大模型从基础到入门 记录
接上文:从DeepSeek大模型文件到大模型入门记录-CSDN博客
本文主要记录入门大模型学习的相关知识,以期为后续工作学习提供帮助。(除了我自己截图外,引用的我尽量标注来源,有些忘记来源了请告诉我orz)
更新ing...
一、大模型基础知识
我们先从一些专业名词开始:
1.1 专业名词
- 大模型:一般指参数规模很大的深度学习模型,现在主流为Transformer改进的GPT系列decoder-only模型;
- 模型参数:模型中可调节的数值,与模型权重文件有关,以参数个数计数,大模型参数规模一般以10亿为单位(Bilion),从计算机存储方面简单来看1B=1G;
- AGI——Artificial General Intelligence:通用人工智能,AI邻域的理想研究目标;
- AIGC:利用AI技术生成的内容;
- Prompt:提示词,引导大模型生成特定输出的上下文指令或信息;
- Token:分词的基本单位,可以简单认为一个中文文字对应一个token,一个英文字符对应一个token(具体划分按使用算法为准,可以看看tokenizer.json文件);
- 推理:大模型根据输入,生成输出结果的过程;
- 涌现:是大模型训练中的一种现象,在模型规模达到一定阈值后,在多任务中表现能力显著提升,可能是多个简单小组件构成一个大组件,而大组件具备小组件所没有的解决复杂问题的能力;
- Agent:智能体,可以在环境中感知、思考、采取行动的AI系统;
- 幻觉:大模型生成内容看似合理,但实际上不准确、无对应来源,与大模型按概率生成输出的性质有关;
- 预训练——Pre-training:在大规模无标准数据上训练模型,学习通用语言规律;
- 微调——Fine Tuning:基于预训练模型,在特定领域的小规模数据上继续训练模型;
- 监督微调——Supervised Fine Tuning:SFT,使用有标注数据集训练模型;
- 人类反馈的强化学习——Reinforcement Learning from Human Feedback:RLHF,通过人类反馈优化模型输出,使其与人类偏好对齐,属于强化学习邻域;
- 知识蒸馏/模型蒸馏:压缩模型大小的技术,通过训练小模型拟合大模型输出结果,达到减少资源、时间的目的。在deepseek前,蒸馏要求大小模型训练时有计算loss的交互,在deepseek出现后,可以用大模型生成数据集微调小模型,这种叫黑盒蒸馏;
- 在线学习:指模型能实时更新参数以适应不断变化的数据环境,适用于数据流持续到达的场景;
-
