详解常见的多模态大模型指令集构建
一、TL;DR
- 详细介绍了常见的多模态模型InternVL系列、Qwen系列、ms-swift、xtuner训练框架的数据集构造方法
- 详细的介绍了纯文本、单张图片、多张图片、grounding任务、视频任务的指令集构造方式
- 针对Omni模态,单独重点以qwen2.5-omni模型为例介绍如何构建
二、InternVL系列
2.1 数据集配置

参数含义:
- 指令集类型
- 是否使用数据增强
- input分块最大数目(比如高分辨率图片会分块输入)
- Repeat(重复)次数
实例化如下所示:

2.2 不同指令集类型
注意:
- 以下的所有格式都是支持多轮对话的,不理解的同学可以翻一下paper开源的数据集,看一下他是如何构建多轮对话的
- 重点还是在conversations的字段里面的构建,注意input_prompt和answer的多样性构造
2.2.1 LLM-纯文本


2.2.2 VLM-单张图片

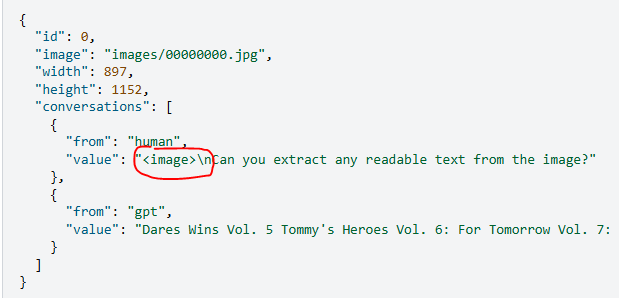
2.2.3 VLM-多张图片
注意:这里没有提到输入图片的顺序,如果需要使用到顺序,则需要在prompt中严格写好,比如第一张图代表什么意思,第二张图代表xx:

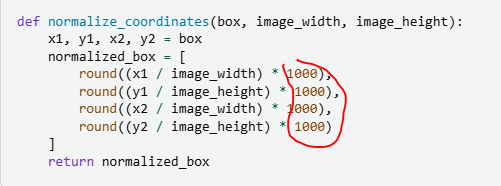
2.2.4 VLM-Grounding
注意:所有的坐标都归一化到了1-1000:

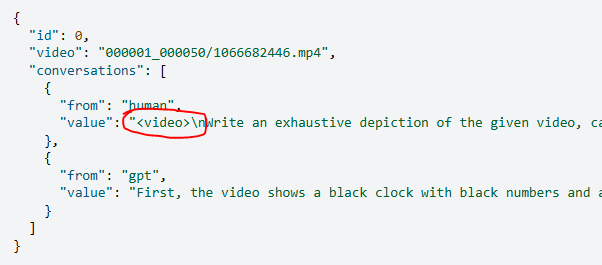
2.2.5 MLLM-video
注意:input的类型变成了Video
参考链接:Chat Data Format — InternVL
三、Qwen系列
3.1 Qwen2.5-VL系列
3.1.1 单张图片

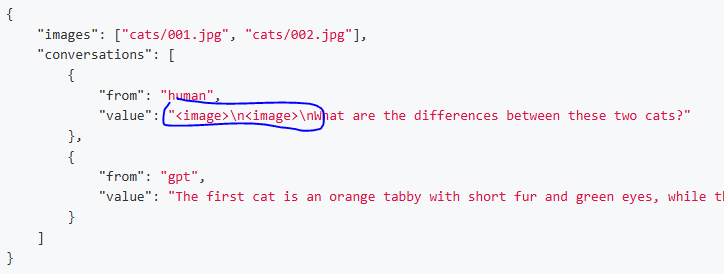
3.1.2 多张图片
注意:多张图片是由多个<image>的标志位的
3.1.3 Grounding
注意:Qwen是没有归一化0-1000的(通常我们归一化坐标是为了加速收敛)
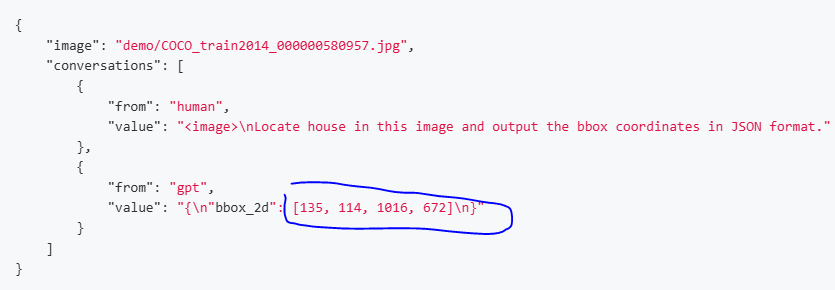
3.1.4 Video

