LangGraph的智能评估
从聊天机器人到智能助手,我们都在努力提升用户体验。但如何确保这些应用真的能达到预期效果呢?这就需要一个强大的评估系统。LangGraph结合了LangSmith和OpenEvals,为智能应用提供了一套完整的评估解决方案。看看这个评估系统是如何工作的。
评估可以帮助我们发现应用的优点和不足,从而进行优化和改进。
就像一个医生给病人做体检一样,评估就是给智能应用做“体检”,确保它健康、高效。
LangGraph的评估流程
LangGraph的评估流程可以分为几个简单的步骤:创建数据集、定义目标函数、定义评估器、运行评估。接下来,我们详细看看每个步骤。
1.创建数据集
首先,需要准备一些测试数据,这些数据将用来评估我们的智能应用。在LangGraph中,我们可以使用LangSmith来创建和管理数据集。比如,我们可以创建一个包含一些常见问题和答案的数据集。
from langsmith import Clientclient = Client()# 在 LangSmith 中以编程方式创建数据集
# 关于其他数据集创建方法,请参阅:
# https://docs.smith.langchain.com/evaluation/how_to_guides/manage_datasets_programmatically
# https://docs.smith.langchain.com/evaluation/how_to_guides/manage_datasets_in_applicationdataset_name = "示例数据集2"dataset = client.create_dataset(dataset_name=dataset_name, description="LangSmith 中的一个示例数据集。"
)# 创建示例
examples = [{"inputs": {"question": "杭州在哪里?"},"outputs": {"answer": "中国的南方。"},},{"inputs": {"question": "地球的最低点是什么?"},"outputs": {"answer": "地球的最低点是死海。"},},
]# 将示例添加到数据集
client.create_examples(dataset_id=dataset.id, examples=examples)#会上传到langSmith服务中了运行后会上传到LangSmith中