prefix LM (前缀语言模型):在输入序列的开头添加一个可学习的任务相关的前缀,然后使用这个前缀和输入序列一起生成输出。这种方法可以引导模型生成适应特定任务的输出。优点是可以减少对预训练模型参数的修改,降低过拟合风险;缺点是可能受到前缀表示长度的限制,无法充分捕捉任务相关的信息。
-
causal LM (因果语言模型):也称为自回归语言模型,它根据之前生成的 token 预测下一个token。在生成文本时,模型只能根据已经生成的部分生成后续部分,不能访问未来的信息。优点是可以生成灵 活的文本,适应各种生成任务;缺点是无法访问未来的信息,可能生成不一致或有误的内容。
基础专业名词就先到这里,接下来我们看看大模型的基础知识。
1.2 Transformer模型
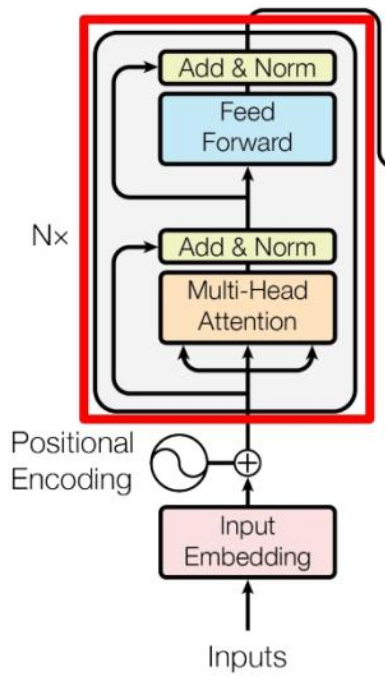
由论文《Attention is All You Need》提出,其结构图如下:
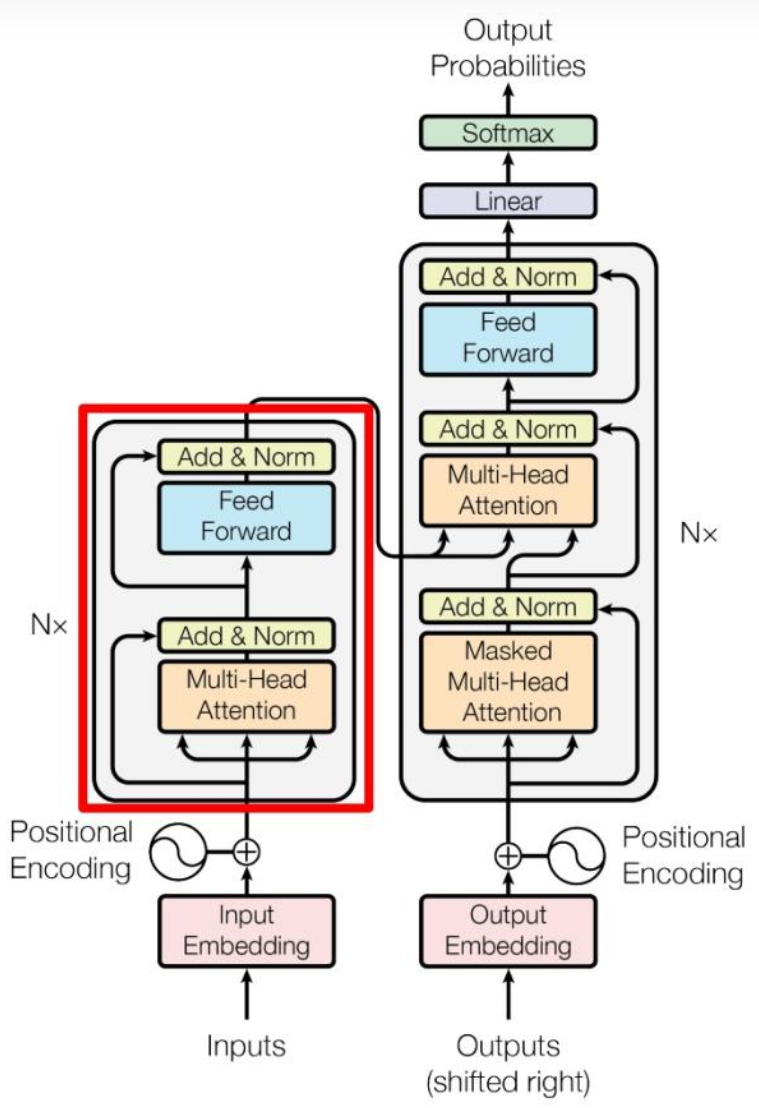
这张图可以先分为左右两个部分,左边部分为Encoder,负责处理输入为编码,右边部分为Decoder,负责生成输出。
Encoder和Decoder共同点:都由多头注意力、前馈神经网络层组成;
Encoder和Decoder不同点:Decoder中处理输入的是带掩码的多头注意力,即当前词与后续词无关,防止未来信息泄露。
基于Transformer模型,我们再深入一点到注意力机制、输入处理中。
1.3 自注意力机制
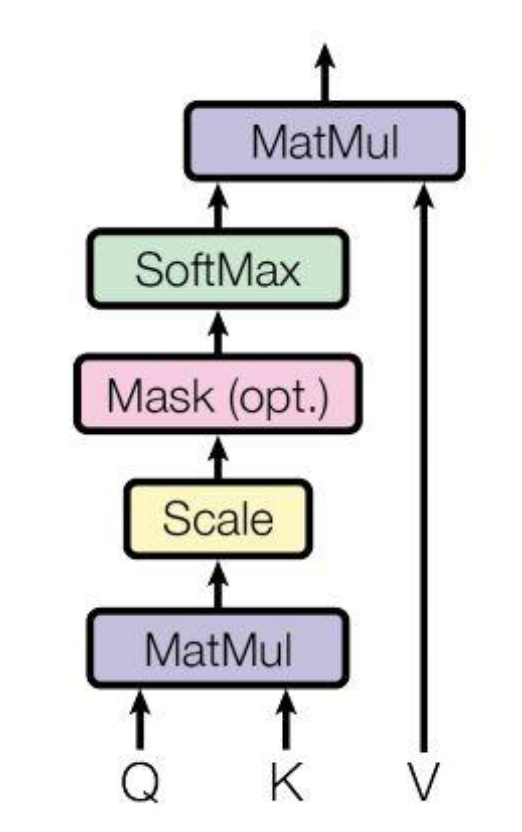
如图所示,对输入X进行线性变换,得到QKV三个矩阵,再根据这三个矩阵计算注意力attn,其公式为:
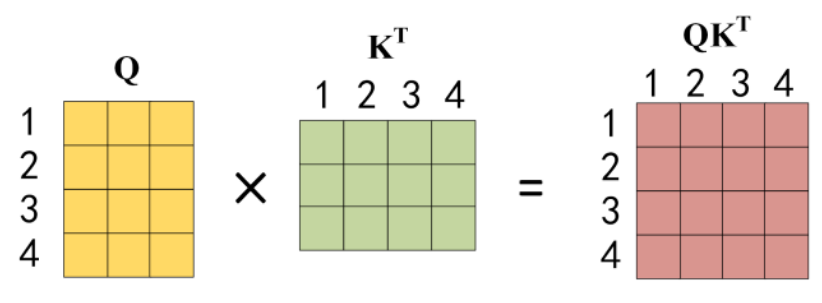
其中d为向量维度,除以d的平方根是类似归一化操作,防止QK内积过大导致梯度消失,将其缩小到softmax的敏感区间;输入长度为n,QK得到的是n*n的矩阵,每一个数值代表了当前词与其他n-1个词的关系。
1.4 输入处理
为了将输入转化为可以计算的数值,我们要将每一个词映射到向量空间中,这就是tokenizer的作用,将输入划分为多个token,每个token都有对应的ID数值,根据这个ID由嵌入矩阵映射到统一维度的向量空间中,这个过程就叫Embedding。
从自注意力机制中可以发现,如果只对输入embedding为向量,那么对于不同位置的同一个词,他们的向量是一样的,在此基础上直接计算注意力数值attn,那么这个注意力数值只与不同词之间的关系有关,相同词之间的数值是一样的,这导致计算没有记录不同词之间的位置关系,所以我们不仅仅要对输入的词做embedding,还要对词的位置信息也做embedding:
