a+b+c+d==0(用哈希表进行优化)
std::unordered_map 基本用法
(1) 声明与初始化
#include <unordered_map>
#include <string>std::unordered_map<std::string, int> wordCount; // 键: string, 值: int// 初始化方式
std::unordered_map<int, std::string> idToName = {{1, "Alice"},{2, "Bob"},{3, "Charlie"}
};(2) 插入元素
// 方式1: insert()
wordCount.insert({"apple", 3}); // 如果 "apple" 已存在,不会覆盖// 方式2: emplace() (更高效)
wordCount.emplace("banana", 5); // 直接构造,避免临时对象// 方式3: operator[]
wordCount["orange"] = 2; // 如果 "orange" 不存在,会自动插入(3) 访问元素
// 方式1: operator[] (如果 key 不存在,会插入默认值)
int count = wordCount["apple"]; // 如果不存在,返回 0(int 的默认值)// 方式2: at() (如果 key 不存在,抛出 std::out_of_range 异常)
int count = wordCount.at("apple");// 方式3: find() (返回迭代器,如果不存在则返回 end())
auto it = wordCount.find("apple");
if (it != wordCount.end()) {std::cout << "Count: " << it->second << std::endl;
}(4) 删除元素
// 方式1: erase(key)
wordCount.erase("apple");// 方式2: erase(iterator)
auto it = wordCount.find("banana");
if (it != wordCount.end()) {wordCount.erase(it);
}// 方式3: clear() (清空整个哈希表)
wordCount.clear();(5) 遍历哈希表
// 方式1: 范围 for 循环
for (const auto& pair : wordCount) {std::cout << pair.first << ": " << pair.second << std::endl;
}// 方式2: 迭代器
for (auto it = wordCount.begin(); it != wordCount.end(); ++it) {std::cout << it->first << ": " << it->second << std::endl;
}std::unordered_set 基本用法
unordered_set 类似于 unordered_map,但只存储键(无值)。
(1) 声明与初始化
#include <unordered_set>std::unordered_set<int> uniqueNumbers = {1, 2, 3, 4, 5};(2) 插入元素
uniqueNumbers.insert(6);
uniqueNumbers.emplace(7); // 更高效(3) 查找元素
if (uniqueNumbers.find(3) != uniqueNumbers.end()) {std::cout << "3 exists!" << std::endl;
}(4) 删除元素
uniqueNumbers.erase(3); // 删除值为 3 的元素(5) 遍历集合
for (int num : uniqueNumbers) {std::cout << num << std::endl;
