基于pytorch深度学习笔记:3.GooLeNet介绍
朋友们现在ip已经是新加坡了,7.30抵达坡坡,8.11号正式开学。适应了几天之后就得开始接着学习了,时间不等人呢,还有一个yolo要学,希望在八月结束之前能把简历更新好。
今天笔记介绍的是GooLeNet。
在2014年的ImageNet图像识别挑战赛中,一个名叫 GoogLeNet的网络架构大放异彩。以前流行的网络使用 小到1×1,大到7×7的卷积核。 本文的一个观点是,有时使用不同大小的卷积核组合是有利的。
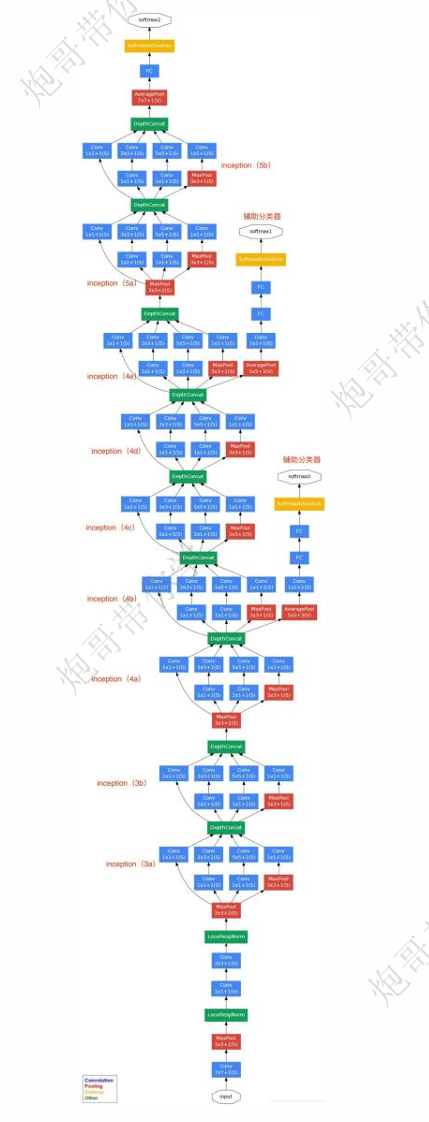
上面展示的是GooLeNet的网络架构,可以看出来相比我们先前学习的复杂度显著上升。值得一提的是2014年的ImageNet图像识别挑战赛亚军正是我们上一节学习的VGGNet,能力压VGG足以显示GoogLeNet的优良性能。
1.GooLeNet网络架构
1.1 Inception Block介绍
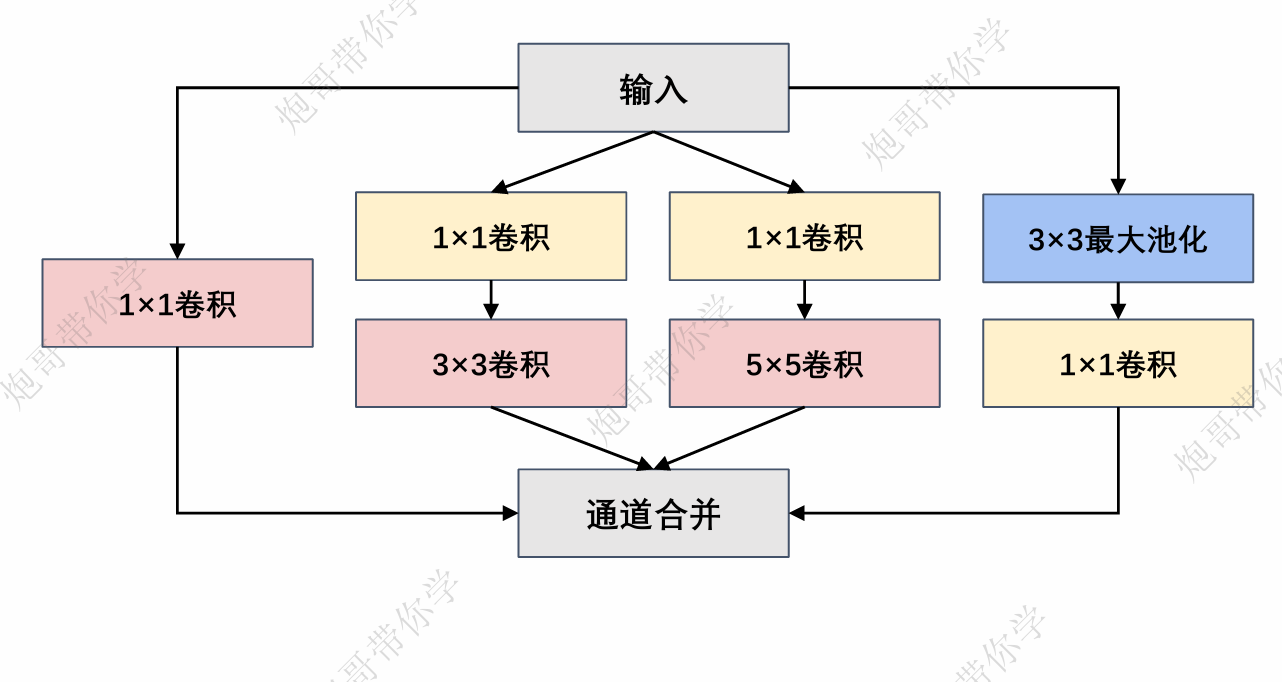
在介绍GoogLeNet网络之前,我们绕不开的一个点就是Inception Block,可以看到在前面的整体结构概述图中出现了非常多的块状结构,这也就是我们的Inception Block。在GoogLeNet中,基本的卷积块被称为 Inception块(Inception block)。这很可能得名于电影《盗梦空间》(Inception),因为电影中的一句话“我们需要走得更深”(“We need to go deeper”)。 这是由前文所提及的“使用不同大小的卷积核组合是有利的”这一思想出发所得出来的创新,也是GooLeNet的标志性突破。“不同的” Inception块由四条并行路径组成。前三条路径使用窗口大小为1×1、3×3和5×5的卷积层, 从不同空间大小中提取信息。对于我这种学习通信的学生来说,常常看到一种解释将其类比于低通和高通滤波器,提取图像不同尺度的特征。