精读:《VideoMAE V2: Scaling Video Masked Autoencoders with Dual Masking》
文章目录
- 作者与研究机构
- 发表会议
- Abstract
- 1. Introduction
- 2. Related Work
- 3. VideoMAE V2
-
- 3.1. VideoMAE Revisited
- 3.2. Dual Masking for VideoMAE
- 3.3. Scaling VideoMAE
- 4. Experiments
-
- 4.1. Implementation and Downstream Tasks
- 4.2. Main Results
- 4.3. Performance on Downstream Tasks
- 5. Conclusion and Discussion
作者与研究机构
-
主要作者及单位:
- 第一作者:王利民 (Limin Wang) 和 黄炳昆 (Bingkun Huang) 为共同第一作者。
- 通讯作者:乔宇 (Yu Qiao) 教授是上海人工智能实验室的首席科学家。
-
合作机构:
- 南京大学新软件技术国家重点实验室 (State Key Laboratory for Novel Software Technology, Nanjing University)
- 上海人工智能实验室 (Shanghai AI Lab)
- 中国科学院深圳先进技术研究院 (Shenzhen Institute of Advanced Technology, CAS)
发表会议
最初于2023年3月在预印本网站 arXiv 上发布。随后,被2023年IEEE/CVF计算机视觉与模式识别会议 (Conference on Computer Vision and Pattern Recognition, CVPR) 正式接收并发表。
Abstract
“Scale is the primary factor for building a powerful foundation model that could well generalize to a variety of downstream tasks. However, it is still challenging to train video foundation models with billions of parameters.”
- 解析:
- 背景 (Scale is the primary factor…): 人工智能领域的共识:模型规模是构建强大基础模型的关键。规模越大,模型的泛化能力通常越强,能更好地适应各种下游任务。
- 挑战 (…it is still challenging…): 作者指出了将这一成功范式应用于视频领域时遇到的核心瓶颈——训练十亿参数级别的视频模型极其困难。点明了本文要解决的根本问题。
“This paper shows that video masked autoencoder (VideoMAE) is a scalable and general self-supervised pre-trainer for building video foundation models. We scale the VideoMAE in both model and data with a core design.”
- 解析:
- 技术选型 (VideoMAE is a scalable…): 作者认为 VideoMAE 框架具备成为视频基础模型的潜力,因为它具有良好的“可扩展性”和“通用性”。
- 核心策略 (We scale… in both model and data…): 论文的扩展路径非常明确,从两个维度同时入手:一是模型规模(训练更大的模型),二是数据规模(使用更多的数据)。
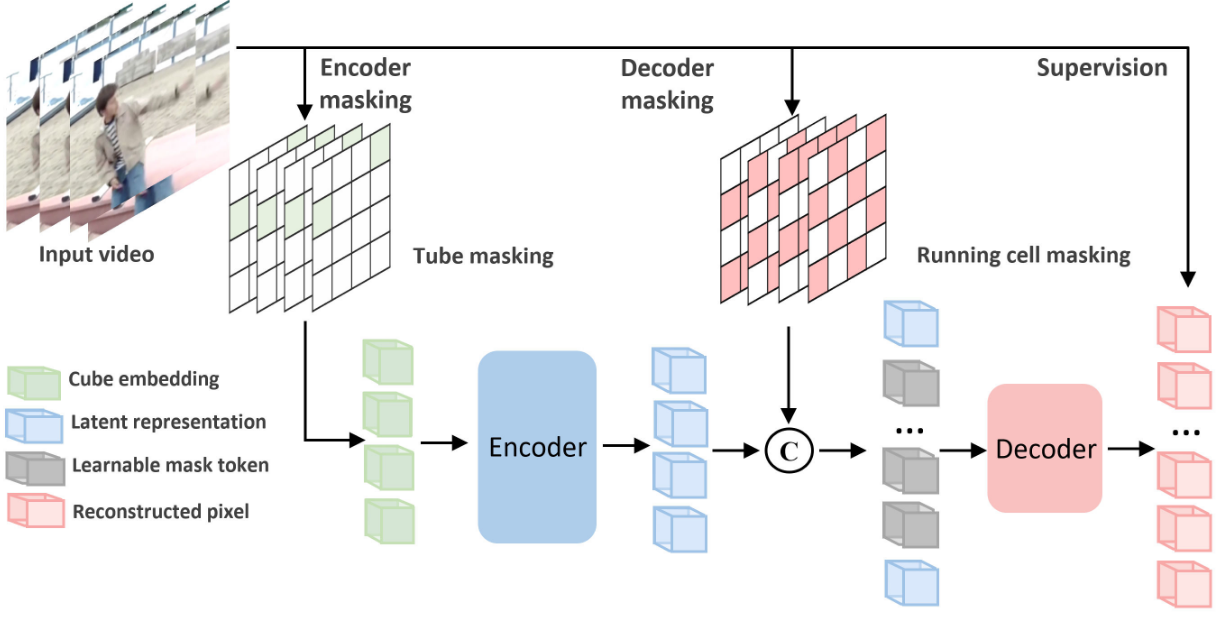
“Specifically, we present a dual masking strategy for efficient pre-training, with an encoder operating on a subset of video tokens and a decoder processing another subset of video tokens. Although VideoMAE is very efficient due to high masking ratio in encoder, masking decoder can still further reduce the overall computational cost. This enables the efficient pre-training of billion-level models in video.”