}其实我最初没有用哈希表,但时间上不给我过
先把题目亮出来:
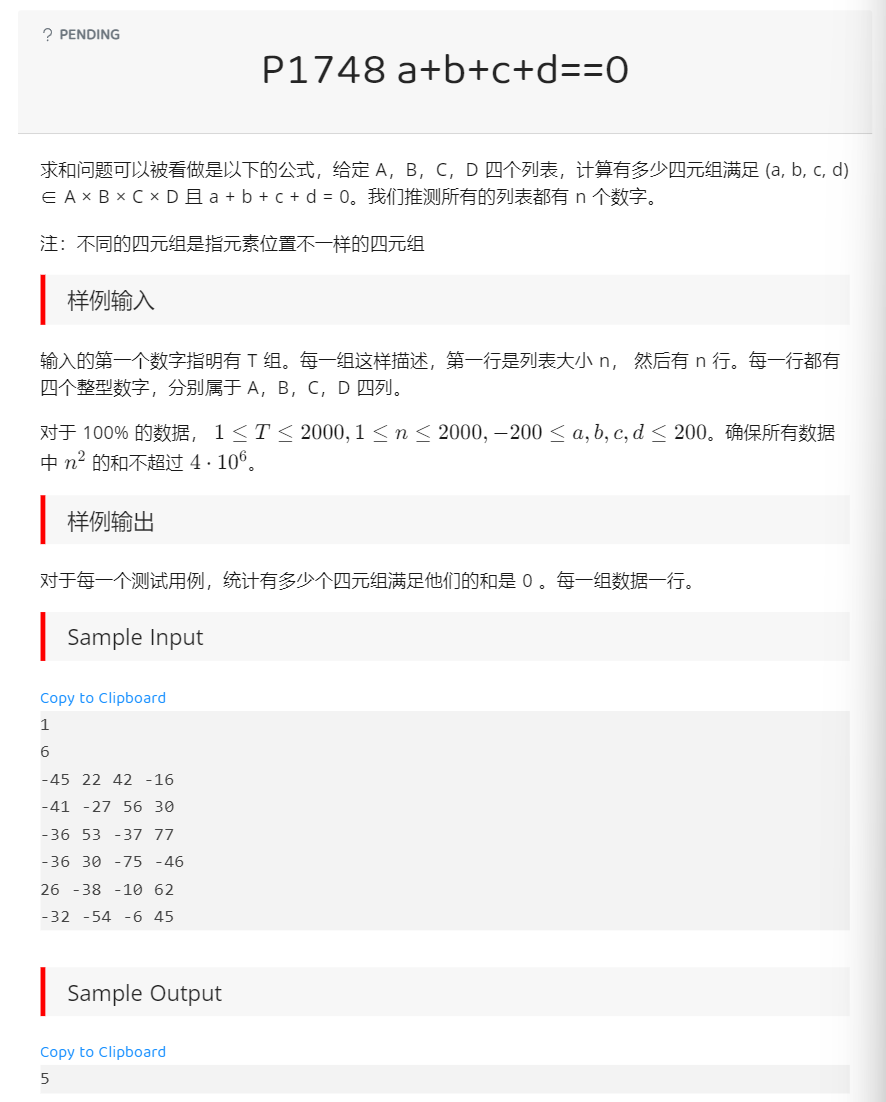
我最初的代码是:
# include<iostream>
# include<vector>
# include<algorithm>
using namespace std;int main()
{int T;cin>>T;while(T--){int n;cin>>n;vector<int> a(n);vector<int> b(n);vector<int> c(n);vector<int> d(n);for(int i=0;i<n;i++){cin>>a[i]>>b[i]>>c[i]>>d[i];} vector<int> result1(n*n);vector<int> result2(n*n);int k = 0;for(int i=0;i<n;i++){for(int j=0;j<n;j++){result1[k] = a[i]+b[j];result2[k] = c[i]+d[j];k++;}}sort(result1.begin(),result1.end());sort(result2.begin(),result2.end());int count = 0;int location1 = 0;int location2 = 0;for(int i=0;i<n*n;i++){if(result1[i]<0){location1++;}else{break;}}for(int i=0;i<n*n;i++){if(result2[i]<0){location2++;}else{break;}}int start = 0;int end = n*n;for(int i=0;i<n*n;i++){if(result1[i]<0){start = location2;end = n*n;}else{start = 0;end = location2;}for(int j=start;j<=end;j++){if(result1[i]+result2[j]==0){count++;if((j+1)<n*n&&result2[j+1]!=result2[j]){break;}}if(result1[i]+result2[j]>0){break;}}}cout<<count<<endl;}return 0;
}代码本身没有问题,时间上不够优化
接下来就是用哈希表进行操作,但是思想其实不复杂:
# include<iostream>
# include<vector>
# include<algorithm>
# include<unordered_map>
using namespace std;int main()
{int T;cin>>T;while(T--){int n;cin>>n;vector<int> a(n);vector<int> b(n);vector<int> c(n);vector<int> d(n);for(int i=0;i<n;i++){cin>>a[i]>>b[i]>>c[i]>>d[i];}unordered_map<int,int> arr(n);for(int i=0;i<n;i++){for(int j=0;j<n;j++){arr[a[i]+b[j]]++;}}int count = 0;for(int i=0;i<n;i++){for(int j=0;j<n;j++){int target = -(c[i]+d[j]);if(arr.find(target)!=arr.end()){count+=arr[target];}}}cout<<count<<endl;} return 0;
}当你在看上面代码的时候,其实并不是特别难,你肯定是可以看懂的,所以其实没有太大的必要去做额外的解释。
ok,这题就到这里。