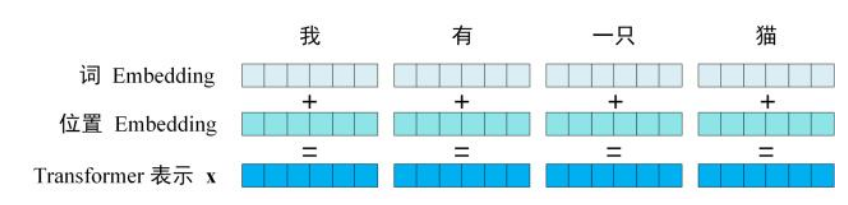
那这里又引入了两个知识点:tokenizer的算法和位置信息的编码方式。
1.4.1 Tokenizer
来源于NLP对输入进行处理的过程,目的是将输入划分为一个个独立的字串,且每个子串都有完整语义,按划分粒度来看有三种划分维度:字符、子词、词。
按字符划分导致划分后序列很长,每个字符包含语义过大,训练困难;按词划分在遇到不在词表中词时会出现OOV(out of vocab)问题,而过大的词表又会导致内存爆炸的问题;子词划分则介于前两个的中间,可以平衡词汇量和语义独立性问题。
BPE(Byte Pair Encoding,子词算法)便是目前最常用的算法,其流程为:
- 准备足够大的训练语料
- 确定期望的subword词表大小
- 将单词拆分为字符序列并在末尾添加后缀“ </ w>”,统计单词频率。 本阶段的subword的粒度是字符。 例如,“ low”的频率为5,那么我们将其改写为“ l o w </ w>”:5
- 统计每一个连续字节对的出现频率,选择最高频者合并成新的subword
- 重复第4步直到达到第2步设定的subword词表大小或下一个最高频的字节对出现频率为1
1.4.2 位置编码
位置编码一般分为两种:绝对位置编码和相对位置编码。
绝对位置编码:在每个输入序列元素上添加一个位置向量,表示该元素在序列中的位置,通常用固定函数生成即可,实现简单,如BERT用正余弦函数计算编码,但外推性较差(长距离位置关系、未见过的长度序列等情景下的性能);
相对位置编码:关心各元素间相对位置关系,通常用一个位置编码矩阵计算实现,可以建立长距离语义关系,能更好处理序列局部结构信息,但需要额外空间保存矩阵参数(学习参数方式实现),且计算效率低(因为每一层都要计算相对位置),同时kvcache也会更复杂(新输入token会影响已经生成的值)。
目前大模型常用的是旋转位置编码RoPE,一种通过绝对位置编码的形式实现相对位置编码的方法,简单来说就是通过复数实现:
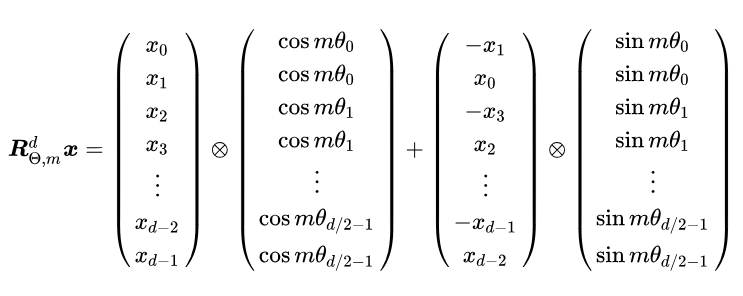
1.5 Encoder
回到Transformer模型,我们可以发现一层encoder由一个注意力层和一个前馈神经网络层组成,他们后面都有一层残差连接和层归一化。
- Add:残差连接,解决多层网络训练中梯度消失问题,可以让网络只关注输入间差异;
