从 “看懂图” 到 “读懂视频”:多模态技术如何用文本反哺视觉?
来gongzhonghao【图灵学术计算机论文辅导】,快速拿捏更多计算机SCI/CCF发文资讯~
分享一个当下大模型时代最“香”的研究方向:多模态融合的高效迁移。众所周知,视觉-语言大模型算力吃紧,模态鸿沟大,逼得大家不得不琢磨“用最少的参数、最轻的数据把知识搬过去。于是,研究热点齐刷刷指向:预训练-下游解耦、动态蒸馏、文本先验注入、跨模态对齐与领域泛化。
本文整理了3篇聚焦多模态融合×迁移学习的新论文,旨在帮助大家把握前沿思路,为相关研究提供参考,有需求可自取,满满干货,点赞收藏不迷路~
SimVG: A Simple Framework for Visual Groundingwith Decoupled Multi-modal Fusion
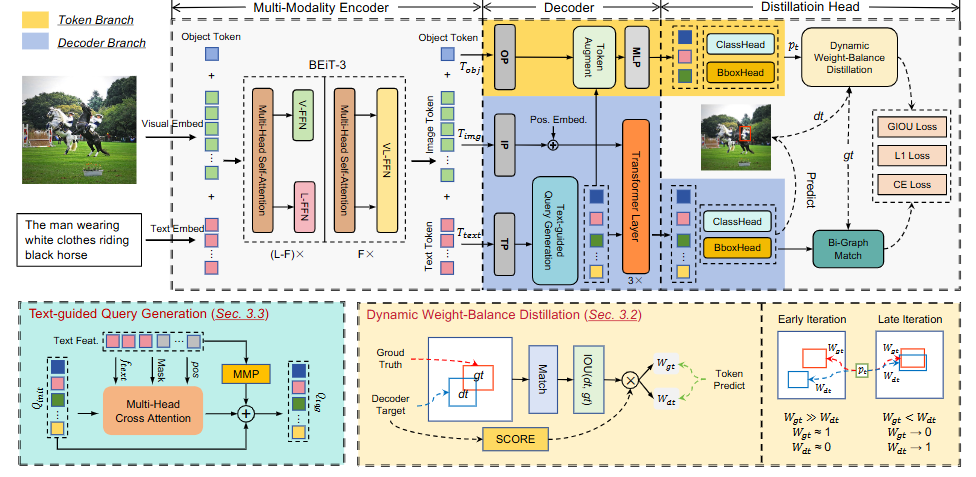
方法:SimVG 先把图像、文本与可学习的对象 token 一起送进 BEiT-3 式的多模态编码器做深层交互;随后两条并行的分支同步训练:一条是类 DETR 的解码器提供丰富监督,另一条仅含一层 MLP 的 token 分支借助 DWBD 动态权衡真值与教师预测的权重以快速收敛;推理时仅保留轻量级 token 分支即可在六个基准数据集上刷新 SOTA,同时仅用单张 RTX 3090 训练 12 小时。
创新点:
首次将视觉-语言预训练与下游任务解耦,用统一编码器同时处理图像、文本和对象 token,打破传统“先编码再融合”的范式。
提出动态权重平衡蒸馏 DWBD,让轻量级 MLP 分支在同步训练中自动向强 Transformer 解码器学习,实现精度与速度的兼得。
