BiLSTM-Attention分类预测+SHAP分析+特征依赖图!深度学习可解释分析,Matlab代码实现
BiLSTM-Attention分类预测+SHAP分析+特征依赖图!深度学习可解释分析,Matlab代码实现
目录
- BiLSTM-Attention分类预测+SHAP分析+特征依赖图!深度学习可解释分析,Matlab代码实现
- 效果一览
- 基本介绍
- 程序设计
- 参考资料
效果一览
基本介绍
该MATLAB代码实现了一个基于BiLSTM-Attention的多分类模型,主要功能包括:
-
数据预处理:导入Excel数据、分层抽样划分数据集、归一化处理
-
BiLSTM-Attention建模:构建并训练BiLSTM-Attention分类网络
-
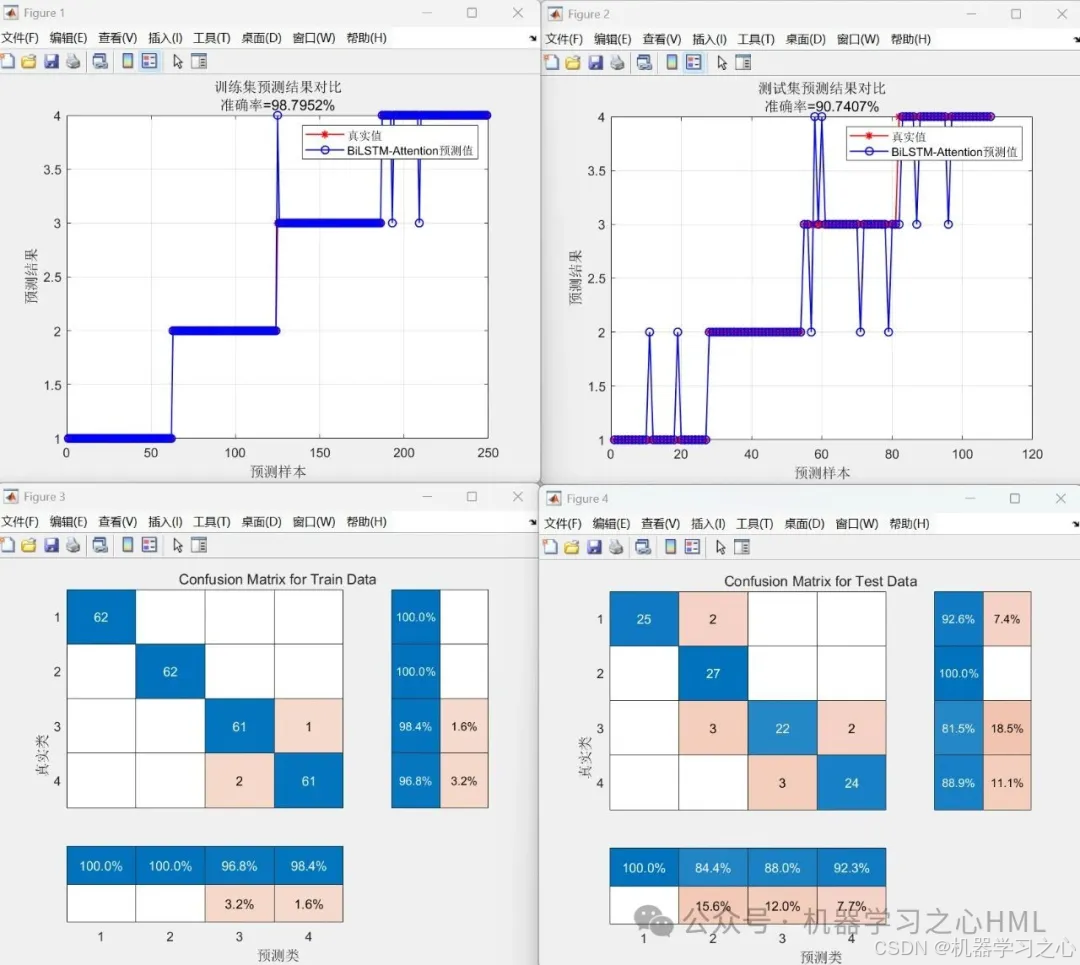
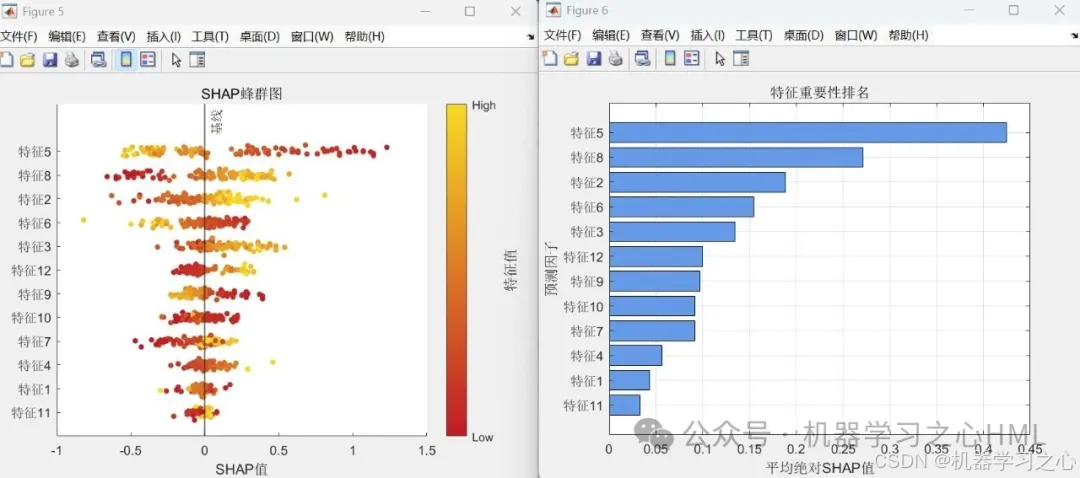
性能评估:计算准确率、绘制混淆矩阵和预测结果对比图
-
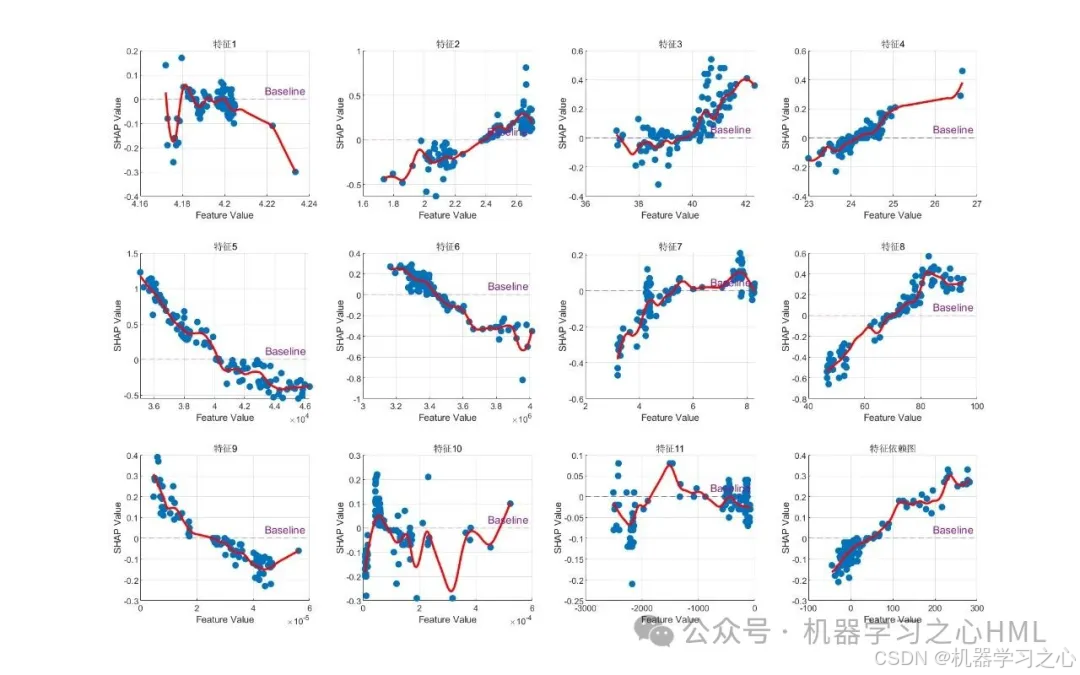
可解释性分析:使用SHAP值进行特征重要性排序和依赖关系分析
算法步骤
- 初始化
• 清空工作区、关闭图窗
• 导入Excel数据集(最后一列为类别标签)
• 计算类别数、特征维度、样本总数
- 数据预处理
• 随机打乱数据集(randperm)
• 分层抽样:按类别比例划分70%训练集和30%测试集
• 归一化特征到[0,1]区间(mapminmax)
• 转换数据为BiLSTM-Attention输入格式
-
BiLSTM-Attention模型构建
-
模型训练
• 使用Adam优化器,批大小=100
• 初始学习率0.01,700轮后衰减10倍
• 最大训练轮数1000
- 预测与评估
• 计算训练/测试集准确率
• 绘制预测结果对比曲线
• 生成混淆矩阵(confusionchart)
- SHAP可解释性分析
• 计算测试样本的Shapley值
