TDengine IDMP 应用场景:工业锅炉监控

TDengine IDMP 应用场景:工业锅炉监控
1. 简介
本文以一个工业燃煤锅炉系统监控为例,详细介绍通过工业上广泛使用的 OPC 中间件软件 KEPServer,轻松采集温度、压力、流量、电流等重要参数,将数据写入 TDengine TSDB 时序数据库,然后通过 TDengine IDMP 构建资产模型,利用 AI 自动生成可视化面板和实时分析,实现分钟级搭建高效、智能的工业重要装置的监控系统。
工业锅炉是许多行业的关键设备,为发电、化工生产、冶金和造纸等工业过程提供必需的热量和蒸汽,如果停炉检修或者锅炉出现故障,将面临停工停产的风险。工厂的锅炉房采用锅炉的台数,应根据热负荷的调度、锅炉检修和扩建的可能性等因素确定, 一般不少于两台。本示例模拟工厂内两台锅炉,可根据需要添加更多。
在这个方案中,TDengine TSDB + TDengine IDMP 的组合能够为您带来四大好处:
- “单列模型”快速资产建模:TDengine IDMP 与 TDengine TSDB 无缝集成,类似锅炉这样的重要工业装置的数据往往是以单列模型写入 TSDB ,在 IDMP 可以快速进行资产建模,并以树形结构的方式展现被监控的对象,设备资产一目了然。
- 无问智推,数据自己说话:不用在 TDengine 侧做任何配置,不用脚本,不用提问,IDMP 会基于采集的数据,自动判断为 工业锅炉 监测场景,自动为您推荐面板和实时预警,锅炉系统的运行状态尽在掌控之中。
- 智能问数,随问随答:不用 SQL,不用任何脚本语言,你只要用自然语言说出感兴趣的数据分析或面板,IDMP 将会自动帮您创建,把数据可视化与分析的使用门槛降为 0。
