Prometheus定义主机监控告警实例
Prometheus 是一个强大的开源监控和告警工具,支持通过灵活的规则定义来监控主机(如服务器、容器等)的运行状态。以下是基于 Prometheus 的主机监控告警定义的核心步骤和示例:
修改Prometheus配置文件prometheus.yml,添加以下配置:
rule_files:
- /etc/prometheus/rules/*.rules
在目录/etc/prometheus/rules/下创建告警文件hoststats-alert.rules内容如下:
groups:
- name: hostStatsAlert
rules:
- alert: hostCpuUsageAlert
expr: sum(avg without (cpu)(irate(node_cpu{mode!='idle'}[5m]))) by (instance)
> 0.85
for: 1m
labels:
severity: page
annotations:
summary: "Instance {{ $labels.instance }} CPU usgae high"
description: "{{ $labels.instance }} CPU usage above 85% (current value: {{
$value }})"
- alert: hostMemUsageAlert
expr: (node_memory_MemTotal - node_memory_MemAvailable)/node_memory_MemTotal
> 0.85
for: 1m
labels:
severity: page
annotations:
summary: "Instance {{ $labels.instance }} MEM usgae high"
description: "{{ $labels.instance }} MEM usage above 85% (current value: {{
$value }})"
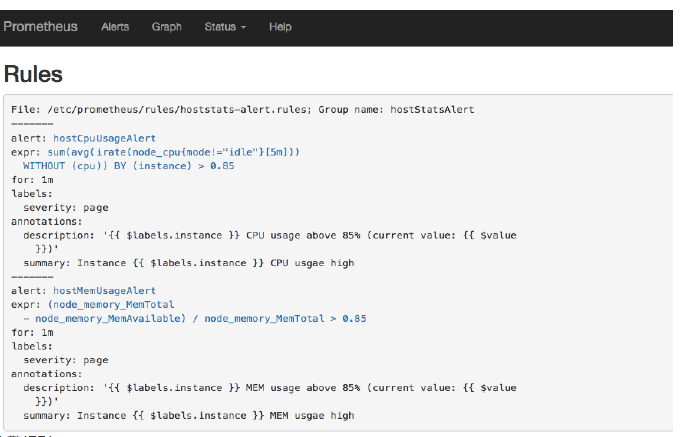
重启Prometheus后访问Prometheus UIhttp://127.0.0.1:9090/rules可以查看当前以加载的规则文
件。
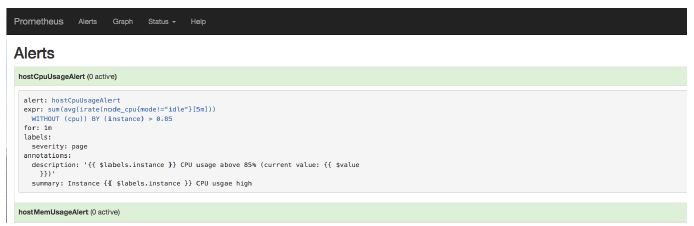
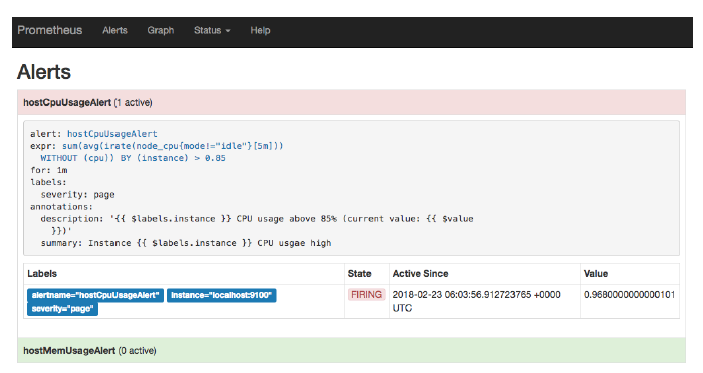
切换到Alerts标签http://127.0.0.1:9090/alerts可以查看当前告警的活动状态。
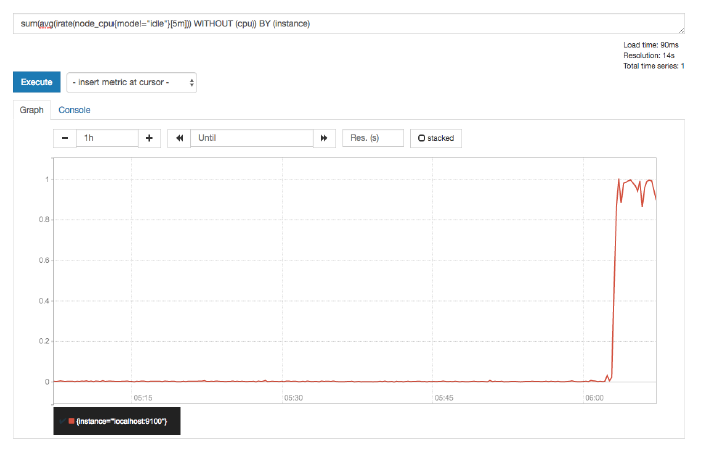
此时,我们可以手动拉高系统的CPU使用率,验证Prometheus的告警流程,在主机上运行以下命令:
cat /dev/zero>/dev/null
运行命令后查看CPU使用率情况,如下图所示:
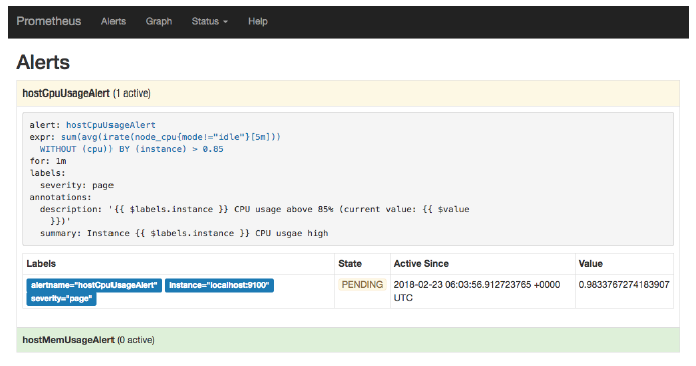
Prometheus首次检测到满足触发条件后,hostCpuUsageAlert显示由一条告警处于活动状态。由于告警规则中设置了1m的等待时间,当前告警状态为PENDING,如下图所示:
如果1分钟后告警条件持续满足,则会实际触发告警并且告警状态为FIRING,如下图所示:
最佳实践
-
合理设置阈值:根据业务需求调整告警阈值,避免误报。
-
分组与抑制:在 Alertmanager 中配置告警分组和抑制规则,减少告警噪音。
-
可视化:结合 Grafana 创建主机监控仪表盘,直观展示关键指标。
需要更多有关普罗米修斯监控的资料可以联系我,一起探讨学习!
