Transformer架构三大核心:位置编码(PE)、前馈网络(FFN)和多头注意力(MHA)。
本文将用“直觉理解” -> “一图看懂” -> “代码实现”三步法,帮你无痛掌握Transformer的三大核心:位置编码(PE)、前馈网络(FFN) 和多头注意力(MHA)。
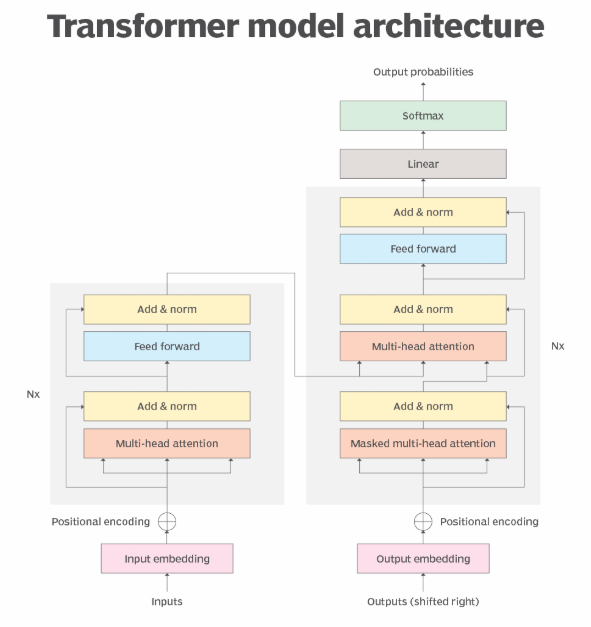
1. 位置编码 (Positional Encoding, PE)
🧠 直觉理解:
Transformer像一位“眼观六路”的读者,能同时看光所有词,但这就失去了词的顺序信息。PE的作用就是给每个词加上一个“数字坐标”,告诉模型每个词的位置。
为什么用正弦函数? 因为它有一个神奇的特性:模型可以轻松学会“位置5的词”和“位置3的词”之间的相对距离关系,这让它能更好地处理训练时没见过的长句子。
📊 一图看懂:
⌨️ 代码实现 (PyTorch):
import torch
import torch.nn as nn
import mathclass PositionalEncoding(nn.Module):def __init__(self, d_model, max_len=5000):super().__init__()pe = torch.zeros(max_len, d_model)position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)# 核心计算公式:分母部分div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))pe[:, 0::2] = torch.sin(position * div_term) # 偶数位置用sinpe[:, 1::2] = torch.cos(position * div_term) # 奇数位置用cosself.register_buffer('pe', pe.unsqueeze(0)) # 注册为不参与训练的缓冲区def forward(self, x):return x + self.pe[:, :x.size(1)] # 将PE切片后直接加到词嵌入上# 使用示例
d_model = 512
seq_len = 50
x = torch.randn(1, seq_len, d_model) # 模拟一个批次的词嵌入
pe = PositionalEncoding(d_model)
output = pe(x)
print(f"加上位置编码后的形状: {output.shape}")
2. 前馈神经网络 (Feed-Forward Network, FFN)
🧠 直觉理解:
FFN是每个位置上的“私人专家”。它对序列中每个词向量进行独立、相同的处理。其设计妙处在于“先扩维再缩回”(例如512维 -> 2048维 -> 512维),这相当于给了模型一个更宽敞的“工作台”,让它能在高维空间里更自由地组合和提炼特征,然后再将结果投影回原来的维度。
📊 一图看懂:
⌨️ 代码实现 (PyTorch):
class FeedForward(nn.Module):def __init__(self, d_model, d_ff=2048, dropout=0.1):super().__init__()self.net = nn.Sequential(nn.Linear(d_model, d_ff), # 扩维nn.GELU(),nn.Linear(d_ff, d_model), # 缩回nn.Dropout(dropout),)def forward(self, x):return self.net(x) # 输入输出形状均为 (batch_size, seq_len, d_model)# 使用示例
ffn = FeedForward(d_model)
ffn_output = ffn(output) # 输入是PE的输出
print(f"FFN输入输出形状: {ffn_output.shape}")
3. 多头注意力 (Multi-Head Attention, MHA)
🧠 直觉理解:
核心:让模型同时从不同角度审视信息。
单头注意力好比你看一篇文章只关注一种关系(例如“谁做了什么”)。而多头注意力让你像有多双眼睛同时关注不同的方面(一双眼看“语法主谓”,一双眼看“情感色彩”,一双眼看“指代关系”),最后把所有观察结果综合起来,得到更全面的理解。
📊 一图看懂:
⌨️ 代码实现 (PyTorch):