- 如果添加新的被监测的装置或设备,只要配置好 KEPServer,在 TDengine 侧不用做任何设置和操作,装置或设备就被自动的加入到监测的对象中,最大程度节省人力。
2. 前提条件
- TDengine 云服务实例。如果您没有可用的 TDengine 云服务实例,可以免费注册
- 被监控的工业锅炉装置。为便于演示,我们采用kaggle.com上的公开数据集:Time-Series of Industrial Boiler Operations | Kaggle。该数据集为浙江省某化工厂的燃煤锅炉的重要监控参数(共30个),采样频率为5秒。
- 数据集
data.csv用来模拟锅炉1,重命名为:Boiler1.csv - 数据集
data_AutoReg.csv用来模拟锅炉2,重命名为:Boiler2.csv
- 数据集
- KEPServer 环境已具备。本示例服务器IP地址:
192.168.1.66,请根据您自己的环境替换。
3. 配置指南
3.1 创建 IDMP 云服务实例
- 使用您的账号,登录 TDengine Cloud,在弹出的 TDengine 实例选择框中,选择“IDMP(工业数据管理平台)”。
- 在实例配置页面,分别配置 IDMP 实例和 TSDB 实例的信息和计费方案:
- IDMP(工业数据管理平台):
- 实例名称:boiler-idmp
- 计费方案:IDMP-入门版
- TSDB(时序数据库)
- 实例名称:boiler-tsdb
- 计费方案:入门版
- IDMP(工业数据管理平台):
- 等待 IDMP 实例启动后,选择加载一个场景的示例数据,即可进入 IDMP 云服务的主页面。
说明:TDengine IDMP 服务默认使用 TDengine TSDB 作为其数据源,在 IDMP 云服务实例创建过程中,会自动创建到上述 TSDB 的连接。