设计文本引导查询生成 TQG 模块,把语言先验注入对象查询,天然支持多目标或无目标的广义指代表达理解。
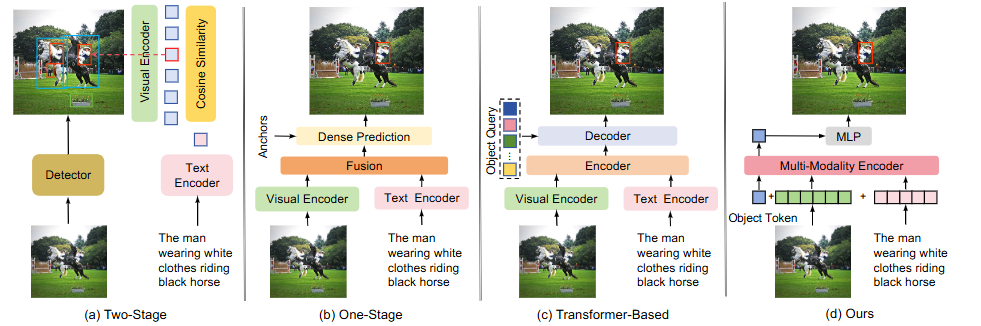
总结:这篇文章用极简框架直击视觉定位痛点——复杂文本下多模态特征难对齐,一举把视觉定位任务推向新高度。
MetaSegNet: Metadata-collaborative Vision-Language Representation Learning for Semantic Segmentation of Remote Sensing Images
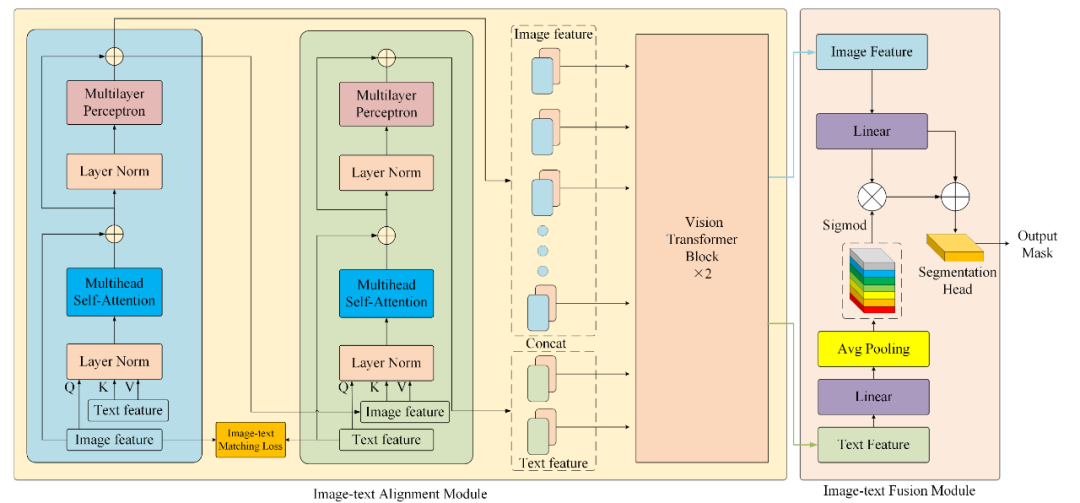
方法:MetaSegNet 以 Swin Transformer 为图像编码器,BERT 为文本编码器,先用 ChatGPT 根据元数据生成气候感知的地理提示,随后 CAFDecoder 通过图像-文本匹配损失、最后联合 Dice-CE-匹配三重损失训练,在 OpenEarthMap、Potsdam、LoveDA 三大数据集上刷新多项指标,同时实现 23.7 FPS 的实时推理。
创新点:
首次提出“元数据协同”框架,把图像自带的气候带等元数据自动转成富含地学知识的文本提示,为多模态学习提供零成本语言监督。
设计 ChatGPT 驱动的提示工厂,通过模板化提问批量产生专业级地理描述,实现遥感影像“一句话增强”。
构建即插即用的跨模态注意力融合解码器 CAFDecoder,显式对齐并深度融合图像-文本特征,显著提升植被等类别在零样本场景下的精度。
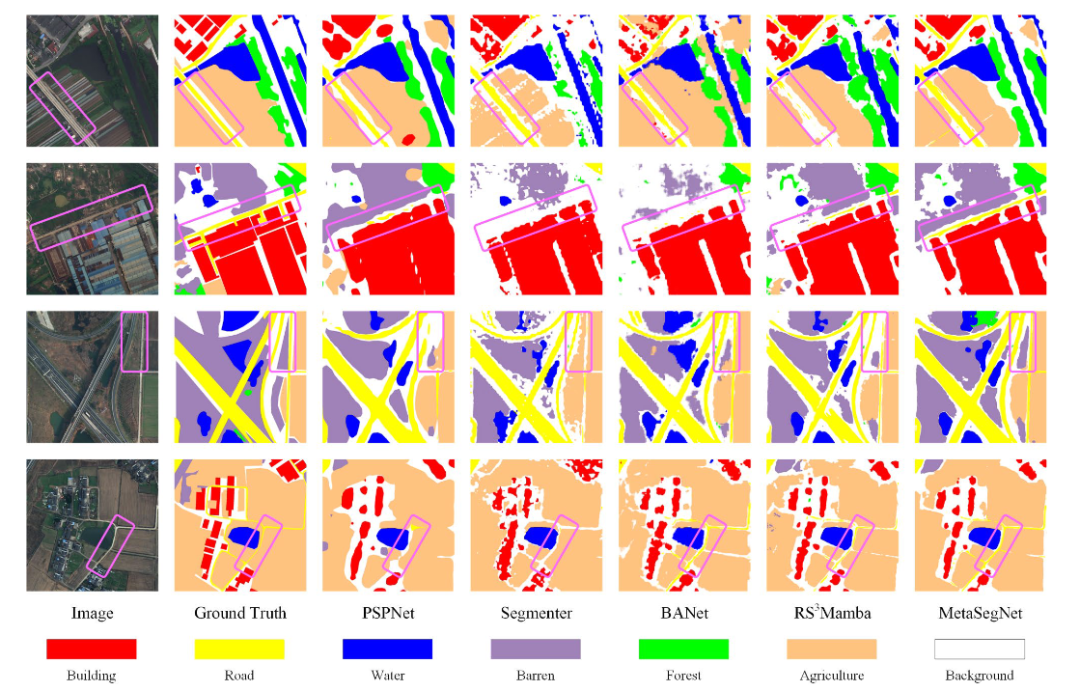
总结:这篇文章把遥感影像语义分割玩出了新高度:用免费元数据召唤 ChatGPT 生成地理文本提示,一举破解纯视觉模型在复杂场景下可靠性不足、跨域泛化差的顽疾。