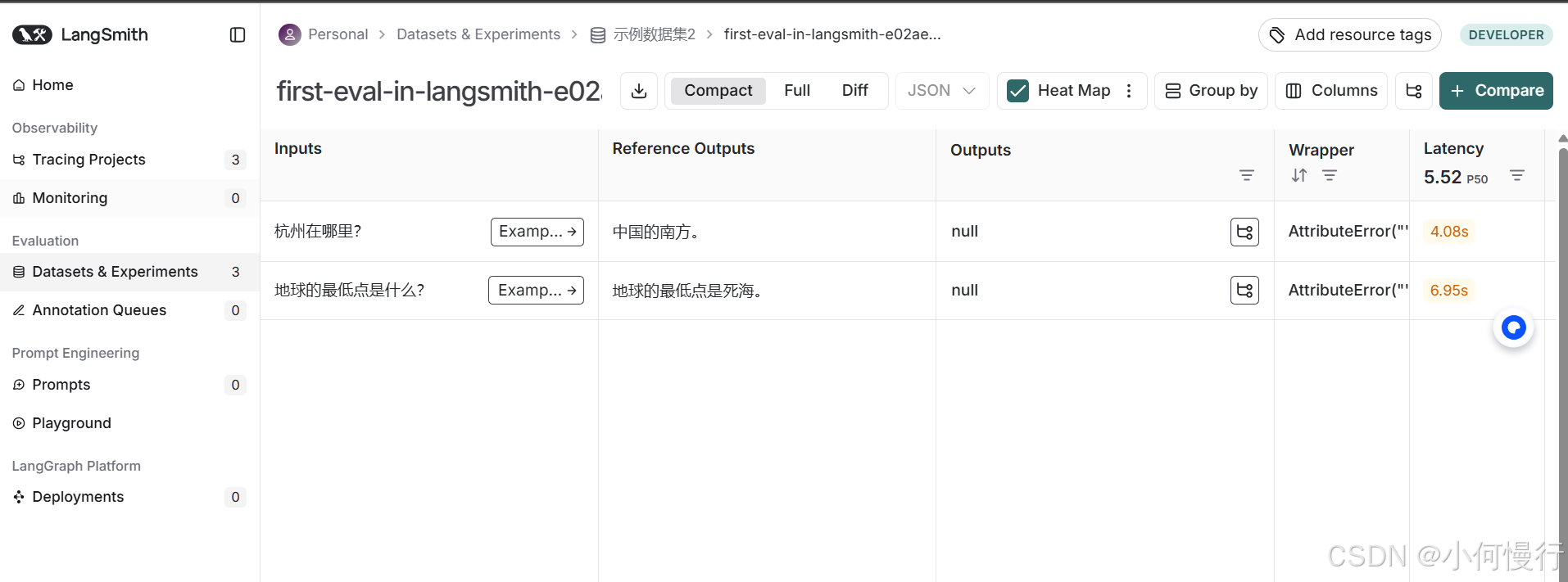
在这个例子中,我们创建了一个名为“示例数据集2”的数据集,并添加了两个示例问题和答案。
2.定义目标函数
接下来,我们需要定义一个目标函数,将包含我们要评估的内容。
比如,我们可以定义一个函数,让它调用我们的智能应用来回答问题。
pip install -U agentevals
# -*- coding: utf-8 -*-
from langgraph.prebuilt import create_react_agent
from langchain_community.chat_models.tongyi import ChatTongyi# 提示
# 这个快速入门使用了开源 openevals 包中的预构建 LLM-as-judge 评估器。OpenEvals 包含了一组常用的评估器,如果你是评估新手,这是一个很好的起点。如果你想在评估你的应用程序时有更大的灵活性,你也可以使用自己的代码定义完全自定义的评估器。# 要开始,你可以使用 AgentEvals 包中的预构建评估器:
# pip install -U agentevals#模型初始化
llm = ChatTongyi(model="qwen-max-latest",#qwen-max-latest qwen-plus qwen-turbotemperature=0,verbose=True,)def target(inputs: dict) -> dict:#构建一个智能体agent = create_react_agent(model=llm,tools=[],)response = agent.invoke({"messages": [{"role": "system", "content": "准确回答以下问题"},{"role": "user", "content": inputs["question"]},]})return {"answer": print(response["messages"][-1]) }
这个函数会调用我们的智能应用,传入一个问题,然后返回应用的回答。
3.定义评估器
有了目标函数和测试数据后,我们需要定义评估器。评估器的作用是根据测试数据和目标函数的结果,给出一个评估分数。LangGraph使用了OpenEvals来定义评估器。
