MySQL运维补充
一、日志
1、错误日志
MySQL 错误日志是 MySQL 服务器记录其运行过程中发生的错误、警告和其他重要事件的日志文件。它是诊断 MySQL 问题的首要资源。
错误日志的位置取决于操作系统和 MySQL 配置:
Linux/Unix 默认位置:通常位于
/var/log/mysqld.log或/var/log/mysql/error.logWindows 默认位置:通常在 MySQL 数据目录下,名为
hostname.err自定义位置:可以在
my.cnf或my.ini配置文件中通过log_error参数指定
# 查看错误日志所处位置SHOW VARIABLES LIKE 'log_error';-- 或使用模糊匹配找到错误日志:log_errorSHOW VARIABLES LIKE '%log_error%';2、二进制日志
二进制日志(Binary Log,简称 binlog)是 MySQL 中最重要的日志之一,它记录了所有对数据库的修改操作(DDL 和 DML),但不包括查询语句(SELECT)。
2.1、主要作用
数据复制:主从复制的核心组件,从库通过重放主库的二进制日志来实现数据同步
数据恢复:可用于时间点恢复(Point-in-Time Recovery)
审计:记录所有对数据库的修改操作
2.2、格式特点
MySQL服务器中提供了多种格式来记录二进制日志,具体格式及特点如下:
| 日志格式 | 含义 |
|---|---|
| STATEMENT | 基于SQL语句的日志记录,记录的是SQL语句,对数据进行修改的SQL都会记录在日志文件中。 |
| ROW | 基于行的日志记录,记录的是每一行的数据变更。(默认) |
| MIXED | 混合了STATEMENT和ROW两种格式,默认采用STATEMENT,在某些特殊情况下会自动切换为ROW进行记录。 |
要想将日志格式设置为STATEMENT需编辑 my.cnf 配置文件
# 进入容器,但不登录docker exec -it <你的容器名> bash# 编辑文件vi /etc/my.cnf-- 在文件内部加上 binlog_format = STATEMENT 即可# 重启容器docker restart <你的容器名>2.3、基本语法
# 模糊匹配查看二进制文件show variables like '%log_bin%';# 查看二进制日志状态show variables like 'log_bin';# 查看所有二进制日志SHOW BINARY LOGS;-- 如果是在本地下载的MySQL,则直接cd即可cd /var/lib/mysql-- 如果是 docker 内安装的 MySQL 则需要先进入容器再cd-- 注意是进入容器,不需要登录容器,登录容器不可使用cddocker exec -it mysql1 bashcd /var/lib/mysql# 之后ls查看发现有binlog开头,数字结尾的就是二进制日志ls-- 当然也可以执行以下语句ls -l /var/lib/mysql/binlog.*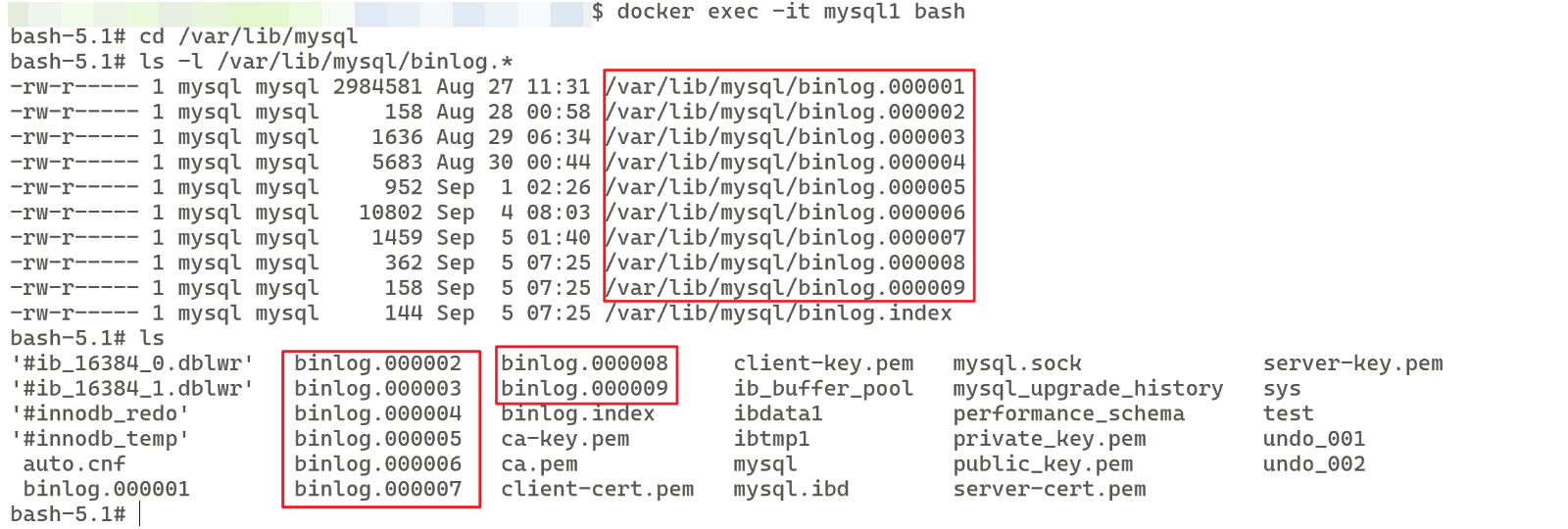
2.4、查看二进制文件
由于日志是以二进制方式存储的,不能直接读取,需要通过二进制日志查询工具 mysqlbinlog 来查看,具体语法:
mysqlbinlog [参数选项] <logfilename>参数选项:
d:指定数据库名称,只列出指定的数据库相关操作。o:忽略掉日志中的前 n 行命令。v:将行事件(数据变更)重构为 SQL 语句。w:将行事件(数据变更)重构为 SQL 语句,并输出注释信息。
2.5、删除日志
对于比较繁忙的业务系统,每天生成的 binlog 数据巨大,如果长时间不清除,将会占用大量磁盘空间。可以通过以下几种方式清理日志:
| 指令 | 含义 |
|---|---|
reset master | 删除全部 binlog 日志,删除之后,日志编号将从 binlog.000001 重新开始。 |
purge master logs to 'binlog.******' | 删除指定编号之前的所有日志。 |
purge master logs before 'yyyy-mm-dd hh24:mi:ss' | 删除指定时间之前产生的所有日志。 |
不想手动删除也可以,由于MySQL的配置文件提供自动删除期限,到期即自动删除
# 查看过期时间show variables like '%binlog_expire%'3、查询日志
查询日志中记录了客户端的所有操作语句,而二进制日志不包含查询数据的 SQL 语句。默认情况下,查询日志是未开启的。如果需要开启查询日志,可以设置以下配置:
# 查看查询日志show variables like 'general%';-- 预计输出+------------------+-------------------------+| Variable_name | Value |+------------------+-------------------------+| general_log | OFF || general_log_file | /var/lib/mysql/loo |+------------------+-------------------------+2 rows in set (0.01 sec)修改 MySQL 的配置文件 /etc/my.cnf 文件,添加如下内容:
# 该选项用来开启查询日志,可选值:0 或者 1;0 代表关闭,1 代表开启general_log=1# 设置日志的文件名,如果没有指定,默认的文件名为 host_name.loggeneral_log_file=mysql_query.log4、慢查询日志
慢查询日志记录了所有执行时间超过参数 long_query_time 设置值,并且扫描记录数不小于 min_examined_row_limit 的所有 SQL 语句的日志,默认未开启。long_query_time 默认为 10 秒,最小为 0,精度可以到微秒。
# 打开慢查询日志slow_query_log=1# 设置执行时间参数(s),即超过这个时间即视为慢long_query_time=2默认情况下,不会记录管理语句,也不会记录不使用索引进行查找的查询。可以通过以下参数更改此行为:
# 记录执行较慢的管理语句log_slow_admin_statements=1# 记录执行较慢的未使用索引的语句log_queries_not_using_indexes=1以上都是对 etc/my.cnf 配置文件进行编辑
二、主从复制
MySQL 主从复制(Replication)是一种数据复制技术,允许将一个 MySQL 数据库服务器(主服务器)的数据复制到一个或多个 MySQL 数据库服务器(从服务器)
1、原理实现
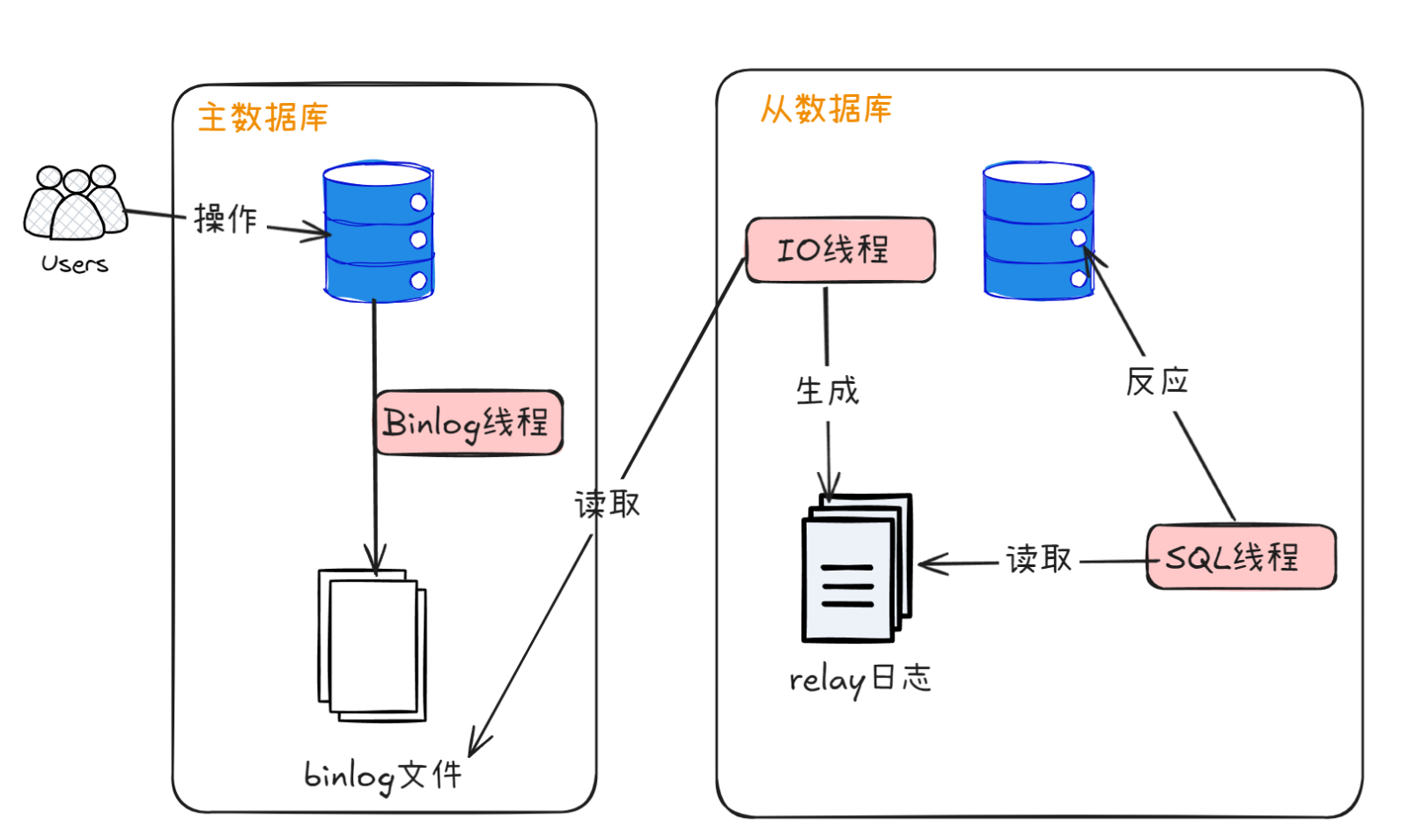
MySQL 主从复制基于以下三个线程实现:
主服务器 Binlog 线程:记录所有更改数据库的语句到二进制日志(binary log)
