【论文阅读】大模型优化器(Large Language Models As Optimizers)
Large Language Models As Optimizers
原文:Large Language Models As Optimizers
1.1 基本信息
论文作者包括 Chengrun Yang、Xuezhi Wang、Yifeng Lu、Hanxiao Liu、Quoc V. Le、Denny Zhou 和 Xinyun Chen 共七人 。所有作者均来自 Google DeepMind 研究机构
该论文最初于 2023 年9月作为预印本发布在 arXiv 。其后,该论文被机器学习领域的顶级国际会议 ICLR 2024 接收为会议论文 (ICLR,全称 International Conference on Learning Representations 2024)。
1.2 摘要
核心贡献:
- 论文提出了 OPRO(Optimization by PROmpting) 方法,利用大语言模型(LLMs)作为优化器。与传统基于梯度的优化算法不同,OPRO用自然语言描述优化任务。
方法原理:
在每个优化步骤中:
- LLM从包含先前生成解决方案及其评分的提示中生成新的解决方案
- 评估新解决方案并将其添加到下一步优化的提示中
- 通过这种迭代过程逐步改进解决方案质量
应用场景:
- 数学优化问题
- 线性回归:寻找最优的线性系数
- 旅行商问题(TSP):寻找最短路径
- 提示词优化
- 目标是找到能够最大化任务准确率的指令
- 在GSM8K(小学数学题)和Big-Bench Hard任务上进行测试
实验结果:
- 在GSM8K上,OPRO优化的提示词比人工设计的提示词**最多提升8%**的准确率
- 在Big-Bench Hard任务上,**最多提升50%**的准确率
- 测试了多种LLMs,包括PaLM 2-L、text-bison、GPT-3.5-turbo、GPT-4等
主要发现:
- LLMs能够有效地作为优化器使用
- 通过自然语言描述优化任务比传统方法更灵活
- 在提示词优化方面特别有效,能够自动发现比人工设计更好的提示词
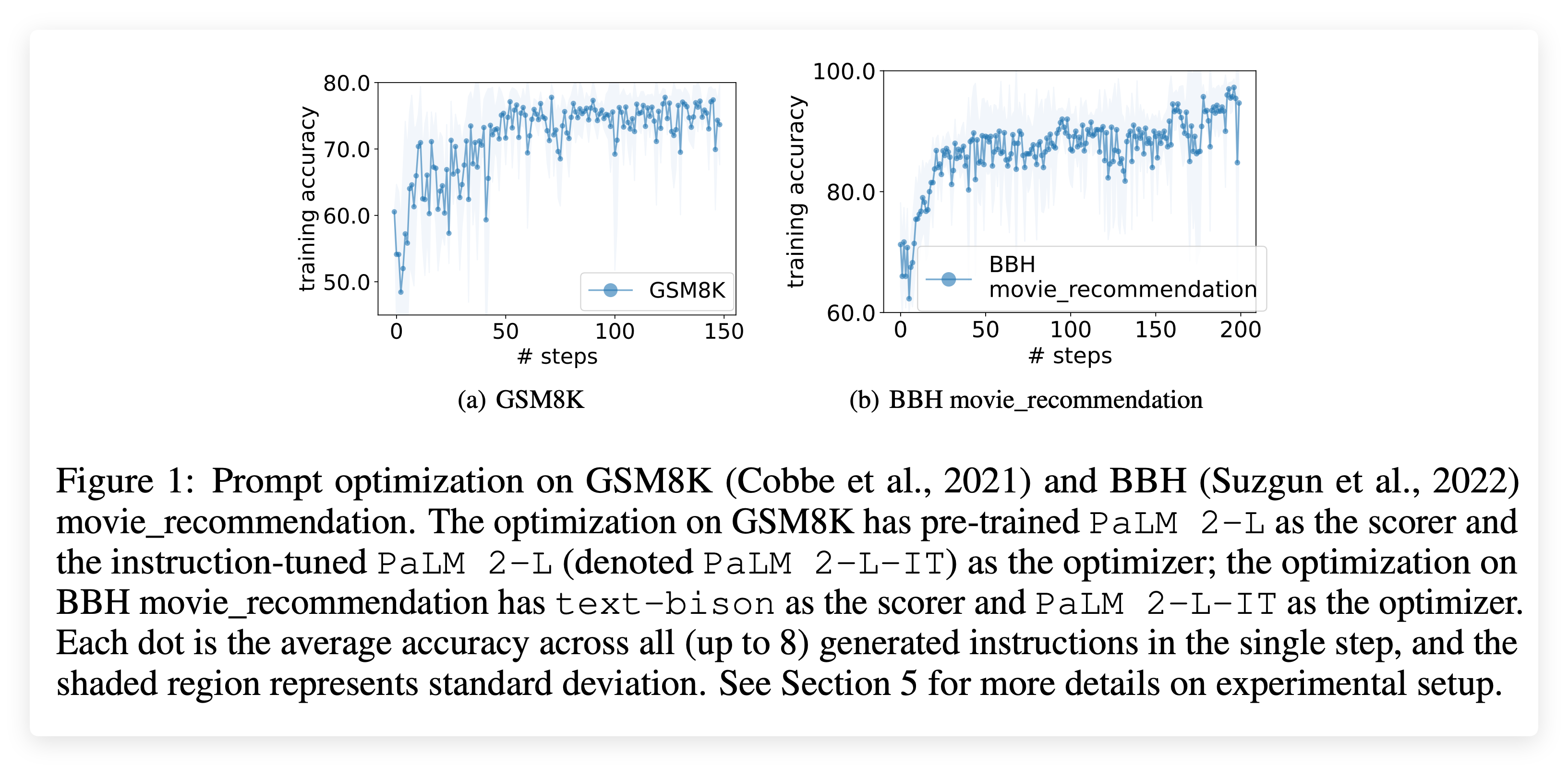
图中阴影部分表示标准差,是一个很好的可视化选择,它可以:
- 评估实验的重现性
- 理解方法的鲁棒性
- 判断性能提升是否显著

在使用不同优化器大语言模型进行提示优化时,在 GSM8K 零样本测试中准确率最高的操作指令。所有结果均使用预训练的 PaLM 2-L 作为评分器。
所有OPRO优化得到的指令都显著超越了人工设计的基线指令。
表格表明三点:
- 自动化提示词优化可以找到比人工设计更好的指令
- 不同的LLM优化器会发现不同风格但都有效的解决方案
- OPRO能够系统性地超越人工经验
1.3 Introduction
(1) 问题背景与动机
- 优化无处不在:许多优化技术都是迭代的,从初始解开始逐步改进
- 传统方法局限:需要为特定任务定制优化算法,特别是在无导数优化场景中
- 新机遇:LLMs在各种领域的成功为优化开辟了新可能性
(2) OPRO核心思想
提出了一种全新的优化范式:
- 用自然语言描述优化问题,而非正式的数学定义
- LLM作为优化器,基于问题描述和历史解决方案迭代生成新解