3.2 在 TSDB 云服务实例创建 DB
- 进入 IDMP 云服务实例的主页面后,点击右上角下拉菜单中的【管理后台】。
- 在管理后台页面点击【云资源管理】,进入云资源管理页面。
- 在实例列表中找到 boiler-tsdb 实例,点击【TSDB 云服务】,进入 TSDB 云服务页面。
- 在左侧点击【数据浏览器】,在数据浏览器页面点击【创建数据库】。
- 设置数据库名称为 db_boiler,完成 DB 创建。
3.3 KEPServer 配置
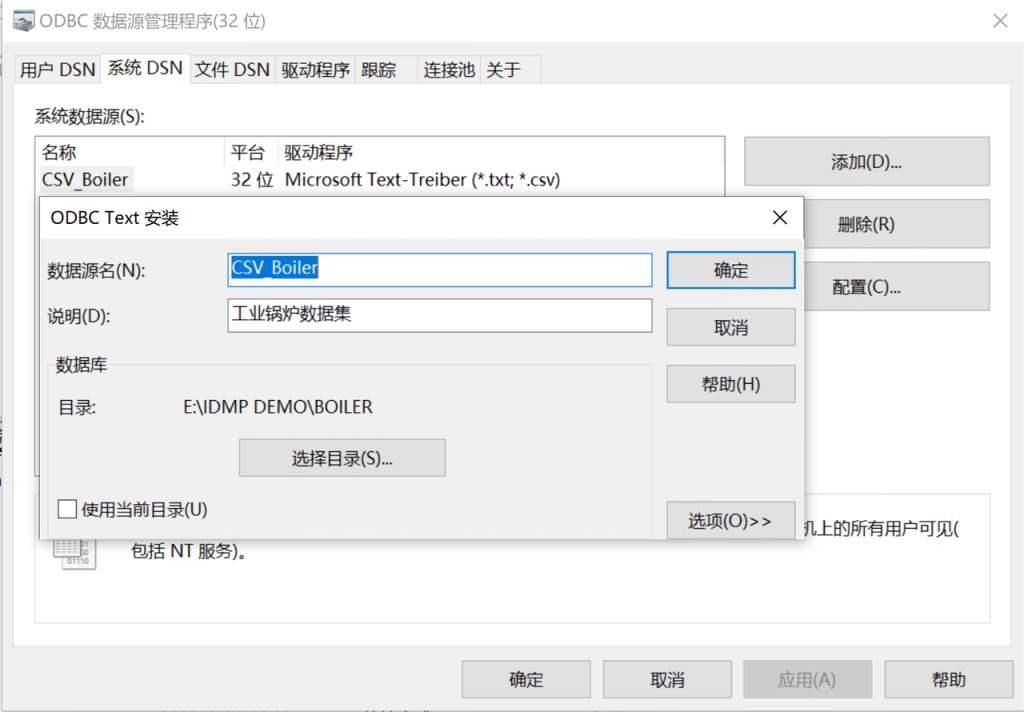
在系统中新建ODBC 数据源CSV_Boiler,选择驱动Microsoft Text Driver (*.txt; *.csv) ,选择数据集所在的目录。
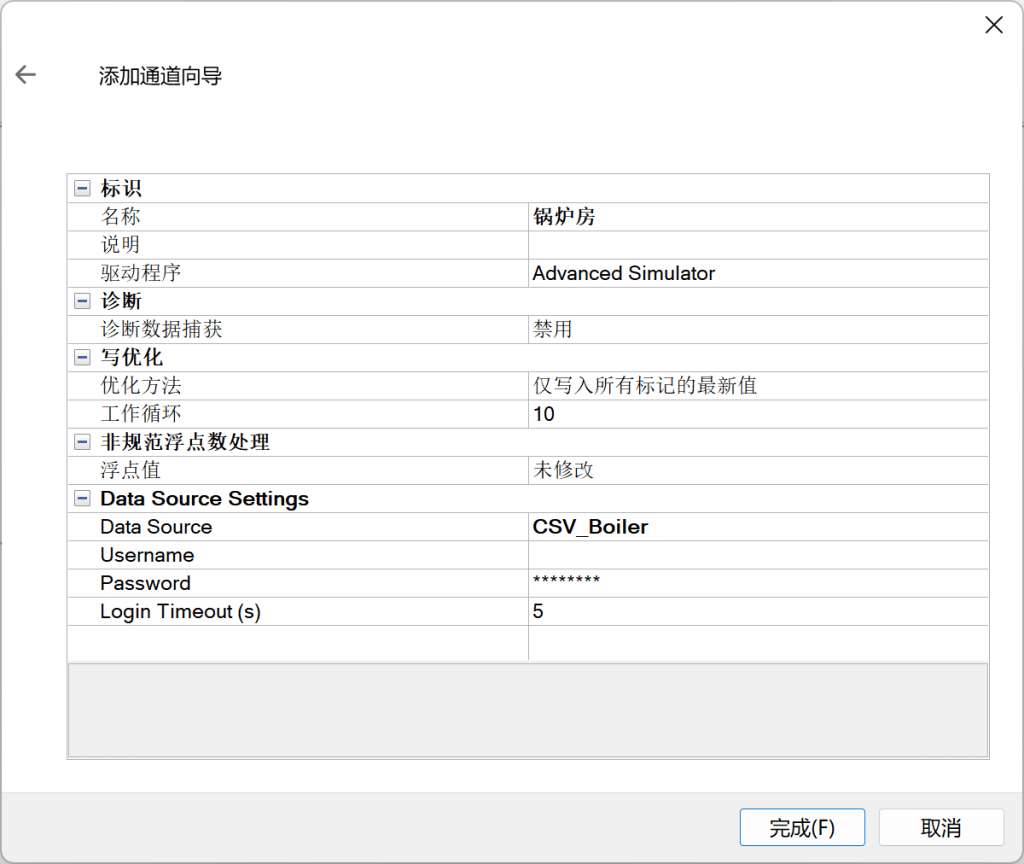
在 KEPServer 添加通道锅炉房,Advanced Simulator驱动,【Data Source】选 CSV_Boiler
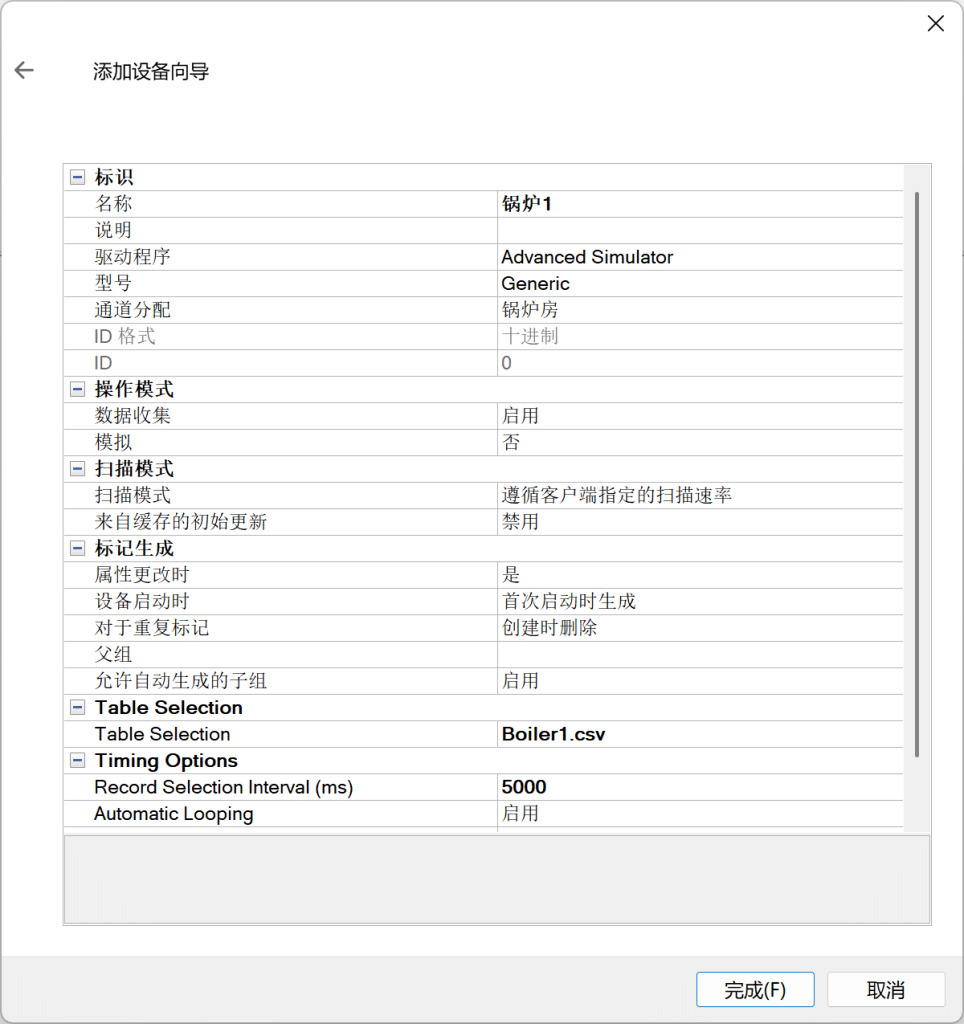
添加设备锅炉1,选择对应的数据集Boiler1.csv,【Record Selection Interval】设置为5000ms。
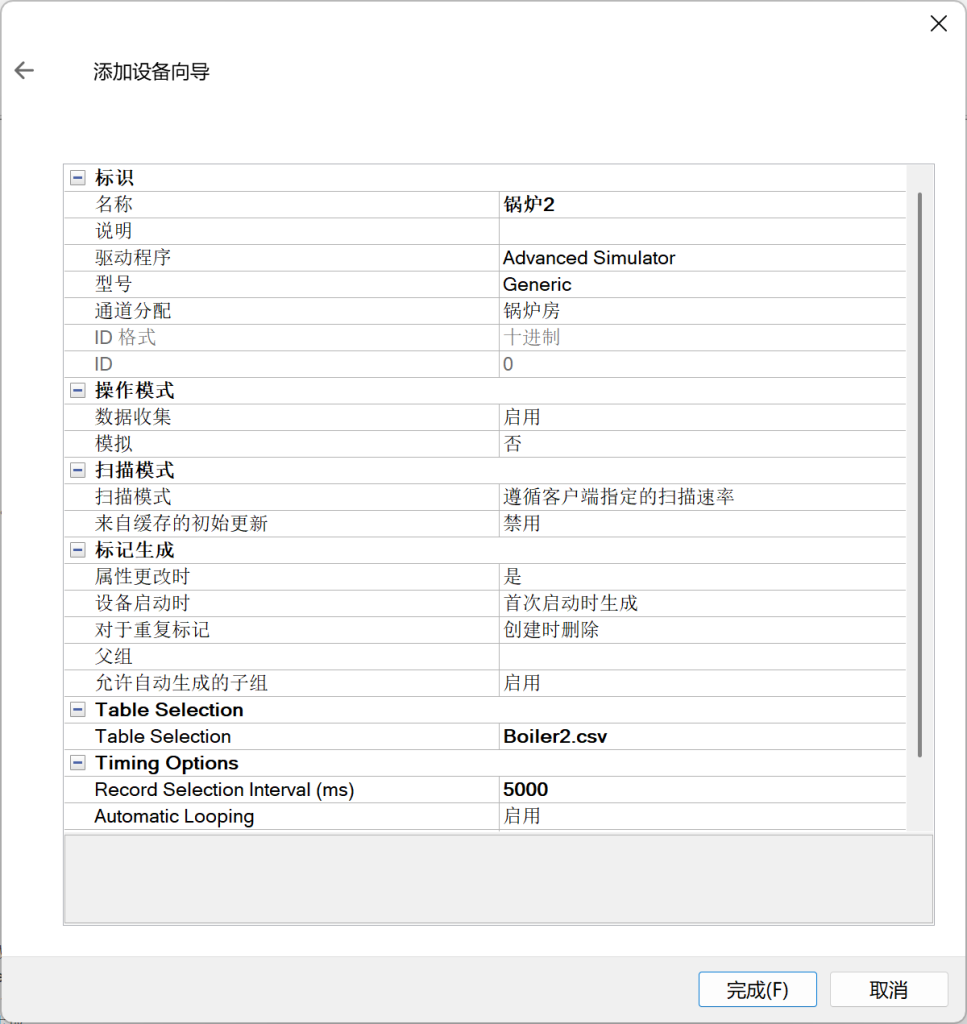
同样的方式添加设备锅炉2。
【运行时】-【连接】,连接到运行时,点击设备锅炉1和锅炉2,会发现标记(点位)已自动生成:
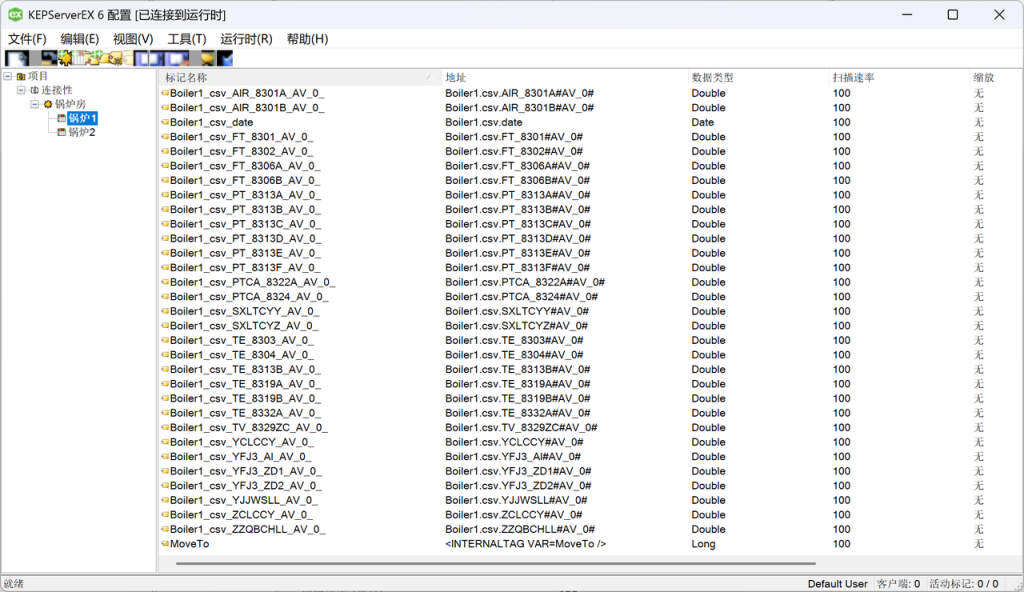
自动生成的标记名称的可读性较差。对这些标记进行分组、重命名,得到点表文件:
锅炉1下载
锅炉2下载
