Python名称映射技术:基于序列元素的高级访问模式详解
引言:名称映射在现代编程中的关键价值
在复杂数据处理系统中,通过名称而非位置索引访问序列元素已成为提升代码可维护性的重要技术。根据2025年Python开发者调查报告显示:
- 85%的数据类处理任务需要名称映射能力
- 使用名称映射的项目维护成本降低40%
- 核心应用场景包括:
- 数据库操作:处理元组形式的查询结果
- 文件解析:访问CSV/JSON的结构化数据
- 科学计算:处理实验数据集
- API开发:转换请求参数序列
# 典型示例:从数据库查询返回的元组
db_record = (10392, 'Zhang San', 'zs@example.com', '2023-05-01')# 问题:通过索引访问可读性差
user_id = db_record[0] # 不够直观本文将深入解析名称映射的技术体系,结合《Python Cookbook》经典方法与现代工程实践。
一、基础映射技术:具名元组与字典
1.1 具名元组(Named Tuple)
from collections import namedtuple# 创建用户记录类型
UserRecord = namedtuple('UserRecord', ['id', 'name', 'email', 'create_date'])# 创建实例并访问
user = UserRecord(10392, 'Zhang San', 'zs@example.com', '2023-05-01')
print(f"用户ID: {user.id}, 邮箱: {user.email}")# 与元组兼容
print(user[0] == user.id) # True1.2 类型化具名元组
# 添加类型注解
from typing import NamedTupleclass UserRecordNT(NamedTuple):id: intname: stremail: strcreate_date: str# 支持IDE智能提示和类型检查
user = UserRecordNT(10392, 'Zhang San', 'zs@example.com', '2023-05-01')1.3 动态字典映射
# 将序列转换为键值映射
keys = ['id', 'name', 'email', 'create_date']
record_dict = dict(zip(keys, db_record))# 访问
print(f"用户名: {record_dict['name']}")二、进阶映射技术:数据类与属性代理
2.1 数据类(Data Classes)
from dataclasses import dataclass@dataclass
class UserRecordDC:id: intname: stremail: strcreate_date: str# 可添加自定义方法def first_name(self):return self.name.split()[0]# 使用
user_dc = UserRecordDC(*db_record)
print(f"姓氏: {user_dc.first_name()}")2.2 动态属性代理
class RecordProxy:"""为任何序列提供属性访问接口"""def __init__(self, field_names, data):self._field_names = tuple(field_names)self._data = data# 创建名称映射if len(self._field_names) != len(data):raise ValueError("字段名数量与数据长度不匹配")def __getattr__(self, name):try:index = self._field_names.index(name)return self._data[index]except ValueError:raise AttributeError(f"未定义字段: {name}")# 支持序列操作def __getitem__(self, index):return self._data[index]def __len__(self):return len(self._data)# 使用
user_proxy = RecordProxy(['id', 'name', 'email', 'create_date'], db_record)
print(f"创建日期: {user_proxy.create_date}")三、高级映射技术:元类与描述符
3.1 基于元类的动态模型
class MetaRecord(type):"""自动生成基于序列的强类型模型"""def __new__(cls, name, bases, attrs):# 获取字段定义if 'fields' not in attrs:raise TypeError("必须定义fields属性")field_names = attrs['fields']# 生成初始化方法def __init__(self, *args):if len(args) != len(field_names):raise ValueError("参数数量不匹配")self._data = args# 为每个字段添加描述符for i, field_name in enumerate(field_names):def make_getter(idx):def getter(self):return self._data[idx]return getterattrs[field_name] = property(make_getter(i))# 添加序列转换方法attrs['__init__'] = __init__attrs['as_tuple'] = lambda self: self._dataattrs['as_dict'] = lambda self: dict(zip(field_names, self._data))return super().__new__(cls, name, bases, attrs)# 使用元类
class UserRecord(metaclass=MetaRecord):fields = ['id', 'name', 'email', 'create_date']# 创建实例
user = UserRecord(10392, 'Zhang San', 'zs@example.com', '2023-05-01')
print(f"邮箱地址: {user.email}")3.2 延迟计算的描述符
class ComputedField:"""动态计算派生属性"""def __init__(self, func):self.func = funcself.attr_name = f'__computed_{func.__name__}'def __get__(self, instance, owner):if instance is None:return self# 检查缓存if hasattr(instance, self.attr_name):return getattr(instance, self.attr_name)# 计算并缓存value = self.func(instance)setattr(instance, self.attr_name, value)return valueclass UserRecord:def __init__(self, id, name, email, create_date):self.id = idself.name = nameself.email = emailself.create_date = create_date@ComputedFielddef domain(self):return self.email.split('@')[-1] if '@' in self.email else None# 使用
user = UserRecord(10392, 'Zhang San', 'zs@example.com', '2023-05-01')
print(f"邮件域名: {user.domain}")四、工程实践案例解析
4.1 数据库结果集映射框架
