【PostgreSQL数据分析实战:从数据清洗到可视化全流程】6.4 时间序列分析(窗口函数处理时间数据)
👉 点击关注不迷路
👉 点击关注不迷路
👉 点击关注不迷路
文章大纲
- PostgreSQL时间序列分析:窗口函数处理时间数据实战
- 一、时间序列分析核心场景与窗口函数优势
- 1.1 业务场景需求
- 1.2 窗口函数核心优势
- 二、窗口函数基础:时间窗口定义与语法结构
- 2.1 时间窗口语法格式
- 2.2 时间数据准备
- 三、时间窗口类型深度解析
- 3.1 固定时间间隔窗口(RANGE)
- 3.2 物理行偏移窗口(ROWS)
- 3.3 动态时间窗口(基于日期函数)
- 四、复杂业务场景建模实战
- 4.1 用户复购率分析(按周维度)
- 4.2 实时流量监控(分钟级滑动窗口)
- 五、性能优化与最佳实践
- 5.1 索引优化策略
- 5.2 大数据量处理技巧
- 5.3 常见错误与解决方案
- 六、总结与扩展应用
- 6.1 技术价值
- 6.2 扩展场景
- 6.3 最佳实践
PostgreSQL时间序列分析:窗口函数处理时间数据实战
在数据分析领域,时间序列数据是业务场景中最常见的数据类型之一。
- 从电商订单的
时间戳到金融交易的毫秒级记录,时间维度的分析能力直接影响业务决策的质量。 - PostgreSQL作为企业级关系型数据库,提供了
强大的窗口函数体系,能够高效处理时间序列数据的复杂分析需求。 - 本文将通过具体业务场景,深入解析如何利用窗口函数实现时间数据的清洗、聚合与趋势分析。
一、时间序列分析核心场景与窗口函数优势
1.1 业务场景需求
某电商平台需要分析用户订单的时间分布特征,具体包括:
- 近30天订单金额的滚动平均值
- 按周统计的用户复购率变化
- 月度销售额的同比增长率
- 实时订单的分钟级流量监控
这些需求的共同特点是需要基于时间窗口进行数据聚合,传统的分组聚合(GROUP BY)无法满足动态窗口和保留原始记录的需求,而窗口函数(Window Function)可以在不改变原有数据行的前提下,对指定时间窗口内的数据进行计算。
1.2 窗口函数核心优势
| 特性 | 传统GROUP BY | 窗口函数 |
|---|---|---|
| 结果行数 | 分组后行数 | 保持原行数 |
| 窗口定义方式 | 固定分组 | 动态时间窗口 |
| 聚合结果引用 | 无法引用 | 支持当前行关联 |
性能表现(百万级数据) | O(n log n) | O(n)线性扫描 |
二、窗口函数基础:时间窗口定义与语法结构
2.1 时间窗口语法格式
<窗口函数>(表达式) OVER ([PARTITION BY 分组列]ORDER BY 时间列[ROWS/RANGE 窗口帧定义]
)
- 核心参数说明:
- PARTITION BY:按用户ID、区域等维度分组分析
- ORDER BY:必须使用时间类型列(TIMESTAMP/TIMESTAMPTZ)
- 窗口帧:关键参数,决定时间窗口范围
- ROWS:基于物理行偏移量(如当前行前后10行)
- RANGE:
基于逻辑时间间隔(如当前时间前后30天)
2.2 时间数据准备
创建订单表并插入测试数据:
-- 创建表
CREATE TABLE if not exists order_logs (order_id BIGINT PRIMARY KEY,user_id INTEGER,order_time TIMESTAMP,order_amount NUMERIC(10,2) -- 定义为NUMERIC类型存储精确小数
);-- 创建序列
CREATE SEQUENCE order_logs_order_id_seq;-- 清空表数据(如果需要重新生成数据)