删除 KEPServer 自动生成的标记。在设备锅炉1右键->【导入 CSV】,选择锅炉1.csv文件,导入标记。同样的方式完成设备锅炉2的标记导入。
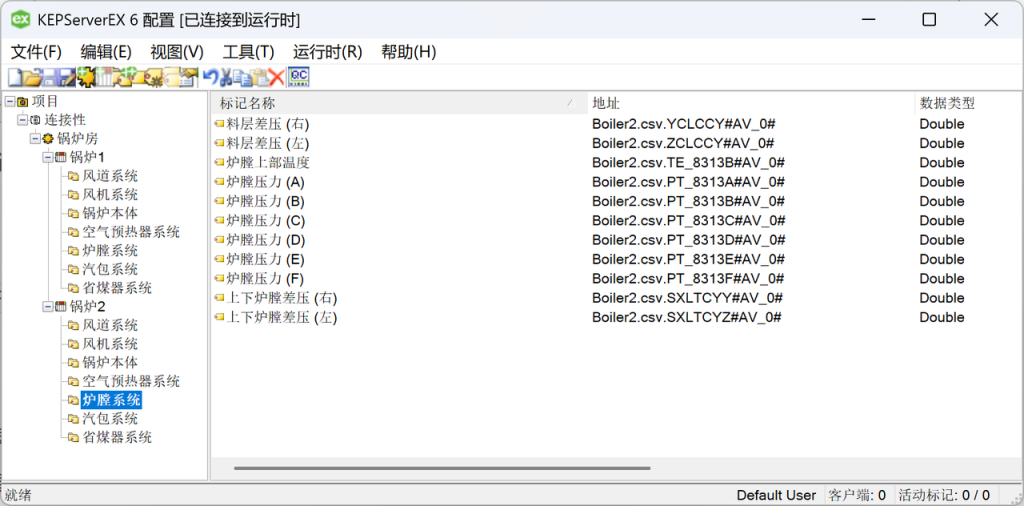
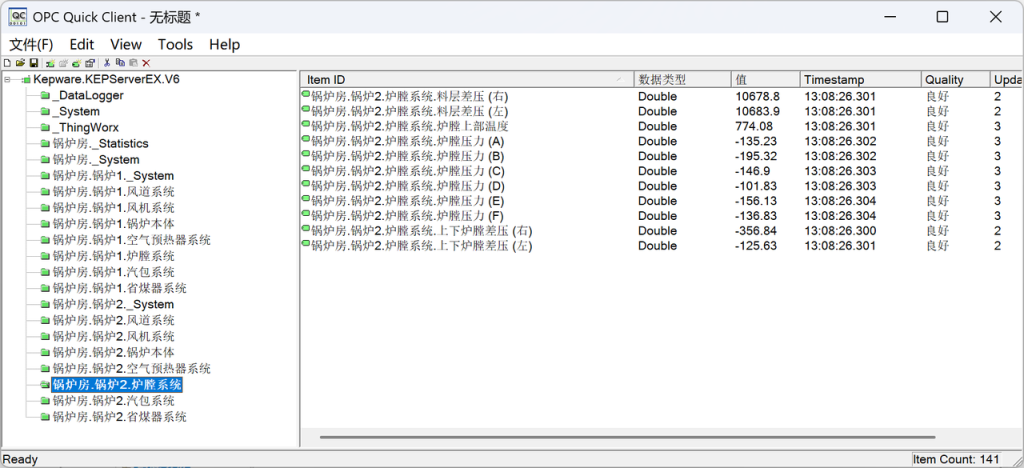
【工具】->【启动 OPC Quick Client】,验证数据是否正确模拟生成:
3.4 零代码写入 OPC 数据到 TSDB
运行 boiler-tsdb 实例,创建 OPC 数据写入任务。
因为本示例使用的云服务在外网,需要在能访问到 KEPServer 所在的内网的某台计算机上安装 taosX Agent,以确保 TSDB 能访问到 OPC Server。本示例把 taosX Agent 安装在本地服务器192.168.1.66
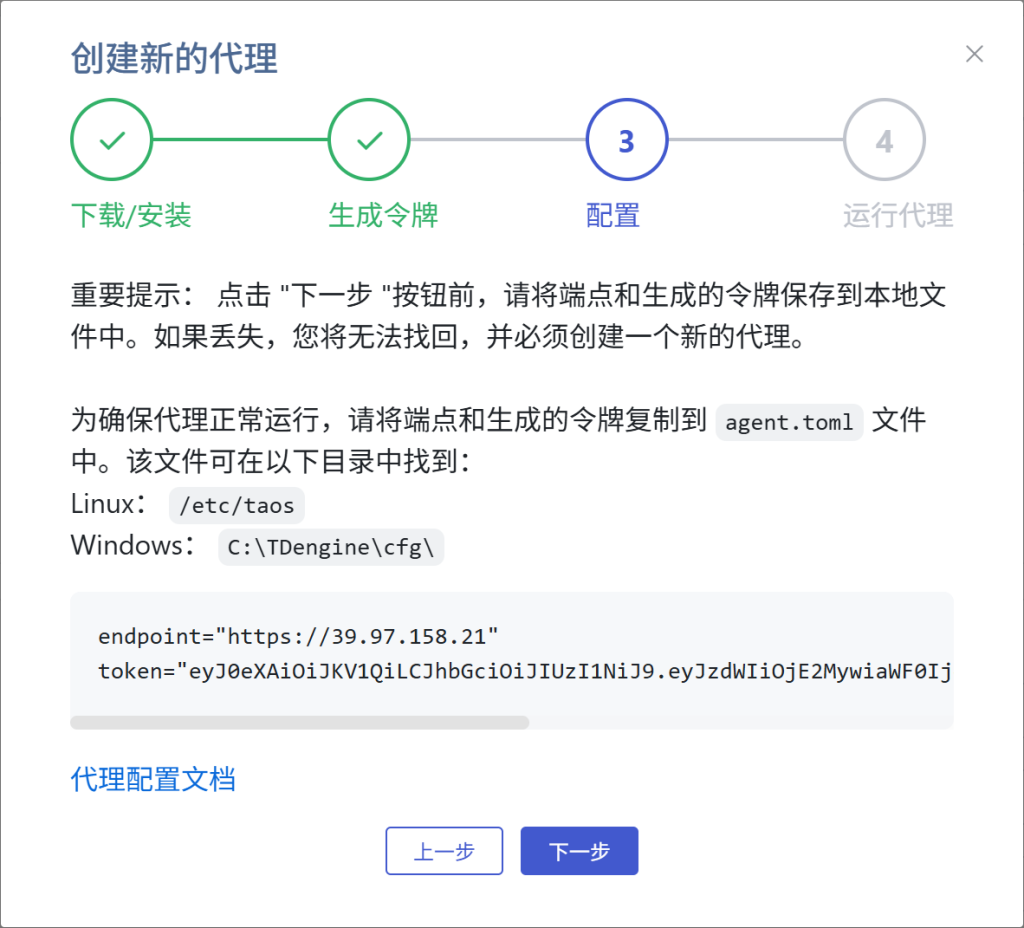
创建数据写入任务 DataIn_Boiler,类型为 OPC-UA,创建代理 opcuaAgent,按提示将端点和生成的令牌复制到本地服务器上的 agent.toml 文件,启动taosX Agent服务,【检查代理是否连接正常】。
在【连接配置】,填写服务地址 192.168.1.66:49320,选择OPC UA配置的安全模式,检查连通性。
如果提示 您的数据源可以连通, 则说明 KEPServer 的 OPC-UA 已能正常访问。
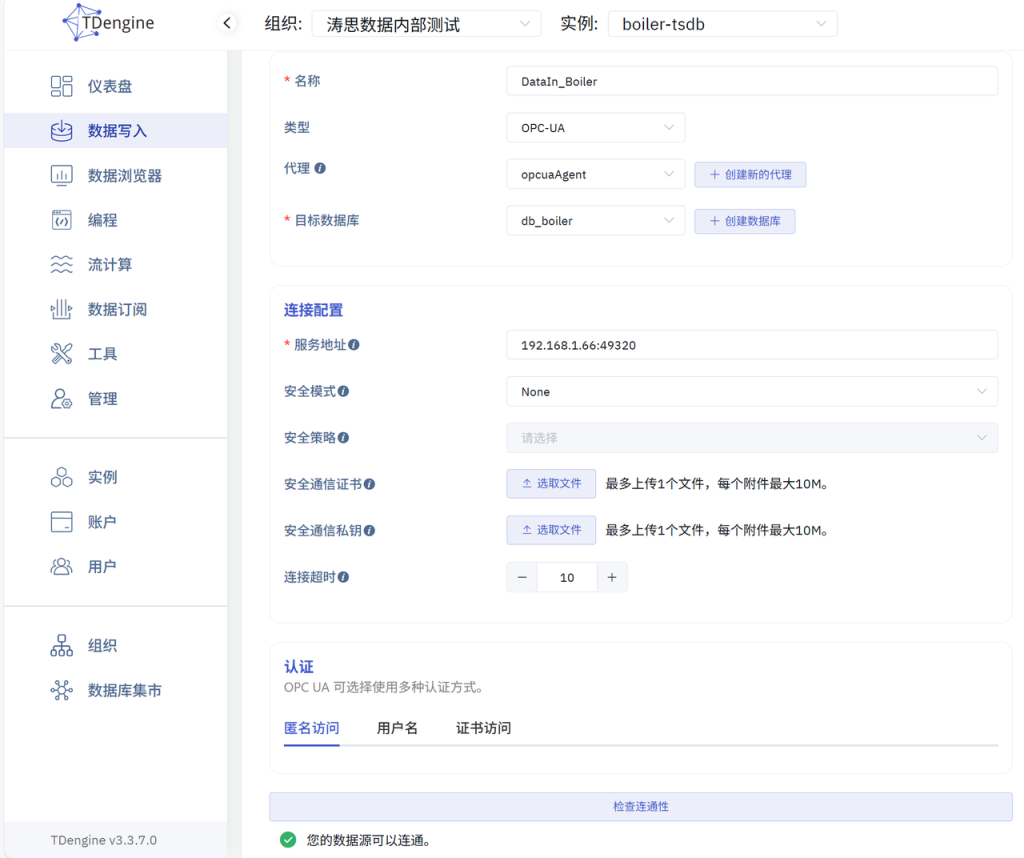
在【点位集】->【选择数据点位】
根节点ID 填写 ns=2;s=锅炉房,命名空间可选可不选,超级表名称 opc_boilers,表名称 t_{id};
采集模式为 observe,采集间隔 5s;
