LLM | 论文精读 | NAACL 2025 | Clarify When Necessary:教语言模型何时该“问一句”再答!
🔍 解读 NAACL 2025 重磅论文《Clarify When Necessary》:教语言模型何时该“问一句”再答!
🧩 一、现实问题:大模型“看不懂装懂”有多危险?
我们每天用的 ChatGPT、Claude 等大型语言模型(LLMs),虽然能写代码、答题、讲故事,看似无所不能,但它们常常在“模糊输入”面前出现重大翻车:
🙋 用户提问:Who won the US Open?
🤖 模型回答:Novak Djokovic.
但其实,用户要问的是女子单打结果,正确答案是:Coco Gauff!
这个例子说明一个现实问题:
LLMs 面对不明确的问题时,往往不会“确认用户意图”,而是贸然给出一个看似合理、实则错误的回答。
这样的错误不仅仅影响用户体验,在医疗、金融、教育等高风险场景中,甚至可能带来严重后果。
于是,本文作者就提出了一个根本性问题:
模型应该学会“什么时候需要先问清楚再作答”?
📌 二、论文核心贡献概览
这篇 NAACL 2025 论文《Clarify When Necessary》来自纽约大学,提出了一个 通用的评估框架 和一个新方法 INTENT-SIM,专门用于训练和评估模型是否能判断:
👈 "这个输入到底需不需要澄清?"
并非生成问题,而是判断 “要不要问”。
论文核心内容如下:
-
✅ 提出一个“判断何时澄清”的三阶段框架
-
📊 横跨 QA(问答)、NLI(自然语言推理)和 MT(机器翻译)三个任务验证方法通用性
-
💡 设计 INTENT-SIM 方法,通过模拟用户意图,评估是否需要提问澄清
-
🏆 实验显示,INTENT-SIM 显著优于传统的模型置信度估计方法
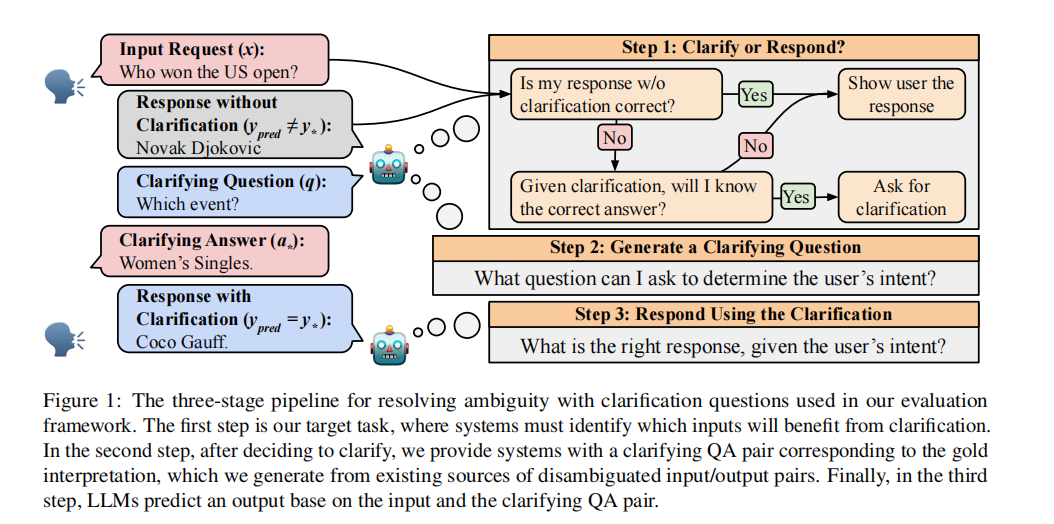
🔁 三、Clarify 三步走框架:先判断,再提问,最后回答
论文提出了一个三阶段的决策流程:
Step 1:判断是否需要澄清(核心任务)
Step 2:生成 Clarifying Question(澄清问题)
Step 3:结合用户回答,再输出最终回答这个流程非常贴近现实的 AI 交互场景,举个例子:
💬 用户提问:Who won the US Open?
🤔 Step 1:模型发现可能有歧义(男/女) → 需要澄清
❓ Step 2:提出澄清问题 → Which event are you referring to?
👤 用户回答:Women’s Singles
✅ Step 3:最终回答:Coco Gauff
通过这个三步流程,LLM 能显著降低由于“自以为懂”而引起的错误。
🔬 四、INTENT-SIM 方法:用模拟意图估不确定性
那么,如何判断“是否该澄清”?论文提出了创新性方法:INTENT-SIM,核心思想是:
🤖 “我假装跟多个用户聊一下,看他们可能想问什么,然后看看答案差不差得远。”
步骤如下:
-
模型生成一个 Clarifying Question q
-
模拟不同用户对 q 的回答(生成 a1, a2...)