中间的两条路径在输入上执行1×1卷积,以减少通道数,从而降低模型的复杂性。第四条路径使用3×3最大池化层,然后使用1×1卷积层来改变通道数。这四条路径都使用合适的填充来使输入与输出的高和宽一致,最后我们将每条线路的输出在通道维度上连结, 并构成Inception块的输出。在Inception块中,通常调整的超参数是每层输出通道数。
接下来我们来详细介绍一下一个Inception块:
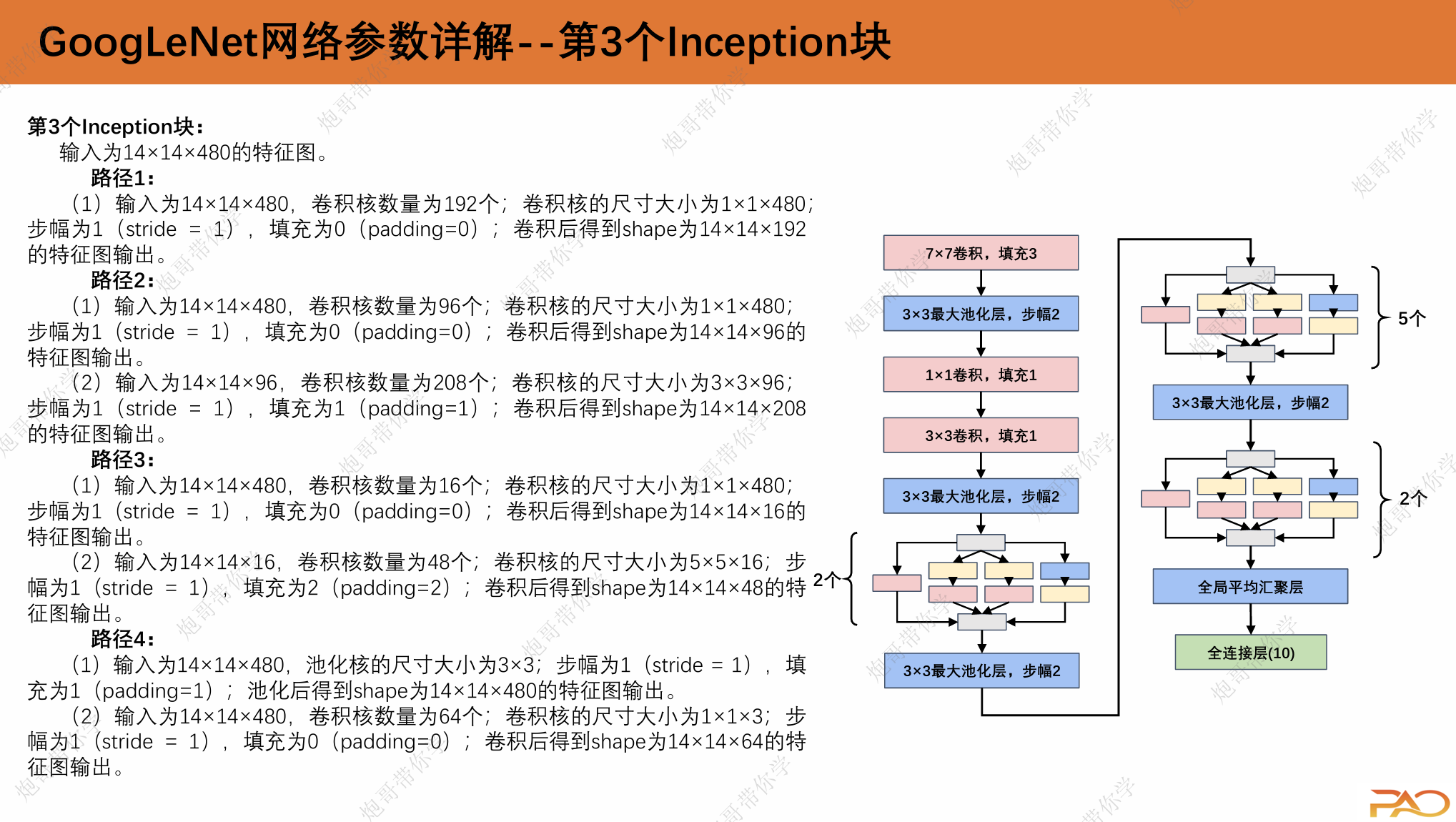
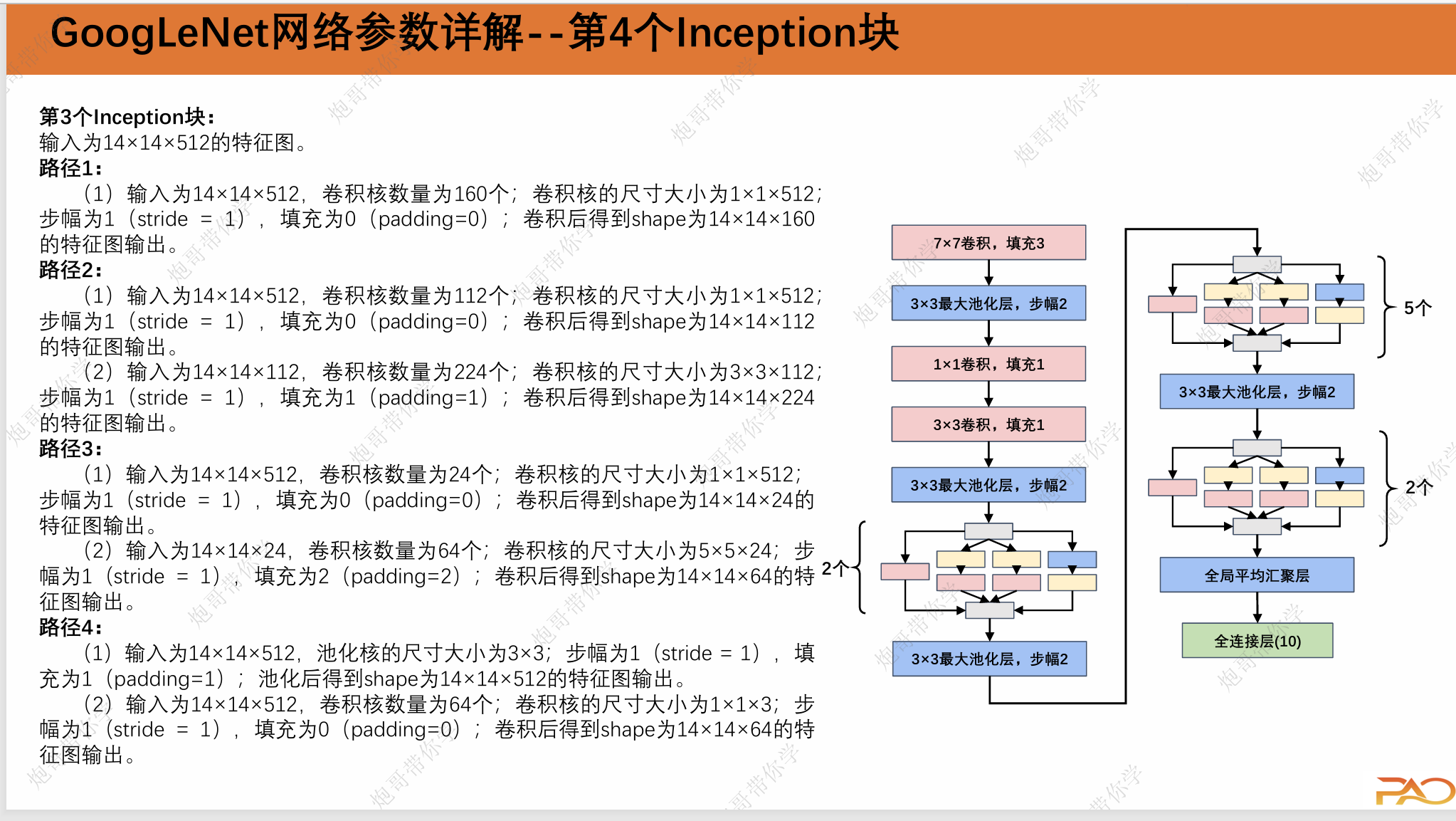
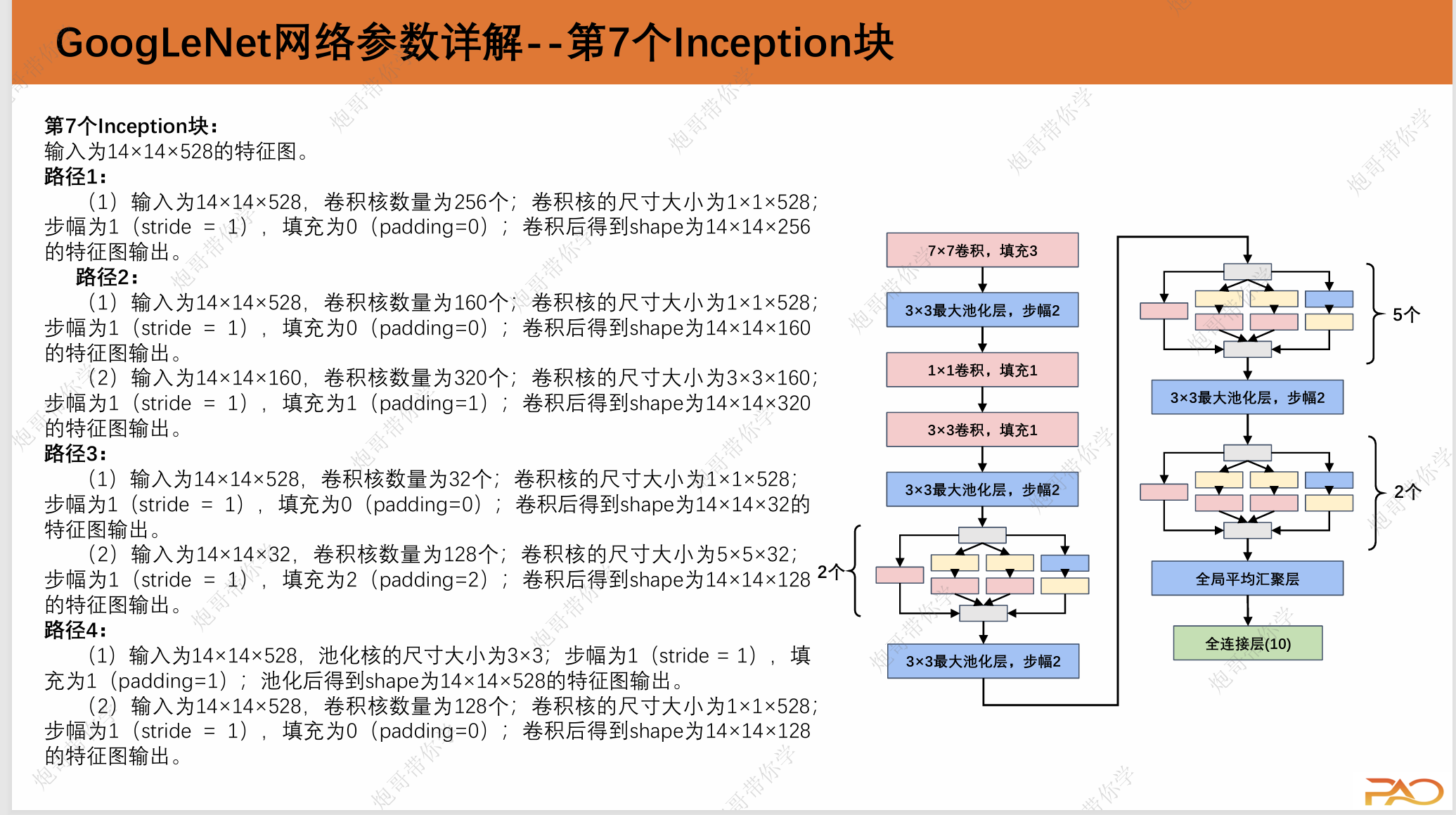
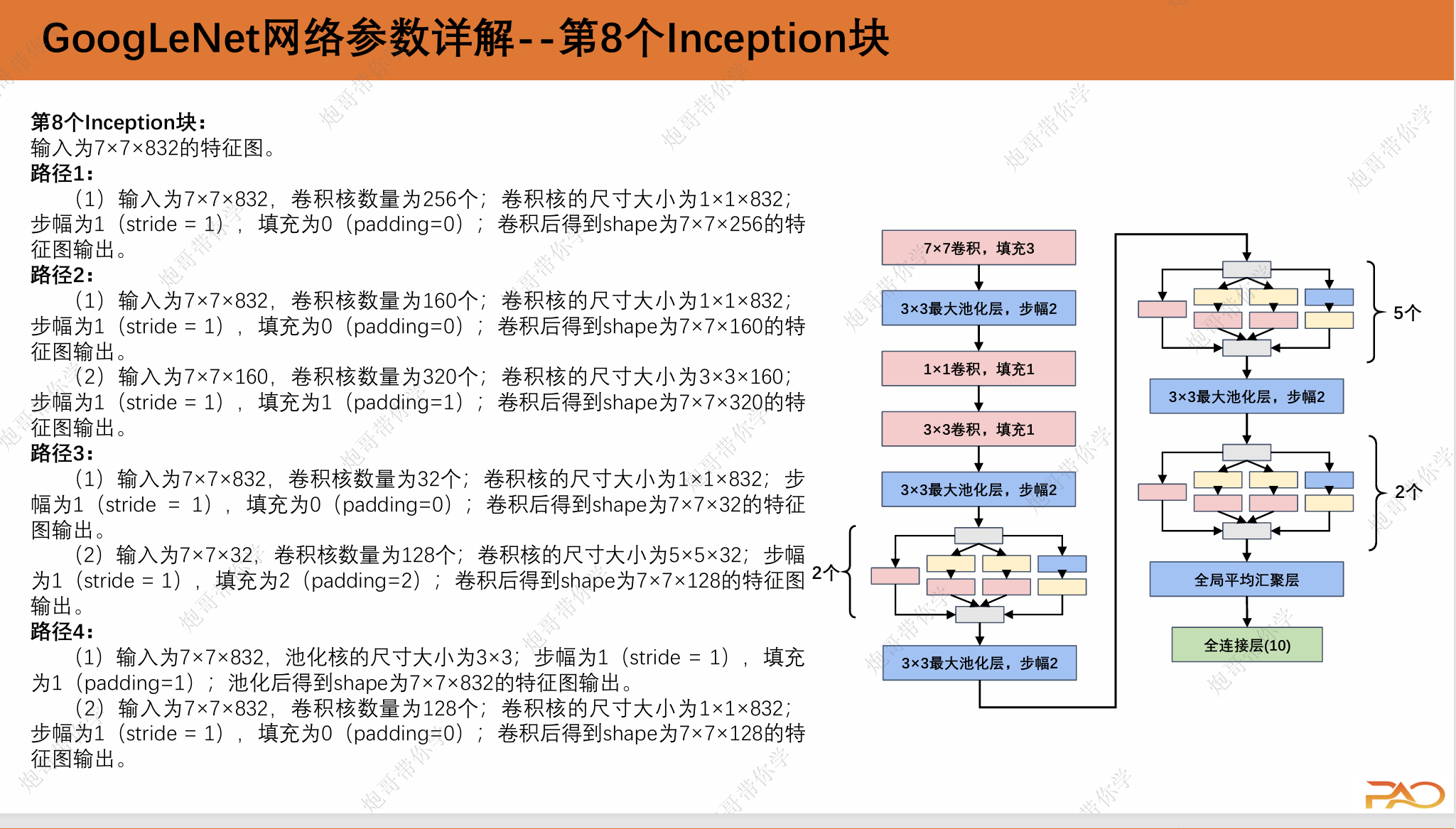
路径1:
(1)输入为224×224×3,卷积核数量为64个;卷积核的尺寸大小为1×1×3;步幅为1(stride=1), 填充为0(padding=0);卷积后得到shape为 224×224×64的特征图输出。
路径2:
(1)输入为224×224×3,卷积核数量为96个;卷 积核的尺寸大小为1×1×3;步幅为1(stride=1), 填充为0(padding=0);卷积后得到shape为 224×224×64的特征图输出。
(2)输入为224×224×64,卷积核数量为128个; 卷积核的尺寸大小为3×3×64;步幅为1(stride= 1),填充为1(padding=1);卷积后得到shape为224×224×128的特征图输出。
路径3:
(1)输入为224×224×3,卷积核数量为16个;卷积核 的尺寸大小为1×1×3;步幅为1(stride=1),填充为 0(padding=0);卷积后得到shape为224×224×16的 特征图输出。