class MultiHeadAttention(nn.Module):def __init__(self, d_model, num_heads, dropout=0.1):super().__init__()self.d_model = d_modelself.num_heads = num_headsself.d_k = d_model // num_heads# 定义投影矩阵self.w_q = nn.Linear(d_model, d_model)self.w_k = nn.Linear(d_model, d_model)self.w_v = nn.Linear(d_model, d_model)self.w_o = nn.Linear(d_model, d_model)self.dropout = nn.Dropout(dropout)def forward(self, q, k, v, mask=None):batch_size = q.size(0)# 1. 线性投影并分头# 输入: (B, S, D) -> 投影: (B, S, D) -> 分头+转置: (B, H, S, d_k)q = self.w_q(q).view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)k = self.w_k(k).view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)v = self.w_v(v).view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)# 2. 计算缩放点积注意力# 公式: Attention(Q, K, V) = softmax(Q•K^T / sqrt(d_k)) • Vattn_scores = torch.matmul(q, k.transpose(-2, -1)) / math.sqrt(self.d_k)if mask is not None:attn_scores = attn_scores.masked_fill(mask == 0, -1e9)attn_weights = torch.softmax(attn_scores, dim=-1)attn_weights = self.dropout(attn_weights)attn_output = torch.matmul(attn_weights, v) # (B, H, S, d_k)# 3. 拼接所有头# 转置: (B, H, S, d_k) -> (B, S, H, d_k) -> 拼接: (B, S, D)attn_output = attn_output.transpose(1, 2).contiguous().view(batch_size, -1, self.d_model)# 4. 最终线性投影return self.w_o(attn_output) # (B, S, D)# 使用示例 (自注意力)
num_heads = 8
mha = MultiHeadAttention(d_model, num_heads)
attn_output = mha(ffn_output, ffn_output, ffn_output) # Q, K, V 均来自FFN输出
print(f"MHA输出形状: {attn_output.shape}")
🧩 如何串联:一个迷你Transformer块
📊 一图看懂:
理解了组件,再看它们如何协作就非常容易了,流程图如下:
⌨️ 代码实现 (PyTorch):
class TransformerBlock(nn.Module):"""一个完整的Transformer编码层"""def __init__(self, d_model, num_heads, d_ff, dropout=0.1):super().__init__()self.self_attn = MultiHeadAttention(d_model, num_heads, dropout)self.ffn = FeedForward(d_model, d_ff, dropout)self.norm1 = nn.LayerNorm(d_model)self.norm2 = nn.LayerNorm(d_model)self.dropout = nn.Dropout(dropout)def forward(self, x):# 子层1: 自注意力 + 残差连接 & 层归一化attn_output = self.self_attn(x, x, x) # 自注意力x = x + self.dropout(attn_output) # 残差连接x = self.norm1(x) # 层归一化# 子层2: 前馈网络 + 残差连接 & 层归一化ffn_output = self.ffn(x)x = x + self.dropout(ffn_output)x = self.norm2(x)return x# 最终串联
mini_transformer = TransformerBlock(d_model, num_heads, d_ff=2048)
final_output = mini_transformer(pe(x)) # 从带位置编码的输入开始
print(f"迷你Transformer块输出形状: {final_output.shape}")
希望这个重新构思的回答更加清晰和深入!它现在包含了更多的设计洞见和更流畅的代码逻辑。