- Norm:指层归一化,将输入转化为均值方差都一样的形式,可以加速收敛;
- Feed Forward:前馈神经网络,这里一般指一个两层的全连接层,第二层没有激活函数,其公式为:
多个这样的encoder block叠加起来就是Encoder,这里引入一个知识点:激活函数。
1.5.1 激活函数
激活函数可以为神经网络引入非线性变化,使模型能学习复杂的数据,主流的激活函数有ReLU、GELU、swish函数:
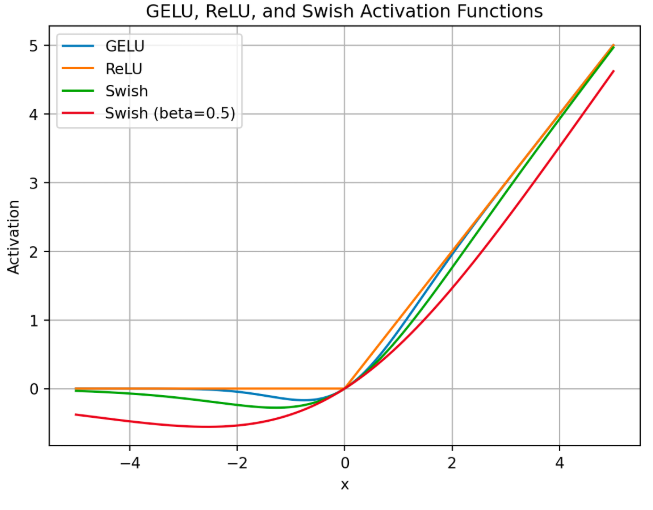
- ReLU函数很简单,其公式为
,但会导致输出为负数的神经元节点死亡,在反向梯度传播时不会更新这些节点;
- GELU则是ReLU的改进,使函数变得平滑,处处可导,但计算复杂度很高;
- Swish函数也是这个意思,即大于0的部分导数相对固定,而小于0的部分导数趋近于0,同时使函数处处可导,其公式为:
swish(x)=sigmoid(
x)×x
sigmoid(x)=
SwiGLU,其实是Swish函数+门控机制,SwiGLU(x)=Swish(xW)⊗(xV),门控机制用于控制通过信息的多少,这样会引入更多权重矩阵,通常会对隐藏层大小做缩放,保证整体参数量不变。
1.6 Decoder
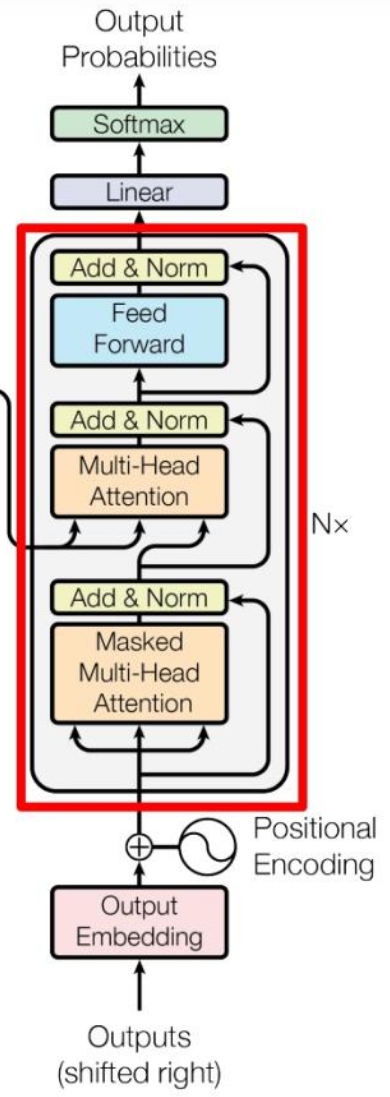
相似的,decoder block中也包含了类似的结构,只是改变了encoder几个地方,这里只重点说明变化的地方:
- 第一个多头注意力层采用掩码形式,防止未来信息泄露;
- 第二个多头注意力层中K、V用encoder得到的编码信息矩阵C来计算得到,只有Q用decoder的输出;
- 在decoder结尾使用了softmax计算下一个token的概率
Transformer中的掩码Mask让当前输出的token只和自己、前面的token有关,和未来token都无关(工程实现是加一个很大的负数,单纯置零会导致增加无效位置权重,和softmax特性有关):
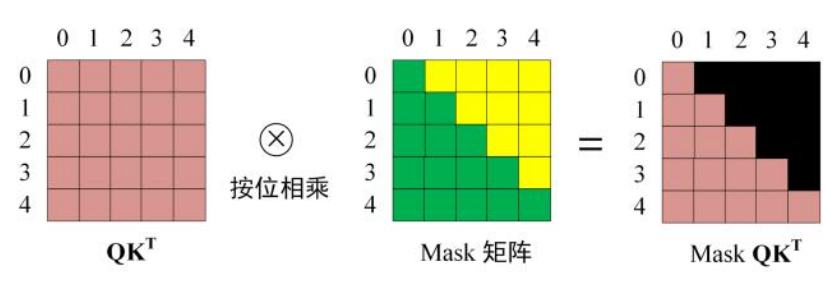
综上,这就是Transformer模型结构,而当今主流大模型根据使用Transformer结构的改进,可以分为三种:
- 只使用encoder,比如BERT;
- 只使用decoder,比如GPT、LLaMA;
- 两个都使用,比如T5、GLM;
后续我们以当前最热门的GPT系列来说明。
1.7 GPT系列decoder-only
可以看看开源模型LLaMA模型的结构:
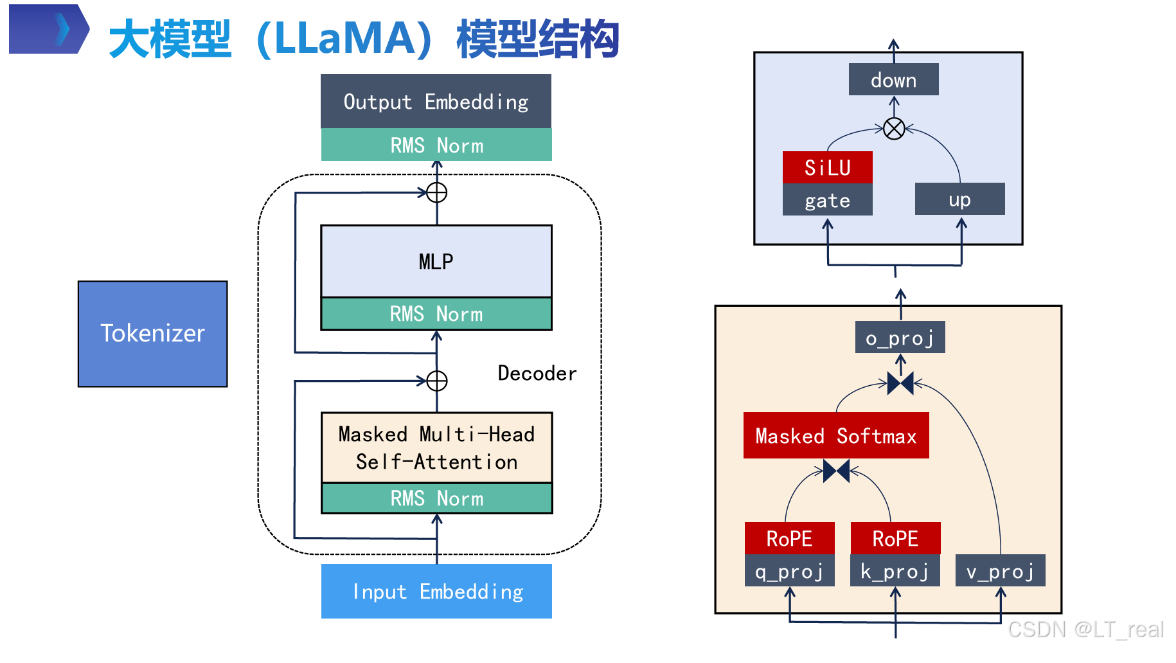
