ceph集群调整pg数量实战(上)
#作者:闫乾苓
文章目录
- 1.问题描述
- 1.1集群报警信息
- 1.2业务侧虚拟机使用ceph rbd作为虚拟磁盘,io util很高
- 2.问题分析及排查
- 2.1 当前环境信息
- 2.2 集群报警信息解析
- 2.3 使用 ceph osd df 检查 OSD 分布
- 2.4 业务侧磁盘IO分析
1.问题描述
1.1集群报警信息
HEALTH_WARN too few PGs per OSD (25 <30 )
1.2业务侧虚拟机使用ceph rbd作为虚拟磁盘,io util很高
- OpenStack 使用 Ceph RBD 作为虚拟机磁盘
- 虚拟机部署的是达梦数据库(DMDBMS)
- 在数据库重启后,从库执行前滚(Redo Apply)速度非常慢
在虚拟机中使用 iostat 观察到:

2.问题分析及排查
2.1 当前环境信息
Ceph 版本:12.2.8(Luminous)
集群节点数:10 个物理节点
每个节点磁盘数:12 块盘
总 OSD 数 = 10 * 12 = 120
pool 数量:1 个
pool 的 PG 数 = 1024
2.2 集群报警信息解析
HEALTH_WARN too few PGs per OSD (25 <30 )
警告含义解析
- 当前每个 OSD 上平均的 PG 数量是 25。
- Ceph 推荐每个 OSD 上至少有 30~70 个 PG(具体取决于集群规模和性能需求)。
- 如果 PG 数量太少,会导致数据分布不均、负载不均衡,影响性能和恢复效率。
2.3 使用 ceph osd df 检查 OSD 分布
(命令出处见第4部分“参考链接” 1 )
ceph osd df 命令提供了关于每个 OSD 的存储使用情况的详细信息,包括已用空间、可用空间、PG 数量等。通过这个命令,可以检查 OSD 之间的负载是否均匀分布,以及是否有某些 OSD 存在过载的情况。
关键字段解释
- ID: OSD 的唯一标识符。
- CLASS: OSD 使用的存储介质类型(例如 HDD 或 SSD)。
- WEIGHT: OSD 的权重,用于确定其在 CRUSH 算法中的相对容量。
- REWEIGHT: OSD的重新加权值,用于临时调整OSD的权重而不改变其实际容量。
- SIZE: OSD 的总容量。
- USE: OSD 当前使用的容量。
- AVAIL: OSD 当前可用的容量。
- %USE: OSD 已用容量的百分比。
- VAR: 相对于平均使用率的变化百分比。
- PGS: 在该 OSD 上的 PG 数量。
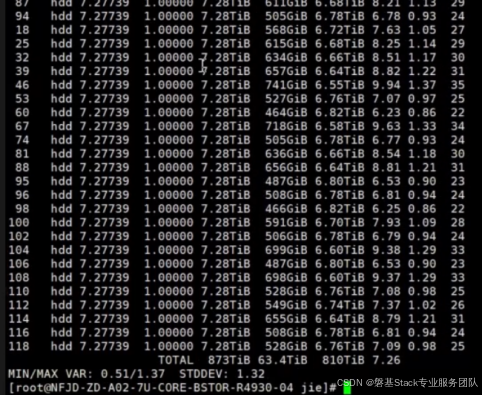
检查容量使用率:
OSD 的 %USE近平均值 7.00, 表明数据在每个OSD上没有出现明显分布不均的情况
检查 PG 数量
每个 OSD 上的 PG 数量大致相同,平均25个。无显著分布不均的情况。
PG 分程度均衡度
看到的 ceph osd df 命令输出中最后的一行:
MIN/MAX VAR: 0.51/1.37 STDDEV: 1.32
MIN/MAX VAR: 0.51/1.37
最小VAR = 0.51:表示某个OSD上的PG数量只有平均值的 51%,即明显偏少。
最大VAR = 1.37:表示某个OSD上的PG数量达到了平均值的 137%,即明显偏多。
结论:PG 分布存在一定程度的不均衡
STDDEV: 1.32
- 如果 STDDEV < 1:表示 PG 分布较为均衡。
- 如果 STDDEV > 1:表示存在一定程度的不均衡。
- 如果 STDDEV > 2:说明分布严重不均,建议调整 CRUSH 规则或增加 PG 数量来改善
STDDEV = 1.32,说明PG分布存在一定程度的不均衡的情况
2.4 业务侧磁盘IO分析
openstack 使用此ceph 的rbd块作为虚拟机的虚拟磁盘,虚拟机上部署的应用为达梦数据库,数据库在重启后,从库在执行前滚操作时,发现速度非常慢,并且在虚拟机的操作系统上使用iostat 输出如下:w/s 498.00 wkB/s 13492.00 w_await 27.69 wareq-sz 23.69 f/s 2.00 f_wait 143.00 aqu-sz 15.88 %util 100
iostat 输出说明与性能瓶颈判断:
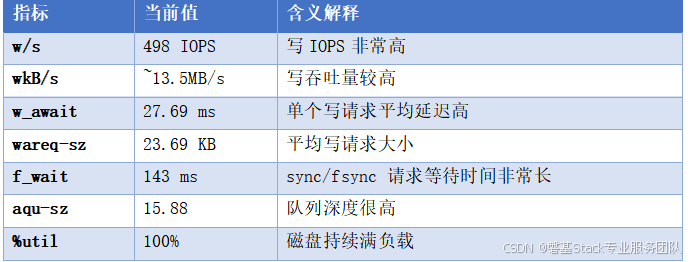
存储子系统(Ceph RBD)存在的IO瓶颈,尤其是在 fsync / sync 操作时延迟极高,导致 Redo Apply 前滚效率较低。
可能原因分析:
(1)Ceph PG 数量过少(已知)
- 当前每个 OSD 上 PG 数量为约 25个,远低于推荐值。
- PG 少意味着数据分布不均匀、恢复或写入并发能力差。
- 导致日志重放(Redo Apply)、checkpoint、fsync 性能下降明显。
(2)RBD 缓存配置不当
- RBD 默认使用 Writeback 模式缓存,如果未开启 flush 或禁用了 cache,则所有 IO 都会同步写入 Ceph。
- 如果没有启用 writeback 缓存,或者启用了但没有设置 flush 接口,会导致大量小文件写和 fsync 被穿透到底层 Ceph,造成性能下降。