一周学会Pandas2之Python数据处理与分析-Pandas2数据合并与对比-df.combine_first():填充合并
锋哥原创的Pandas2 Python数据处理与分析 视频教程:
2025版 Pandas2 Python数据处理与分析 视频教程(无废话版) 玩命更新中~_哔哩哔哩_bilibili

df.combine_first():填充合并
df.combine_first() 是 pandas 中用于 填补缺失值 的重要方法,其核心功能是用另一个 DataFrame 或 Series 中的非空值覆盖当前对象的空值(NaN)。该方法特别适合在两个数据集存在部分重叠时,通过“互补”合并数据。以下是详细说明及示例:
基本语法:
DataFrame.combine_first(other)other: 另一个 DataFrame 或 Series,用于填补当前对象的缺失值。
返回值: 新的 DataFrame,包含合并后的数据。
核心特点:
-
填补规则:
-
对于当前 DataFrame 中的
NaN,用other对应位置的值填充。 -
如果
other中存在当前 DataFrame 没有的列或行索引,这些列或行会被添加到结果中。 -
如果某个位置在两个 DataFrame 中都有非空值,优先保留当前 DataFrame 的值。
-
-
索引对齐:
-
合并时按行和列索引对齐,类似于
reindex_like的逻辑。
-
示例:
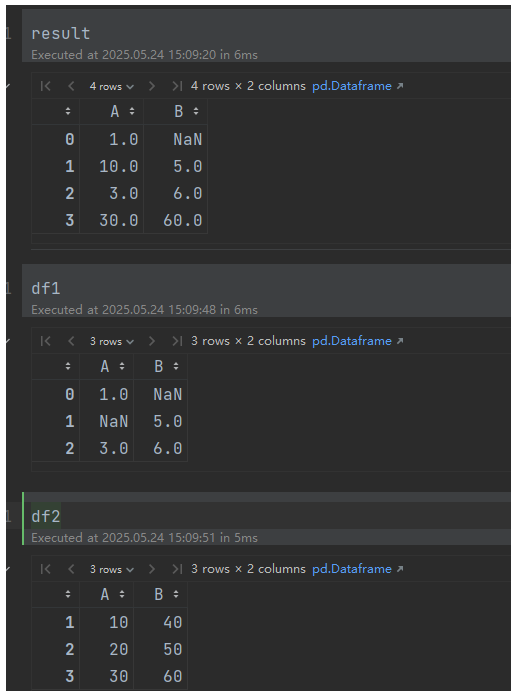
import pandas as pd
import numpy as npdf1 = pd.DataFrame({'A': [1, np.nan, 3], 'B': [np.nan, 5, 6]}, index=[0, 1, 2])
df2 = pd.DataFrame({'A': [10, 20, 30], 'B': [40, 50, 60]}, index=[1, 2, 3])result = df1.combine_first(df2)