从服务器 I/O 线程:从主服务器请求二进制日志变更
从服务器 SQL 线程:执行从主服务器获取的二进制日志中的变更
2、搭建主从复制
准备工作如关闭防火墙就不演示了
2.1、主库配置
①、配置文件
# 主服务器 my.cnf 配置# 唯一服务器IDserver-id = 1 # 是否只读,1是只读,0是可读可写read_only = 0# 启用二进制日志log_bin = mysql-bin # 可选:默认 binlog_format 是 ROW 格式,如果修改了才进行下一步binlog_format = ROW # 可选:指定要复制的数据库binlog_do_db = database_name # 可选:指定要忽略的数据库binlog_ignore_db = database_name 重启容器以更新配置
②、创建复制用户
# 创建用户 test1,可在任意主机以自定义密码访问 MySQL 服务CREATE USER '<自定义用户名,我以test1为例>'@'%' IDENTIFIED BY '<自定义密码>';# 给 test1 用户分配主从复制权限GRANT REPLICATION SLAVE ON *.* TO '<自定义用户名,我以test1为例>'@'%';# 查看二进制日志坐标show binary log status;2.2、从库配置
①、配置文件
# 从服务器 my.cnf 配置# 唯一服务器IDserver-id = 2 # 是否只读,1是只读,0是可读可写(只是普通用户只读,super可读写)read_only = 1# super_read_only = 1 (将超级管理员也设置为只读)# 中继日志relay_log = mysql-relay-bin # 可选:从服务器也可以开启二进制日志 log_bin = mysql-bin # 可选:指定要复制的数据库binlog_do_db = database_name # 可选:指定要忽略的数据库binlog_ignore_db = database_name 重启容器以更新配置
②、启动从库主从复制