- 通过改变提示描述快速适应不同任务
- 可以通过添加指令来定制解决方案的期望属性
为什么可以通过改变提示描述快速适应不同任务?
# 线性回归任务
def linear_regression_optimizer():# 需要专门编写算法return gradient_descent()# 旅行商问题
def tsp_optimizer():# 需要完全不同的算法return genetic_algorithm()# 提示词优化
def prompt_optimizer():# 又需要另一种算法return reinforcement_learning()
# 只需要改变自然语言描述!
# 线性回归任务
meta_prompt = """
找到最佳的线性系数w和b,使得损失函数最小。
历史结果:w=10, b=5, loss=0.8
请生成新的(w,b)组合。
"""# 旅行商问题
meta_prompt = """
找到访问所有城市的最短路径。
历史结果:路径A-B-C-D,距离=100
请生成新的路径组合。
"""# 提示词优化
meta_prompt = """
找到能最大化数学题准确率的指令。
历史结果:"Let's think step by step", 准确率=71.8%
请生成新的指令。
"""
- 不需要为每个任务编写专门的优化算法,只需要修改自然语言描述即可
- 快速部署:传统方法几周到几月,OPRO 方法:只需要几分钟
论文中展示的不同任务都用同样的OPRO框架:
| 任务类型 | 提示描述重点 |
|---|---|
| 线性回归 | “找到使损失函数最小的w, b参数” |
| 旅行商问题 | “找到访问所有节点的最短路径” |
| 数学题提示优化 | “找到提高GSM8K准确率的指令” |
| 逻辑推理提示优化 | “找到提高BBH任务准确率的指令” |
关键在于:底层的优化机制(LLM生成-评估-反馈)保持不变,只是任务描述在变化
(3) 方法验证:从简单到复杂
数学优化验证
- 线性回归和旅行商问题作为经典案例
- 证明LLMs能在小规模问题上找到高质量解
- 有时甚至匹配或超越手工设计的启发式算法
核心应用:提示词优化
- 目标:找到能最大化任务准确率的提示词
- 挑战:LLMs对提示格式敏感,语义相似的提示可能表现差异巨大
- 解决方案:使用训练集计算准确率作为优化目标
(4) 技术创新:元提示设计
元提示包含两个核心组件:
- 历史轨迹:之前生成的提示词及其对应的训练准确率
- 问题描述:包含从训练集随机选择的样例
关键区别:与现有工作不同,OPRO利用完整优化轨迹,使LLM能够发现高质量指令的共同模式
(5) 实验验证与成果
- 在多种LLMs上验证:text-bison、PaLM 2-L、GPT-3.5-turbo、GPT-4
- 在推理基准上测试:GSM8K和Big-Bench Hard
- 显著成果:
- GSM8K上提升最多8%
- Big-Bench Hard上提升最多50%
- 从低准确率起始逐步改进到超越人工设计
(6) 方法优势
- 灵活性:通过改变自然语言描述快速适应新任务
- 可定制性:可以指定解决方案的期望属性
- 有效性:在多个基准测试中显著超越传统方法
1.4 OPRO: LLM AS THE OPTIMIZER
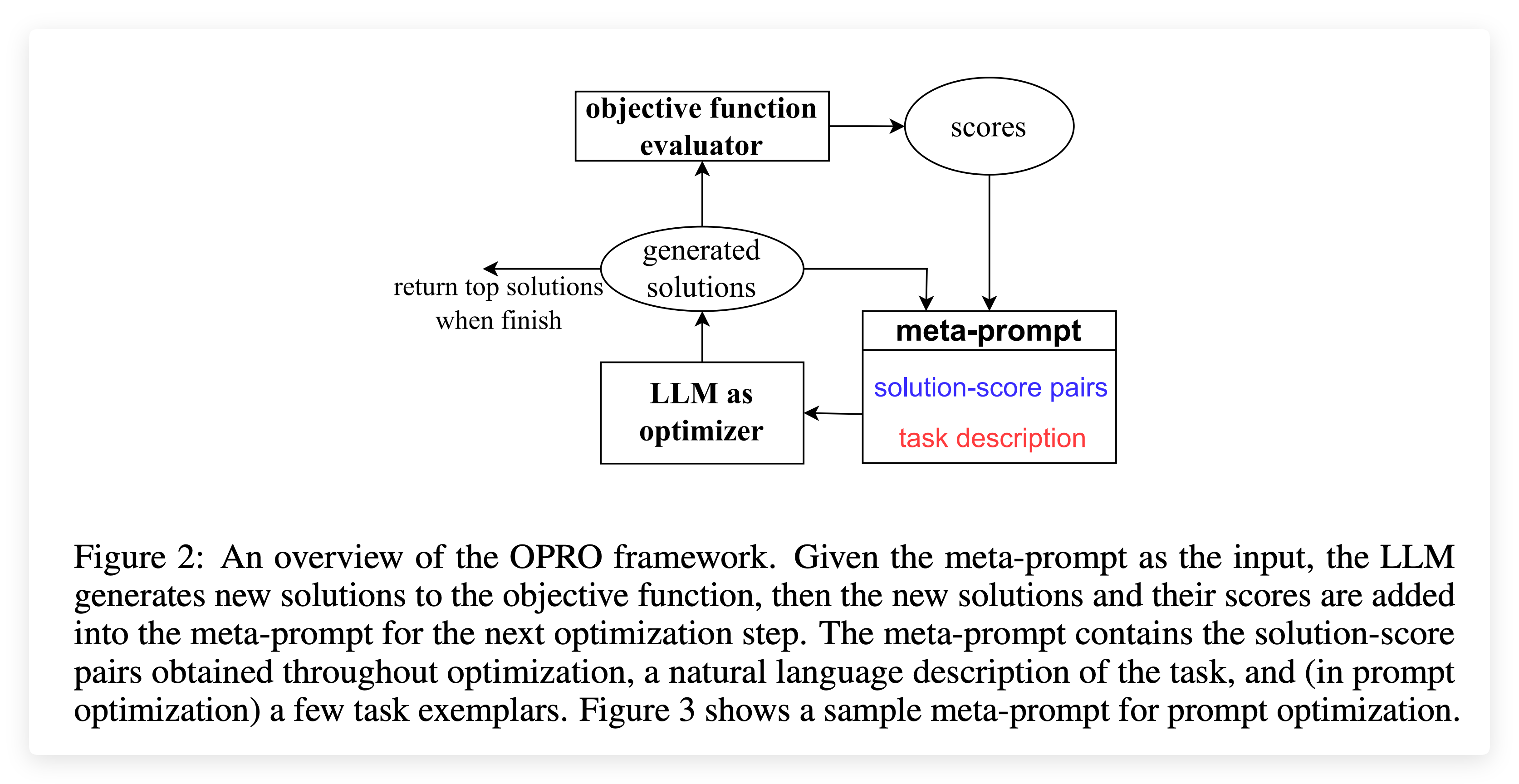