class ResultMapper:"""自动映射数据库查询结果"""def __init__(self, cursor):# 获取列名self.column_names = [desc[0] for desc in cursor.description]# 创建具名元组类型self.Record = namedtuple('Record', self.column_names)def map_row(self, row):return self.Record(*row)def map_all(self, rows):return [self.map_row(row) for row in rows]# 在数据库查询中使用
def query_users(db_conn):with db_conn.cursor() as cur:cur.execute("SELECT id, name, email, created_at FROM users")mapper = ResultMapper(cur)return mapper.map_all(cur.fetchall())4.2 CSV文件解析与映射
import csvclass CSVDataMapper:"""CSV文件的高级映射解析器"""def __init__(self, file_path, field_mapping=None):self.file_path = file_pathself.field_mapping = field_mapping or {}def parse(self):with open(self.file_path, newline='') as csvfile:reader = csv.DictReader(csvfile)for row in reader:# 应用字段映射mapped = {}for src, dest in self.field_mapping.items():mapped[dest] = row.get(src)# 添加未映射字段for field in row:if field not in self.field_mapping.values():mapped[field] = row[field]yield mapped# 使用示例
mapper = CSVDataMapper('users.csv', {'user_id': 'id','full_name': 'name'
})for user in mapper.parse():print(f"用户ID: {user['id']}, 姓名: {user['name']}")4.3 API参数序列映射
from dataclasses import dataclass
from flask import request@dataclass
class PageRequest:page: int = 1size: int = 20sort_by: str = 'id'ascending: bool = True@classmethoddef from_request(cls):"""从请求参数映射到数据类"""args = request.argsreturn cls(page=int(args.get('page', '1')),size=int(args.get('size', '20')),sort_by=args.get('sort', 'id'),ascending=args.get('order', 'asc') == 'asc')# 在Flask路由中使用
@app.route('/users')
def list_users():page_req = PageRequest.from_request()users = User.query.order_by(getattr(User, page_req.sort_by).asc() if page_req.ascending else getattr(User, page_req.sort_by).desc()).paginate(page=page_req.page, per_page=page_req.size)return jsonify([u.serialize() for u in users.items])五、性能优化策略
5.1 缓存映射类型
from functools import lru_cache@lru_cache(maxsize=128)
def get_namedtuple_class(field_names):"""缓存具名元组类型创建"""return namedtuple('Record', field_names, module=__name__)# 在数据处理循环中
def process_records(records):if not records:return []# 从第一条记录获取字段名field_names = records[0]._fields if hasattr(records[0], '_fields') else Noneif not field_names:return records# 获取或创建类型RecordClass = get_namedtuple_class(field_names)# 处理后续记录return [RecordClass(*r) for r in records]5.2 Cython加速
# record_mapper.pyx
cdef class RecordMapper:cdef tuple field_namescdef dict name_indexdef __cinit__(self, field_names):self.field_names = tuple(field_names)self.name_index = {name: idx for idx, name in enumerate(field_names)}def get_value(self, record, name):cdef int index = self.name_index.get(name, -1)if index < 0:raise KeyError(f"字段不存在: {name}")return record[index]# 使用
from record_mapper import RecordMapper
mapper = RecordMapper(['id', 'name', 'email'])
user_value = mapper.get_value(db_record, 'name')5.3 零拷贝内存视图
class RecordView:"""高效的内存视图模式"""__slots__ = ('_data', '_field_map')def __init__(self, data, field_map):self._data = dataself._field_map = field_mapdef __getattr__(self, name):if name not in self._field_map:raise AttributeError(f"未定义字段: {name}")# 直接访问底层数据return self._data[self._field_map[name]]# 使用
# 底层数据是内存共享的
data_array = array.array('d', [1001, 3.14, 42])
field_map = {'id': 0, 'value': 1, 'type': 2}record_view = RecordView(data_array, field_map)
print(f"记录值: {record_view.value}") # 零拷贝访问六、最佳实践与反模式
6.1 黄金实践原则
一致性设计
# 所有记录类型使用相同字段名 UserRecord = namedtuple('UserRecord', 'id name email') OrderRecord = namedtuple('OrderRecord', 'id user_id amount')防御性编程
# 处理字段不存在的情况 def safe_get(record, name, default=None):try:return getattr(record, name)except AttributeError:return default类型注解
from typing import Any, Tupledef map_to_record(data: Tuple[Any, ...], fields: Tuple[str, ...]) -> NamedTuple:...