点位更新模式 选择 update,未来如果 OPC Server 发生点位变更,TDengine 将自动获取新增或变更的点位。
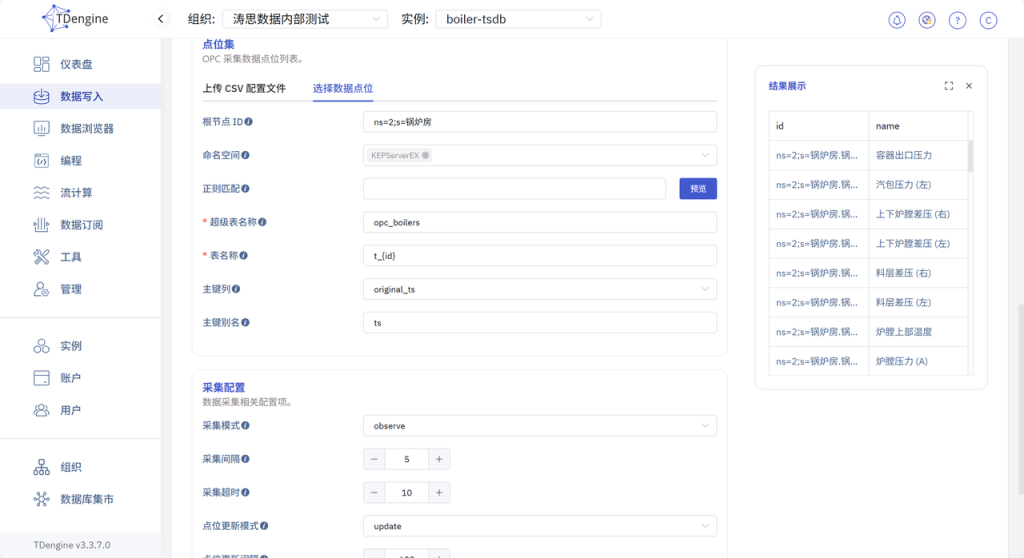
【新增】成功,【查看】任务状态。显示系统已自动创建表并写入数据。
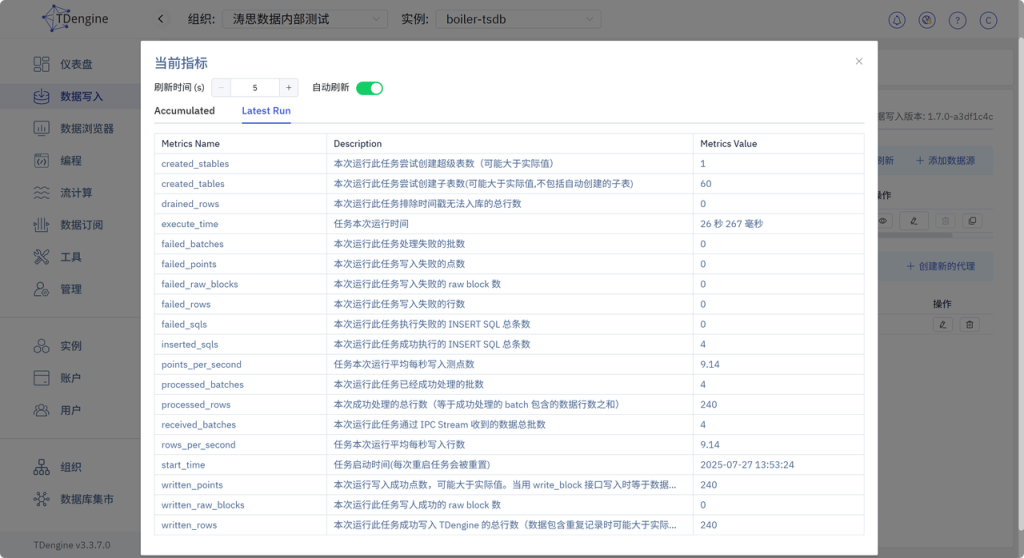
3.5 在 IDMP 中创建元素模板
登录 IDMP 实例,创建元素模板及元素,将 TDengine TSDB 的数据加载至 TDengine IDMP。
首先创建元素模板。
【基础库】->【元素模板】->【新建元素模板】,【模板名称】填 风道系统,【元素命名模式】为 模板名称 即 ${Template#name},【保存】
右上角切换至 元素模板 > 风道系统 > 属性面板 ,【新增属性模板】,【名称】填 回风室流量 (右),【值类型】选 Double , 【显示的小数位数】2,【计量单位分类】选 体积流量,【默认计量单位】选 立方米每小时,【显示计量单位】选 立方米每小时,【数据引用类型】选 TDengine 指标
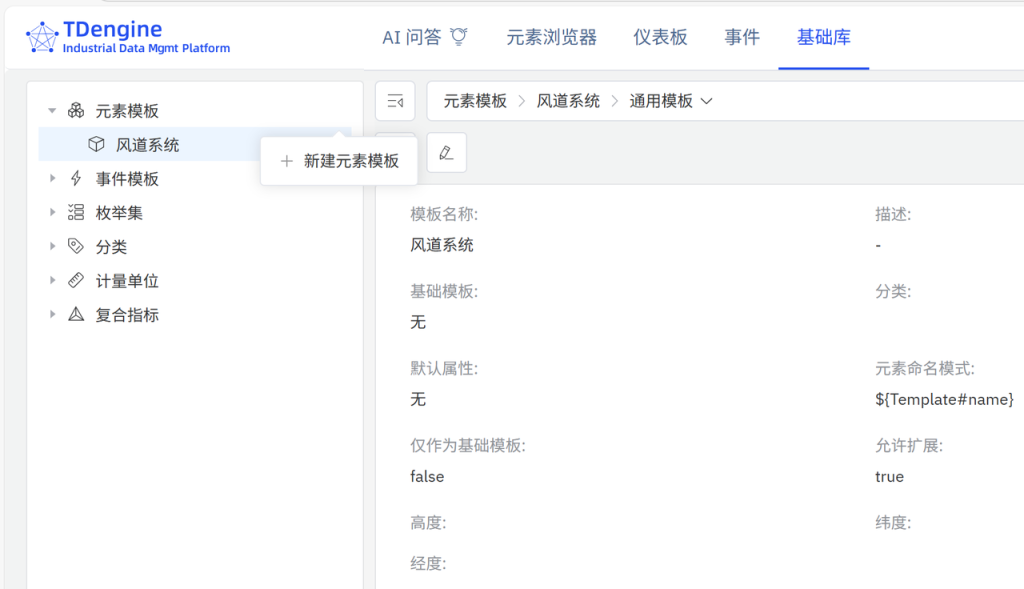
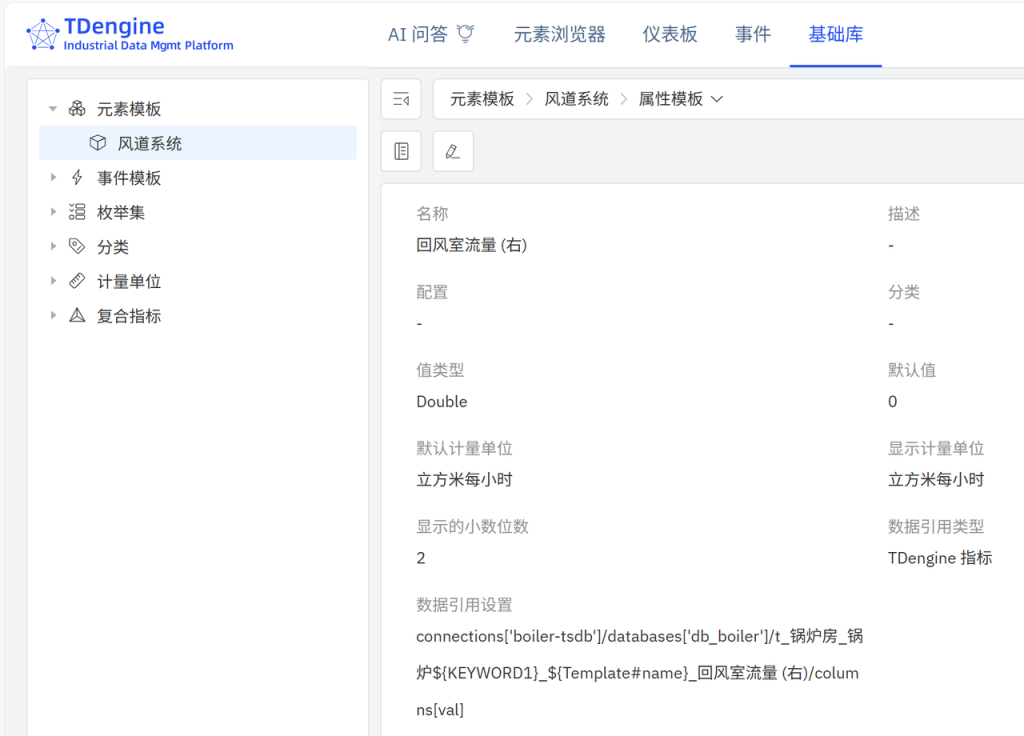
在弹出的【数据引用表达式】填写:【连接】boiler-tsdb;【数据库】db_boiler;【源表名称模式】t_锅炉房_锅炉${KEYWORD1}_${Template#name}_回风室流量 (右);【列】val
首次添加 ${KEYWORD1} 时,系统要求【请输入关键字描述】,此处填写 请输入锅炉编号(正整数)
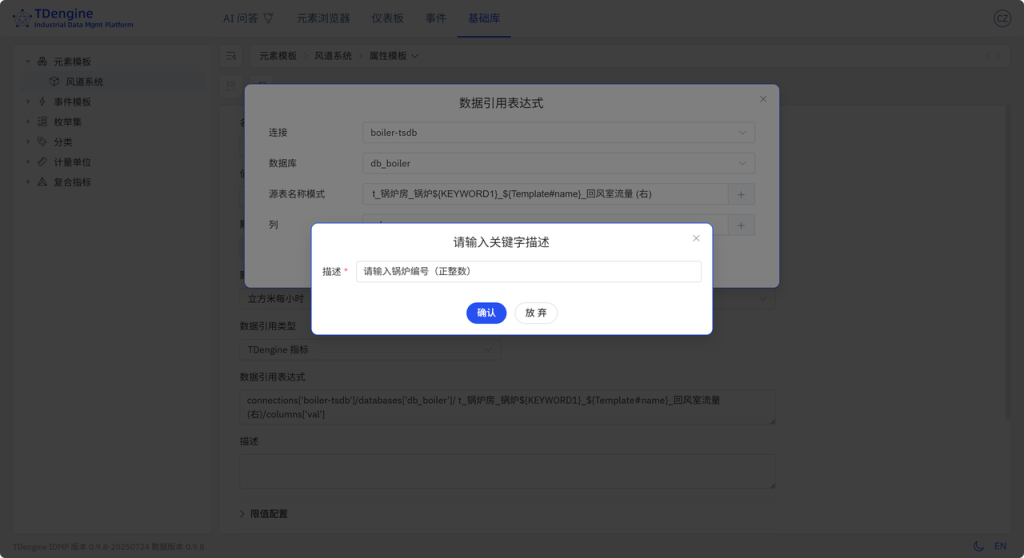
说明:
- 替换字符串 KEYWORD 在具体的元素模板内有效,同个元素模板内如果用到相同 KEYWORD,只需创建一次。
- 如果是手工新建的元素模板也用到 KEYWORD,必须点【+】显式创建;如果是通过复制元素模板,则不用。
复制属性模板回风室流量 (右),粘贴并编辑得出另一个属性模板回风室流量 (左)。最终得到效果如下:

按照上述方法,创建出所有7个元素模板。完整的配置过程参见:锅炉_元素模板.csv
锅炉_元素模板下载
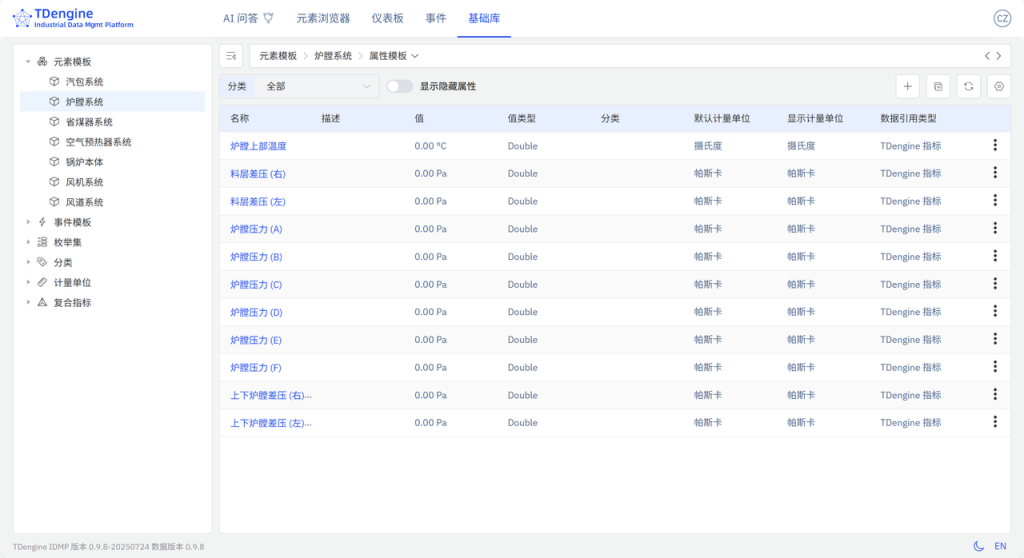
说明:
- 属性模板可以跨元素模板复制粘贴,但每个元素模板里都需要建自己的 KEYWORD。
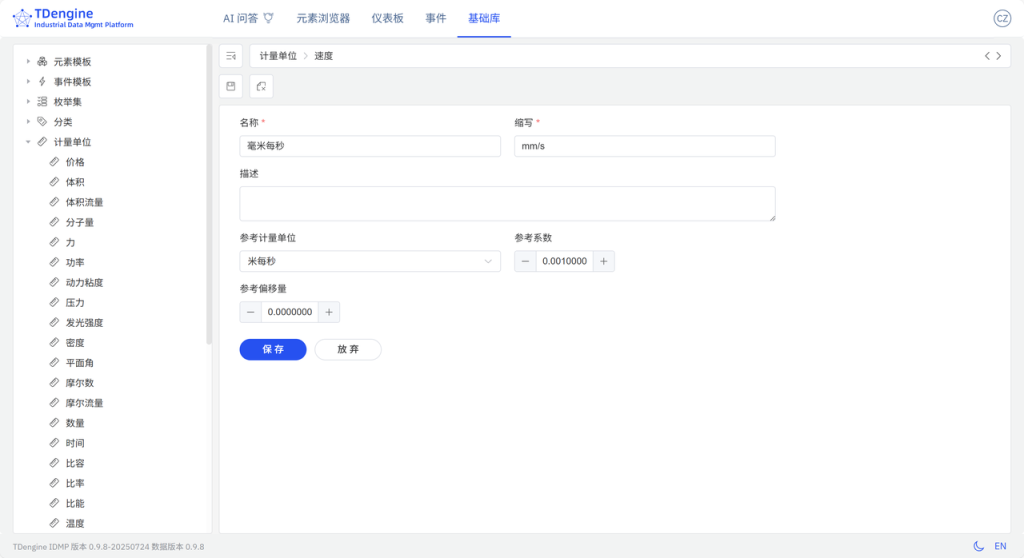
- IDMP 已内置了各种计量单位,如有需要扩展的,可在【基础库】->【计量单位】里扩展。本示例中,扩展了计量单位
mm/s用在引风机轴承振动。
3.6 创建资产模型
【元素浏览器】->【元素】,按层级依次构建 化工厂 > 锅炉房,在元素 锅炉房【新建子元素】锅炉1 和 锅炉2。
选择元素 锅炉1,【新建子元素】,【模板】选 风道系统,【KEYWORD1】填 1
按上述步骤,依次选择不同的元素模板创建出 锅炉1 和 锅炉2 的所有子元素。最终得到资产模型如下:
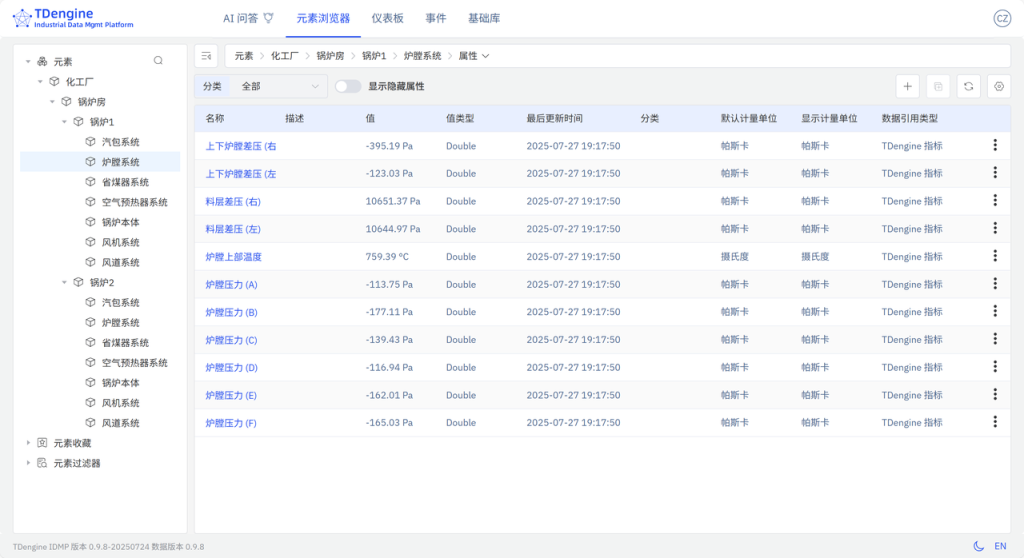
在【元素浏览器】中,IDMP 会自动根据资产模型的路径信息,以树形结构的方式展示装置的监控参数。
3.7 体验 AI 生成面板
- 在左侧资源浏览器中,点击
化工厂 > 锅炉房 > 锅炉1 > 炉膛系统元素,通过上方路径导航菜单选择【面板】,跳转至该元素的 AI 推荐面板页面。 - 等待 AI 生成面板推荐后,您可根据需求进行选择,例如:“过去一小时每分钟的炉膛压力 (C)变化”,在您感兴趣的面板右上方的菜单中,点击【生成】按钮。等待面板生成后,可以【查看】该面板。
