Transformer架构(详解)
🍋🍋AI学习🍋🍋
🔥系列专栏: 👑哲学语录: 用力所能及,改变世界。
💖如果觉得博主的文章还不错的话,请点赞👍+收藏⭐️+留言📝支持一下博主哦🤞
Transformer采用的是一个非常经典的“编码-解码”(Encoder-Decoder)架构,其核心思想是:
编码器:将输入序列压缩成一个富含语义信息的上下文矩阵(Context Matrix)。
解码器:根据这个上下文矩阵,像“猜谜”一样,一步步自回归地生成目标序列。
第一步:编码器(Encoder)的工作流程
编码器的目的是理解和编码输入句子:
1. 输入处理 (Input Processing)
输入:
["I", "love", "you"]输入嵌入(Input Embedding):每个单词通过一个可训练的嵌入层(Embedding Layer)被转换成一个512维的向量(假设
d_model=512)。I-> 向量[0.1, 0.3, -0.2, ..., 0.5](512维)love-> 向量[-0.2, 0.4, 0.1, ..., -0.3]you-> 向量[0.5, -0.1, 0.2, ..., 0.4]
位置编码(Positional Encoding):因为Transformer没有RNN的递归结构,它需要额外注入单词的位置信息。通过正弦和余弦函数生成一个位置编码向量,直接加到词嵌入向量上。
Pos 0(I) +位置编码向量1-> 新向量1Pos 1(love) +位置编码向量2-> 新向量2Pos 2(you) +位置编码向量3-> 新向量3
这样,输入变成了一个矩阵,包含了每个词的信息和位置信息。
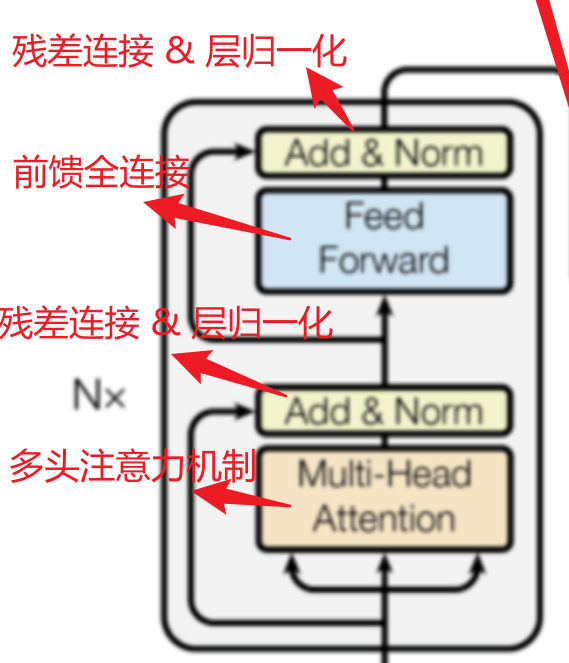
2. 编码器层 (Encoder Layers) - 核心计算
编码器由N个(原论文是6个,但不是固定的)完全相同的层堆叠而成。每一层都包含两个子层:
a) 多头自注意力机制 (Multi-Head Self-Attention)
目的:让序列中的每一个词都和其他所有词进行交互,从而根据上下文来理解当前词。
过程:以“I”这个词为例。
- 它会产生一个查询(Query)。
- 序列中的每个词(包括“I”自己)都会产生一个键(Key)和值(Value)。
- “I”的Query会与所有词的Key进行相似度匹配,计算出注意力分数。
- 分数经过Softmax变成权重,然后对所有的Value进行加权求和。
- 结果:新的“I”的表示向量,不再是一个孤立的词,而是一个融入了“love”和“you”信息的向量。它知道自己是“被谁爱”的主体。
“love”和“you”也经历相同的过程。最终,每个词都得到了一个包含全局上下文信息的新向量表示。
b) 前馈神经网络 (Feed-Forward Network)
目的:进一步加工自注意力层的输出,引入非线性变换,增加模型的表达能力。
过程:每个词经过一个全连接层(ReLU激活) + 另一个全连接层。
特点:这个操作对序列中的每个位置是独立且相同的。
c) 残差连接与层归一化 (Add & Norm)
每个子层(自注意力、前馈网络)都被一个残差连接包围,并紧跟一个层归一化(LayerNorm)。
作用:
残差连接:缓解梯度消失问题,让模型可以训练得更深。
层归一化:稳定训练过程,加速收敛。
经过6层(一般是6层处理之后的结果会比较好的,当然也可以选择其它数量)这样的处理,输入序列 ["I", "love", "you"] 被编码成了一个强大的上下文矩阵(图中编码器的最终输出)。这个矩阵的每一行都代表一个单词,但每个单词的表示都已经被整个句子的信息所充分丰富。
第二步:解码器(Decoder)的工作流程
解码器的目的是根据编码器的信息生成目标句子。它是一个自回归模型,意味着它一个一个词地生成,每次生成时都会将之前生成的词作为输入。
注意!!!!!!