相比于传统Transformer,llama做了几个改进:
- RMS-norm归一化操作前置,叫pre-norm;
- 激活函数由ReLU改为SiLU;
- 使用分组查询注意力机制GQA,减少kvcache占用显存,提高计算效率;
- 使用MLP(多层感知机)代替简单两层全连接层,引入门控机制,MLP(x) = down_proj(SiLU(gate_proj(x)) * up_proj(x)),过滤冗余信息,在不减少计算效率的同时提高模型表达能力。
我们可以看看Meta-Llama-3.1-8B-Instruct/model.safetensors.index.json文件:
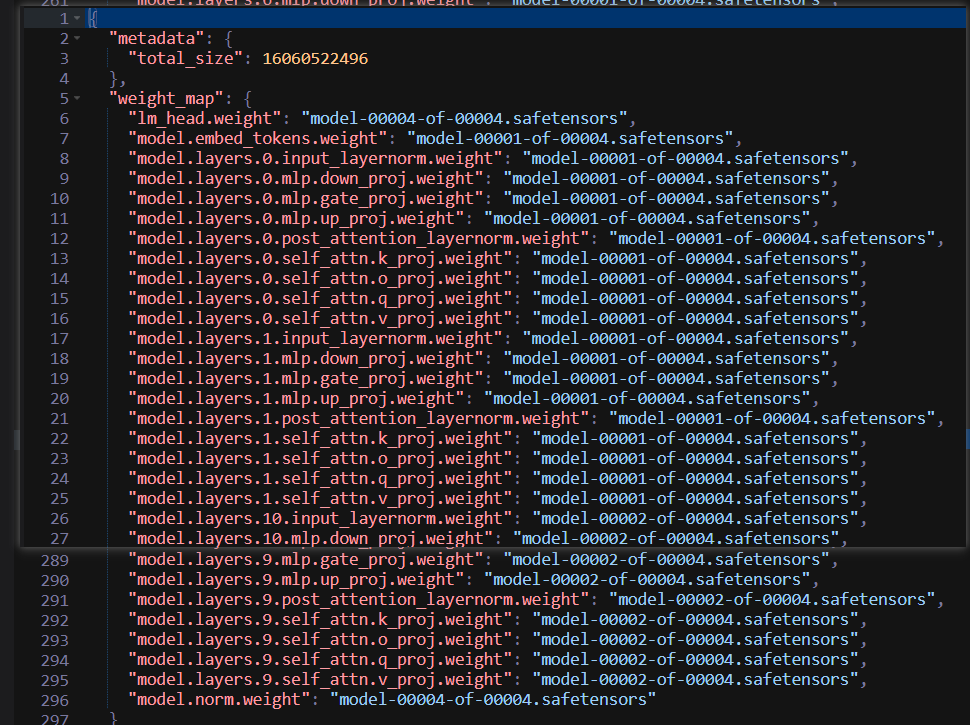
- 其中lm_head.weight用于处理输出,得到下一个token概率;
- model.embed_tokens.weight是将输出转化为向量的矩阵;
- input_layernorm就是pre-norm,这个权重代表对归一化后的数值进行缩放;
- post_layernorm其实就是pre-norm,不过换个角度来看,就是attention层的post-norm。
输入x的计算流程为:x → input_layernorm → Self-Attention → Residual Add → post_attention_layernorm → MLP → Residual Add → Output
这里又引入几个知识点:
1.7.1 pre-norm与post-norm
相比于传统的post-norm(先计算,再加残差,最后归一化),pre-norm则先进行归一化操作,再计算的流程,可以避免梯度消失问题,并加快训练速度(但上限低于post-norm,因为归一化会降低模型表征能力)。
同时,采用RMS归一化,省略层归一化的均值减法,提高计算效率
1.7.2 KVcache
虽然前面也提到了KVcache,这里详细说明一下。大模型推理可以分为两个阶段:prefill和decode。
prefill:对输入tokens一次性并行计算,最终输出第一个输出token;
docode:每次输入上次生成的token,生成一个token,直到生成EOS,拼接起来得到最终response。
现在再看看decode第一次的计算过程:
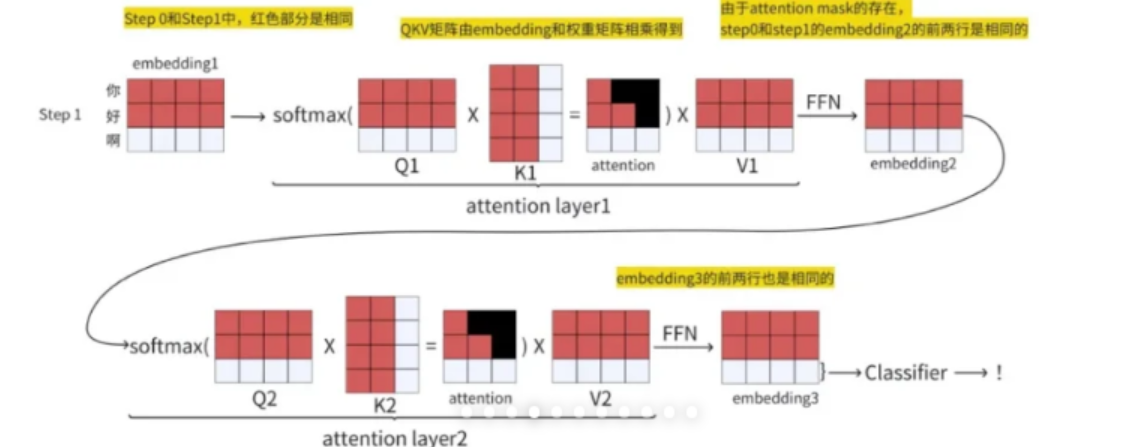
