场景非常友好,让交互更自然。
核心技术:Web Speech Synthesis API
这是浏览器自带的 API,不需要额外安装库,直接用 JavaScript 就能调用。它支持多语言(如中文、英文),还能调整语速、音调等参数,非常适合前端开发。
二、一步一步实现语音合成功能
1. 准备工作:初始化语音合成对象
首先,在 JavaScript 里创建一个语音合成实例,并定义一些变量来跟踪当前播放状态:
const synth = window.speechSynthesis; // 语音合成对象
let currentUtterance = null; // 当前正在播放的语音实例
let lastPlayedText = ''; // 最后播放的文本,用于全局播放控制
2. 播放语音的核心函数:speak ()
这个函数负责把文本转为语音并播放,还会更新按钮和状态指示器的样式。
function speak(text, button = null) { // 先停止当前正在播放的语音 if (currentUtterance) { synth.cancel(); } // 创建语音实例 const utterance = new SpeechSynthesisUtterance(text); // 设置语音参数(从全局设置中获取) utterance.rate = speechSettings.rate; // 语速(0.5倍最慢,2倍最快) utterance.pitch = speechSettings.pitch; // 音调(0最低,2最高) utterance.volume = speechSettings.volume; // 音量(0-1) utterance.lang = speechSettings.lang; // 语言,如'zh-CN'(中文)或'en-US'(英文) // 播放时更新UI:按钮变绿,显示加载动画 if (button) { button.classList.add('active'); // 添加激活态样式(绿色背景) button.innerHTML = '<i class="fa fa-pause"></i>'; // 切换为暂停图标 const indicator = button.parentElement.querySelector('.voice-indicator'); indicator?.classList.add('active'); // 显示动态脉冲效果 } // 绑定播放结束事件:播放完后重置按钮状态 utterance.onend = () => { if (button) { button.classList.remove('active'); button.innerHTML = '<i class="fa fa-play"></i>'; indicator?.classList.remove('active'); } }; // 开始播放 synth.speak(utterance); currentUtterance = utterance; // 记录当前播放的实例 lastPlayedText = text; // 记录最后播放的文本
}
3. 添加播放按钮到 AI 消息气泡
在 AI 回复的 HTML 里,每个消息气泡右侧加一个播放按钮。点击按钮时,调用上面的speak函数:
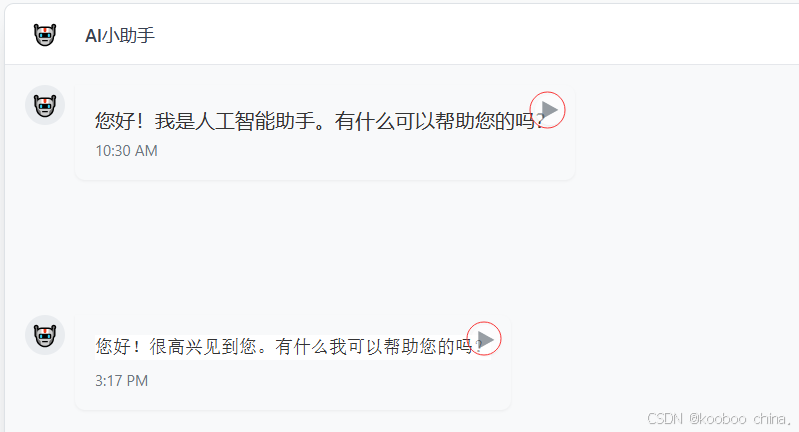
<div class="max-w-[70%] relative"> <div class="bg-[var(--chat-bubble-ai)] p-4 rounded-lg"> <p>您好!这是AI的语音回复。</p> </div> <!-- 播放按钮:点击时调用speak函数,传入文本和当前按钮 --> <button class="play-button absolute right-4 top-4" onclick="speak('您好!这是AI的语音回复。', this)" > <i class="fa fa-play text-gray-500"></i> </button> <!-- 语音状态指示器:播放时显示绿色脉冲 --> <div class="voice-indicator absolute right-12 top-5"></div>
</div>
4. 全局播放按钮:一键控制所有语音
在页面右下角加一个固定按钮,方便用户暂停 / 继续所有语音,或重播最后一条:
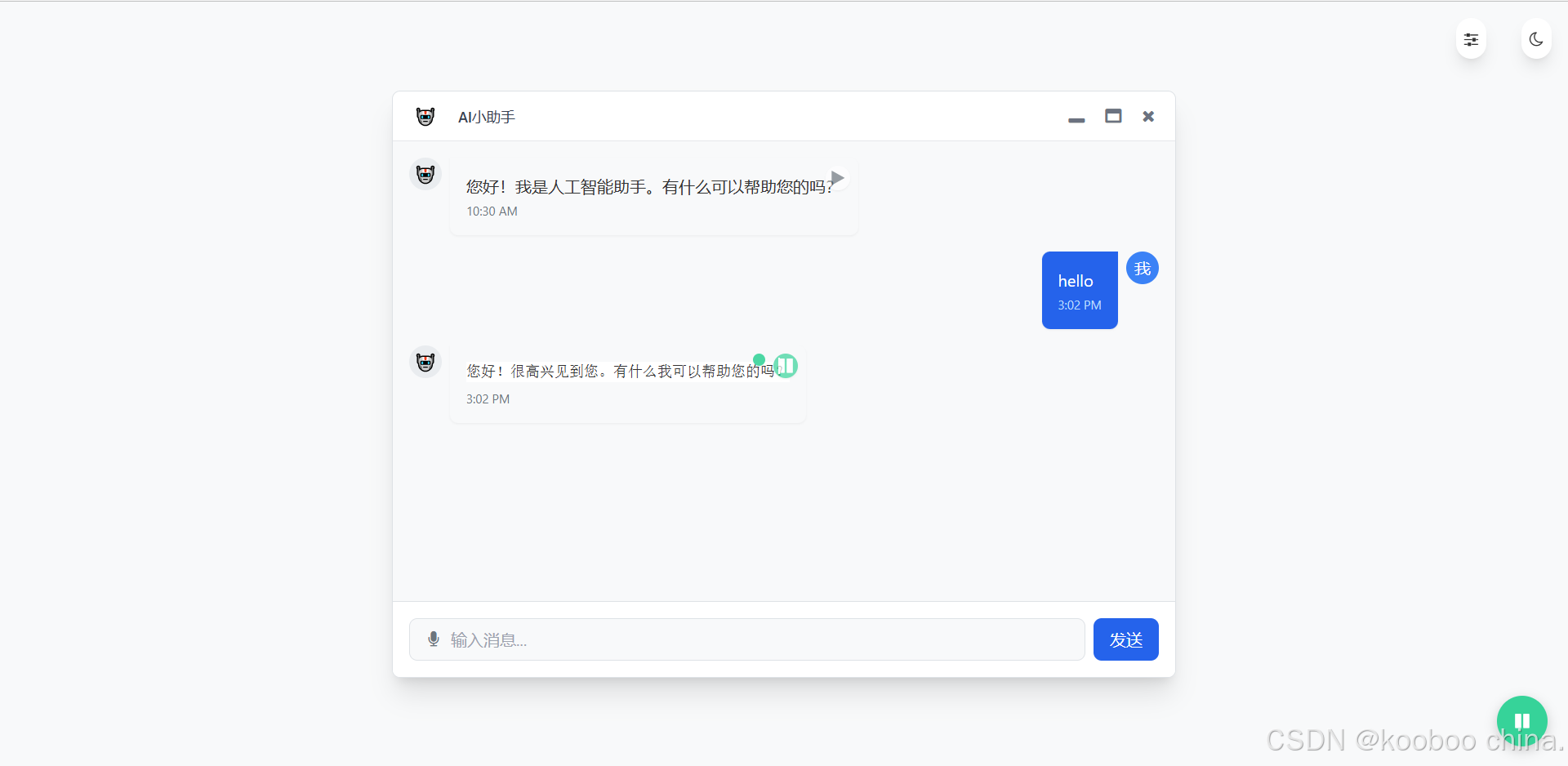
<button id="globalPlayButton" class="fixed bottom-4 right-4 w-12 h-12 rounded-full bg-blue-500 text-white"> <i class="fa fa-play"></i>
</button>
点击事件逻辑:
globalPlayButton.addEventListener('click', () => { if (synth.speaking) { // 如果正在播放,切换暂停/继续 synth.paused ? synth.resume() : synth.pause(); } else if (lastPlayedText) { // 如果没有播放,重播最后一条消息 speak(lastPlayedText); }
});
三、设计语音设置面板:让用户自定义声音
为什么需要设置面板?