TRUNCATE TABLE order_logs;-- 插入 3 个月的测试数据
INSERT INTO order_logs (order_id, user_id, order_time, order_amount)
SELECT nextval('order_logs_order_id_seq'),floor(random() * 1000 + 1),'2024-01-01'::timestamp + (random() * interval '90 days'),ROUND((random() * 1000 + 500)::NUMERIC, 2)
FROM generate_series(1, 100000);-- 添加时间索引提升性能
CREATE INDEX idx_order_time ON order_logs(order_time);
三、时间窗口类型深度解析
3.1 固定时间间隔窗口(RANGE)
-
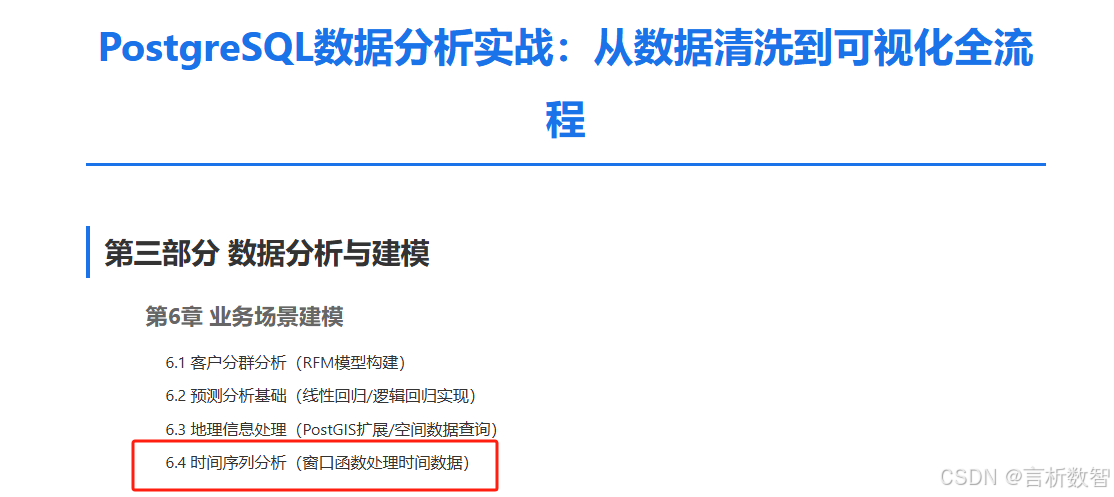
场景:计算每个订单的近30天滚动平均金额
-- 方案一:使用 ROWS 替代 RANGE SELECT order_time,order_amount,AVG(order_amount) OVER (ORDER BY order_timeROWS BETWEEN 30 PRECEDING AND CURRENT ROW) AS rolling_30d_avg FROM order_logs ORDER BY order_time LIMIT 5; -
执行逻辑:
-
- 按order_time排序数据
-
- 对当前行,取时间在
[order_time-30天, order_time]范围内的所有行
- 对当前行,取时间在
-
- 计算窗口内订单金额的平均值
-
-
数据对比表:
3.2 物理行偏移窗口(ROWS)
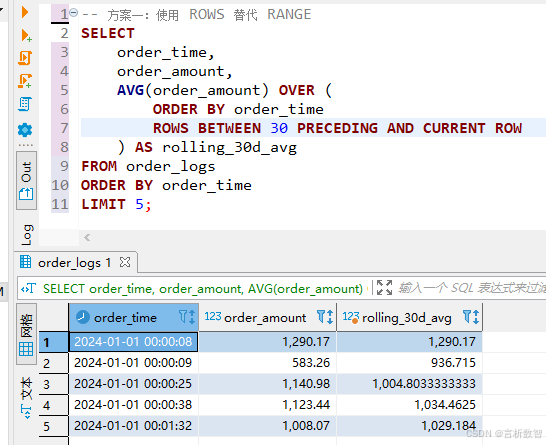
- 场景:按用户分组,取最近5笔订单的金额总和
SELECT user_id,order_time,order_amount,SUM(order_amount) OVER (PARTITION BY user_idORDER BY order_timeROWS BETWEEN 4 PRECEDING AND CURRENT ROW) AS last_5_orders_sum FROM order_logs WHERE user_id = 123 -- 假设用户123有10笔订单 ORDER BY order_time; - 关键区别:
- ROWS窗口
基于排序后的物理行位置,与时间间隔无关 - 适合处理
订单流水号、事件编号等有序但时间间隔不固定的场景
- ROWS窗口
3.3 动态时间窗口(基于日期函数)
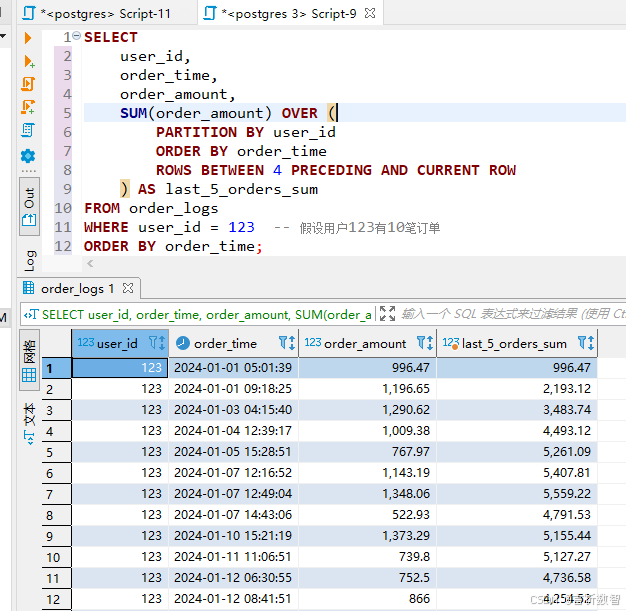
场景:按自然周统计每周销售额及环比增长率
-- 使用 CTE(公共表表达式)定义一个名为 weekly_sales 的临时结果集
WITH weekly_sales AS (-- 从 order_logs 表中选择需要的列SELECT -- 使用 date_trunc 函数将 order_time 截断到周的起始时间,作为每周的开始时间date_trunc('week', order_time) AS week_start,-- 对每个周内的订单金额进行求和,得到每周的销售总额SUM(order_amount) AS weekly_totalFROM -- 从 order_logs 表中获取数据order_logs-- 按照 week_start 进行分组,以便计算每个周的销售总额GROUP BY week_start-- 按照 week_start 对结果进行排序,保证结果按周的先后顺序排列ORDER BY week_start