在训练时,我们有完整的输入序列(“I love you”)和完整的目标序列(“<s> 我 爱 你 </s>”)。
为了高效地并行训练,我们会一次性把整个目标序列(尽管要偏移一位)喂给解码器,但同时使用掩码来确保自回归属性。这也就是:Teacher Forcing。也只有在训练阶段才会有Teacher Forcing。
但是,在预测时,我们没有目标序列,只有一个起始符。就会像上面说的一样进行自回归的生成。
1. 输入处理 (Output Processing)
初始输入:在训练时,解码器的输入是目标句子的起始符
<start>,后面接着移位后的真实输出["我", "爱"]。输出嵌入与位置编码:和编码器一样,这些词会被转换成向量并加上位置编码。
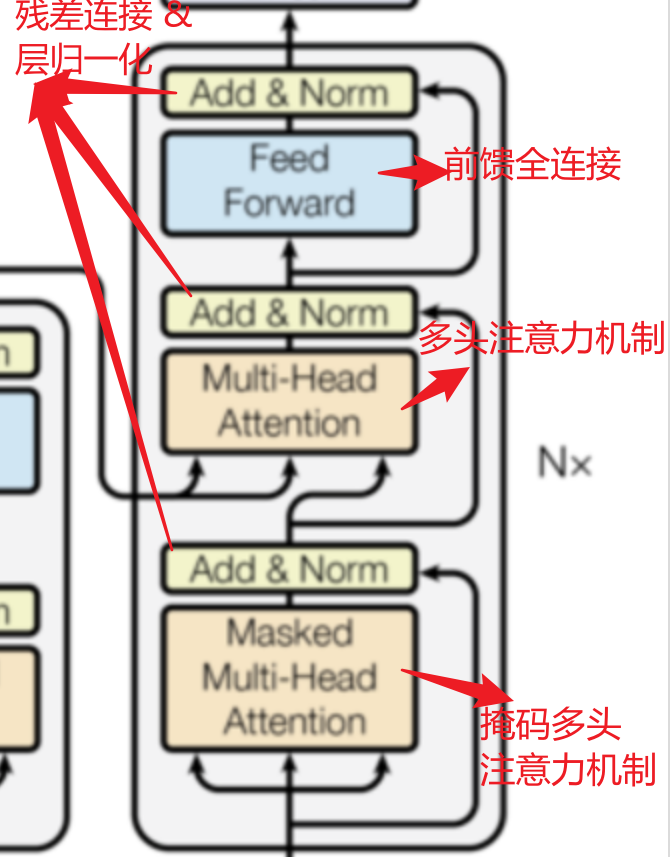
2. 解码器层 (Decoder Layers) - 核心计算
解码器也由N个(原论文是6个)相同的层堆叠而成。每一层包含三个子层:
a) 掩码多头自注意力机制 (Masked Multi-Head Self-Attention)
目的:让解码器在生成第t个词时,只能关注到已经生成了的前t-1个词,而不能“偷看”未来的词。这是保证模型能有效用于推理的关键。
实现:通过一个look-ahead mask(前瞻掩码) 来实现。它在计算注意力分数后,将所有未来位置的分数设置为负无穷(-inf),这样经过Softmax后,这些位置的权重就变成了0。
b) 编码器-解码器注意力机制 (Encoder-Decoder Attention)
这是连接编码器和解码器的桥梁!
Query:来自解码器上一子层的输出。
Key 和 Value:来自编码器的最终输出(那个强大的上下文矩阵)。
过程:解码器在生成“我”这个词时,会用自己的Query去“询问”编码器:“关于源句子‘I love you’,我現在应该输出什么?”。
注意力机制会计算解码器当前状态(想生成词)和编码器所有输出状态(源句子信息)的相关性。
例如,生成“我”时,注意力可能会非常集中在源词的“I”上。
生成“爱”时,注意力可能会集中在“love”上。
生成“你”时,注意力可能会集中在“you”上。
结果:解码器成功地将源语言的信息“对齐”并“注入”到了生成过程中。
c) 前馈神经网络 (Feed-Forward Network)
与编码器中的完全相同,进一步处理信息。
同样,每个子层都伴随着残差连接和层归一化。
3. 最终输出 (Final Output)
解码器最后一层的输出是一个向量序列(每个对应位置一个向量)。
这个向量通过一个线性层(Linear Layer) 把它投影到目标词汇表大小的维度(例如3万个中文词)。
然后通过一个 Softmax层,将其转换为一个概率分布。
例如,在第一步,概率分布中“我”这个词的概率可能是0.85,“他”是0.1,其他词概率很低。
模型会选择概率最大的词(“我”)作为第一个输出。
第三步:迭代生成与结束
将生成的“我”字拼接到解码器的输入后面。
新的输入变成了
[<start>, "我"],重复整个解码过程。这次模型会输出“爱”的概率最高。
再将“爱”拼接到输入后:
[<start>, "我", "爱"],重复过程,输出“你”。最终,模型会生成一个结束符
<end>,标志着生成过程完毕。
最终,解码器输出了序列:["我", "爱", "你", "<end>"]。翻译完成!