(2)输入为224×224×16,卷积核数量为32个;卷积 核的尺寸大小为5×5×16;步幅为1(stride=1),填 充为2(padding=2);卷积后得到shape为 224×224×32的特征图输出。
路径4:
(1)输入为224×224×3,池化核的尺寸大小为3×3; 步幅为1(stride=1),填充为1(padding=1);池 化后得到shape为224×224×3的特征图输出。
(2)输入为224×224×3,卷积核数量为32个;卷积核 的尺寸大小为1×1×3;步幅为1(stride=1),填充为 0(padding=0);卷积后得到shape为224×224×32的特征图输出。
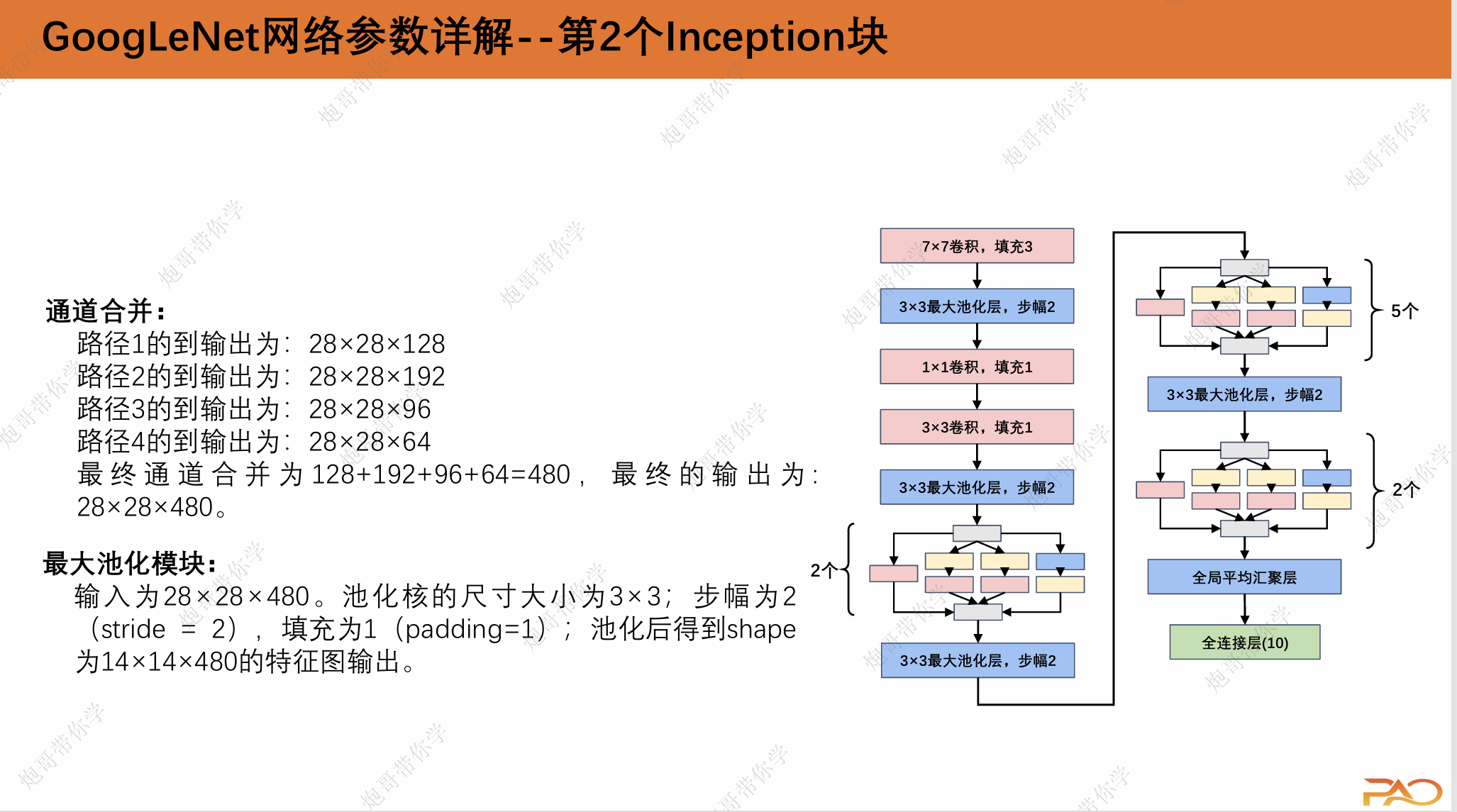
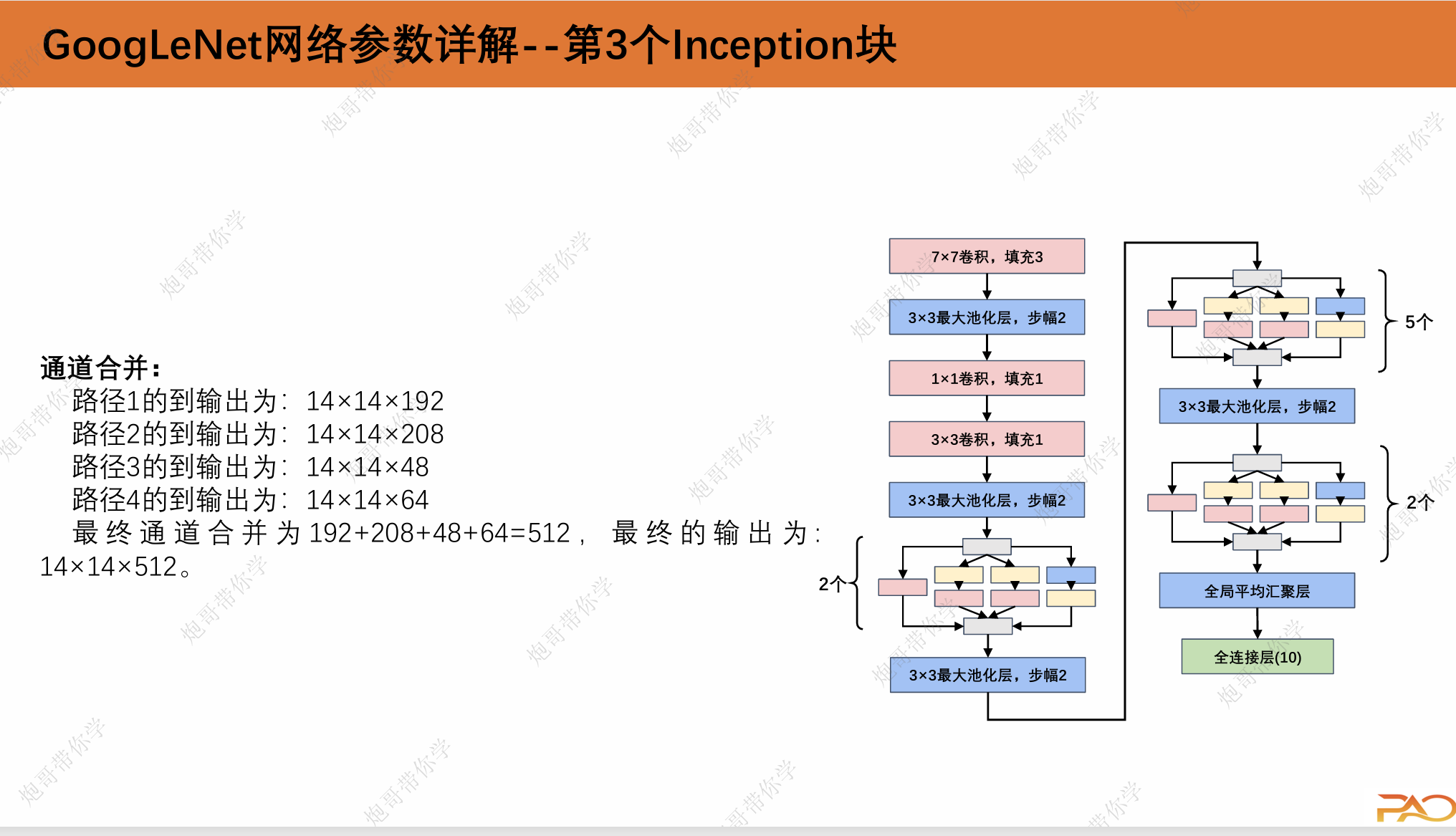
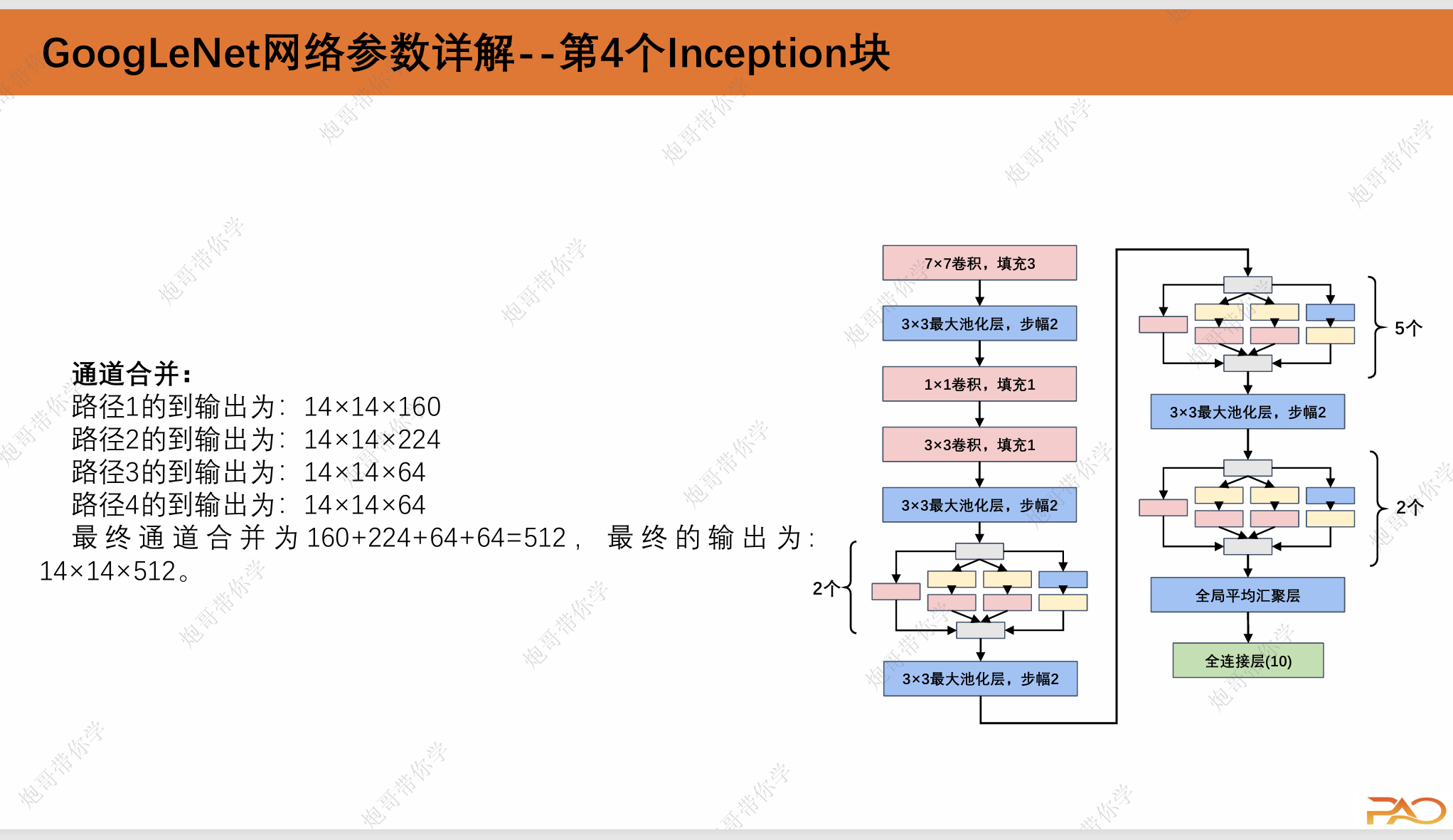
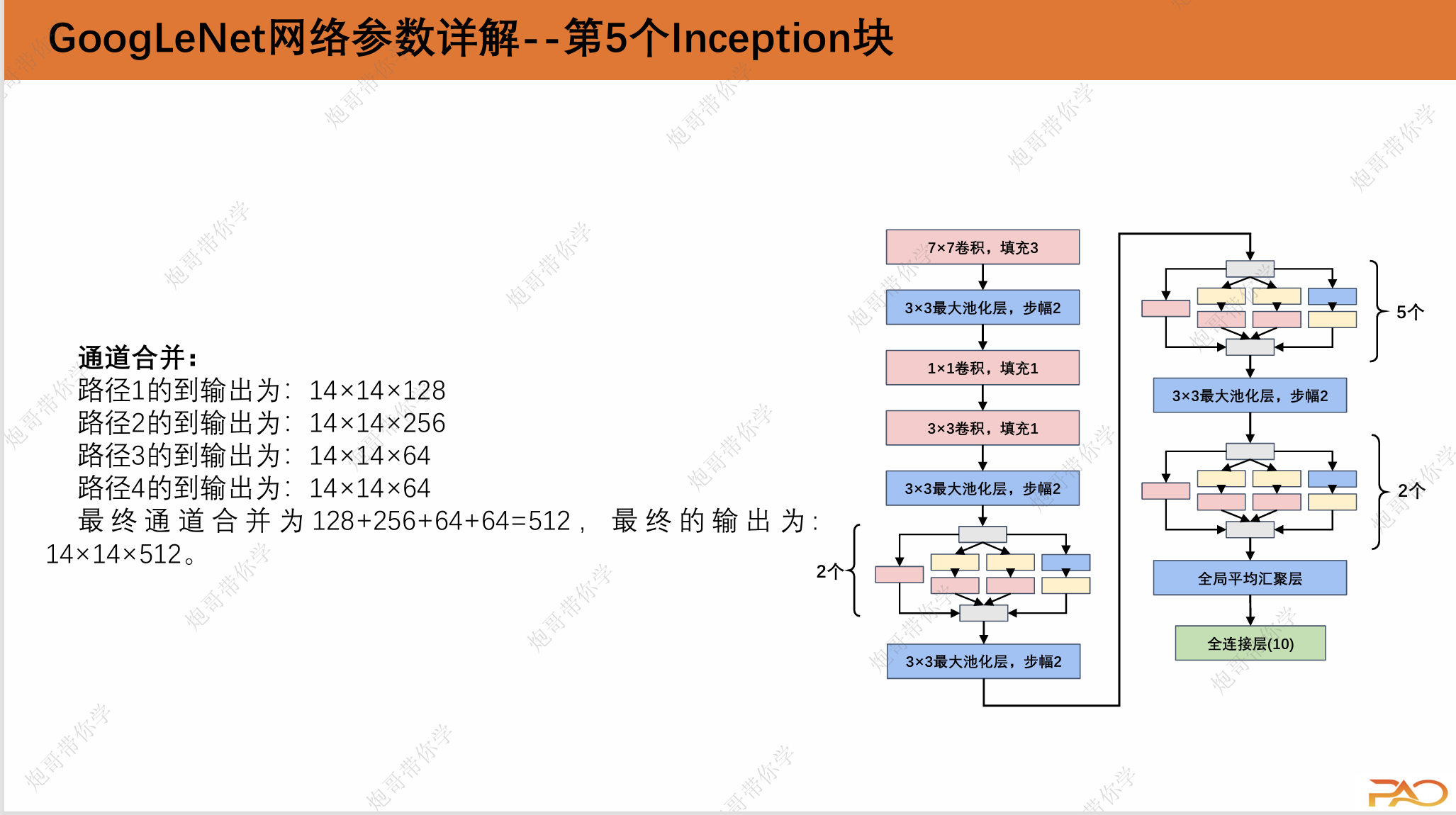
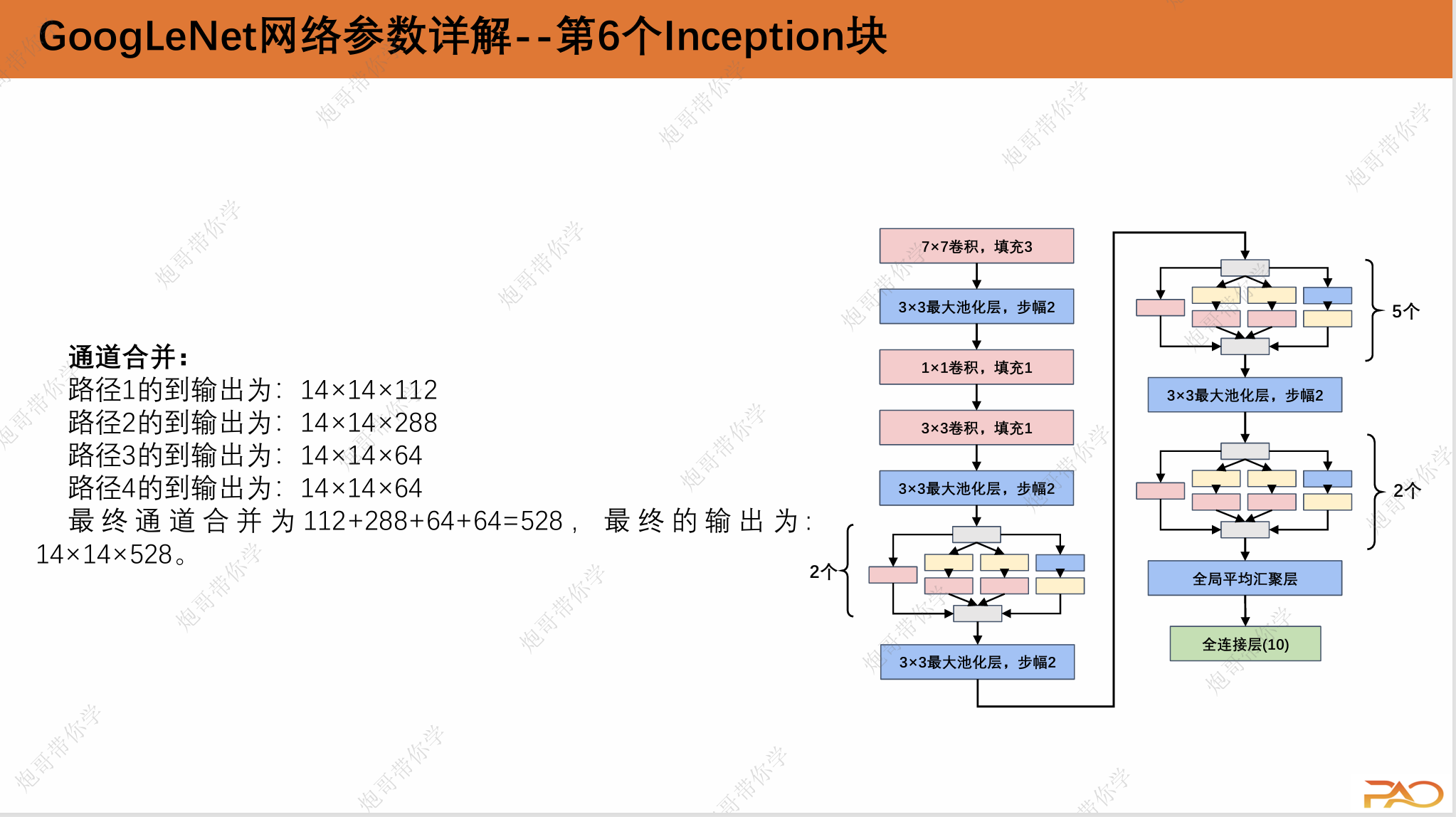
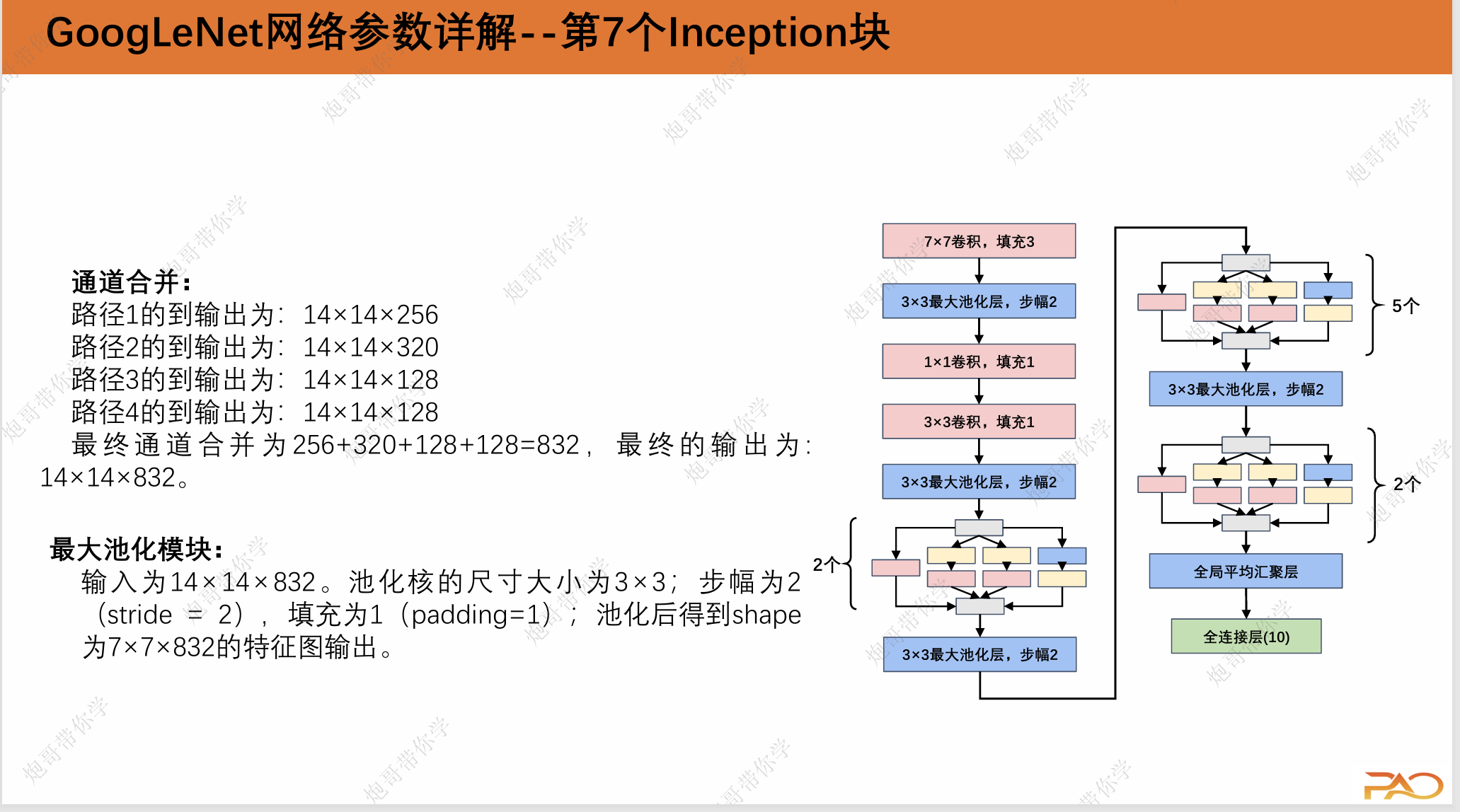
通道合并:
路径1的到输出为:224×224×64
路径2的到输出为:224×224×128
路径3的到输出为:224×224×32
路径4的到输出为:224×224×32
最终通道合并为64+128+32+32=256,最终的输出为: 224×224×256。
那么为什么GoogLeNet这个网络如此有效呢?首先我们考虑一下滤波器(filter)的组合,它们可以用各种滤 波器尺寸探索图像,这意味着不同大小的滤波器可以有效地识别不同范围的图像细节。同时,我们可以为不同的滤波器分配不同数量的参数
1.2 Inception的技术细节
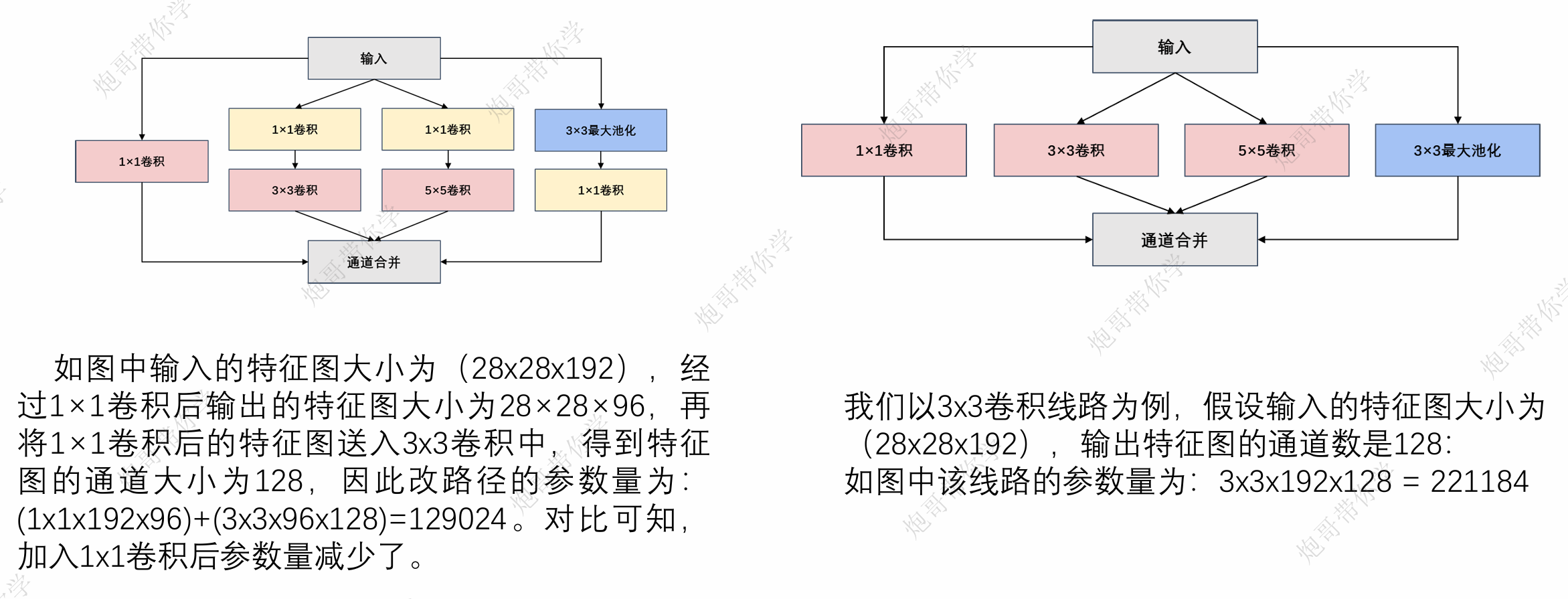
