【学习笔记】机器学习(Machine Learning) | 第五章(4)| 分类与逻辑回归
机器学习(Machine Learning)
简要声明
基于吴恩达教授(Andrew Ng)课程视频
BiliBili课程资源
文章目录
- 机器学习(Machine Learning)
- 简要声明
- 四、梯度下降实现
- 梯度下降算法
- 参数更新规则
- 偏导数计算
- 梯度下降步骤
- 梯度下降的实现细节
- 梯度下降的伪代码
- 向量化实现
- 特征缩放
一、逻辑回归的基本原理
二、决策边界
三、代价函数
四、梯度下降实现
梯度下降算法
梯度下降是一种常用的优化算法,用于最小化代价函数。在逻辑回归中,我们使用梯度下降来更新模型参数 w j w_j wj 和 b b b,以最小化代价函数 J ( w → , b ) J(\overrightarrow{w}, b) J(w,b)。
参数更新规则
梯度下降的参数更新规则如下:
w j = w j − α ∂ ∂ w j J ( w → , b ) w_j = w_j - \alpha \frac{\partial}{\partial w_j} J(\overrightarrow{w}, b) wj=wj−α∂wj∂J(w,b)
b = b − α ∂ ∂ b J ( w → , b ) b = b - \alpha \frac{\partial}{\partial b} J(\overrightarrow{w}, b) b=b−α∂b∂J(w,b)
其中, α \alpha α 是学习率,控制每次更新的步长。
偏导数计算
对于逻辑回归,代价函数 J ( w → , b ) J(\overrightarrow{w}, b) J(w,b) 对 w j w_j wj 和 b b b 的偏导数分别为:
∂ ∂ w j J ( w → , b ) = 1 m ∑ i = 1 m ( f w → , b ( x → ( i ) ) − y ( i ) ) x j ( i ) \frac{\partial}{\partial w_j} J(\overrightarrow{w}, b) = \frac{1}{m} \sum_{i=1}^{m} (f_{\overrightarrow{w}, b}(\overrightarrow{x}^{(i)}) - y^{(i)}) x_j^{(i)} ∂wj∂J(w,b)=m1i=1∑m(fw,b(x(i))−y(i))xj(i)
∂ ∂ b J ( w → , b ) = 1 m ∑ i = 1 m ( f w → , b ( x → ( i ) ) − y ( i ) ) \frac{\partial}{\partial b} J(\overrightarrow{w}, b) = \frac{1}{m} \sum_{i=1}^{m} (f_{\overrightarrow{w}, b}(\overrightarrow{x}^{(i)}) - y^{(i)}) ∂b∂J(w,b)=m1i=1∑m(fw,b(x(i))−y(i))
梯度下降步骤
- 初始化参数:随机初始化 w j w_j wj 和 b b b。
- 重复直到收敛:
- 计算当前参数下的代价函数值。
- 计算每个参数的梯度。
- 更新参数 w j w_j wj 和 b b b。
- 终止条件:
- 代价函数的变化小于阈值:
当连续两次迭代的代价函数值变化小于某个预设的阈值(如 1 0 − 6 10^{-6} 10−6)时,认为算法已经收敛。 - 梯度的范数小于阈值:
当梯度向量的范数(如 L2 范数)小于某个预设的阈值时,认为算法已经收敛。 - 达到最大迭代次数:
如果达到预设的最大迭代次数仍未收敛,则停止迭代。
梯度下降的实现细节
梯度下降的伪代码
Initialize w_j and b randomly
Repeat {Compute gradients dw_j and dbUpdate w_j = w_j - alpha * dw_jUpdate b = b - alpha * db
} until convergence
向量化实现
为了提高计算效率,梯度下降可以向量化实现,即同时更新所有参数:
w → = w → − α 1 m X → T ( f w → , b ( X → ) − y → ) \overrightarrow{w} = \overrightarrow{w} - \alpha \frac{1}{m} \overrightarrow{X}^T (f_{\overrightarrow{w}, b}(\overrightarrow{X}) - \overrightarrow{y}) w=w−αm1XT(fw,b(X)−y)
b = b − α 1 m ∑ i = 1 m ( f w → , b ( x → ( i ) ) − y ( i ) ) b = b - \alpha \frac{1}{m} \sum_{i=1}^{m} (f_{\overrightarrow{w}, b}(\overrightarrow{x}^{(i)}) - y^{(i)}) b=b−αm1i=1∑m(fw,b(x(i))−y(i))
特征缩放
在梯度下降中,特征缩放(如标准化或归一化)可以加速收敛。常见的特征缩放方法包括:
- 标准化:将特征值转换为均值为 0,标准差为 1 的分布。
- 归一化:将特征值缩放到 [0, 1] 或 [-1, 1] 区间。
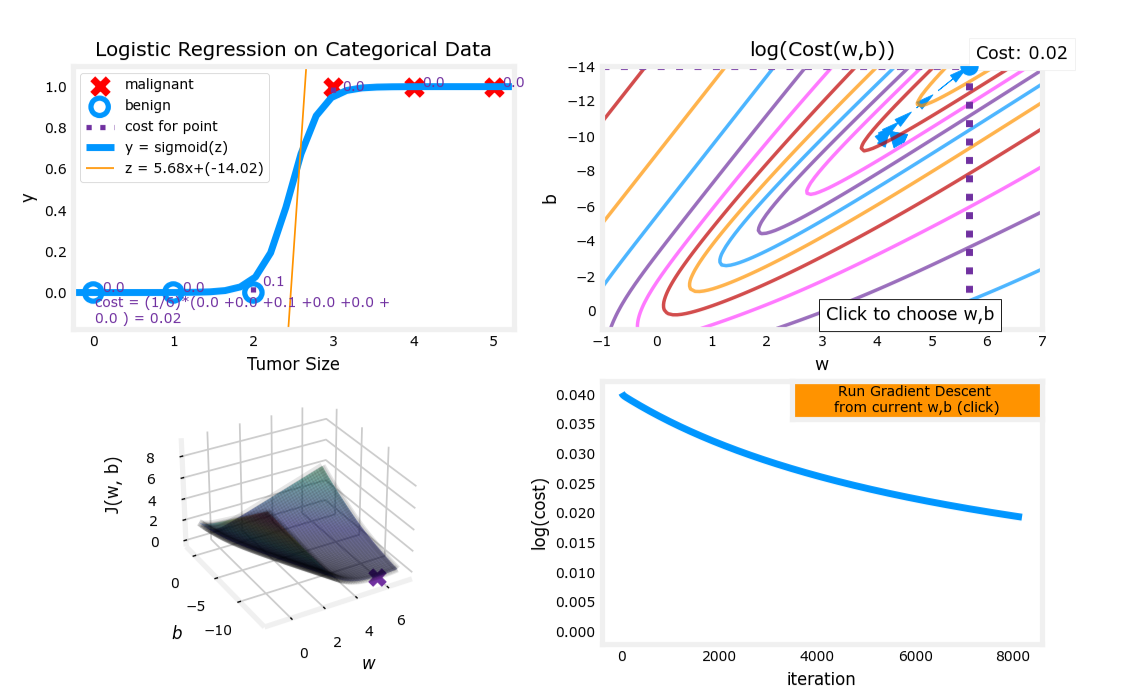
可视化梯度下降示例
end