3.2 Qwen-Omni全模态
注意:
- jsonl里面的每一行都是如下格式
- input需要先表明type,然后在下一个key给出对应input的地址或者内容
全模态的输入导致qwen2.5-Omni的thinker模块需要同时处理多个模态的输入,将不同模态变成序列化,因此会引入新的位置编码,感兴趣的同学去看我上一篇博客就好:Qwen2.5-Omni 技术报告:全模态的基础模型-CSDN博客
再加一行特别注意:
- 如果输入是video,要考虑视频是要有音轨的,omni会同时解析视频和里面的音频,如果视频是没有收音的,则需要进行预处理增加静音音轨
{"id": "302-_EtwHSuT4LA-split_6","data_source": "0_30_s_academic_v0_1","conversations": [{"role": "user","content": [{"type": "video","video": "academic_source/youcook2/302/_EtwHSuT4LA/split_6.mp4"},{"type": "text","text": "Describe every scene and its significance in the video."}]},{"role": "assistant","content": "The video showcases a detailed process of preparing a food item on a white cutting board with green edges. A person begins by placing a mixture of finely chopped vegetables and possibly meat onto a square sheet of dough. The mixture includes ingredients like carrots, peas, and ground meat. The person then skillfully folds the dough over the filling, starting from one corner and rolling it tightly. They carefully tuck in the sides of the dough to ensure the filling is securely wrapped. In the background, a glass bowl containing more of the filling mixture and a small glass bowl with a clear liquid, possibly oil or water, are visible. Additionally, a large white plate is present on the left side of the cutting board. The person continues to roll the dough until the filling is completely enclosed, resulting in a neat, cylindrical shape."}]
}参考链接:https://github.com/hyc2026/sft-qwen2.5-omni-thinker/
四、ms-swift框架
ms-swift是阿里的框架,应该是比较完善和前沿的技术框架,分为两种数据集构建格式:
4.1 ms-swift自定义数据集
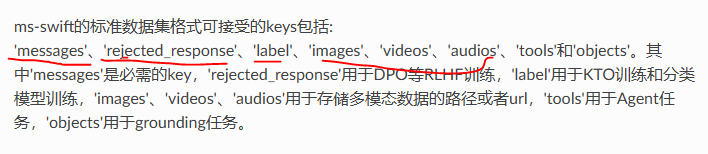
指令集jsonl里面可读的字段:
- messages:单轮/多轮对话的指令
- rejected_response:强化学习的偏好学习输出
- object:做grounding任务
- tools:Agent的任务
- videos/images等:输入的路径
ms-swift的标准自定义数据集:
多模态数据集:
{"messages": [{"role": "assistant", "content": "预训练的文本在这里"}]}
{"messages": [{"role": "assistant", "content": "<image>是一只小狗,<image>是一只小猫"}], "images": ["/xxx/x.jpg", "/xxx/x.png"]}
{"messages": [{"role": "assistant", "content": "<audio>描述了今天天气真不错"}], "audios": ["/xxx/x.wav"]}
{"messages": [{"role": "assistant", "content": "<image>是一个大象,<video>是一只狮子在跑步"}], "images": ["/xxx/x.jpg"], "videos": ["/xxx/x.mp4"]}注意:<image>或者<video>或者<audio>这个代表文本描述的哪一个模态的输入,记得在指令内容里面加上这个字段
Grounding任务稍微有点特殊:
可以直接使用对应模型的数据集格式:
- 比如你用qwen模型,可以用qwen的数据集
{"messages": [{"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": "<image>描述图像"}, {"role": "assistant", "content": "<|object_ref_start|>一只狗<|object_ref_end|><|box_start|>(221,423),(569,886)<|box_end|>和<|object_ref_start|>一个女人<|object_ref_end|><|box_start|>(451,381),(733,793)<|box_end|>正在沙滩上玩耍"}], "images": ["/xxx/x.jpg"]}
{"messages": [{"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": "<image>找到图像中的<|object_ref_start|>羊<|object_ref_end|>"}, {"role": "assistant", "content": "<|box_start|>(101,201),(150,266)<|box_end|><|box_start|>(401,601),(550,666)<|box_end|>"}], "images": ["/xxx/x.jpg"]}
{"messages": [{"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": "<image>帮我打开谷歌浏览器"}, {"role": "assistant", "content": "Action: click(start_box='<|box_start|>(246,113)<|box_end|>')"}], "images": ["/xxx/x.jpg"]}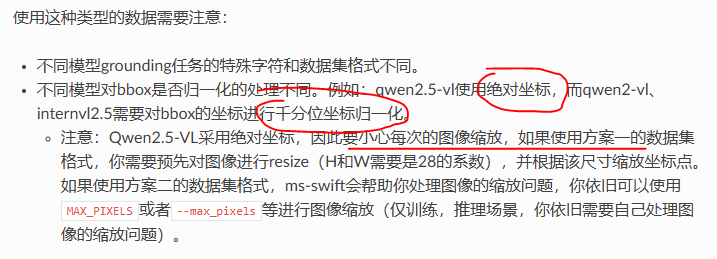
- 也可以直接使用ms-swift的标准数据集
{"messages": [{"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": "<image>描述图像"}, {"role": "assistant", "content": "<ref-object><bbox>和<ref-object><bbox>正在沙滩上玩耍"}], "images": ["/xxx/x.jpg"], "objects": {"ref": ["一只狗", "一个女人"], "bbox": [[331.5, 761.4, 853.5, 1594.8], [676.5, 685.8, 1099.5, 1427.4]]}}
{"messages": [{"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": "<image>找到图像中的<ref-object>"}, {"role": "assistant", "content": "<bbox><bbox>"}], "images": ["/xxx/x.jpg"], "objects": {"ref": ["羊"], "bbox": [[90.9, 160.8, 135, 212.8], [360.9, 480.8, 495, 532.8]]}}
{"messages": [{"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": "<image>帮我打开谷歌浏览器"}, {"role": "assistant", "content": "Action: click(start_box='<bbox>')"}], "images": ["/xxx/x.jpg"], "objects": {"ref": [], "bbox": [[615, 226]]}}4.2 标准开源数据集
- 推荐如果使用ms-swift就可以使用自定义的数据集,方便不同模型训练比较效果