• 绘制特征重要性条形图
• 生成SHAP摘要图和特征依赖图
技术路线
-
数据流:Excel数据 → 矩阵 → 归一化 → 4D张量
-
建模路线:序列输入 → BiLSTM-Attention特征提取 → 全连接分类
-
可解释性:Shapley值计算 → 特征重要性排序 → 依赖关系可视化
运行环境
MATLAB版本:≥2023b
应用场景
- 多分类问题
• 支持任意类别数(自动识别num_class)
• 适用场景:故障诊断、状态划分
- 结构化数据分析
• 处理表格数据(Excel格式)
• 典型领域:金融风控、信用评分、客户分群
- 高可解释性需求场景
• SHAP分析特征贡献:
• 医疗诊断(关键指标定位)
• 工业质检(缺陷特征分析)
• 科学研究(变量重要性排序)
- 时序分类(需调整数据格式)
• 应用场景:ECG信号分类、设备状态监测
数据集
程序设计
- 完整程序和数据下载私信博主回复BiLSTM-Attention分类预测+SHAP分析+特征依赖图!深度学习可解释分析,Matlab代码实现。
t-size: 10pt; font-family: Menlo, Monaco, Consolas, "Courier New", monospace; font-style: normal; font-weight: normal; }
%% 清空环境变量
warning off % 关闭报警信息
close all % 关闭开启的图窗
clear % 清空变量
clc % 清空命令行
rng('default');
%% 导入数据
res = xlsread('data.xlsx');
%% 数据分析
num_size = 0.7; % 训练集占数据集比例
outdim = 1; % 最后一列为输出
num_samples = size(res, 1); % 样本个数
res = res(randperm(num_samples), :); % 打乱数据集(不希望打乱时,注释该行)
num_train_s = round(num_size * num_samples); % 训练集样本个数
f_ = size(res, 2) - outdim; % 输入特征维度
%% 划分训练集和测试集
P_train = res(1: num_train_s, 1: f_)';
T_train = res(1: num_train_s, f_ + 1: end)';
M = size(P_train, 2);
P_test = res(num_train_s + 1: end, 1: f_)';
T_test = res(num_train_s + 1: end, f_ + 1: end)';
N = size(P_test, 2);
%% 数据归一化
[p_train, ps_input] = mapminmax(P_train, 0, 1);
p_test = mapminmax('apply', P_test, ps_input);
[t_train, ps_output] = mapminmax(T_train, 0, 1);
t_test = mapminmax('apply', T_test, ps_output);
%% 数据平铺
pn_train = reshape(p_train, f_, 1, 1, M);
pn_test = reshape(p_test , f_, 1, 1, N);
t_train = double(t_train)';
t_test = double(t_test )';参考资料
[1] https://blog.csdn.net/kjm13182345320/article/details/128163536?spm=1001.2014.3001.5502
[2] https://blog.csdn.net/kjm13182345320/article/details/128151206?spm=1001.2014.3001.5502