# 从库执行CHANGE MASTER TOMASTER_HOST='<主库地址>',MASTER_USER='<自定义用户名,我以test1为例>',MASTER_PASSWORD='<自定义密码>',# 查看二进制日志左标# show binary log status;# 以上输出信息即要记录的文件名和位置值MASTER_LOG_FILE='记录的文件名',MASTER_LOG_POS=记录的位置值;# 开启主从复制START SLAVE;SHOW SLAVE STATUS\G# 检查 Slave_IO_Running 和 Slave_SQL_Running 是否为 Yes三、分库分表
分库分表是解决数据库性能瓶颈和存储容量问题的常用方案,通过将数据分散到多个数据库或表中,提高系统的整体处理能力。即随着发展和用户请求量增加,单库压力不断增大导致最终出现问题,所以要分库分表。
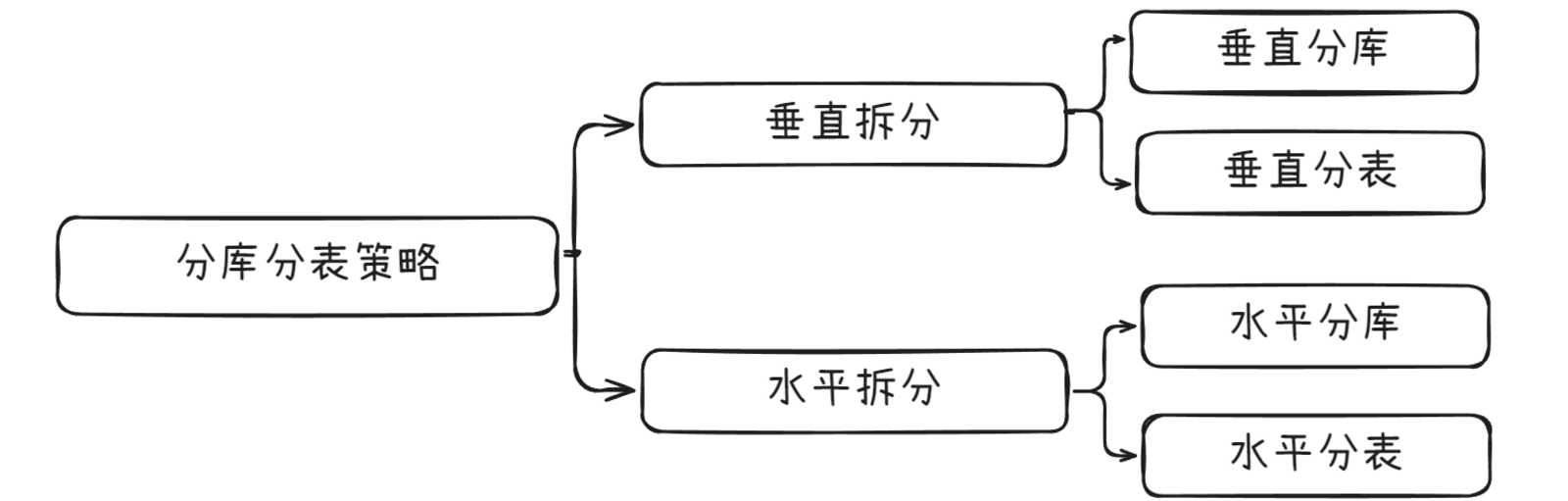
1、分库分表策略
1.1、 水平拆分(横向拆分)
按照数据行拆分,将同一表的不同行分散到不同库/表
例如:按用户ID范围、时间范围、哈希值等拆分
1.2.、垂直拆分(纵向拆分)
按照列拆分,将不同字段分散到不同库/表
例如:将常用字段和不常用字段分开,将大字段单独存放
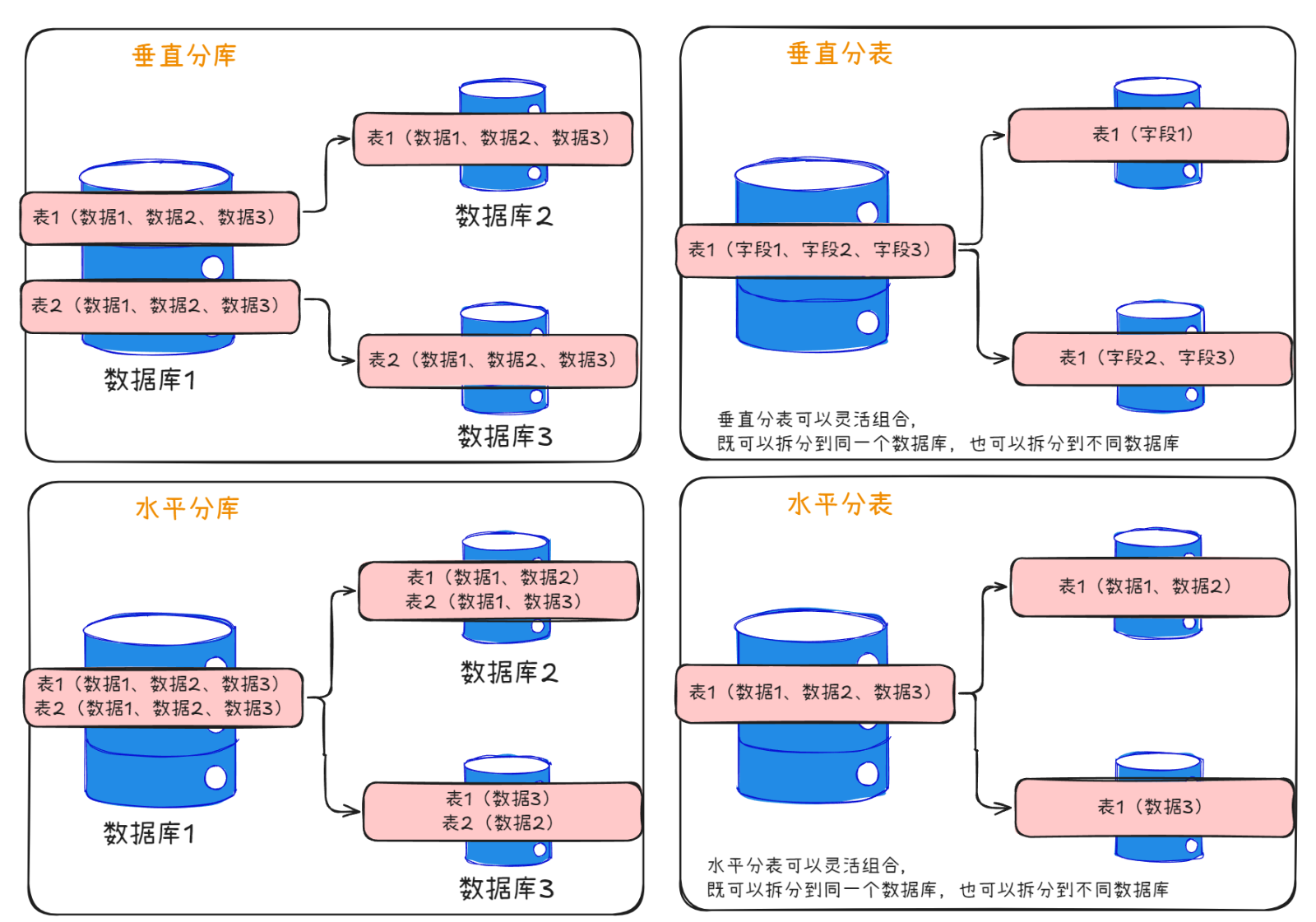
可见垂直拆分类似微服务化
2、常见分片策略
1. 哈希分片
# 例如按用户ID哈希取模shard_id = user_id % 42. 范围分片
# 例如按时间范围shard_2023: 2023年数据shard_2024: 2024年数据3. 列表分片
# 例如按地区shard_north: 北京、天津、河北shard_south: 广东、广西、海南4. 复合分片
结合多种分片策略,如先按地区再按时间
3、分库分表实现方式
1. 应用层实现
在代码中直接处理分库分表逻辑
优点:灵活可控
缺点:侵入性强,维护成本高
2. 中间件实现
常用中间件:
ShardingSphere(前Sharding-JDBC)
MyCat
TDDL(阿里)
Vitess(YouTube)
四、读写分离
读写分离是数据库架构设计中常用的性能优化手段,通过将读操作和写操作分发到不同的数据库节点,显著提升数据库集群的整体吞吐量。
即目的是减小单台数据库压力,写走主数据库,读走从数据库。
读写分离是基于主从复制的二进制文件和三大进程实现的,其最终实现方案可使用中间件(如:MyCat、ShardingSphere)或数据库原生等等实现