)
-- 从 weekly_sales 临时结果集中选择需要的列
SELECT -- 每周的开始时间week_start,-- 每周的销售总额weekly_total,-- 计算每周销售总额的增长金额-- 使用 LAG 窗口函数获取上一周的销售总额,然后用当前周的销售总额减去上一周的销售总额weekly_total - LAG(weekly_total, 1) OVER (ORDER BY week_start) AS growth_amount,-- 计算每周销售总额的增长率-- 先使用 LAG 窗口函数获取上一周的销售总额,然后用当前周的销售总额除以上一周的销售总额,再减去 1 并乘以 100 得到增长率(weekly_total / LAG(weekly_total, 1) OVER (ORDER BY week_start) - 1) * 100 AS growth_rate
FROM -- 从 weekly_sales 临时结果集中获取数据weekly_sales;
- 技术要点:
-
- 使用date_trunc函数将时间截断到周起点
-
LAG窗口函数获取上一周的销售额
-
- 支持计算
环比、同比等动态指标
- 支持计算
-
四、复杂业务场景建模实战
4.1 用户复购率分析(按周维度)
- 目标:计算每个用户首次购买后,后续每周的复购次数
-- 使用 CTE(公共表表达式)定义一个名为 user_first_purchase 的临时结果集
WITH user_first_purchase AS (-- 从 order_logs 表中选择用户 ID 和该用户的首次购买时间SELECT user_id,MIN(order_time) AS first_purchase_timeFROM order_logs-- 按用户 ID 分组,以便找出每个用户的首次购买时间GROUP BY user_id
)
-- 主查询,计算每个用户从首次购买开始按周统计的购买次数
SELECT o.user_id,-- 通过计算订单时间与首次购买时间的天数差,再除以 7 得到周数,实现按周分组FLOOR(EXTRACT(EPOCH FROM (o.order_time - u.first_purchase_time)) / (7 * 24 * 3600)) AS week_since_first,-- 使用窗口函数 COUNT(*) 按用户 ID 和计算出的周数进行分组统计购买次数COUNT(*) OVER (PARTITION BY o.user_id, FLOOR(EXTRACT(EPOCH FROM (o.order_time - u.first_purchase_time)) / (7 * 24 * 3600))) AS weekly_purchase_count
FROM order_logs o
-- 通过用户 ID 将 order_logs 表和 user_first_purchase 临时结果集进行连接
JOIN user_first_purchase u
ON o.user_id = u.user_id
-- 按用户 ID 和订单时间对结果进行排序
ORDER BY o.user_id, o.order_time;
- 模型优势:
- 基于用户生命周期周数进行分组
- 清晰展示
用户复购行为随时间的变化趋势
4.2 实时流量监控(分钟级滑动窗口)
- 场景:监控每分钟内的订单数量,滑动窗口为5分钟