三、流程梳理:
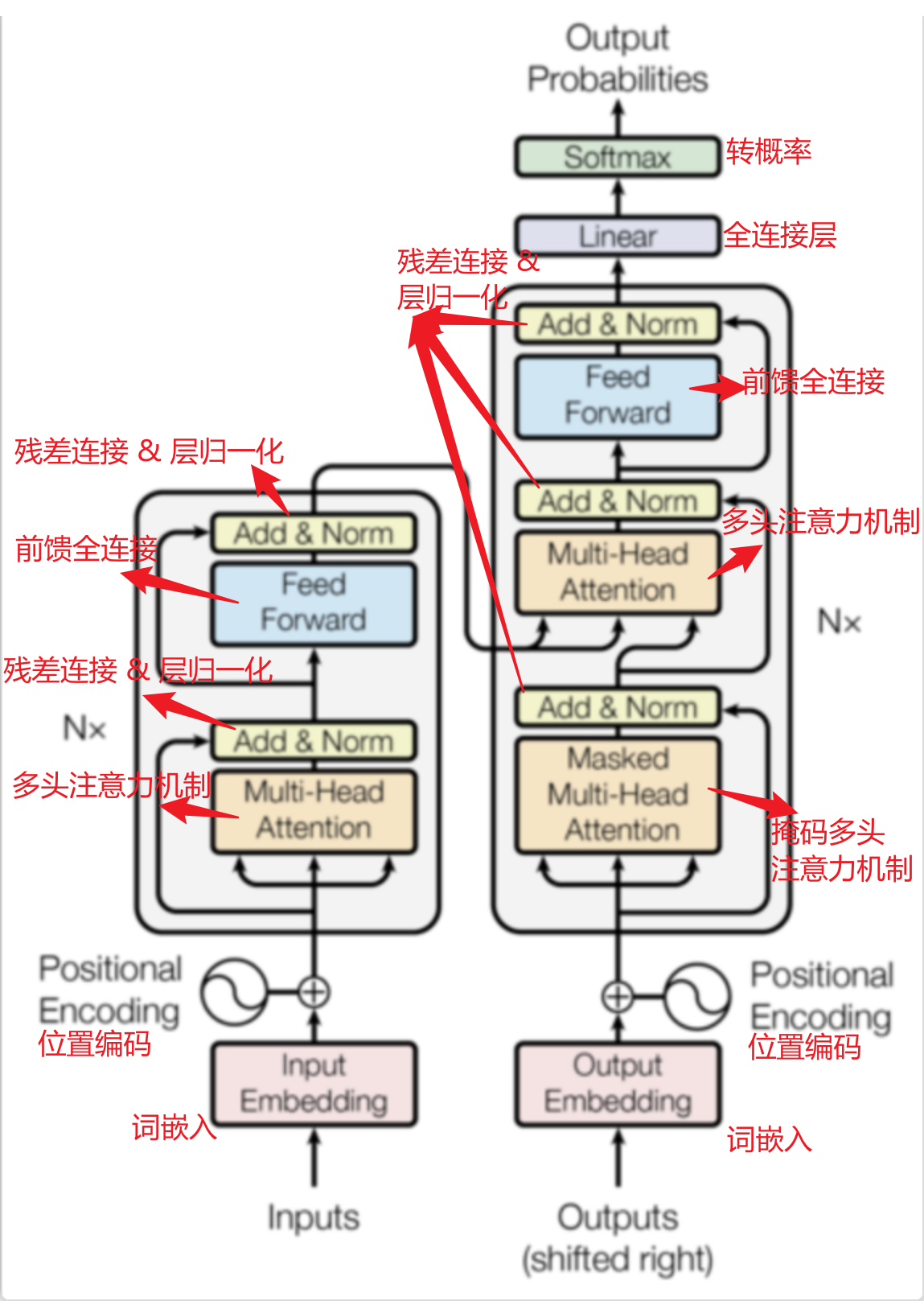
Transformer的编解码过程就像一个车模型拆解在组装的过程,只不过需要将编码器理解成一个单独的拆解,解码器才是重组的过程,最终组装成一个新的车模型:
编码器(主理解):它的工作就是精读和理解源句子。它反复推敲句子中的每个词,并让每个词都在所有其他词的上下文背景下得到充分理解,最终形成一份详尽的“阅读理解报告”(上下文矩阵)。
解码器(主生成):它的工作是根据报告来创作目标句子。它一边写,一边要遵守两个规则:
规则一(不剧透):写当前这句话时,不能看后面还没写的内容(掩码自注意力)。
规则二(紧扣主题):每写一个词,都要反复去查阅编码器的那份“报告”,确保自己写的内容准确反映了源句子的意思(编码-解码注意力)。