from openevals.llm import create_llm_as_judge
from openevals.prompts import CORRECTNESS_PROMPTdef correctness_evaluator(inputs: dict, outputs: dict, reference_outputs: dict):evaluator = create_llm_as_judge(prompt=CORRECTNESS_PROMPT,model=llm,feedback_key="correctness",)eval_result = evaluator(inputs=inputs,outputs=outputs,reference_outputs=reference_outputs)return eval_result这个评估器会比较目标函数的结果和测试数据中的正确答案,然后给出一个评估分数。
4.运行评估
最后,我们运行评估。LangGraph会自动将测试数据传入目标函数,然后用评估器给出评估分数。
experiment_results = client.evaluate(target,# data="Sample dataset",data=dataset_name,#8e388686-616d-4c66-8467-1b0e8270f983evaluators=[correctness_evaluator,# 可以在这里添加多个评估器],experiment_prefix="first-eval-in-langsmith",max_concurrency=2,
)
运行结果截图
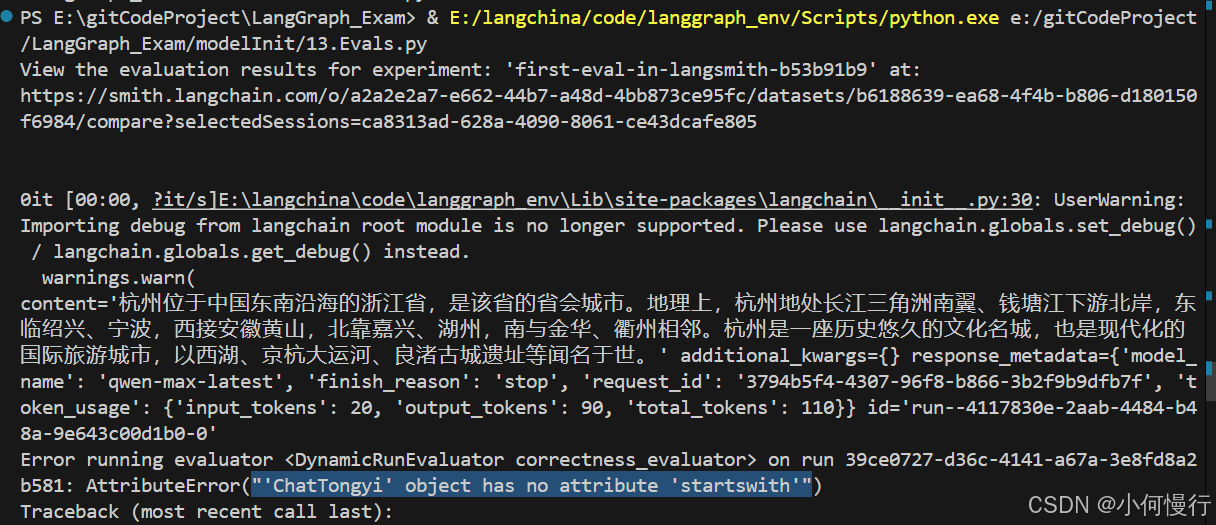
langchain服务上查看报错
运行评估后,LangGraph会提供一个链接,我们可以在这个链接中查看详细的评估结果。
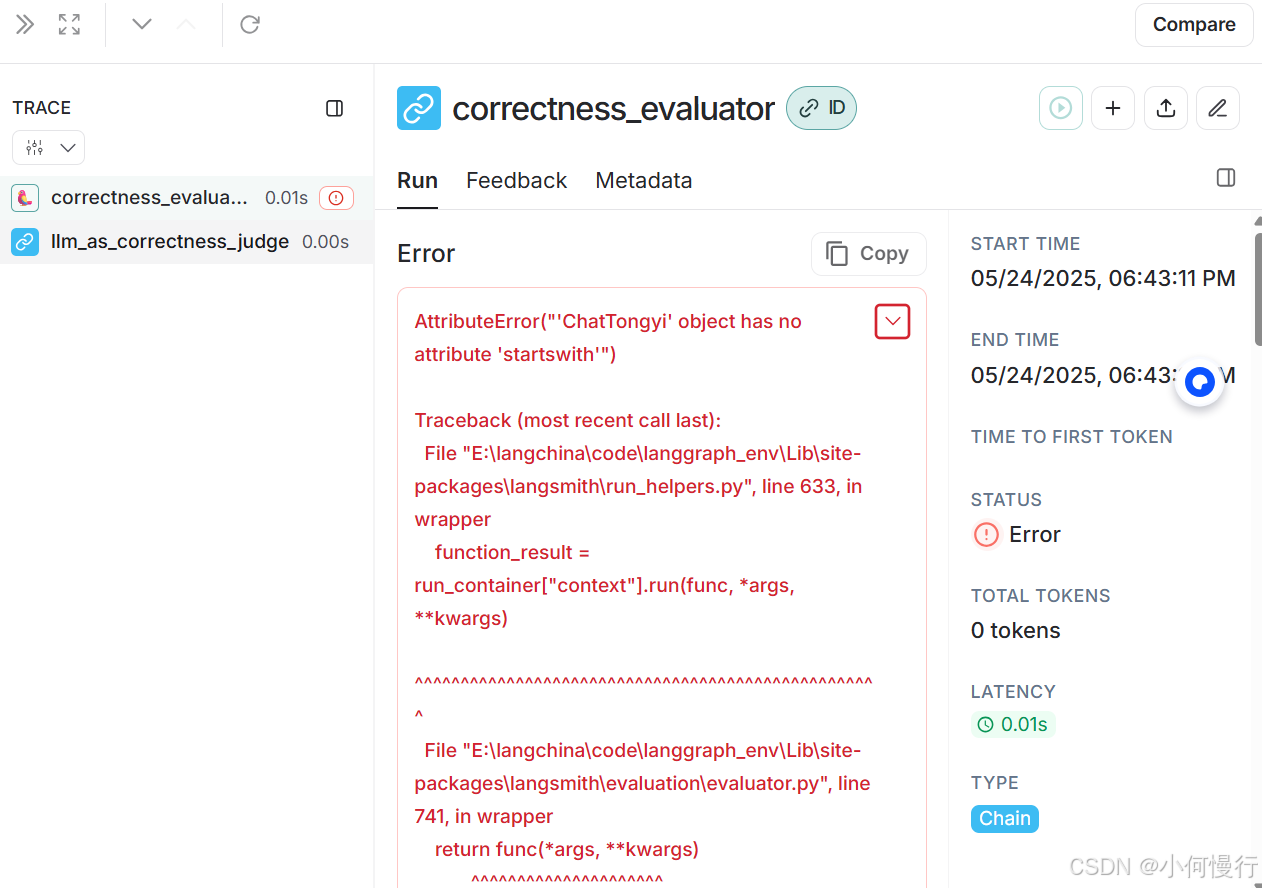
当然运行结果会报错,应该时国内大模型有些参数还没有定义吧!报错:AttributeError(“‘ChatTongyi’ object has no attribute ‘startswith’”)。
通过这个评估过程,可以发现智能客服的优点和不足,从而进行优化和改进。比如,如果评估结果显示智能客服在回答某些问题时不够准确,你可以调整模型或优化提示,提高回答的准确性。