1*1卷积的作用主要是: 实现跨通道的交互和信息整合 卷积核通道数的降维和升维,减少网络参数:
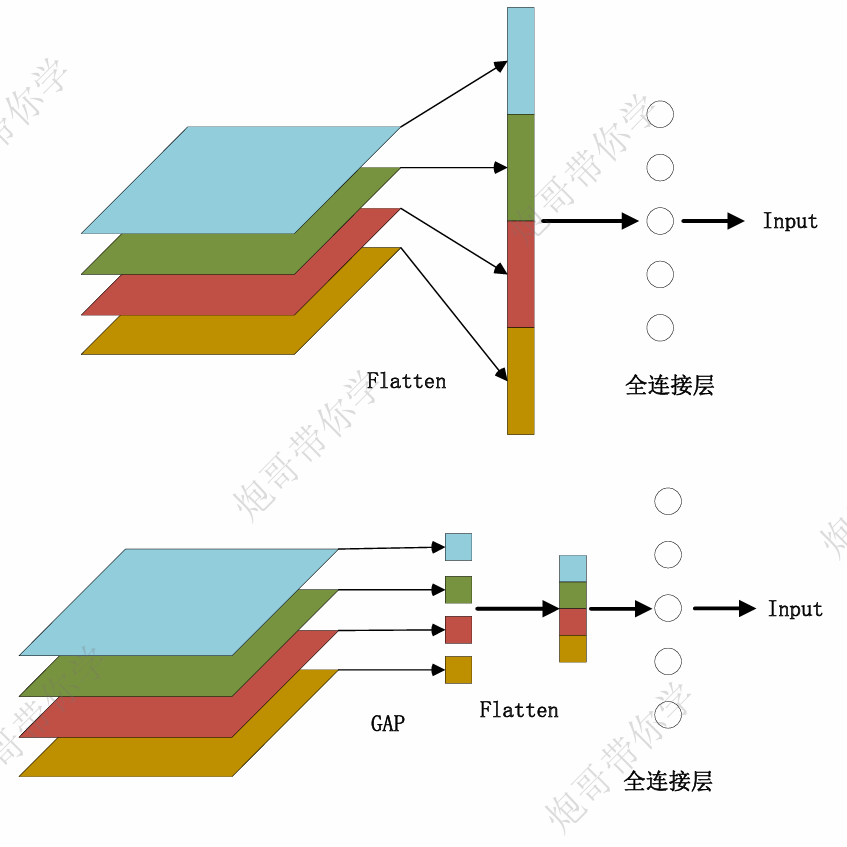
全局平均池化层(GAP):
优势:
1. 抑制过拟合:直接拉平做全连接层的方式依然保留了大量的空间 信息,假设feature map是32个通道的10*10图像,那么拉平就得到 了32*10*10的向量,如果是最后一层是对应两类标签,那么这一层 就需要3200*2的权重矩阵,而GAP不同,将空间上的信息直接用均值代替,32个通道GAP之后得到的向量都是32的向量,那么最后一 层只需要32*2的权重矩阵。相比之下GAP网络参数会更少,而全连接更容易在大量保留下来的空间信息上面过拟合。
2.GAP使特征图输入尺寸更加灵活:在前面举例里面可以看到特征图经过GAP后的大小为1×1×C,这里的C为通道的数量,因此,此刻 神经网络参数不再与输入图像尺寸的大小有关,和输入特征图的通 道有关,也就是输入图像的长宽可以不固定。
劣势:
1.信息丢失:全局平均池化会将每个通道内的特征信息压缩成一个 单一的数值。这可能会导致一些特征信息的丢失,特别是在深层网 络中,重要的细节可能会被平均掉,从而降低了网络的表达能力。
2.特征丰富性:在一些任务中,特征之间的关系和细节对于正确的 分类或预测是至关重要的。全局平均池化可能无法很好地捕捉这些 特征之间的复杂关系,从而影响了模型的性能。
3.梯度信息:在深度学习中,梯度信息是用于权重更新的关键。在 全局平均池化之后,特征图被降维为一个向量,导致梯度的传播变 得更加困难。这可能会导致梯度消失或爆炸,从而影响了优化过程。
4.复杂任务:对于一些复杂的任务,模型需要更多的层级和特征表 示,而全局平均池化可能无法提供足够的表达能力。
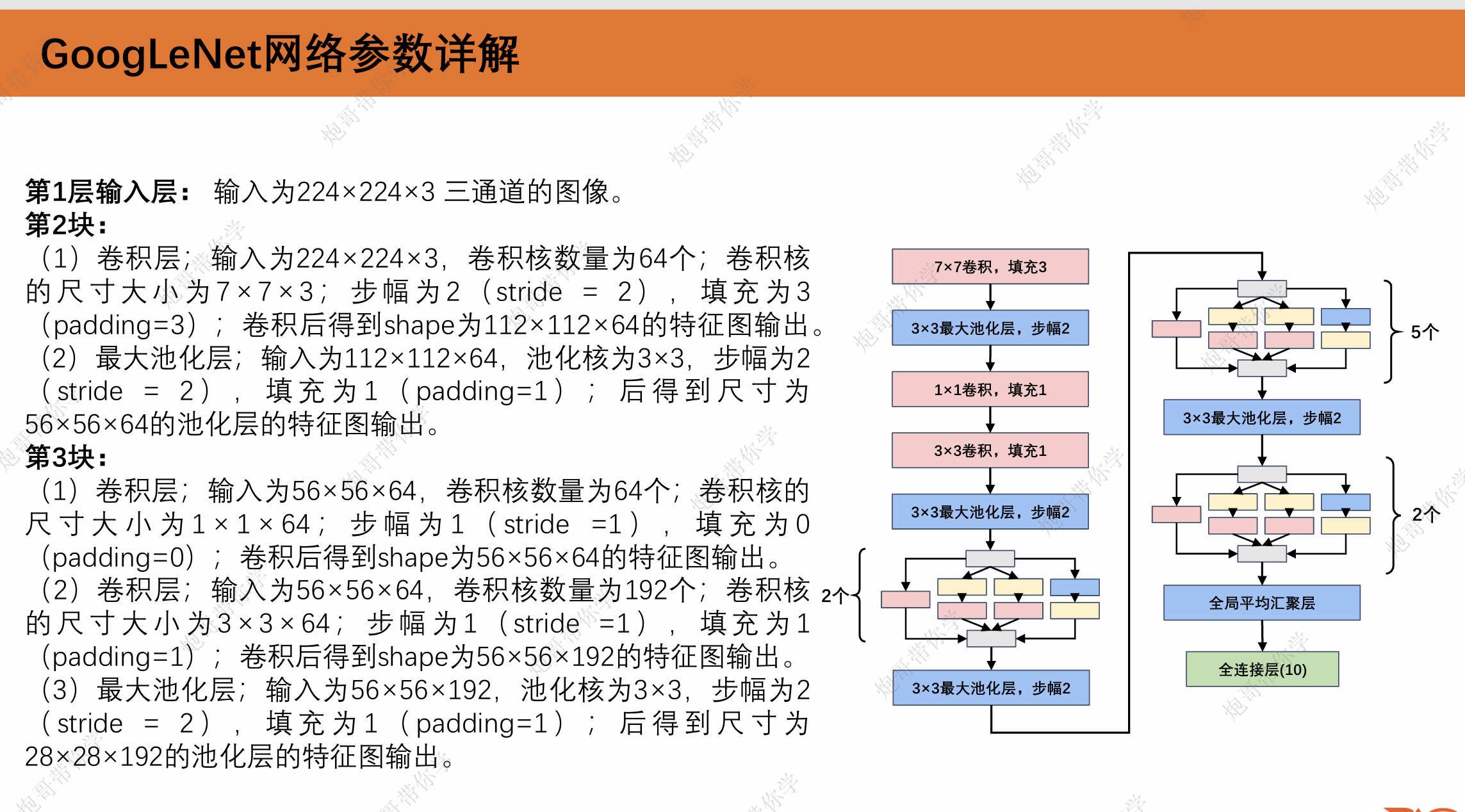
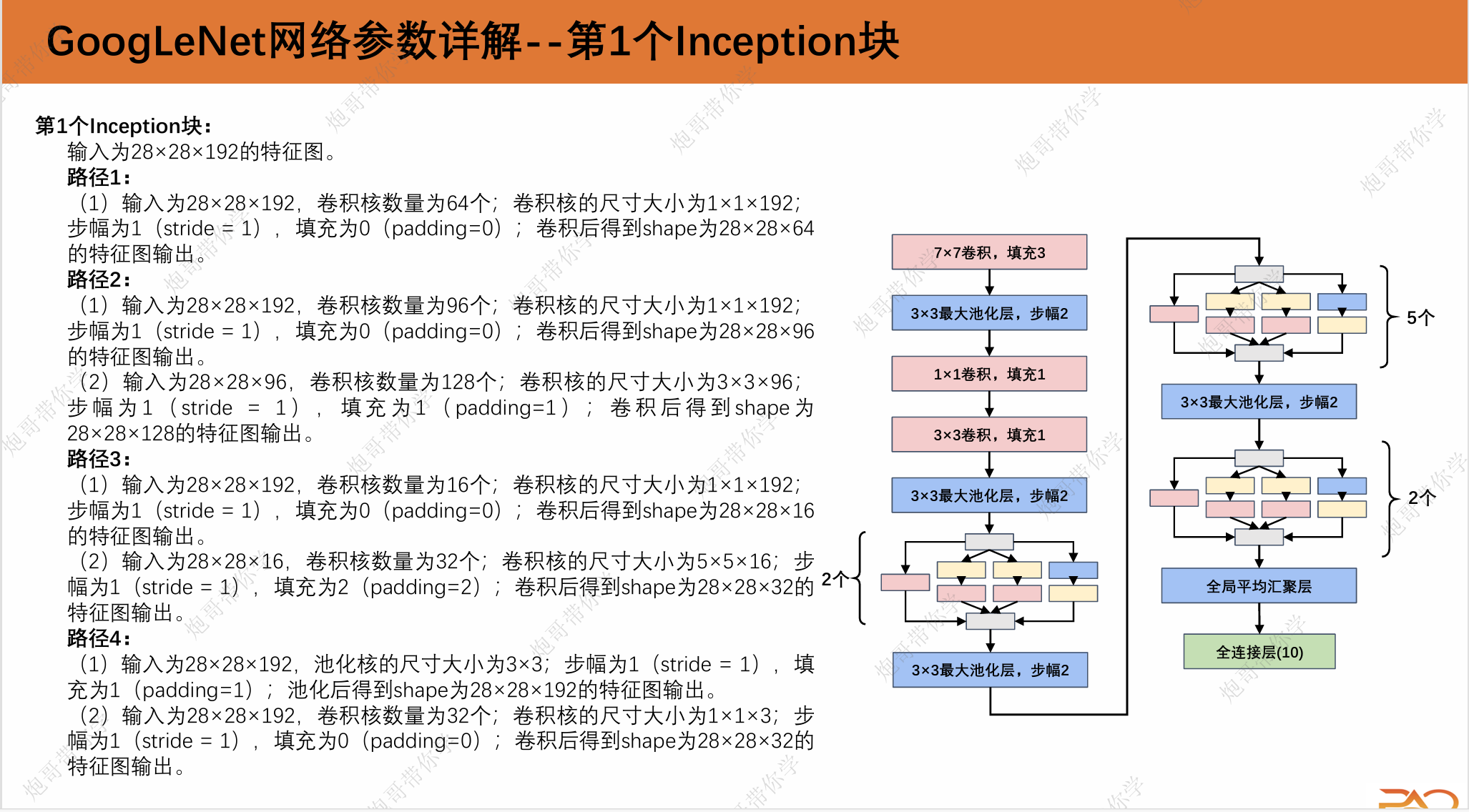
