mime嗅探的默认行为及Markdown文件响应格式
mime嗅探的默认行为及Markdown文件响应格式
目录
mime嗅探的默认行为及Markdown文件响应格式
一、何谓mime嗅探
二、mime嗅探的机理
2.1、发现mime的charset值为空。2.2、发现mime的本质essence[主类型/子类型]为空。2.3、发现mime的子类型mimeType为空。2.4、发现Content-Type响应标头需要获取、解码和分割才能得到结果,返回空。2.5、以上若值为空,则返回失败。2.6、对于多值values的每个值
2.7、如果mimeType为空,则返回失败。2.8、返回mimeType
三、html文档与text主类型
3.1、html的mimeType
3.2、文本类型的mimeType
3.3、错误的mimeType声明导致的结果
3.3.1、原本是想执行text/javascript结果被误判【嗅探】为结构解析
3.3.2、原本是想让js加载css进行样式渲染结果被误判【嗅探】为结构解析
3.3.3、原本是想让js加载.md文件注入到iFrame中的html结果被误判【嗅探】为结构解析
3.4、最终导致致命错误而被浏览器用户代理判定为404资源不存在
四、不同的mimeType文本格式产生不同的响应格式
4.1、虽然.txt 响应200 ok但这并非你想要的格式
4.2、错误的mimeType导致错误的.md的格式
4.3、修正.md正确的mimeType的响应结果
五、mime嗅探的潜在风险及规避
5.1、text/html和text/markdown的本质区别
5.2、xss注入风险
5.3、mime嗅探潜在风险规避步骤
本博客相关博文
喜欢就点赞、收藏,鼓励我坚持更多原创技术写作
一、何谓mime嗅探
mime嗅探,英文MIME Sniffing,它是浏览器的默认行为,当用户请求某个资源,浏览器用户代理拦截响应时,若发现应用服务未明确声明该资源的内容类型时,或浏览器判断服务申明的内容类型貌似不正确时,浏览器便开启了其默认的“mime嗅探”行为。
二、mime嗅探的机理
` Content-Type` 标头在 HTTP 中定义较为广泛。由于 HTTP 中定义的模型与 Web 内容不兼容,按照HTTP标准模型来进行处理,从响应中提取Content-Type并进行识别处理,返回失败或正确的mime类型,步骤:
2.1、发现mime的charset值为空。
2.2、发现mime的本质essence[主类型/子类型]为空。
2.3、发现mime的子类型mimeType为空。
2.4、发现Content-Type响应标头需要获取、解码和分割才能得到结果,返回空。
2.5、以上若值为空,则返回失败。
2.6、对于多值values的每个值
2.6.1、让temporaryMimeType成为解析value的结果。
2.6.2、如果temporaryMimeType失败或其本质为“ */*”,则继续。
2.6.3、将mimeType设置为temporaryMimeType。
2.6.4、如果mimeType的本质essence[主类型/子类型],则:
2.6.4.1、将其参数[字符集charset]设置为空。
2.6.4.2、如果mimeType的参数[" charset"]存在,则将charset设置为mimeType的参数[" charset"]。
2.6.4.3、将essence设置为mimeType的本质essence。
2.6.4.5、否则,如果mimeType的参数[" charset"] 不存在,并且charset非空,则将mimeType的参数[" charset"] 设置为charset。
2.7、如果mimeType为空,则返回失败。
2.8、返回mimeType
如果浏览器提取MIME类型返回失败,或者MIME类型的本质与给定格式不符,则应将其视为致命错误。现有的Web服务功能并非始终遵循此规则。
多年来,这一直是这些Web服务功能中安全漏洞的主要来源。相比之下,MIME类型的参数通常可以安全地忽略。
三、html文档与text主类型
3.1、html的mimeType
html的mimeType是text/html;charset=UTF-8。
3.2、文本类型的mimeType
常用的有:text/plain,text/html,text/xml,text/markdown,text/javascript,text/css等。
3.3、错误的mimeType声明导致的结果
以下为旧版的【遗留格式】,不建议使用 :
| 标头(与网络上的一样) | 输出(序列化) |
|---|---|
| text/html |
| text/html;x=y;charset=gbk |
| |
| text/html;x=y |
| text/html |
| |
|
当主mime为text/ 的标头错误的被发送给浏览器导致的结果,比如:
3.3.1、原本是想执行text/javascript结果被误判【嗅探】为结构解析
text/html;charset=UTF-8
3.3.2、原本是想让js加载css进行样式渲染结果被误判【嗅探】为结构解析
text/html;charset=UTF-8
3.3.3、原本是想让js加载.md文件注入到iFrame中的html结果被误判【嗅探】为结构解析
text/html;charset=UTF-8
3.4、最终导致致命错误而被浏览器用户代理判定为404资源不存在
四、不同的mimeType文本格式产生不同的响应格式
4.1、虽然.txt 响应200 ok但这并非你想要的格式
虽然请求 /myWebApiProjs/marked/public/demo/quickref.txt 响应200 ok

4.2、错误的mimeType导致错误的.md的格式
虽然请求 /myWebApiProjs/marked/public/demo/quickref.md 响应200 ok但格式错误:
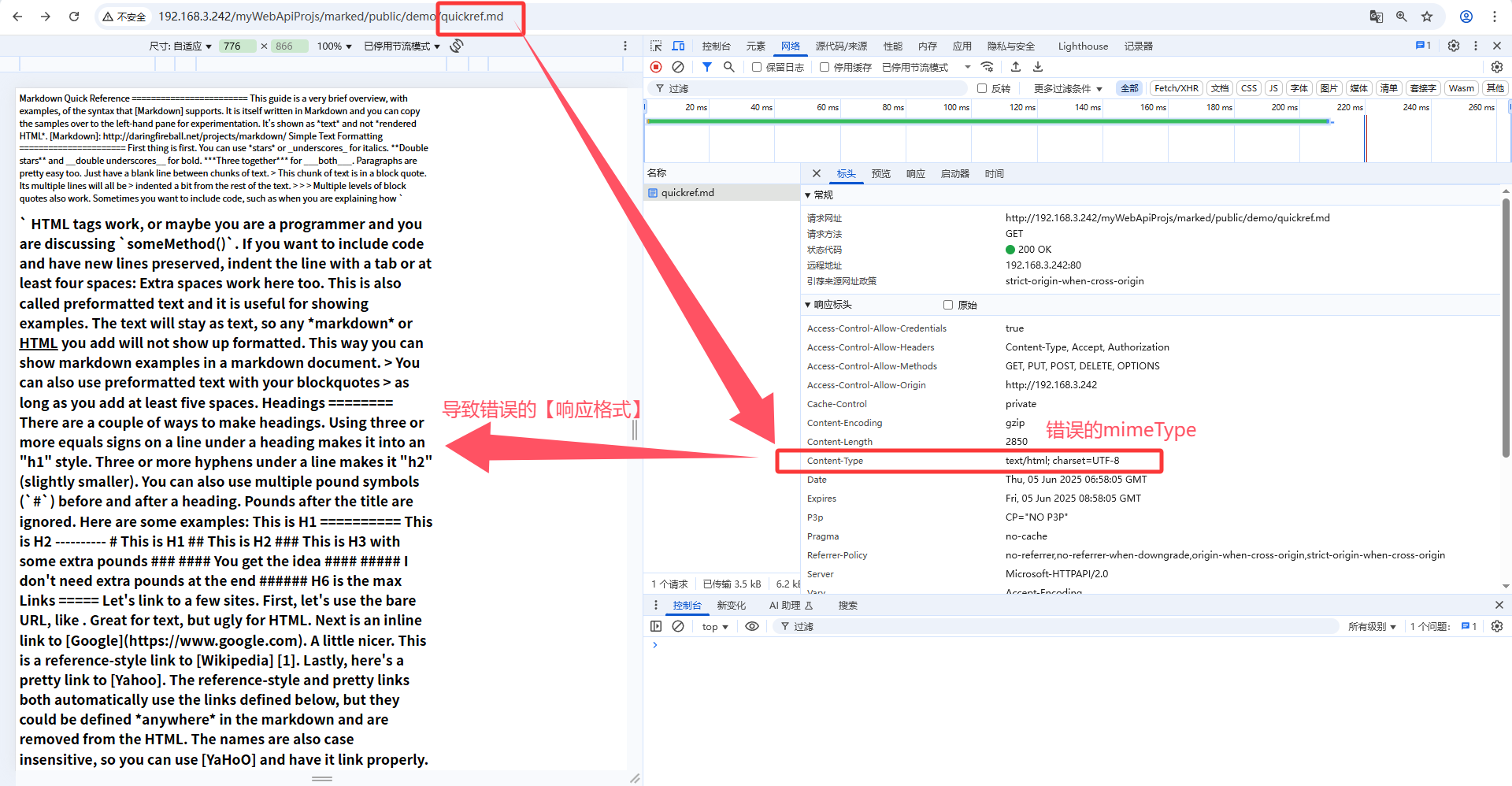
4.3、修正.md正确的mimeType的响应结果
请求 /myWebApiProjs/marked/public/demo/quickref.md 正确响应:
HTTP
content-type: text/markdown; charset=UTF-8