不同用户对语音的偏好不同,比如有人喜欢快语速,有人喜欢低沉的声音。设置面板允许用户调整参数,并保存设置到本地,下次打开页面时自动应用。
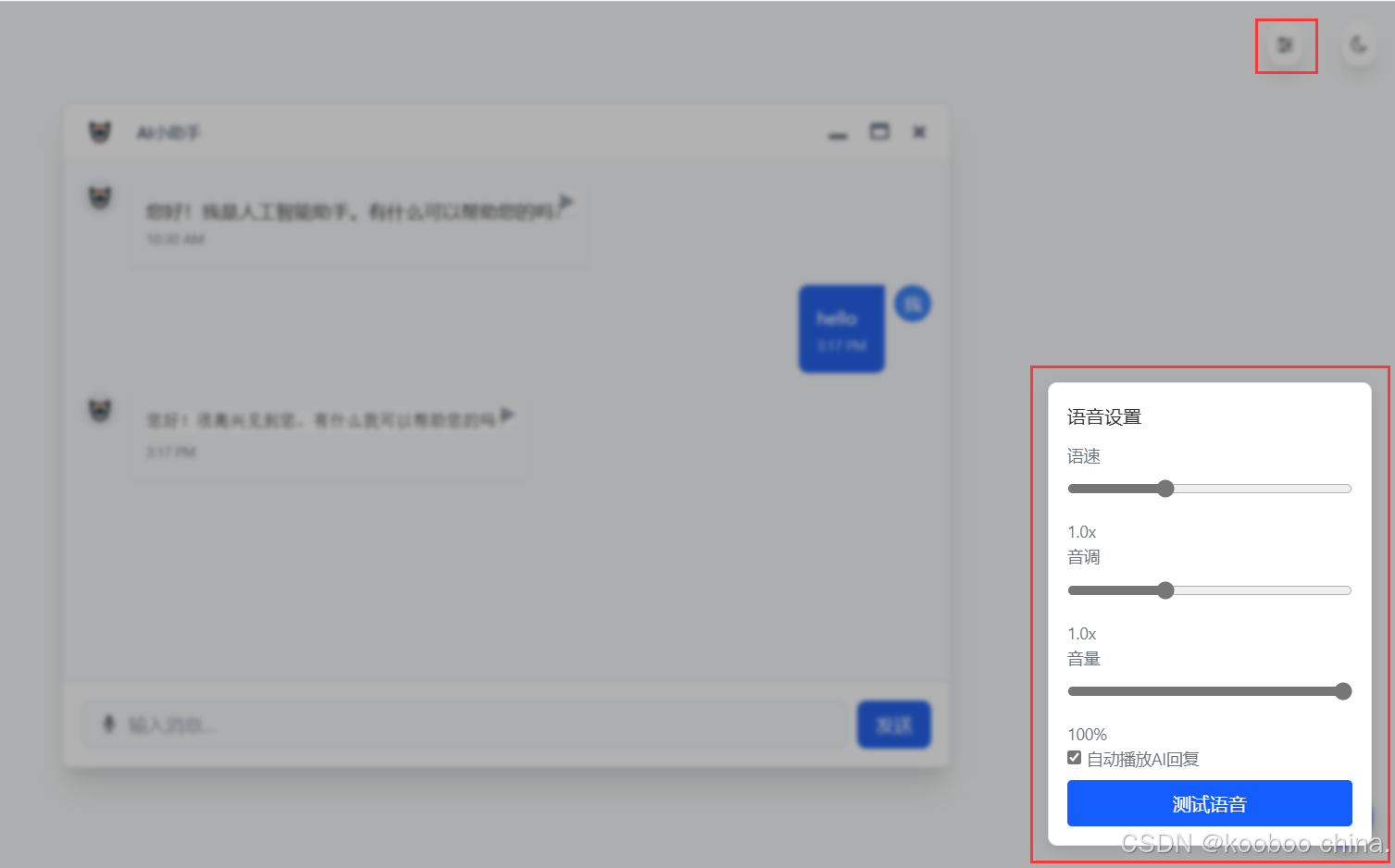
面板里有什么?