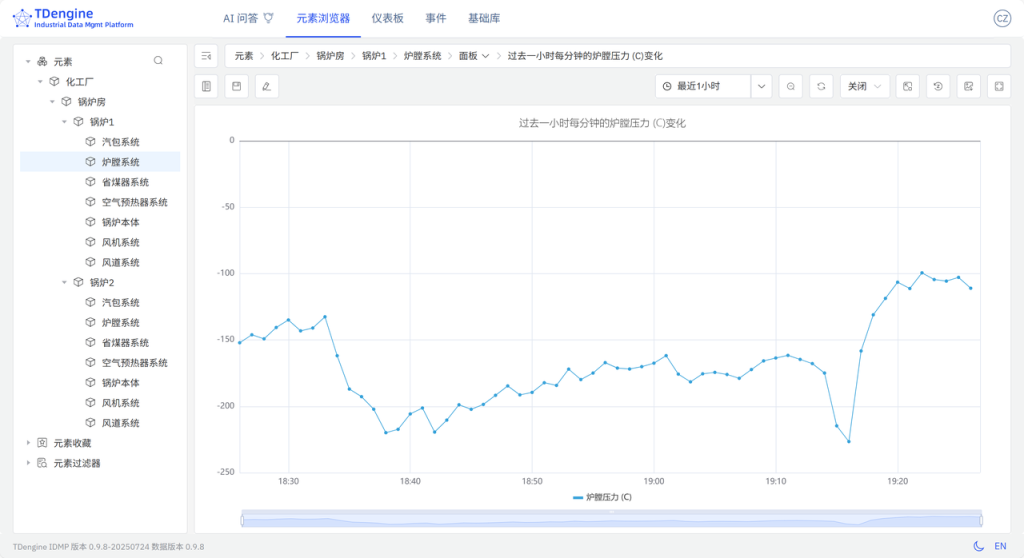
- 面板生成后,您还可以在该面板的详情页面中选择【高级】,查看 AI 创建面板时使用的 SQL 语句:
SELECT _wstart,AVG(`炉膛压力 (C)`) AS `炉膛压力 (C)`FROM `idmp`.`vt_炉膛系统_162502`WHERE _c0 >= now-1h and _c0 <= now INTERVAL(1m);
- 点击【保存】,即可在下方面板列表中查看
炉膛系统元素下对应的面板。
3.8 体验 AI 分析
- 在左侧资源浏览器中,点击
化工厂 > 锅炉房 > 锅炉1 > 炉膛系统元素,通过上方路径导航菜单选择【分析】,跳转至该元素的 AI 推荐分析页面。 - 等待 AI 生成分析问题推荐后,您可以根据需求进行选择,例如:“炉膛系统:炉膛系统的实时炉膛上部温度超过300°C持续超过15分钟时,严重告警,计算平均温度,事件窗口”,点击您感兴趣的问题链接,以进入分析编辑页面,点击页面最下方的【保存】。
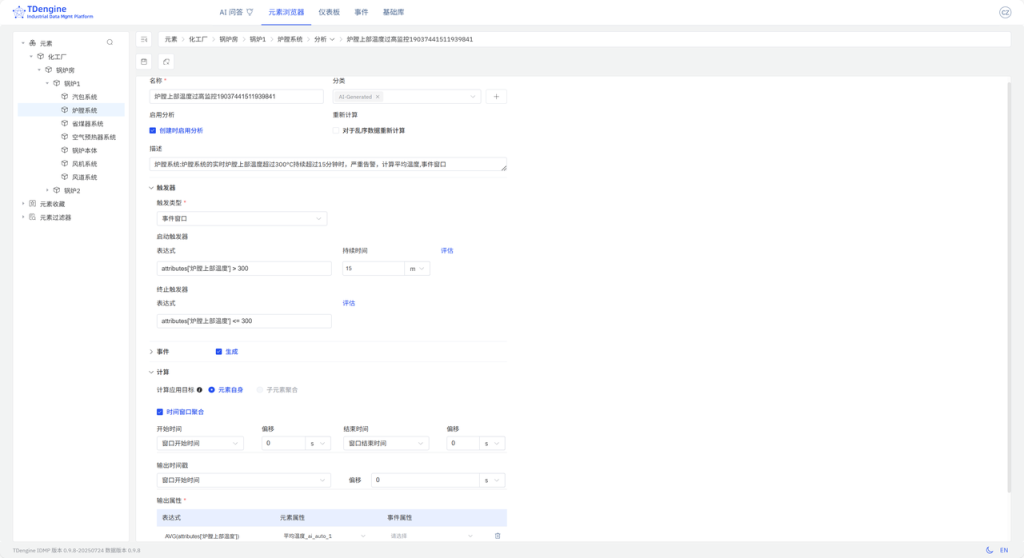
- 退回到分析列表中,即可查看对应的分析。
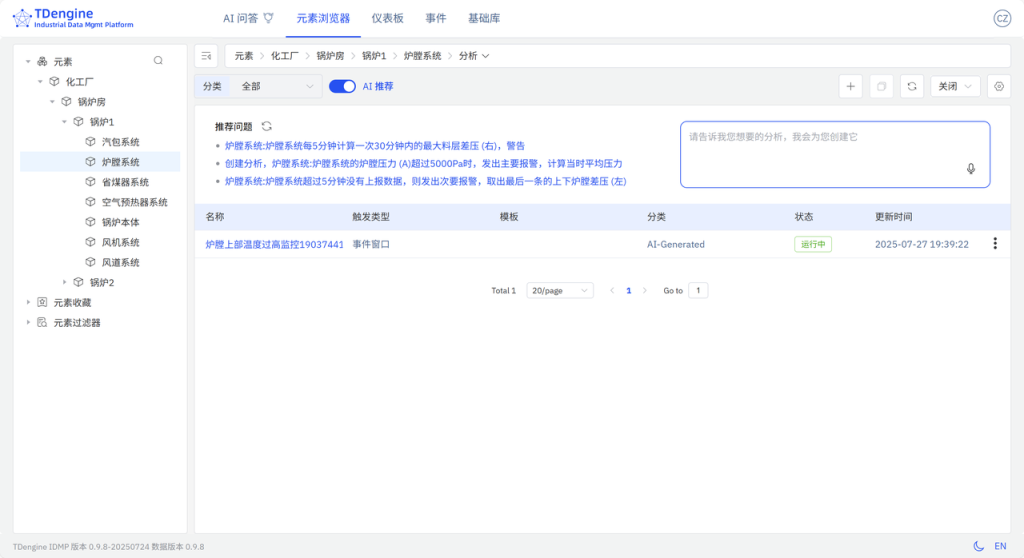
4. 更多
除了使用云服务以外,TDengine 还支持以私有化部署。为了简化部署,我们提供了 Ansible, Docker/Dcoker Compose, Helm 等多种部署方式,详见:https://github.com/taosdata/tdengine-idmp-deployment
5. 构建资产模型的建议