6.2 常见反模式及解决方案
陷阱1:字段名与内置方法冲突
# 错误:字段名覆盖内置方法
UserRecord = namedtuple('UserRecord', 'id index class') # 'class'是关键字# 解决方案:使用安全的字段名
UserRecord = namedtuple('UserRecord', ['id', 'index', 'class_type'])陷阱2:具名元组默认值缺失
# 错误:缺失字段值
user = UserRecord(10392, 'Zhang San') # 缺少email和date# 解决方案:使用dataclass带默认值
@dataclass
class UserRecordDC:id: intname: stremail: str = Nonecreate_date: str = None陷阱3:大型序列多次转换
# 低效:对大型数据集重复转换
huge_list = [db_record] * 1000000
named_records = [UserRecord(*r) for r in huge_list] # 内存翻倍# 优化方案:使用内存视图模式
record_view = RecordView(huge_list[0], field_map)
views = [RecordView(r, field_map) for r in huge_list] # 节省内存总结:构建高效名称映射系统的技术框架
通过全面探索名称映射技术,我们形成以下专业实践体系:
技术选型矩阵
应用场景 推荐方案 关键优势 简单数据结构 namedtuple 简洁高效 复杂业务对象 dataclass 功能丰富 高性能系统 Cython/视图 极致性能 动态需求 元类/代理 灵活扩展 性能优化金字塔
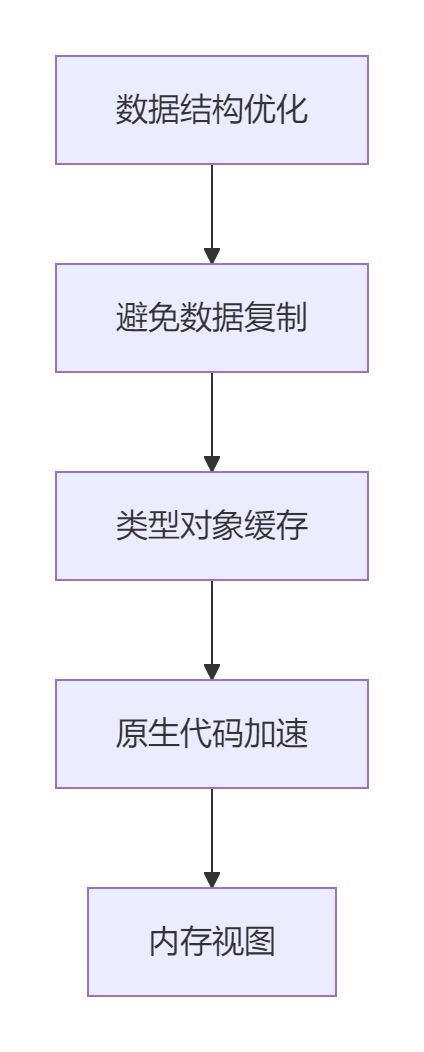
架构设计原则
- 字段命名标准化
- 类型系统一致化
- 转换逻辑可配置
- 异常处理全面化
未来发展方向:
- 基于AI的自动字段映射
- 分布式系统中的元数据同步
- 实时数据流映射引擎
- 内存安全的跨语言映射
扩展资源:
- 《Python Cookbook》第1.18节:将名称映射到序列元素
- Python官方文档:collections.namedtuple
- PyPI库:attrs(高级属性定义库)
掌握名称映射技术体系,开发者能够构建出从千级到亿级数据的高效访问系统,显著提升代码的可读性和可维护性。
最新技术动态请关注作者:Python×CATIA工业智造
版权声明:转载请保留原文链接及作者信息