五、mime嗅探的潜在风险及规避
5.1、text/html和text/markdown的本质区别
共性:
它们都是文本类型的资源。
本质区别:
它们【子类型】不同,带来如下结果:
类型为text/markdown的mimeType,被设计为“文本”的编辑和“文本”的解析,解析的结果,文档中的链接仅为<a>标签的链接,文档也没有事件,不会执行代码。
但类型为text/html的mimeType,被设计为“超文本标记语言”的编辑及其解析,作为语言,解析的结果,文档中不仅可以正常注入<link>和<script>,而且可以在特定的事件驱动下执行可能的代码。
5.2、xss注入风险
如果服务代码并未很好的解决【安全隐患】,则如果text/markdown被浏览器错误的判定【嗅探】为text/html;那么当请求被【恶意拦截】时特别是跨站点时,攻击者可能篡改.md文件中的文本,将其注入可执行的恶意的js脚本代码。这些代码在text/html上下文环境下可以被执行。
5.3、mime嗅探潜在风险规避步骤
以text/markdown类型示例,假设其它安全风险已经被处理的前提下,处理步骤如下:
5.3.1、服务正确声明mimeType响应标头
content-type: text/markdown; charset=UTF-8
5.3.2、服务明确指示【不允许-mime嗅探】
在5.3.1、正确设置的前提下:
X-Content-Type-Options: 'nosniff'
5.3.3、服务对.md文件的请求结果在客户端响应时应“被动拦截”验证.md未被篡改
function setInitialQuickref() {return fetch('./quickref.md') .then( (res) => {fetch("https://www.cpuofbs.com/VerifyFileMD5", {method: "POST", headers: {"Content-Type": "application/json; charset=UTF-8",},body: encodeURIComponent(JSON.stringify(res.json())),}).then((response) => response.json()).then((data) => {if (data.code&&data.code===200) {console.log("验证成功quickref.md未被传输层篡改:");document.querySelector('#quickref').value = res.text();} else document.querySelector('#quickref').value = '';}).catch((error) => {console.error("验证过程异常请联系管理员,Error:", error);});});
}
5.3.4、客户端使用.md的响应结果
本博客相关博文
《socket.io库如何配置socket及express和http/2》、《再谈SSL证书及Https应用服务器访问》、《最新ssl证书申请与安装配置2024版》。