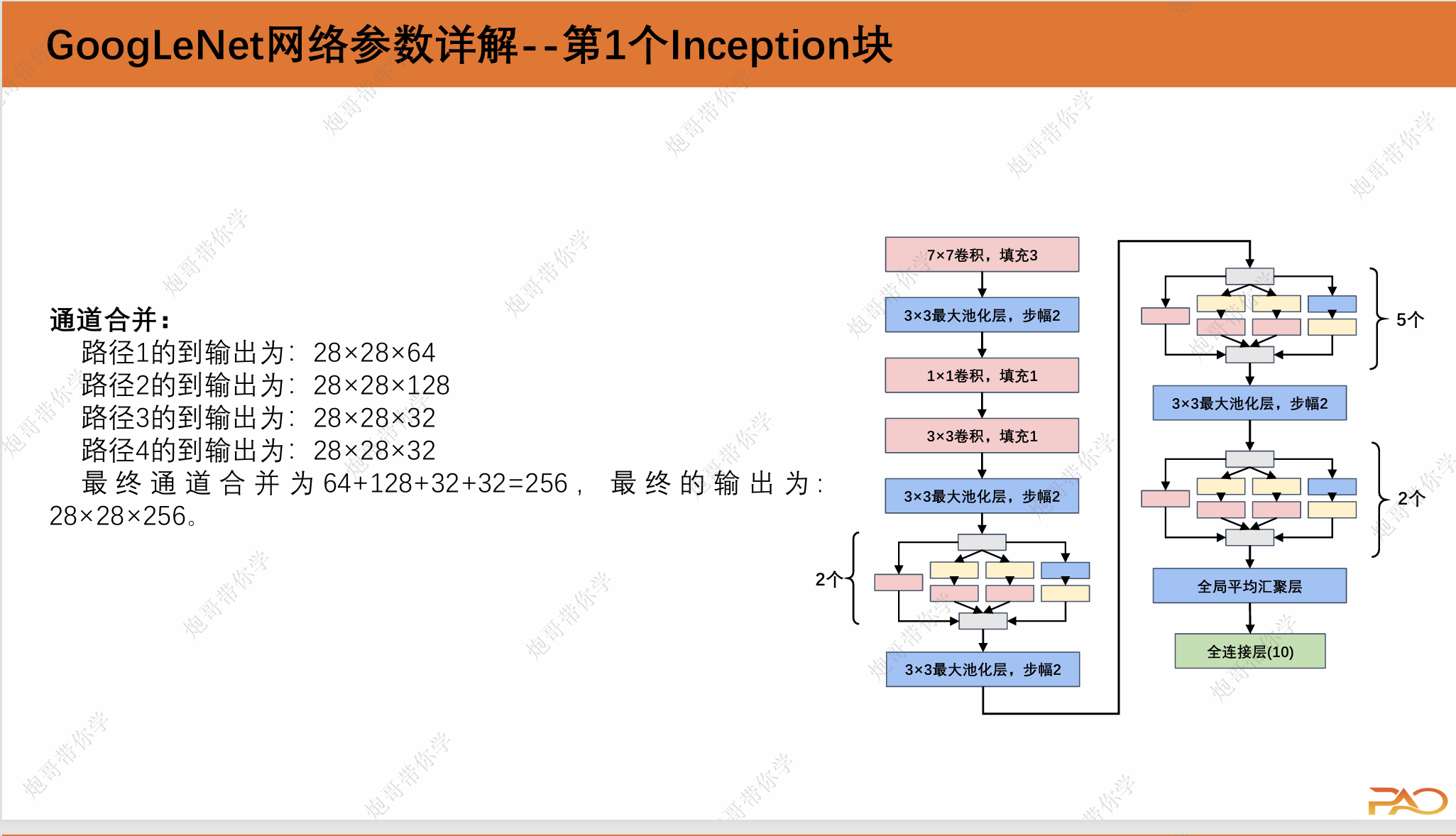
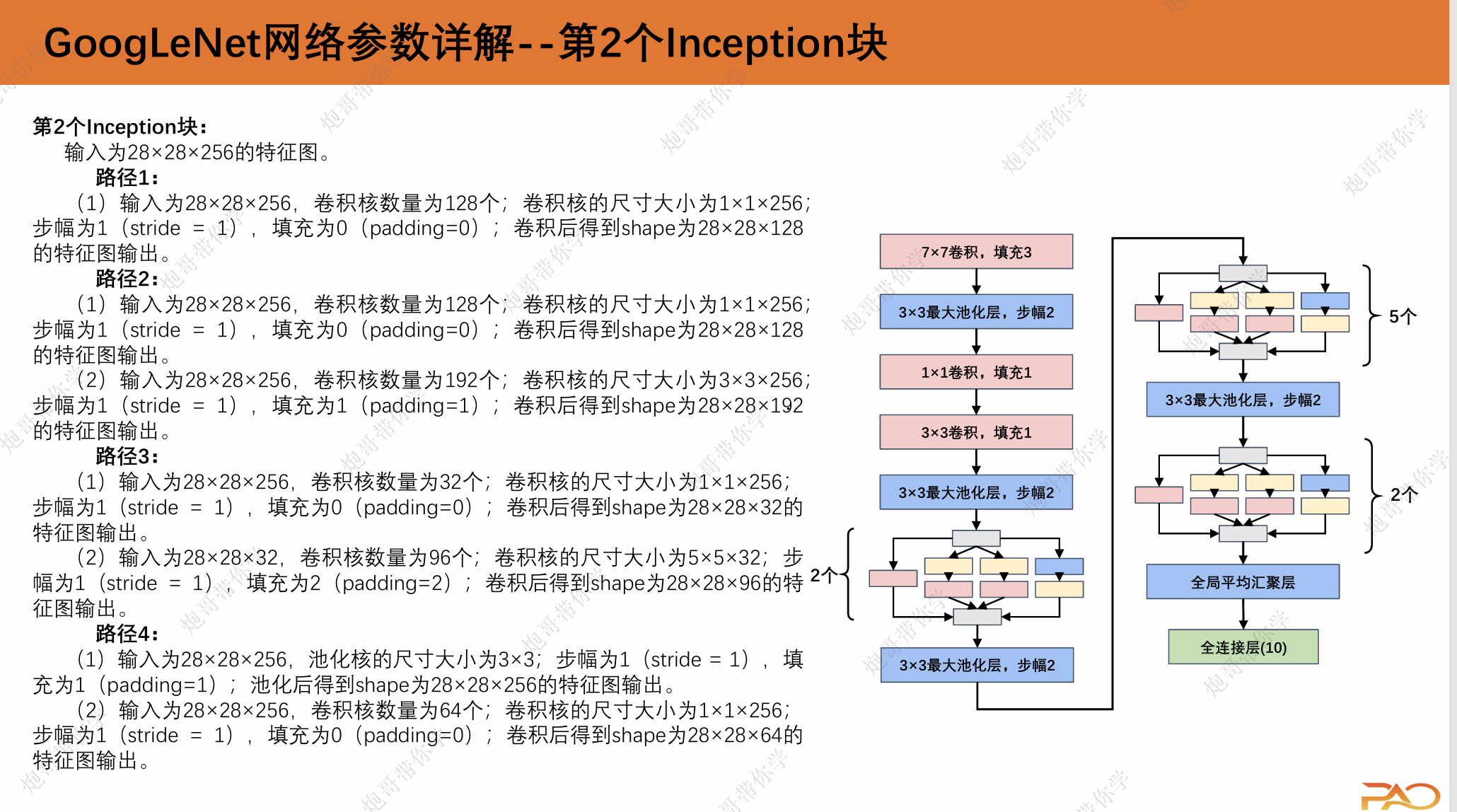
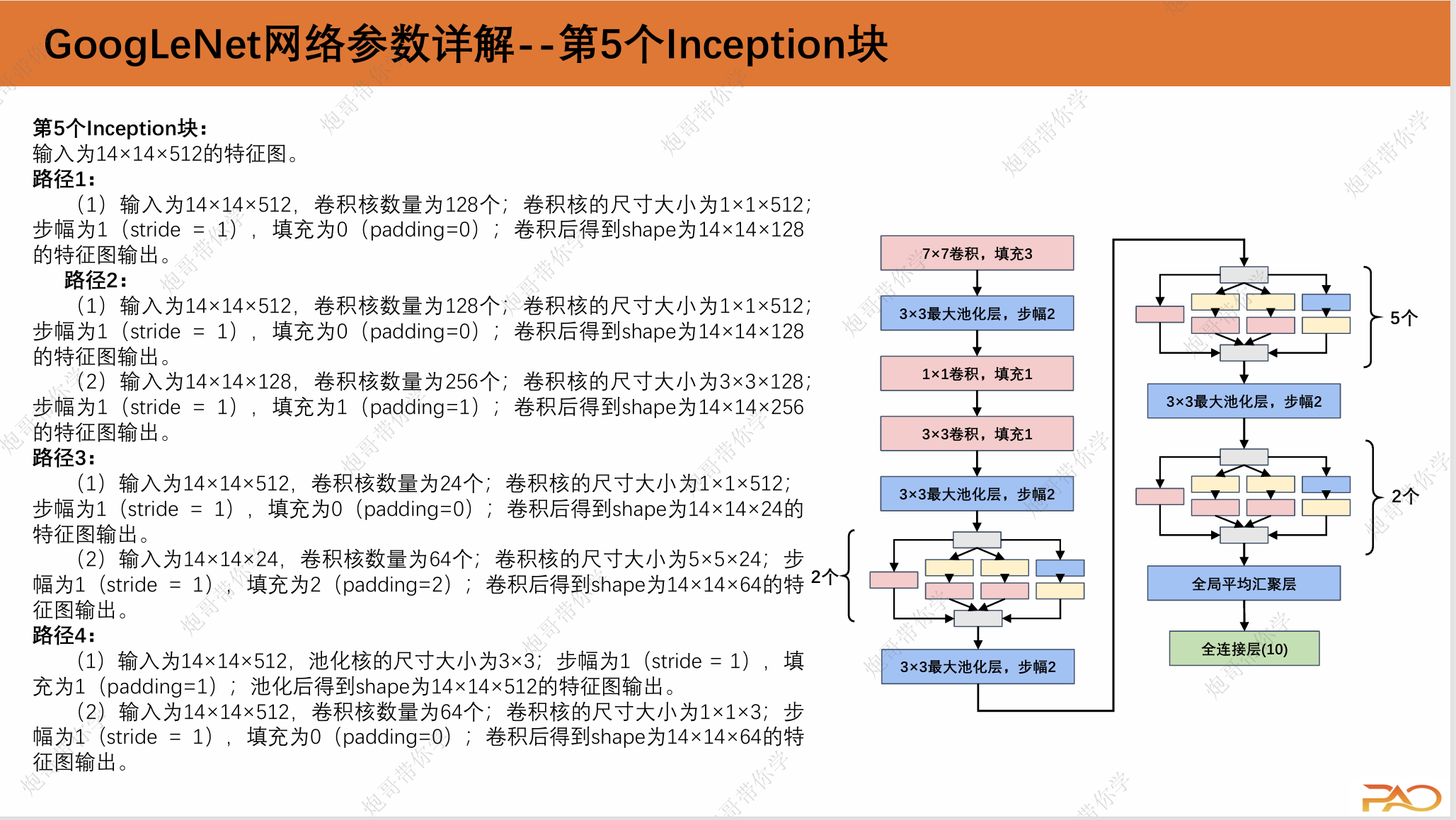
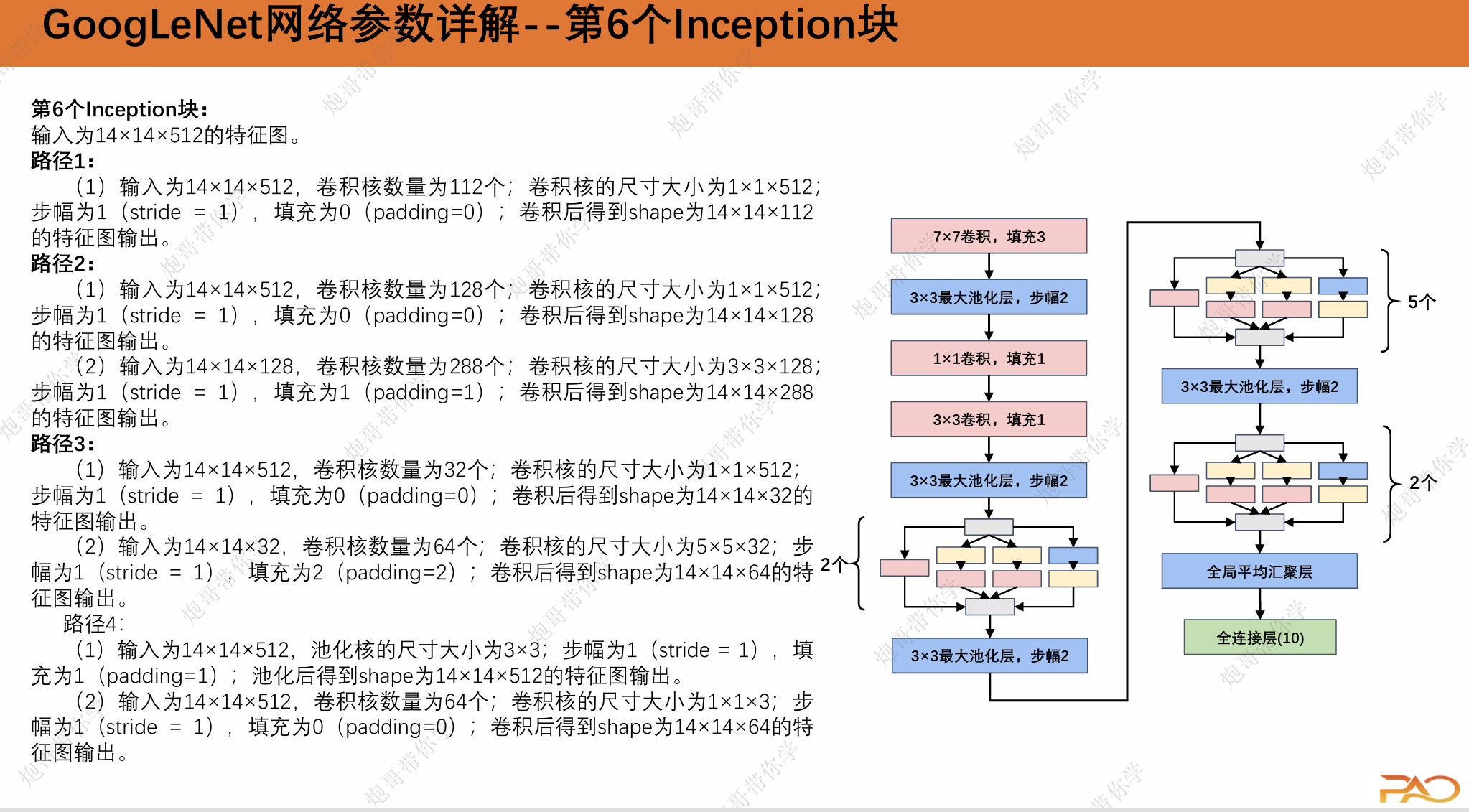
1.3 GoogLeNet网络参数详解
这一段重复性比较高,我直接上图吧。
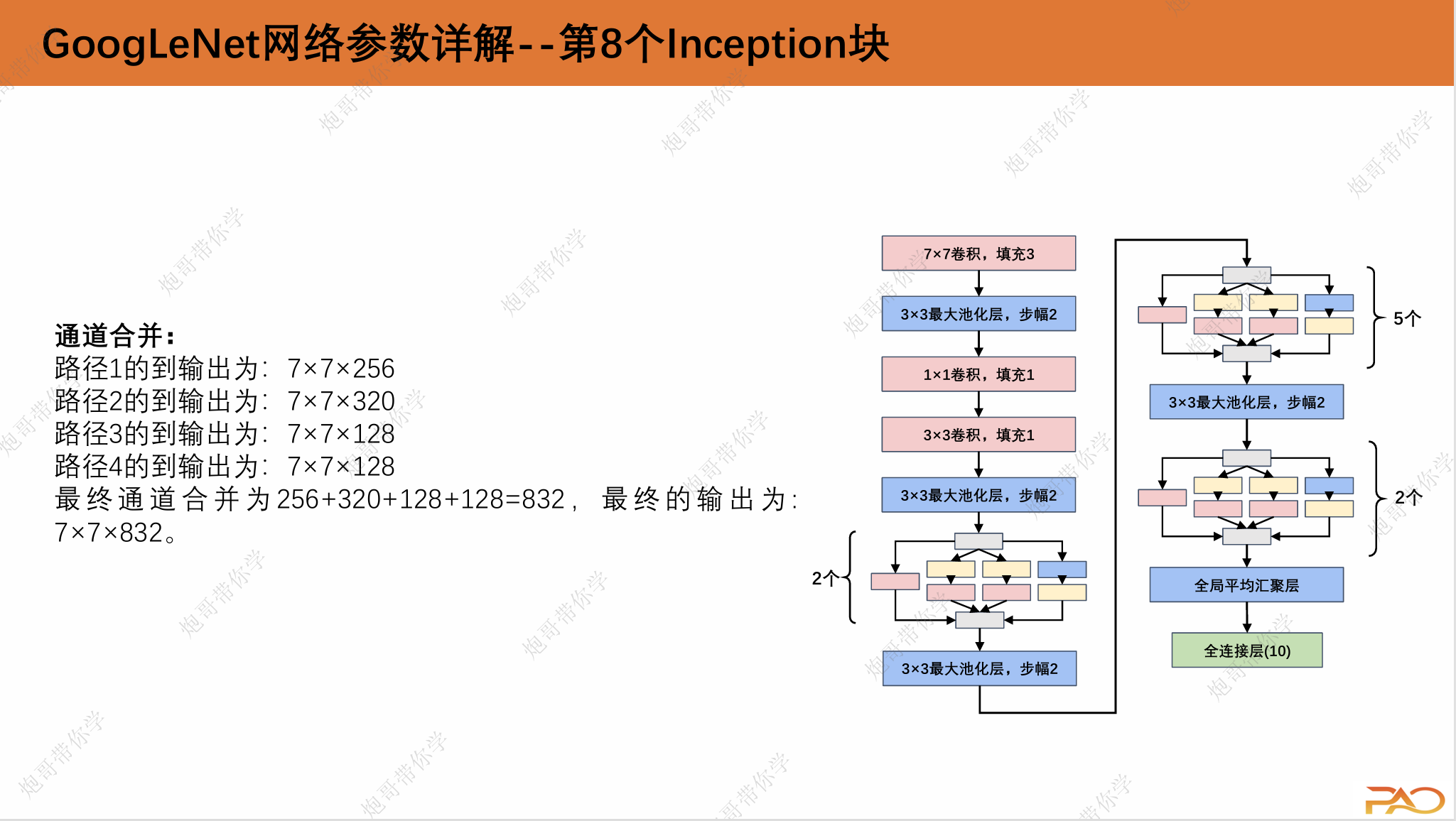
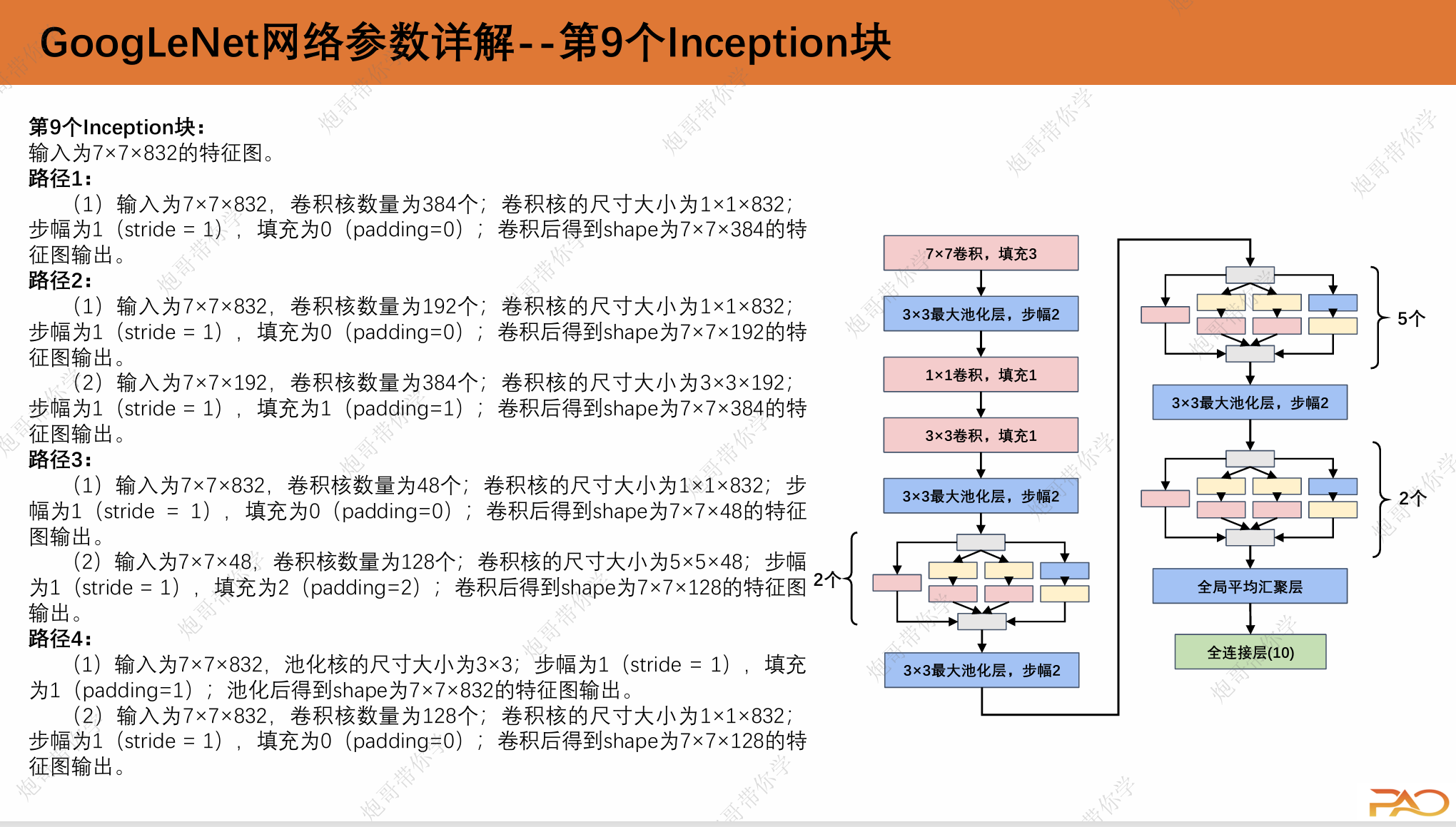
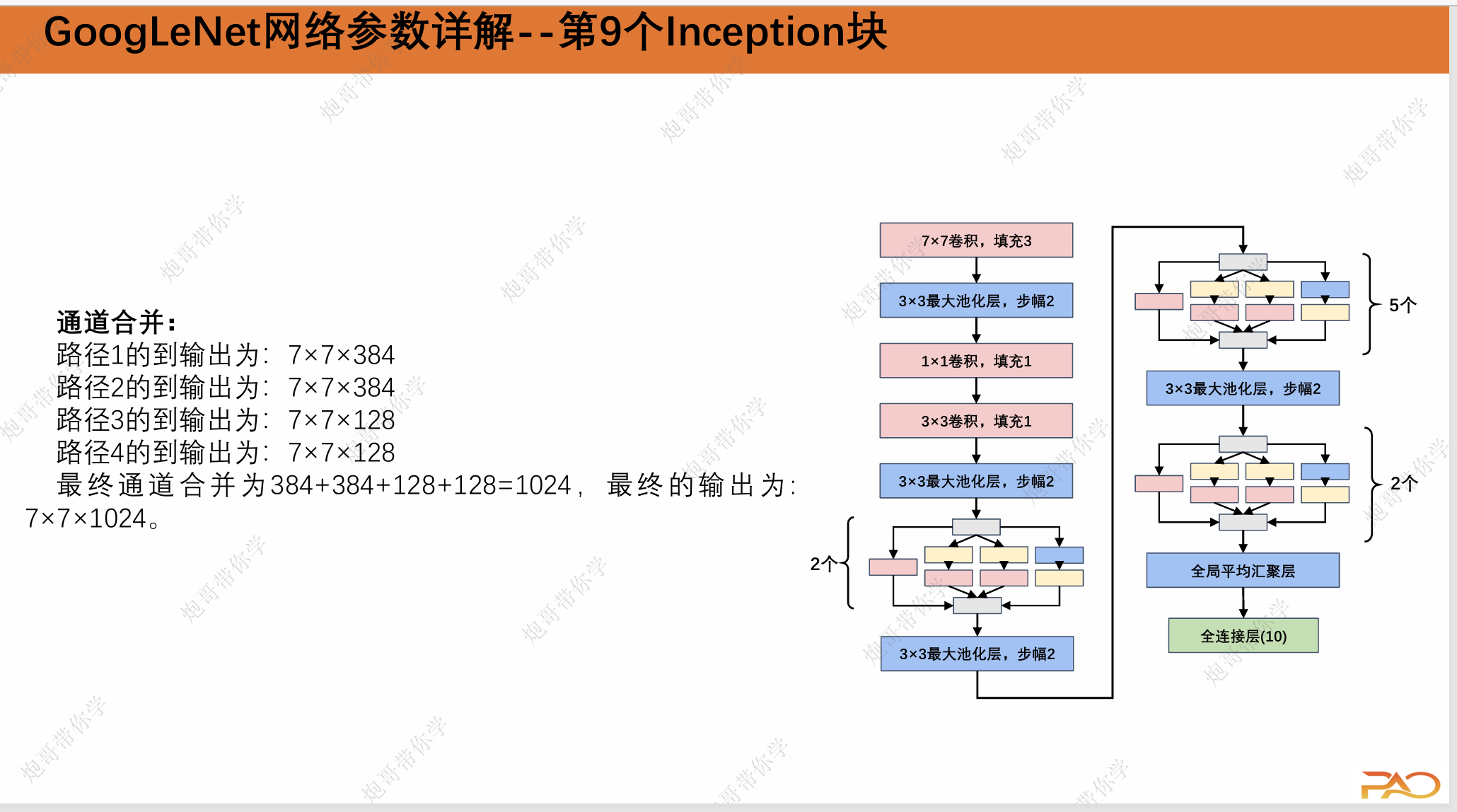
2.GoogLeNet总结
通过创新性的Inception模块和较为复杂的网络设计,使得作 者团队上力压VGGNet夺冠。而GoogLeNet作为Inception模块设 计的代表,有很多值得学习的地方。通过并行的filter将输入特征 提取并在通道维上进行串联合并,构成下一层的输入,再将 Inception块层层叠加。通过这种方式引入了稀疏型、模拟了卷积 视觉网络的最佳拓扑结构。同时也让网络具备了自动选择的能力, 而不是人为地设置卷积或池化,或决定卷积核的尺寸。为了降 低整体参数量,在Inception块中添加了1×1卷积,有效降低了特征的维度,避免了参数爆炸。
3.pytorch代码实现
import torch
from torch import nn
from torchsummary import summaryclass Inception(nn.Module):def __init__(self, in_channels, c1, c2, c3, c4):super(Inception, self).