输入 → LLM生成候选解 → 评估解决方案 → 更新元提示 → 下一轮
具体过程:
- 生成阶段:LLM基于两个信息源生成候选解决方案
- 优化问题描述(任务定义)
- 历史评估结果(元提示中的解决方案-分数对)
- 评估阶段:对新生成的解决方案进行性能评估
- 更新阶段:将新的解决方案和分数添加到元提示中,为下一轮优化提供更丰富的信息
终止条件:性能收敛、步数限制
1.4.1 LLM 优化的理想目标
利用自然语言描述
- 核心优势:
- LLMs理解自然语言的能力是其作为优化器的主要优势
- 允许人们无需正式规范就能描述优化任务
- 实际价值:
- 降低门槛:不需要数学优化专业知识
- 提高灵活性:可以用高层次的文本描述复杂任务
- 易于定制:通过样例展示期望的行为模式
平衡探索与利用(Trading off exploration and exploitation)
- 优化的基本挑战:
- 探索(Exploration):寻找新的、可能更好的解决方案区域
- 利用(Exploitation):在已知好的区域深入挖掘更优解
- LLM 的要求
- 利用已知信息:在已发现的有希望区域继续搜索、基于历史好解决方案进行改进
- 探索新的可能:搜索新的解决方案空间区域,避免错过潜在的更好解决方案
OPRO 中的体现:
- 利用:LLM 分析元提示中的高分解决方案,学习其共同模式
- 探索:同时生成与历史解决方案不同的新变体
- 平衡:通过调节 LLM 的采样温度等参数来控制这种平衡
1.4.2 元提示设计(meta-prompt)
(1)优化问题描述(Optimization problem description)
- 目标函数描述:用自然语言说明要优化什么
- 解决方案约束:限制条件和要求
可定制特性
- 可以提供定制化的元指令
- 作为对生成解决方案的非正式正则化
- 例如:“指令应该简洁且普遍适用”
(2)优化轨迹(Optimization trajectory)—— 从前面内容推断
基于前面2.1节提到的内容,第二部分应该包含:
- 历史解决方案及其优化分数
- 按分数升序排列
- 让LLM能够识别高分解决方案的相似性
(3)设计原理
利用LLMs的能力
- 自然语言理解:通过文本描述而非数学公式定义优化任务
- 上下文学习:从历史样例中识别模式,无需显式训练
支持探索-利用平衡
- 元指令提供探索方向的指导
- 历史轨迹提供利用已知成功经验的信息
灵活性与定制性
- 可以通过修改问题描述快速适应新任务
- 可以通过添加约束条件指定期望的解决方案属性
(4)应用价值
这种设计使得:
- 任务适应性强:改变描述就能处理不同优化问题
- 性能可控:通过元指令控制生成解决方案的特性
- 学习能力强:通过历史轨迹累积优化经验
:::info
元提示设计是OPRO框架的核心,它将复杂的优化任务转化为LLMs能够理解和处理的自然语言任务。
:::
1.4.3 解决方案生成阶段(SOLUTION GENERATION)
过程:在解决方案生成步骤中,LLM以元提示作为输入来生成新的解决方案。
关键挑战和解决方案
(1)优化稳定性(Optimization stability)
问题:
- 并非所有解决方案都能获得高分或单调改进
- 由于上下文学习对提示敏感,LLM输出容易受到输入优化轨迹中低质量解决方案的显著影响