- 本示例是典型的工业 OPC “单列模型”的场景。但同类设备有多个,在 IDMP 中通过元素模板去创建资产模型,不仅把“单列模型”转换为“多列模型”,并且添加同类设备的效率也大大提升。
- 本示例中,设备(锅炉)的子元素较多,属性也较多,需配置7个元素模板。IDMP 今后的版本,将支持用 CSV 编辑资产模型,上传,批量创建,可以进一步提高资产模型的构建速度。
6. 小结
本文以 Step by Step 的方式,介绍了如何使用 KEPServer + TDengine TSDB + TDengine IDMP 快速搭建一个 工业装置 的监控系统。以往需要几天、甚至几周,并进行繁琐的配置、调试才能搭建起来的系统,使用 TDengine IDMP 后,30分钟内即可搞定。日后,如果有新的装置、设备系统需要被纳入到监控系统中,只需选择元素模板创建元素即可。如果监控的点位有变更或新增,仅需更新元素模板里相应的属性模板即可,无需操作其他地方。
搭建整个监控系统的工作几乎都在 KEPServer 的配置 以及 构建资产模型,无需编写复杂的 SQL 语句,无需脚本和其他配置,无需学习 Grafana,无需了解多少 工业装置 知识,即可轻松掌握 工业装置 的运行状态,实时监控和分析 工业装置 的工况并采取相应措施。
关于 TDengine
TDengine 专为物联网IoT平台、工业大数据平台设计。其中,TDengine TSDB 是一款高性能、分布式的时序数据库(Time Series Database),同时它还带有内建的缓存、流式计算、数据订阅等系统功能;TDengine IDMP 是一款AI原生工业数据管理平台,它通过树状层次结构建立数据目录,对数据进行标准化、情景化,并通过 AI 提供实时分析、可视化、事件管理与报警等功能。