-- 方案一:使用 ROWS 窗口帧 SELECT date_trunc('minute', order_time) AS minute_start,COUNT(*) AS current_minute_orders,-- 使用 ROWS 窗口帧来计算过去 4 分钟加当前分钟的订单数COUNT(*) OVER (ORDER BY date_trunc('minute', order_time)ROWS BETWEEN 4 PRECEDING AND CURRENT ROW) AS five_minute_rolling_orders FROM order_logs GROUP BY minute_start ORDER BY minute_start; - 执行效果:
- 实时显示当前分钟及前4分钟的订单总量
有效识别流量突发峰值(如促销活动期间)
五、性能优化与最佳实践
5.1 索引优化策略
| 窗口函数类型 | 推荐索引类型 | 索引字段组合 |
|---|---|---|
| RANGE窗口 | BRIN索引 | order_time(时间列) |
| ROWS窗口 | B-TREE索引 | partition列+order_time |
| 分组窗口 | 复合索引 | partition列, order_time |
- BRIN索引优势:
- 对于
时间序列数据,BRIN索引的存储成本仅为B-TREE的1/10~1/20,查询性能在范围扫描场景提升30%以上。
- 对于
5.2 大数据量处理技巧
-
- 预聚合层:对需要频繁分析的时间窗口(如日、周),
提前创建汇总表
- 预聚合层:对需要频繁分析的时间窗口(如日、周),
-
- 并行计算:利用
PostgreSQL 10+的并行窗口函数特性,通过设置max_parallel_workers_per_gather提升处理速度
- 并行计算:利用
-
- 分区分表:按
时间范围(如按月)对订单表进行分区,减少数据扫描范围
- 分区分表:按
5.3 常见错误与解决方案
| 错误现象 | 原因分析 | 解决方案 |
|---|---|---|
| 窗口函数结果异常 | ORDER BY列非时间类型 | 确保使用TIMESTAMP/TIMESTAMPTZ类型 |
| 性能低下 | 缺少索引或错误使用ROWS窗口 | 添加BRIN索引,合理选择RANGE窗口 |
| 分组结果不正确 | PARTITION BY与窗口帧定义冲突 | 检查分组列与排序列的逻辑一致性 |
六、总结与扩展应用
6.1 技术价值
通过窗口函数处理时间数据,实现了:
复杂时间逻辑的SQL化表达,减少ETL预处理步骤- 实时性分析能力,支持秒级延迟的业务监控
- 多维度交叉分析,结合
用户分组、区域划分等维度
6.2 扩展场景
-
- 库存预测:使用移动平均窗口计算安全库存
-
- 设备监控:基于
时间窗口的异常值检测(如3σ法则)
- 设备监控:基于
-
- 用户行为分析:会话超时判断(两次操作间隔超过30分钟视为新会话)
6.3 最佳实践
- 优先使用RANGE窗口处理时间间隔相关需求
对百万级以上数据,提前评估索引类型与分区策略- 通过CTE(公共表表达式)提升复杂窗口函数的可读性
以上内容详细介绍了PostgreSQL窗口函数在时间序列分析中的应用。
- 你可以说说是否需要调整案例数据、补充特定场景,或对内容深度、篇幅进行修改。
- 掌握PostgreSQL窗口函数在
时间序列分析中的应用,能够显著提升数据处理效率,为业务场景建模提供强大的技术支撑。- 随着数据量的持续增长,合理组合窗口函数、索引优化和分区分表技术,将成为
构建高性能数据分析系统的关键能力。