- 特别是初期阶段,解决方案空间还没有充分探索时
后果:
- 导致优化不稳定
- 产生较大方差
解决方案:
- 在每个优化步骤中生成多个解决方案
多解决方案生成
- 数量:每步生成多个(如8个)解决方案
- 目的:提高发现高质量解决方案的概率
- 效果:减少单次生成的随机性影响
优势:
- 让LLM能够同时探索多种可能性
- 快速发现有前景的前进方向
- 提高优化过程的稳定性
(2)探索-利用权衡(Exploration-exploitation trade-off)
调节机制:通过调节LLM采样温度来平衡探索与利用:
🌡️ 低温度 → 更多利用
鼓励LLM在已发现解决方案附近搜索
进行小幅适应性改进
更保守,更稳定
🌡️ 高温度 → 更多探索
允许LLM更激进地探索
生成显著不同的解决方案
更冒险,可能有突破
温度调节
- 动态调整:根据优化阶段调整温度
- 平衡控制:在稳定性和创新性之间找到最佳平衡点
1.5 激励示例:数学优化(MOTIVATING EXAMPLE: MATHEMATICAL OPTIMIZATION)
展示LLMs作为优化器在数学优化领域的潜力
案例一:线性回归。
- 优化类型:连续优化的代表
- 问题性质:参数空间连续,需要找到最优的数值解
案例二:旅行商问题(TSP)
- 优化类型:离散优化的代表
- 问题性质:组合优化,在有限的离散选择中找最优解
LLMs能够正确捕捉优化方向
- 通过分析历史的解决方案和对应的目标函数值
- 学会识别哪些参数变化能改善目标函数
- 生成新的解决方案朝着更优的方向前进
意义:证明了LLMs不仅仅是文本生成工具,还能理解数值优化逻辑
通用性:
- 连续+离散:覆盖了两大主要优化类型
- 无梯度:在传统梯度方法无法应用的场景中依然有效
智能程度:LLMs能够从纯文本描述的历史数据中:
- 理解优化目标
- 识别改进模式
- 推断下一步优化方向
1.5.1 线性回归
(1)实验设置
问题定义
目标:找到最佳的线性系数来解释响应变量
一维线性回归:
$ y = w*x + b + ε $
- $ w KaTeX parse error: Double subscript at position 3: _、_̲ b $两个需要优化的一维参数
- $ ε $标准高斯噪声
数据生成
- 真实参数:预先设定$ w_{true } 和 和 和 b_{true} $
- 数据点:通过真实公式生成 50 个数据点(真实点)
- x 范围从 1-50
优化流程
- 初始化:从5个随机采样的$ (w,b) $对开始
w ~ Uniform[10, 20] # w从[10,20]区间均匀随机采样
b ~ Uniform[10, 20] # b从[10,20]区间均匀随机采样
- 历史维护:元提示包含历史最佳的20个$ (w,b) $对及其排序后的目标值
一开始只有 5 个,后续慢慢增加
- 解决方案生成:每步提示LLM 8次,生成最多8个新的$ (w,b) $对
- 黑盒优化:元提示中不包含解析形式(防止LLM直接计算解)
(2)实验参数
测试的 LLM 优化器:
text-bisongpt-3.5-turbogpt-4
真实参数设置:
- 内部场景:$ w_{true} $, $ b_{true} $ ∈ [10,20] × [10,20](起始区域内)