上图为输入到输出的过程,step0先输入‘你好’,计算部分为红色矩阵,得到输出‘啊’,再把输出‘啊’与step0输入拼接起来,作为step1的输入‘你好啊’,此时新增的计算部分为白色矩阵,我们可以发现,红色矩阵部分数值是不受影响的,只需要计算新输入‘啊’的部分即可,为避免重复计算,我们可以只保存前面步骤计算得到的K、V矩阵,再与新输入计算后的向量拼接即可。
这个简化计算的方法就叫KVcache
1.7.3 MHA、MQA、GQA
现在已知KVcache会随着输入输出序列长度增加而增大,保存和加载KVcache成为一个挑战,所以提出了一些优化KVcache的方法。这里我们先只关心MHA、GQA、MQA方法:
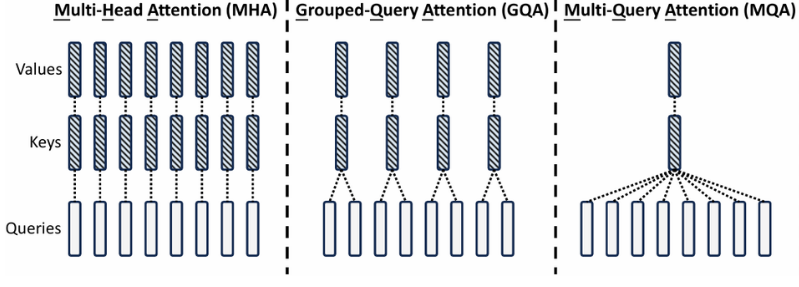
如图最左边,MHA作为最开始的注意力机制方法,对每一个Q头,都有一个KV与之对应;
如图最右边,MQA就是为了减少KVcache提出的,对所有的Q头,都有且只有一个相同的KV与之对应,这样我们只用一份KVcache就可以,但效果会大打折扣;
如图中间部分,GQA是一个折中的办法,即多个Q头共享一个KV,平衡了存储成本和最终效果。
至此,普通大模型的基础知识就介绍完成,但要想更深入理解大模型相关理论知识,入门大模型还需要更进一步。
二、大模型进阶知识
DeepSeek
我们不妨从国内最火大模型DeepSeek开始:
- 2024 年 5 月DeepSeek 宣布开源第二代混合专家(MoE)大模型 DeepSeek-V2,并使用MLA改进MOE(MHA);
- 2024 年 12 月DeepSeek 发布了第三代大模型 DeepSeek-V3,引入MTP,无辅助损失负载均衡,FP8混合精度训练,FP8精度的KV cache(MQA);
- 2025 年 1 月DeepSeek 发布开源推理模型 DeepSeek-R1,引入强化学习框架GRPO、蒸馏、多阶段训练技术,加入冷启动数据。
MoE
混合专家架构,最初是在深度学习中提出,用于解决计算资源限制大规模密集模型训练的问题,将大模型拆分为多个小模型,根据样本选择性激活一部分专家用于计算结果,从而达到增加参数量又不会过分增加计算开销的目的,一般用一个门控单元控制激活专家的数量,引入额外超参数。
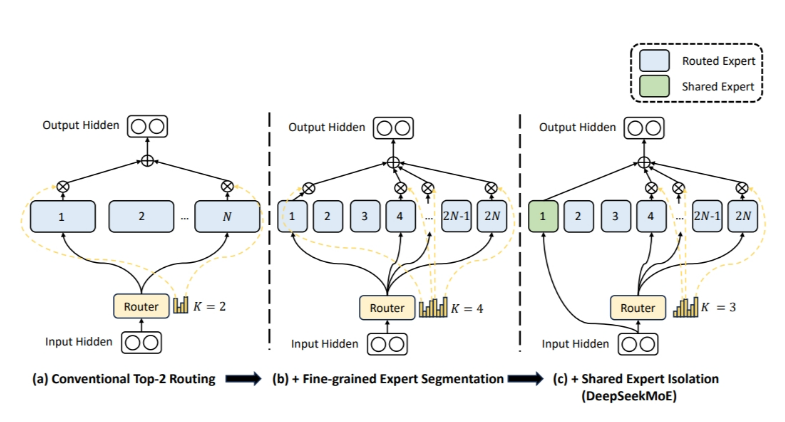
deepseek则引入细粒度专家划分和共享专家隔离策略,前者将一个专家进一步分为多个子专家,这样每个令牌可以关联更多的专家,且参数量不变;后者将一些专家标记为共享专家,在每次输出都进行激活,以捕捉共同知识、减少专家间冗余。
MLA
回到这张图:
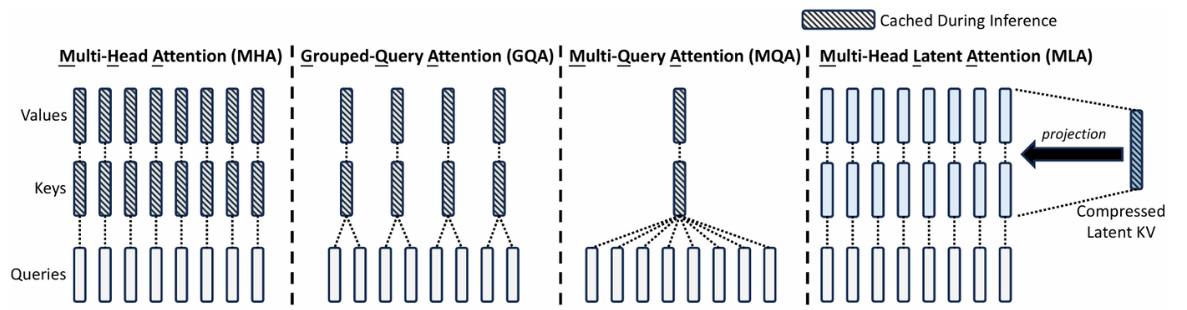