- 解析:摘要的核心,介绍了论文最关键的技术创新——双重掩码 (Dual Masking)。
- 是什么 (a dual masking strategy…): 该策略对编码器(Encoder)和解码器(Decoder)的输入都进行了掩码。编码器只看一部分视频块(token),而解码器也只处理另一部分视频块。
- 为什么 (…masking decoder can still further reduce…): 原始的 VideoMAE 已经通过在编码器端进行高比例掩码实现了很高的效率,但解码器仍然是计算瓶颈。通过给解码器也加上掩码,可以进一步压缩计算和内存开销。
- 作用 (This enables the efficient pre-training…):现有硬件条件下高效地训练十亿参数级别的视频模型成为可能。
“We also use a progressive training paradigm that involves an initial pre-training on a diverse multi-sourced unlabeled dataset, followed by a post-pre-training on a mixed labeled dataset.”
- 解析:论文的第二个关键贡献——渐进式训练 (Progressive Training) 范式。这是一种精心设计的训练流程,旨在将大模型的知识高效地迁移到下游任务中。
- 第一步 (initial pre-training…): 首先,在一个大规模、多来源的无标签数据集上进行自监督预训练,让模型学习通用的视觉表征。
- 第二步 (post-pre-training…): 接着,在一个混合的有标签数据集上进行有监督的“后预训练”。将模型学到的通用知识与具体的语义标签联系起来,为最终的微调做准备。
“Finally, we successfully train a video ViT model with a billion parameters, which achieves a new state-of-the-art performance on the datasets of Kinetics (90.0% on K400 and 89.9% on K600) and Something-Something (68.7% on V1 and 77.0% on V2).”
- 解析:展示了研究的核心成果。
- 里程碑 (successfully train a video ViT model with a billion parameters): 论文成功训练了视频领域的首个十亿参数模型,这是一个重要的工程和算法突破。
- SOTA 性能 (achieves a new state-of-the-art performance): 该模型在多个主流视频理解基准测试中刷新了记录,并列举了在 Kinetics 和 Something-Something 这两个最具代表性的数据集上的具体准确率。
“In addition, we extensively verify the pre-trained video ViT models on a variety of downstream tasks, demonstrating its effectiveness as a general video representation learner.”
- 解析:。
- 验证通用性 (extensively verify… on a variety of downstream tasks): 作者强调,他们的模型不仅仅在几个特定任务上表现出色,而是在多种不同类型的下游任务(如动作分类、时空动作检测等)上都进行了验证。
- 最终结论 (demonstrating its effectiveness as a general video representation learner): 这证明了 VideoMAE V2 成功地学习到了一种通用的视频表示,使其有资格成为一个真正的“视频基础模型”。
1. Introduction
第一部分:背景
“Effectively pre-training large foundation models… have become the main driving force for advancing many areas in AI.”