- 近外部:参数在起始区域外,但距离<10
- 远外部:参数在起始区域外,且距离>10
(3)关键结果
- 所有模型探索的$ (w,b) $对数量都少于穷举搜索
- 证明LLMs能进行有效的黑盒优化:比较数值并提出下降方向
难度影响:
- 距离效应:当真实参数距离起始区域越远,所有模型都需要更多探索和步数
- 合理表现:符合优化理论的预期
(4)重要意义
- 概念验证:LLMs确实能理解数值优化逻辑
- 智能优化:不是随机搜索,而是有策略的方向性搜索
- 模型差异:不同LLMs在优化能力上存在显著差异
- 实用局限:在小规模问题上有效,为更复杂应用奠定基础

测量指标:
- 收敛步数:到达全局最优解所需的平均步数 ± 标准差【优化迭代轮次】
- 探索效率:到达全局最优解前探索的唯一$ (w,b) $对数量 ± 标准差
一个优化步骤可能生成多个参数对,所以唯一对数通常比步数大。
每个模型探索的唯一(w,b)对的数量少于穷举搜索
1.5.2 旅行商问题
(1)问题背景
问题定义:
- 经典组合优化问题
- 目标:给定 n 个节点,找到最短路径遍历所有节点并回到起点
- 应用广泛:物流、电路设计等领域
现有方法:
- 启发式算法:最近邻、最远插入等
- 精确求解器:Concorde、Gurobi等
- 深度学习方法:训练神经网络求解
(2)OPRO 实验设置
初始化与迭代
- 起始解:5个随机生成的路径
- 每步生成:最多8个新解决方案
- 问题实例:n个节点,坐标在[-100, 100]范围内随机采样
评估基准:
- Oracle解:使用Gurobi求解器获得最优解
- 评估指标:最优性差距(optimality gap)
gap = (OPRO_distance - optimal_distance) / optimal_distance
(3)对比方法
启发式算法:
- 最近邻算法(NN)
- 从起始节点开始
- 每次选择距离当前节点最近的未访问节点
- 直到所有节点都被访问
- 最远插入算法(FI)
- 考虑插入新节点的最小成本:
- c(k) = min(i,j) {d(i,k) + d(k,j) - d(i,j)}
- 每次添加能最大化最小插入成本的节点
在这些未访问的节点中,我们选择那个 c(k) 值最大的节点作为下一个要插入的节点。
为什么是最大化? 这个策略的直观想法是:优先处理那些“最难”或者“距离当前路径最远”(以插入成本衡量)的节点。通过先将这些“最远”的节点纳入路径,算法试图尽早地勾勒出路径的整体骨架。这样做可以避免在后期因为要迁就一些孤立的远点而对已形成的良好路径结构造成大的破坏。
(4)实验结果
规模与性能关系:
- n=10: 所有LLM都能找到最优解
- n=15: gpt-4仍表现良好,其他开始退化
- n=20: 性能差距明显
- n=50: 传统启发式算法开始超越LLM
模型性能对比:
gpt-4: 显著超越其他LLM
- 小规模问题:比其他LLM快4倍收敛
- 大规模问题:仍能找到可比质量的解
(5)方法局限性
可扩展性问题:
- 上下文长度限制:难以处理大规模问题描述
- 性能快速退化:随问题规模增长性能急剧下降
优化景观复杂性:
- 局部最优陷阱:复杂目标函数让LLM难以找到正确下降方向
- 优化卡住:经常在既非全局也非局部最优的点停止
设计目标澄清:
- OPRO不是为了超越最先进的算法而设计!