-
用 NLI(自然语言推理模型)判断回答是否语义相近,进行聚类
-
统计回答分布,计算 entropy(熵)作为 u(x),熵越高,表示用户意图越不明确,越该澄清。
换句话说,INTENT-SIM 并不是看“模型知不知道”,而是看“用户可能在想什么,有没有很大的分歧”。
🧪 五、三大任务实测:QA / NLI / MT 全覆盖
作者用 INTENT-SIM 框架在以下三个典型 NLP 任务上做了实测验证:
| 任务 | 说明 | 示例 |
|---|---|---|
| QA(问答) | 用户问题可能指多个实体或含义 | Who plays Gwen Stacy? → 角色 or 演员? |
| NLI(自然语言推理) | 多种解读会影响结论 | The cake was dry like sand → figurative or literal? |
| MT(翻译) | 单句多解可能产生不同翻译 | "I love dates" → 约会?还是枣子? |
数据集:AmbigQA, AmbiEnt, DiscourseMT
模型:GPT-3, LLaMA2-7B/13B(含 Chat-finetune 与否)
衡量指标:
-
AUROC(是否准确预测出“该不该问”)
-
Performance under budget:如只允许 10% 问澄清,能不能选对那 10%
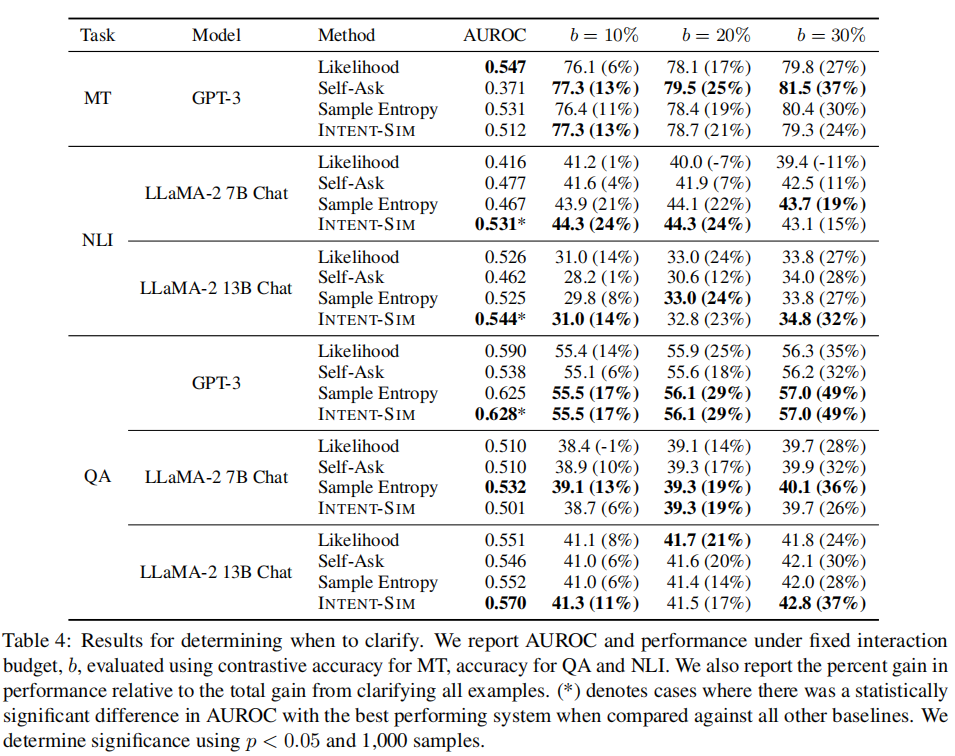
结果亮点:
-
INTENT-SIM 多数场景中表现最好
-
明显好于基于 likelihood、Self-Ask、Sample Entropy 等基线方法
-
对 LLaMA 模型提升特别明显
🧠 六、知识点拔高:INTENT-SIM 的技术优势
| 概念 | 定义 | INTENT-SIM 如何处理 |
| Epistemic Uncertainty | 模型知识盲区 | 不处理(不懂就是不懂) |
| Aleatoric Uncertainty | 输入本身就模糊 | 👍 INTENT-SIM 专门抓这个 |
INTENT-SIM 本质是:
模拟多个用户可能的理解(构建语义意图分布) → 度量这种分布是否分散(熵) → 判断需不需要澄清
相比传统方法仅看“置信度”、“输出一致性”,INTENT-SIM 更符合人类的“对话常识”:
如果我知道用户到底问什么,我就能答对;否则,我得先问清楚。
💬 七、现实意义与未来价值
🤖 哪些系统该用这个方法?
-
智能助理:Siri、小爱同学是否可以“先问一句”?
-
问答机器人:如金融客服、医疗问答,不应轻率作答
-
多轮对话 AI:选择合适时机插入澄清
📈 模型训练启示:
-
不止优化回答本身,也应训练模型判断“是否提问”
-
加入“意图模拟”机制,才能更贴近真实用户交互
🚧 局限与挑战:
-
模拟用户需多次生成,计算量略大(不过可并行)
-
多轮互动、上下文融合等仍有待研究扩展
✅ 八、总结:模糊提问时代的 AI 新素养
这篇论文为我们打开了一个新视角:
AI 不应该只是“会回答”,更要“知道何时该问”!
通过 INTENT-SIM 方法,我们可以更系统地衡量、训练和部署那些真正理解“模糊性”、并能主动消除歧义的智能系统。
对于每一个设计人机交互界面、开发 AI 系统、研究 LLM 应用的人来说:
【判断是否澄清】本身,就该成为系统能力的一部分。
未来的 LLM,不再是“永远自信”的答题机器,而是“知之为知之,不知就先问”的聪明助手。
📚 原论文:Michael J.Q. Zhang & Eunsol Choi. "Clarify When Necessary: Resolving Ambiguity Through Interaction with LMs", NAACL 2025.
如需具体算法流程、实验 prompt、数据集细节,欢迎留言,我可以继续整理一份深入阅读指南!