- 解析:引言的第一段首先确立了当前人工智能领域最成功的范式——大规模预训练基础模型。作者指出,无论是在语言、图像还是音视频领域,通过在海量数据上预训练一个巨大的模型,再将其适配到各种下游任务,已经成为学习通用表征的主流方法。这种方法的优势在于其卓越的泛化能力,远超为单一任务设计的专用模型。
“For vision research… Transformer with masked autoencoding… is becoming a conceptually simple yet effective self-supervised visual learner…”
- 解析:第二段将焦点从宏观的AI领域缩小到视觉研究。作者特别指出了一个简洁而强大的技术路线:基于Transformer的掩码自编码(Masked Autoencoding, MAE) 。这种方法,如图像领域的 MAE 和视频领域的 VideoMAE,通过让模型重建被遮盖的部分内容来进行自监督学习,已经证明了其有效性。
第二部分:提出问题
“…scaling model capacity and data size is an important ingredients for its remarkable performance improvement. However, for pre-trained vision models… This issue is even more serious for scaling up video masked autoencoder pre-training…”
- 解析:肯定了 MAE 范式的成功后,作者立刻抛出了核心挑战:扩展(Scaling) 。借鉴语言模型的经验,模型和数据规模的扩展是性能提升的关键。但在视觉领域,尤其是视频领域,扩展之路困难重重。原因在于:
- 高数据维度:图像本身数据量就大。
- 高计算开销:处理高维数据需要巨大的计算资源。
- 视频的额外复杂性:视频比图像多了一个时间维度,这使得数据量和计算复杂度呈指数级增长,扩展的难度远超图像。
第三部分:三大瓶颈与解决方案
明确了“要扩展视频模型,但扩展极其困难”这一核心矛盾后,作者进一步将挑战分解为三个具体、必须解决的关键问题,并逐一给出了解决方案的雏形。
1. 瓶颈一:计算成本与内存消耗 (Computational Cost and Memory Consumption)
- 问题陈述:作者指出,尽管 VideoMAE V1 采用了高效的非对称架构(编码器只处理少量可见块),但在尝试训练十亿参数级别的 ViT-g 模型时,计算和内存依然是根本性的瓶颈 。他们给出了一个惊人的数据点:在64块A100 GPU上,用V1的方法预训练一个ViT-g模型需要超过两周时间。
- 解决方案预告:作者的核心洞察在于,视频数据的冗余性不仅存在于编码器端,也存在于解码器端。因此,他们提出可以同时对解码器进行掩码,只让解码器重建一部分被遮盖的视频块。这一策略(即后文的“双重掩码”)可以在几乎不损失性能的前提下,将预训练时间缩短三分之一,并允许使用更大的批量大小(batch size),从而解决了训练的可行性问题 。
2. 瓶颈二:数据稀缺与模型过拟合 (Data Scarcity and Overfitting)
- 问题陈述:MAE这类模型对数据量需求巨大,而十亿参数的模型在“相对较小”的数据集上极易过拟合。作者通过对比鲜明地指出了视频领域的数据困境:最大的公开视频数据集之一 Kinetics-400 仅有约24万个视频,而图像领域的 ImageNet-22k 有1420万张图片,更不用说谷歌内部数十亿级别的 JFT-3B 数据集了。
- 解决方案预告:为了“喂饱”巨型模型,作者提出需要构建一个更大规模的视频预训练数据集。他们的策略是将来自多个不同来源的公开视频数据集混合,创建一个更多样化、规模达到百万级别的预训练数据集,以提升模型的泛化能力。
3. 瓶颈三:知识迁移与下游任务适配 (Knowledge Transfer and Adaptation)
- 问题陈述:如何将一个在海量无标签数据上预训练好的十亿参数模型,有效地迁移到一个只有几十万样本的下游任务上?作者指出,直接微调是“次优”的(suboptimal),因为有限的标注样本很容易导致模型在微调阶段发生过拟合。
- 解决方案预告:借鉴图像领域的“中间微调”(intermediate fine-tuning)技术,作者提出了一套渐进式训练(progressive training)流程。具体来说,他们构建了一个大规模的有标签混合数据集,作为连接大规模无监督预训练和下游特定任务微调之间的“桥梁”。通过在这个中间数据集上进行有监督的“后预训练”,可以平滑地将通用知识适配到具体的语义任务上,从而在最终的下游任务中取得更好的性能 。
第四部分:总结与贡献声明
“Based on the above analysis, we present a simple and efficient way to scale VideoMAE…termed as VideoMAE V2. Within this framework, we successfully train the first video transformer model with one billion parameters, which attains a new state-of-the-art performance on a variety of downstream tasks…”
- 解析:引言的最后部分对上述分析进行了总结,正式提出了 VideoMAE V2 框架。该框架的核心就是为了解决三大瓶颈而设计的两大技术支柱:
- 双重掩码策略 (Dual Masking Strategy)
- 渐进式训练流程 (Progressive Training Pipeline)
最终,作者自信地声明,基于这一框架,他们成功训练了视频领域的首个十亿参数模型,并在动作识别、空间动作检测和时间动作检测等多种下游任务上均取得了新的SOTA性能。
2. Related Work
1. 视觉基础模型 (Vision Foundation Models)
-
发展脉络:作者首先追溯了视觉基础模型的发展历程。
- 早期(有监督):最初的研究集中在利用大规模有标签数据集(如 ImageNet)对 CNN 或 Transformer 模型进行有监督预训练。
- 近期(自监督/无监督):随后,研究方向转向了无需人工标签的自监督学习,主要包括两大流派:
- 对比学习 (Contrastive Learning):通过拉近相似样本的表示、推远不相似样本的表示来学习特征。