- 目标是证明:
- LLM能通过提示进行不同类型的优化
- 在小规模问题上达到全局最优
- 展示作为通用优化器的潜力
(6)重要意义
概念验证:
- 证明LLM能处理离散组合优化问题
- 展示了从连续优化到离散优化的通用性
能力边界:
- 明确了当前方法的适用范围和局限性
- 为future work提供了改进方向
为主应用铺路:
- 数学优化作为"热身",验证基础能力
- 为提示词优化(更适合LLM的任务)建立信心

行表示问题规模:n 个城市的 TSP 问题。(每个规模测试5个不同的问题实例)
最优性差距:optimality gap = (算法解 - 最优解) / 最优解 × 100%
步数与成功率:
- steps: 找到最优解的平均步数 ± 标准误差
- successes: 在5个问题中找到最优解的问题数量
结论: 小规模时LLM完全碾压传统算法。大规模时LLM完全失效
1.6 应用场景:提示词优化
接下来,我们展示了OPRO在提示词优化上的有效性,其目标是找到能够最大化任务准确率的提示词。我们首先介绍问题设置,然后说明元提示的设计。
1.6.1 问题设置
这部分详细描述了提示词优化任务的完整问题设置:
(1)任务定义:
应用范围:
- 专注于自然语言任务
- 输入和输出都是文本格式
- 覆盖各种NLP任务(推理、理解等)
数据集结构:
- 数据集 = {训练集, 测试集}
- 训练集 → 计算训练准确率 → 优化过程中的目标值
- 测试集 → 计算测试准确率 → 优化完成后的最终评估
(2)优化目标与数据效率:
小数据集优势。
传统优化通常需要大量训练数据,但OPRO实验显示:
- GSM8K: 仅需3.5%的训练样本就足够
- BBH: 仅需20%的训练样本就足够
目标函数:
- 目标: 最大化训练准确率
- Prompt* = argmax Accuracy(Prompt, 训练集)
(3)LLM 角色分工
双 LLM 架构
- 优化器LLM (Optimizer LLM):
- 角色: 生成新的提示词指令
- 输入: 元提示 (历史结果 + 任务描述)
- 输出: 候选提示词指令
- 评分器LLM (Scorer LLM):
- 角色: 评估提示词性能
- 输入: 提示词 + 任务样例
- 输出: 任务预测结果
LLM选择灵活性
- 可以是相同的LLM担任两个角色
- 也可以是不同的LLM分工协作
(4)指令插入位置
Q_begin: 问题前插入
[指令]
Q: Janet's ducks lay 16 eggs per day...
A:
Q_end: 问题后插入
Q: Janet's ducks lay 16 eggs per day...
[指令]
A:
A_begin: 答案开头插入
Q: Janet's ducks lay 16 eggs per day...
A: [指令]
- 适用场景: 预训练LLM(未经指令调优)
- 格式: QA对序列格式
Q_begin: 指令影响对问题的理解
Q_end: 问题影响对指令的解读
A_begin: 指令直接影响回答生成
Q_begin: "Think step by step"
→ 让LLM从一开始就准备逐步推理Q_end: "Show your calculation process"
→ 在看完具体数学题后强调计算过程A_begin: "Let me work through this carefully:"
→ 以谨慎的语调开始解答
在OPRO实验中,研究者会:
- 根据评分器LLM的类型选择合适的插入位置
- 对比不同位置的优化效果
- 为每种位置独立优化最佳指令
(5)实际工作流程
优化循环:
- 优化器LLM生成候选指令
- 将指令插入到训练样例中
- 评分器LLM执行任务并计算准确率
- 更新元提示,进入下一轮
评估方式:
训练阶段: 在小训练集上快速评估
测试阶段: 在完整测试集上最终验证
(6)设计优势
- 效率性
- 小数据集训练,大幅降低计算成本
- 快速迭代优化过程
- 灵活性
- 多种指令插入位置适应不同LLM类型
- 优化器和评分器可独立选择
- 实用性
- 直接针对任务准确率优化
- 无需人工试验不同提示词
1.6.2 元提示设计
这部分详细描述了针对提示词优化任务的元提示设计,说明了如何构建有效的meta-prompt

实验设置:
- 任务: GSM8K数学推理题
- 优化器LLM: 指令调优的PaLM 2-L (PaLM 2-L-IT)
- 插入位置: A_begin(答案开头插入)
具体插入方式:
- Q: Janet’s ducks lay 16 eggs per day…
- A: [生成的指令] + LLM的实际回答
蓝色文本: 解决方案-分数对
- 作用: 提供历史优化轨迹,让LLM学习什么样的指令效果更好
紫色文本: 任务描述和输出格式
- 作用:
- 解释如何使用生成的指令
- 说明期望的输出格式
- 定义优化目标
橙色文本: 元指令
- 具体的指导信息,告诉LLM如何进行优化
- 作用: 提供明确的操作指南和约束条件
指令插入位置的占位符
工作流程:
LLM理解过程
- 分析历史: 看到"Let’s solve the problem" (score: 63)比"Let’s figure it out!" (score: 61)效果更好
- 理解任务: 通过样例知道这是数学应用题
- 明确目标: 需要生成比63分更高的新指令
- 遵循格式: 用方括号输出新指令
(1)元提示的三个核心组件
优化问题样例 (Optimization problem examples)
作用:
- 从训练集中选取少量样例来展示任务本质
- 帮助优化器LLM理解要优化什么样的任务
具体内容:
- 输入-输出对样例
- 展示任务类型 (如数学推理题)
- 显示指令插入位置 (标记)
展示:
从上图的输入输出对可以推断:
输入: Q: Alannah, Beatrix, and Queen are preparing for...
输出: 140
→ LLM理解这是数学应用题
采样策略:
- 每步随机采样:每轮优化随机选择3个训练样例
- 针对性采样:可选择之前指令表现不佳的样例
优化轨迹 (Optimization trajectory)
历史信息结构:
指令1 + 分数1
指令2 + 分数2
...
指令N + 分数N (按分数升序排列)
关键设计决策
- 排序方式:按训练准确率升序排列
- 数量限制:只保留最高分数的指令(考虑上下文长度)
- 分数来源:训练集上的准确率
作用机制
- 让LLM识别高分指令的共同模式
- 鼓励生成类似于成功指令的新变体
- 避免重复已验证无效的指令
元指令 (Meta-instructions)
功能:向优化器 LLM 解释:
- 优化目标:生成更高准确率的指令
- 使用方法:如何利用上述信息
- 输出格式:期望的指令格式
内容示例:
“Write your new text that is different from the old ones and has a score as high as possible. Write the text in square brackets.”