纠结选题?导师放养?投稿被拒?对论文有任何问题的同学,欢迎来gongzhonghao【图灵学术计算机论文辅导】,获取顶会顶刊前沿资讯~
Weakly Supervised Temporal Action Localization via Dual-Prior Collaborative Learning Guided by Multimodal Large Language Models
方法:给定视频级标签后,MLLM先分别输出一句“关键动作描述”和一段“完整动作描述”,KSM将关键描述与视频片段做跨模态相似度匹配得到紧凑候选区间,CSR则在完整描述上随机掩码关键动词并通过Transformer重建以挖掘完整动作区间:KSM用CSR的完整区间弥补漏检,CSR用KSM的紧凑区间抑制过检,最终仅用轻量级WTAL模型即可在推理阶段脱离MLLM独立运行并斩获SOTA精度。
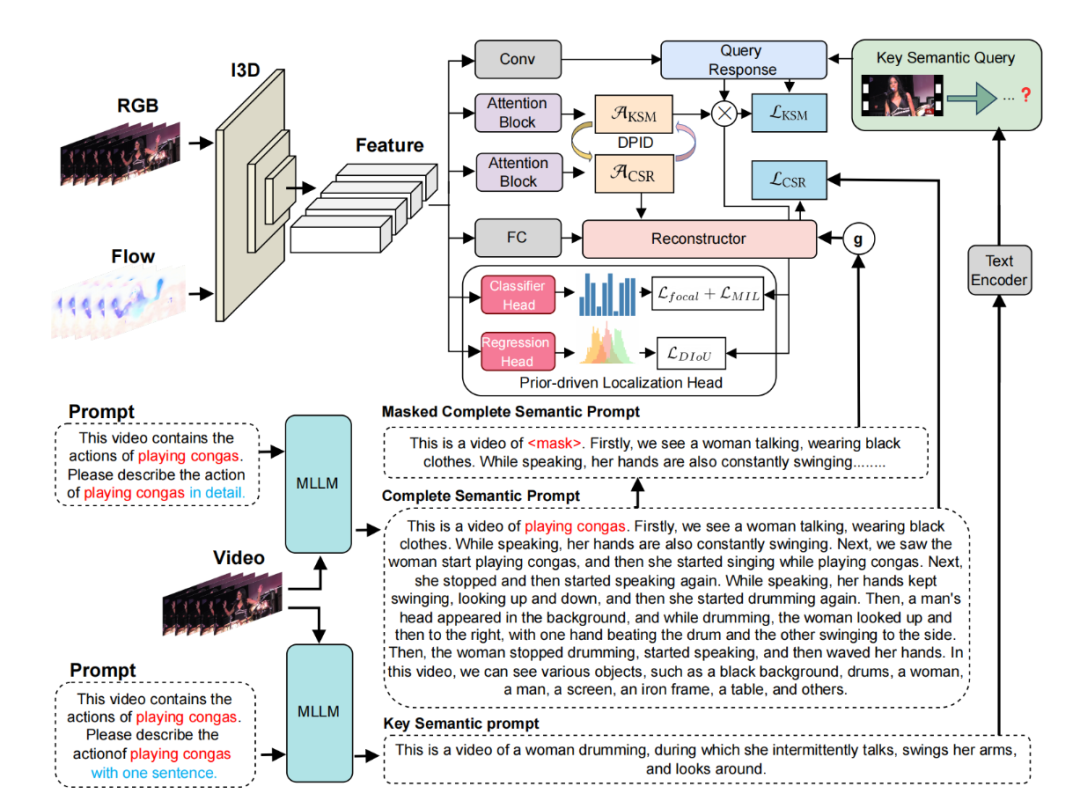
创新点:
提出MLLM4WTAL范式,在训练阶段零额外推理开销地引入大模型先验,开创WTAL与MLLM协作的新路径。
设计关键语义匹配KSM模块,用MLLM生成的动作关键词嵌入精准激活视频片段,显著抑制背景误检。
设计完整语义重构CSR模块,通过掩码语言建模重建动作全过程,最大限度找回被漏检的子动作区间。

总结:这篇文章用多模态大语言模型给传统弱监督时序动作定位WTAL输送关键与完整语义先验,一举破解“漏检”与“过检”顽疾,刷新THUMOS14与ActivityNet纪录。
来gongzhonghao【图灵学术计算机论文辅导】,快速拿捏更多计算机SCI/CCF发文资讯~