前面已经提到,KVcache太多,存储成本太高,而减少KVcache,又导致性能下降。MLA的目的便是优化KVcache来减少显存占用:
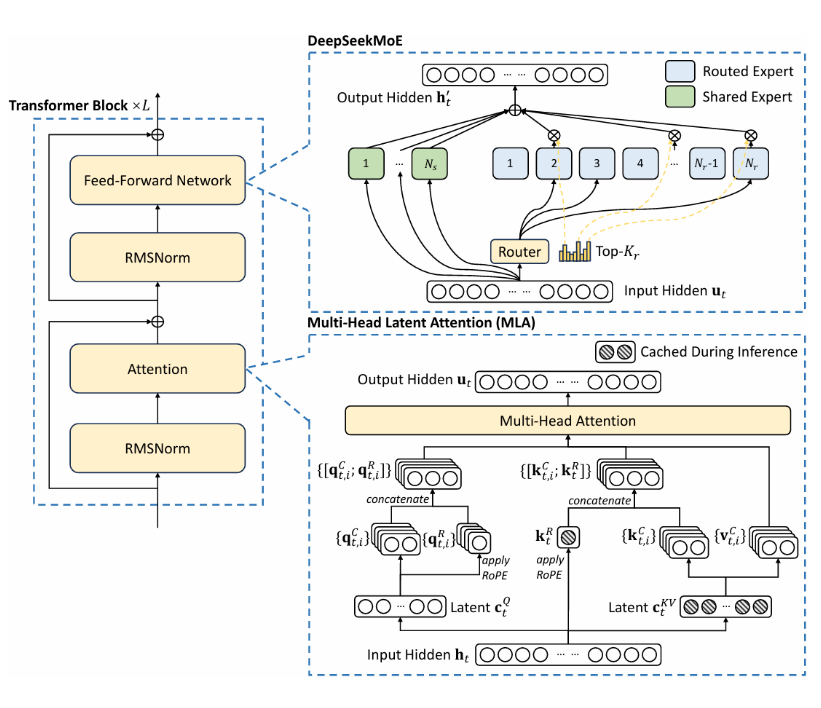
通过对键值对KV的低秩压缩,减少推理过程中缓存的KV cache(由于低秩压缩与ROPE不兼容,只能将输入拆为两部分,2/3一部分压缩,1/3一部分RoPE编码,再拼接起来),将访存密集型转化位计算密集型,充分发挥CPU算力。
deepseek也对q进行了压缩,将输入转化为两个低秩矩阵,一个用于高维映射还原K、V,一个用于还原Q,可以只用2.25倍的KVcache达到更好的效果。
MTP
大模型微调
微调方法:其实是迁移学习的一个实例,包括全面微调、参数高效微调PEFT
PEFT常用7方法:
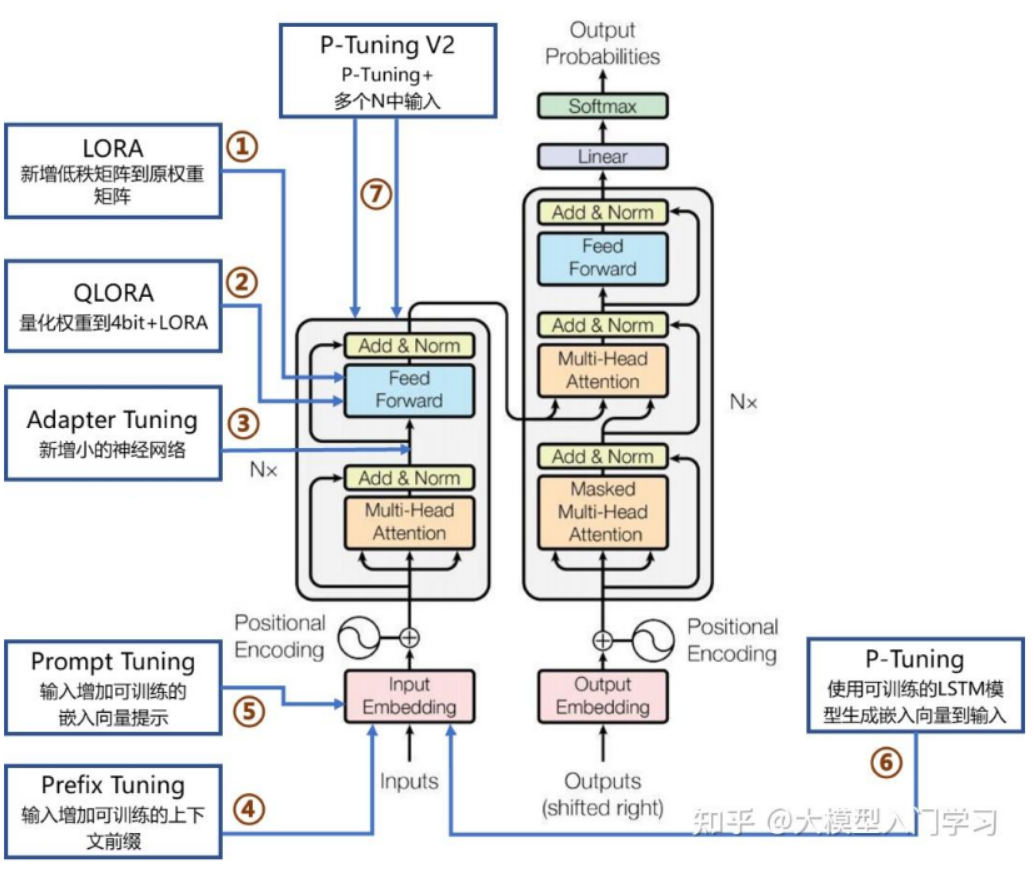
LoRA:微调预训练大模型,在模型决定性层中引入小型、低秩矩阵,避免对模型结构的大幅度修改。可插拔性强,可作为adapter加载;
Prefix/Prompt Tuning:在模型输入或隐藏层添加k个额外可训练的前缀tokens,只训练这些参数;难以优化,性能随参数规模非单调变化,引入前缀token会减少处理下游任务序列长度;
Adapter Tuning:将小神经网络层插入模型的每一层,只训练这些适配器参数。有串行和并行两种,会引入额外计算,带来推理延迟。
LoRA引入低秩AB,其秩r远小于模型中参数dim,且训练时只训练A矩阵参数,B和模型参数不变。秩r影响性能和训练时间、缩放系数alpha确保训练稳定。
LoRA开始时随机高斯分布初始化矩阵A的缩放因子,B用0初始化,A矩阵使用随机高斯分布初始化是为了保持模型的表达能力,B矩阵初始化为0是为了减少训练初期对原始模型参数的影响。
P-tuning方法开销、时间远大于LoRA,而且其需要很多数据,容易过拟合,但效果一般比lora好;
强化学习
强化学习:源自机器学习中马尔可夫决策过程,学习器(Agent)对环境施加动作action,获得状态state、奖励reward。学习任务:确定获得最大奖励的策略policy。
在自然语言处理下,大模型就是agent,人类通过设置奖励,训练模型。
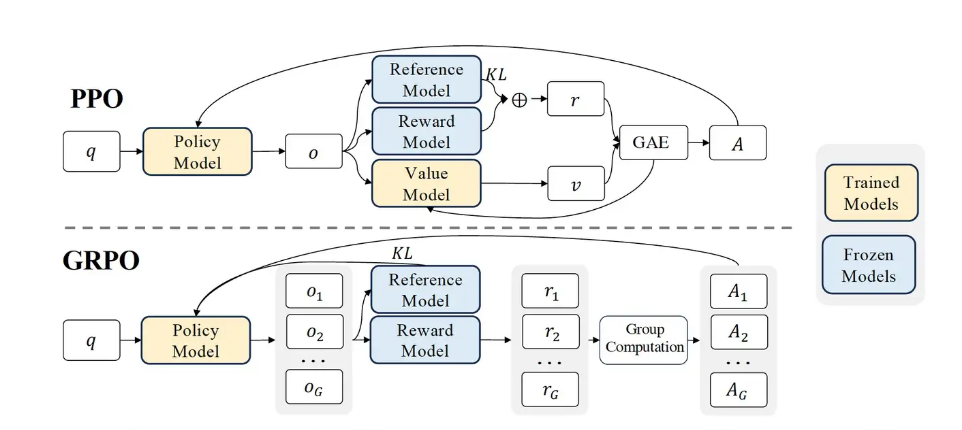
RLHF:SFT模型+奖励模型,让奖励模型对SFT模型输出打分,更新策略;