__init__()self.ReLU = nn.ReLU()# 路线1,单1×1卷积层self.p1_1 = nn.Conv2d(in_channels=in_channels, out_channels=c1, kernel_size=1)# 路线2,1×1卷积层, 3×3的卷积self.p2_1 = nn.Conv2d(in_channels=in_channels, out_channels=c2[0], kernel_size=1)self.p2_2 = nn.Conv2d(in_channels=c2[0], out_channels=c2[1], kernel_size=3, padding=1)# 路线3,1×1卷积层, 5×5的卷积self.p3_1 = nn.Conv2d(in_channels=in_channels, out_channels=c3[0], kernel_size=1)self.p3_2 = nn.Conv2d(in_channels=c3[0], out_channels=c3[1], kernel_size=5, padding=2)# 路线4,3×3的最大池化, 1×1的卷积self.p4_1 = nn.MaxPool2d(kernel_size=3, padding=1, stride=1)self.p4_2 = nn.Conv2d(in_channels=in_channels, out_channels=c4, kernel_size=1)def forward(self, x):p1 = self.ReLU(self.p1_1(x))p2 = self.ReLU(self.p2_2(self.ReLU(self.p2_1(x))))p3 = self.ReLU(self.p3_2(self.ReLU(self.p3_1(x))))p4 = self.ReLU(self.p4_2(self.p4_1(x)))return torch.cat((p1, p2, p3, p4), dim=1)class GoogLeNet(nn.Module):def __init__(self, Inception):super(GoogLeNet, self).