- 语速滑动条:控制语音速度(0.5x 到 2x)。
- 音调滑动条:调整声音高低(0 到 2)。
- 音量滑动条:设置音量大小(0% 到 100%)。
- 自动播放开关:AI 回复生成后是否自动播放语音。
- 测试按钮:用当前设置播放测试语音。
HTML 结构:
<div id="voiceSettings" class="voice-settings"> <h3>语音设置</h3> <label>语速</label> <input type="range" id="rateSlider" min="0.5" max="2" step="0.1" value="1"> <span id="rateValue">1.0x</span> <label>音调</label> <input type="range" id="pitchSlider" min="0.5" max="2" step="0.1" value="1"> <span id="pitchValue">1.0x</span> <label>音量</label> <input type="range" id="volumeSlider" min="0" max="1" step="0.1" value="1"> <span id="volumeValue">100%</span> <label> <input type="checkbox" id="autoPlayToggle" checked> 自动播放AI回复 </label> <button id="testVoiceButton">测试语音</button>
</div>
保存设置到本地:
用localStorage存储用户设置,页面刷新后不会丢失:
// 监听滑动条变化,更新设置并保存
rateSlider.addEventListener('input', (e) => { speechSettings.rate = parseFloat(e.target.value); rateValue.textContent = `${speechSettings.rate.toFixed(1)}x`; localStorage.setItem('speechSettings', JSON.stringify(speechSettings));
}); // 页面加载时读取本地设置
const savedSettings = localStorage.getItem('speechSettings');
if (savedSettings) { speechSettings = JSON.parse(savedSettings); rateSlider.value = speechSettings.rate; // 同步更新其他滑动条和开关
} 四、完整代码:从 HTML 到 JavaScript
HTML 部分:
包含暗黑模式切换、语音设置按钮、消息容器、输入框和全局播放按钮。注意 AI 消息里的播放按钮和状态指示器:
<body> <!-- 暗黑模式切换按钮 --> <button id="darkModeToggle">...</button> <!-- 语音设置按钮 --> <button id="voiceSettingsToggle"><i class="fa fa-sliders"></i></button> <!-- 语音设置面板 --> <div id="voiceSettings" class="voice-settings"> <!-- 滑动条和开关 --> </div> <!-- 聊天窗口 --> <div id="messageContainer"> <!-- AI初始消息,包含播放按钮和状态指示器 --> </div> <!-- 输入框和发送按钮 --> <div class="input-wrapper"> <button id="voiceButton"><i class="fa fa-microphone"></i></button> <input id="messageInput" placeholder="输入消息..."> </div> <!-- 全局播放按钮 --> <button id="globalPlayButton"><i class="fa fa-play"></i></button>
</body> JavaScript 部分:
核心逻辑包括语音合成、语音识别、设置管理和 UI 交互。这里重点看speak函数和设置面板的逻辑:
// 语音设置参数
let speechSettings = { rate: 1, pitch: 1, volume: 1, autoPlay: true, lang: 'zh-CN'
}; // 播放语音函数
function speak(text, button) { // 停止当前播放 synth.cancel(); // 创建语音实例并设置参数 const utterance = new SpeechSynthesisUtterance(text); Object.assign(utterance, speechSettings); // 更新按钮和指示器状态 if (button) { button.classList.add('active'); button.querySelector('.fa').classList.remove('fa-play').add('fa-pause'); button.nextElementSibling.classList.add('active'); } // 播放结束后重置状态 utterance.onend = () => { if (button) { button.classList.remove('active'); button.querySelector('.fa').classList.remove('fa-pause').add('fa-play'); button.nextElementSibling.classList.remove('active'); } }; synth.speak(utterance);
} // 自动播放AI回复
function addAIResponse(response) { // 添加消息到页面 messageContainer.innerHTML += `...`; // 如果开启自动播放,调用speak函数 if (speechSettings.autoPlay) { speak(response, messageContainer.lastElementChild.querySelector('.play-button')); }
} 五、常见问题(初学者必看)
1. 为什么语音不播放?
- 检查浏览器支持:Web Speech Synthesis API 在 Chrome、Edge 等现代浏览器中支持较好,IE 不支持。
- 权限问题:浏览器可能需要用户交互(如点击按钮)才能播放声音,直接在页面加载时播放可能被阻止。
- 网络问题:部分浏览器需要联网才能使用语音合成。
2. 如何添加更多语言?
修改speechSettings.lang的值即可,比如:
speechSettings.lang = 'en-US'; // 美式英语
speechSettings.lang = 'ja-JP'; // 日语
注意:浏览器需要支持该语言的语音引擎,可能需要安装语音包。
3. 按钮样式不生效怎么办?
- 确保 Tailwind CSS 的类名正确,比如
rounded-full、bg-green-500是否存在。 - 检查 CSS 变量是否定义,如
--voice-playing是否在:root或.dark中声明。
4. 如何调试?
- 使用浏览器开发者工具(F12),在控制台查看错误信息。
- 在
speak函数中添加console.log('播放语音:', text),确认函数是否被正确调用。
最终效果:
- 用户输入文字或语音,AI 回复文本并自动播放语音(若开启自动播放)。
- 点击消息气泡旁的播放按钮,可手动播放 / 暂停。
- 拖动设置面板的滑动条,实时调整语速、音调、音量。
- 点击全局播放按钮,快速控制所有语音。
结语
通过这篇教程,你学会了如何用 Web Speech Synthesis API 实现语音合成,结合 Tailwind CSS 设计交互界面,并通过设置面板提升用户体验。现在,你的 AI 对话框已经具备 “听” 和 “说” 的能力,形成完整的语音交互闭环。