PPO:近端优化,PPO对梯度更新做了一个裁剪,防止更新过于激进,提高模型训练稳定性,其在奖励函数中引入目标函数裁剪(避免完全离开旧策略);在Hugging face实现中,还在策略模型旁边保留一个参考模型,计算KL散度,使模型生成内容不会偏离SFT模型太远。
reward model:自动评分,对生成内容有评估指标;人类评分,人工对输出内容打分;混合方式
GRPO(Group Preference Optimization):相比于PPO,一次生成多个答案,对答案进行归一化,以相对奖励r'赋给输出该token的优势函数;不再需要一个大型价值网络来估计答案间的优劣,而是由分组对比获得;r'代替PPO中大型价值网络(区分答案好坏)
RFT(Rejection Sampling Fine-tuning):也是生成多个答案,但只筛去其中低质量、错误答案,不显示区分答案差异,也不更新策略分布;少了细粒度奖励;
DPO(Direct Preference Optimization):无需单独RL优化器,但还是需要有偏好数据集;
BBPE
回到开始的tokenizer中,BPE在处理英文方面友好,但处理不了中文等多语言,于是BBPE(Byte-level Pair Encoding)被提出,其将文本转换为UTF-8字节序列后再处理,以字节对的形式进行合并,实现了真正的跨语言支持。
Tokenizer中算法
不妨再深入一点,子词算法除了BPE,还有wordPiece、Unigram。
WordPiece:与BPE流程相似,不过该算法选择能够提升语言模型概率最大的相邻子词加入词表,通过似然值变化衡量信息变化,比如将相邻x和y合并为z,则句子S的似然变化计算为:
Unigram:与前两个算法不同,不是一点点增加词表,而是从一个初始的大词表,以一定标准不断丢弃,直到词表大小满足条件。
longformer
RoPE
生成参数
三、大模型相关工具
KTransformer
参考:
大模型基础知识汇总(非常详细)零基础入门到精通-CSDN博客
Transformer模型详解(图解最完整版) - 知乎
NLP中Tokenizers总结(BPE、WordPiece、Unigram和SentencePiece)-CSDN博客
让研究人员绞尽脑汁的Transformer位置编码 - 科学空间|Scientific Spaces
探秘Transformer系列之(9)--- 位置编码分类 - 罗西的思考 - 博客园
十分钟读懂旋转编码(RoPE)
大模型基础|激活函数|从ReLU 到SwiGLU - 知乎
注意力机制进化史:从MHA、MQA、GQA、MLA到NSA、MoBA!_nsa mla-CSDN博客
DeepSeek V3推理: MLA与MOE解析 - 知乎