__init__()self.b1 = nn.Sequential(nn.Conv2d(in_channels=3, out_channels=64, kernel_size=7, stride=2, padding=3),nn.ReLU(),nn.MaxPool2d(kernel_size=3, stride=2, padding=1))self.b2 = nn.Sequential(nn.Conv2d(in_channels=64, out_channels=64, kernel_size=1),nn.ReLU(),nn.Conv2d(in_channels=64, out_channels=192, kernel_size=3, padding=1),nn.ReLU(),nn.MaxPool2d(kernel_size=3, stride=2, padding=1))self.b3 = nn.Sequential(Inception(192, 64, (96, 128), (16, 32), 32),Inception(256, 128, (128, 192), (32, 96), 64),nn.MaxPool2d(kernel_size=3, stride=2, padding=1))self.b4 = nn.Sequential(Inception(480, 192, (96, 208), (16, 48), 64),Inception(512, 160, (112, 224), (24, 64), 64),Inception(512, 128, (128, 256), (24, 64), 64),Inception(512, 112, (128, 288), (32, 64), 64),Inception(528, 256, (160, 320), (32, 128), 128),nn.MaxPool2d(kernel_size=3, stride=2, padding=1))self.b5 = nn.Sequential(Inception(832, 256, (160, 320), (32, 128), 128),Inception(832, 384, (192, 384), (48, 128), 128),nn.AdaptiveAvgPool2d((1, 1)),nn.Flatten(),nn.Linear(1024, 2))for m in self.modules():if isinstance(m, nn.Conv2d):nn.init.kaiming_normal_(m.weight, mode="fan_out", nonlinearity='relu')if m.bias is not None:nn.init.constant_(m.bias, 0)elif isinstance(m, nn.Linear):nn.init.normal_(m.weight, 0, 0.01)if m.bias is not None:nn.init.constant_(m.bias, 0)def forward(self, x):x = self.b1(x)x = self.b2(x)x = self.b3(x)x = self.b4(x)x = self.b5(x)return xif __name__ == "__main__":device = torch.device("cuda" if torch.cuda.is_available() else "cpu")model = GoogLeNet(Inception).to(device)print(summary(model, (3, 224, 224)))