参考文档:自定义数据集 — swift 3.8.0.dev0 文档
五、xtuner框架
xtuner是上海人工智能实验室搞的就是商汤:
- 可以使用开源LLaVA的多模态格式来训练
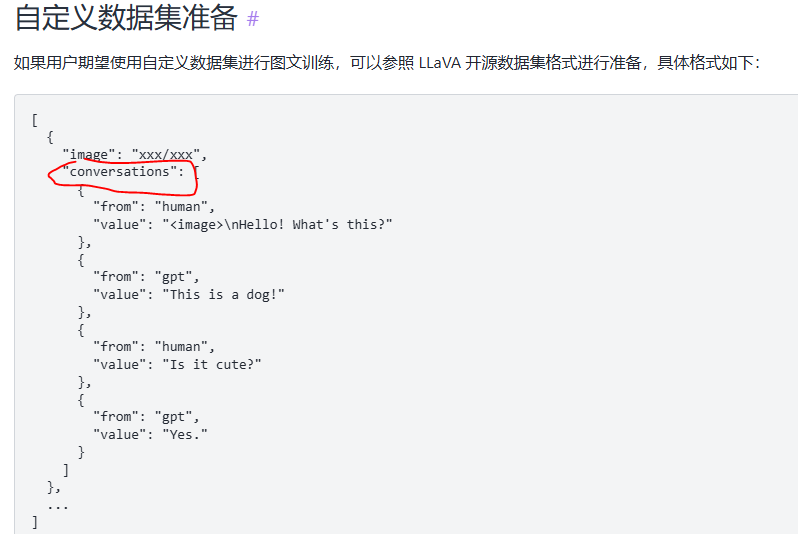
参考文档:https://xtuner.readthedocs.io/zh-cn/latest/training/multi_modal_dataset.html