定制化指导:添加额外约束
“the instruction should be concise and generally applicable” (指令应该简洁且普遍适用)
(2)设计原理
利用 LLM 的上下文学习能力:历史轨迹 → 模式识别 → 生成改进版本
平衡信息量与上下文限制:
- 足够的历史信息 vs. 不超出LLM上下文窗口
- 任务理解样例 vs. 不占用过多空间
鼓励探索-利用平衡:
- 历史最佳指令 → 利用已知成功模式
- “different from old ones” → 鼓励探索新变体
(3)实际应用示例
GSM8K任务的元提示
[历史结果部分]
text: Let's figure it out!
score: 61
text: Let's solve the problem.
score: 63
...[任务样例部分]
input: Q: Alannah, Beatrix, and Queen are preparing...
A: <INS>
output: 140[元指令部分]
Write your new text that is different from the old ones
and has a score as high as possible...
(4)关键设计选择
样例数量:
- 默认3个训练样例
- 平衡任务理解 vs. 上下文长度
历史指令数量:
- 默认保留20个最佳指令
- 根据LLM上下文窗口调整
更新策略:
- 每轮添加8个新生成的指令
- 保持最优的20个,淘汰其余
1.7 提示词优化实验
OPRO在各种LLM组合下都带来了显著性能提升
全面有效性:不同的优化器-评分器组合都表现良好
5.1 → 建立实验基础
5.2 → 证明方法有效
5.3 → 理解为什么有效
5.4 → 确认结果可靠
5.5 → 证明相对优越
1.7.1 评估设置
(1)LLM 模型配置
优化器LLM (Optimizer LLM):负责生成新的提示词指令
- Pre-trained PaLM 2-L (Anil et al., 2023)
- Instruction-tuned PaLM 2-L (PaLM 2-L-IT)
- text-bison
- gpt-3.5-turbo
- gpt-4
评分器LLM (Scorer LLM):负责评估提示词性能
- Pre-trained PaLM 2-L
- text-bison
模型搭配策略:
- Pre-trained PaLM 2-L作为评分器 → 优化器LLM生成A_begin指令
- text-bison作为评分器 → 优化器LLM生成Q_begin和Q_end指令
- 原因: text-bison经过指令调优,更适合Q位置的指令格式
(2)基准测试数据集
GSM8K (Cobbe et al., 2021)
- 任务类型: 小学数学应用题
- 数据规模: 7,473训练样本 + 1,319测试样本
- 特点: 链式思维推理 (chain-of-thought) 效果显著
- 经典指令: “Let’s think step by step.” 带来巨大提升
Big-Bench Hard (BBH) (Suzgun et al., 2022)
- 任务类型: 23个具有挑战性的BIG-Bench任务
- 覆盖范围:
- 符号操作 (symbolic manipulation)
- 常识推理 (commonsense reasoning)
- 算术推理之外的广泛主题
- 数据规模: 每个任务最多250个样本
转移性测试数据集
为了验证优化指令的跨数据集泛化能力:
- MultiArith (Roy & Roth, 2016): 数学推理
- AQuA (Ling et al., 2017): 数学推理
测试GSM8K优化得到的指令在其他数学任务上的效果
(3)实施细节
温度设置:
- 评估指令性能时: temperature = 0 (贪婪解码)
- 生成新指令时: temperature = 1.0 (默认设置,鼓励多样性)
生成策略
每个优化步骤:
- 提示优化器LLM共8次
- 生成8个候选指令
- 添加到优化轨迹中
元提示配置
- 历史指令数量: 保留最佳20个指令
- 任务样例数量: 每步随机选择3个训练样例
- 上下文管理: 考虑LLM上下文长度限制
(4)评估指标与流程
优化过程
- 训练阶段: 在小训练集上计算准确率作为优化目标
- 测试阶段: 在完整测试集上评估最终性能
数据效率
- GSM8K: 仅使用3.5%的训练数据进行优化
- BBH: 仅使用20%的训练数据进行优化
验证: 小训练集优化足以获得良好的测试性能
消融研究设置
在5.3节中研究不同超参数的影响:
- 历史指令数量的影响
- 任务样例数量的影响
- 温度参数的影响
- 元提示设计的影响
(5)实验控制
公平比较
-
所有方法使用相同的评分器LLM
-
相同的基准测试数据集
-
统一的评估指标 (准确率)
可重现性
-
详细的超参数设置
-
明确的模型版本信息
-
标准化的实验流程
多样化验证
-
多种优化器-评分器组合
-
多个基准测试任务
-
跨数据集转移性测试
(6)设计合理性
模型选择多样性
- 覆盖不同规模和类型的LLM
- 包括预训练和指令调优版本
- 验证方法的通用性
任务覆盖全面性
- 数学推理 + 多领域推理
- 不同难度级别的任务
- 验证方法的适用范围
实验设置严谨性
- 控制变量的科学设计
- 统计显著性的考虑
- 泛化能力的专门测试
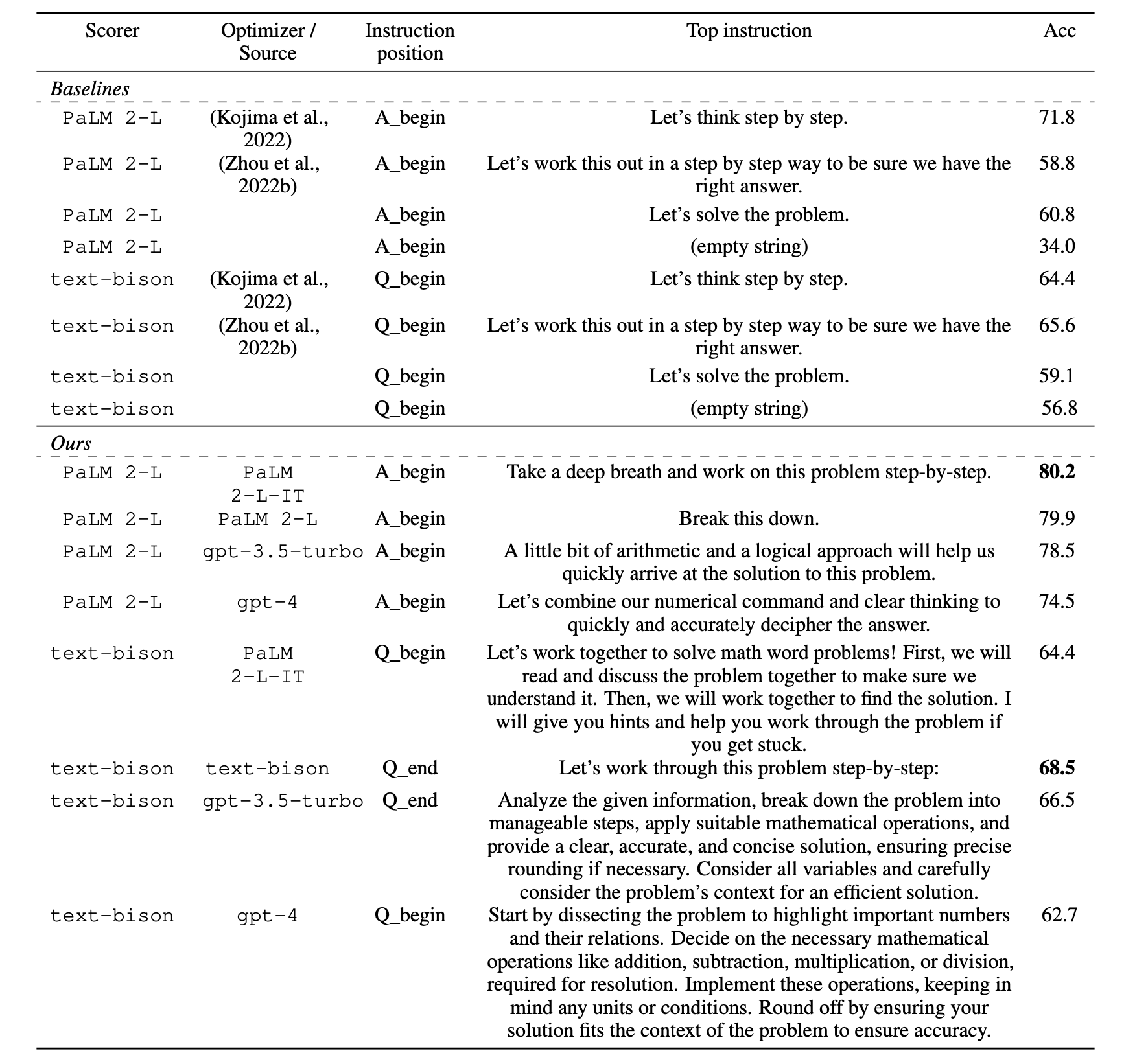
这张表格展示了GSM8K任务上各种方法的详细性能对比
列:
Scorer: 评分器LLM (PaLM 2-L 或 text-bison)
Optimizer/Source: 优化器LLM或基线方法来源
Instruction position: 指令插入位置
Top instruction: 获得最高测试准确率的具体指令
Acc: 测试准确率
行:
Baselines: 人工设计的基线指令
Ours: OPRO优化得到的指令
自动化优化的价值
- 超越人类直觉: 找到了人类不太可能想到的指令
- 系统性改进: 所有OPRO指令都超越了基线
- 适应性: 不同LLM找到了不同风格但都有效的指令
实际应用价值
- 即插即用: 这些优化指令可以直接用于GSM8K类似任务
- 迁移潜力: 可能在其他数学推理任务上也有效
- 方法验证: 证明了自动化提示词优化的巨大潜力
1.7.2 主要结果 (Main Results)
这部分是论文的核心实验结果展示,详细呈现了OPRO在主要基准测试上的表现
(1) GSM8K结果详细分析
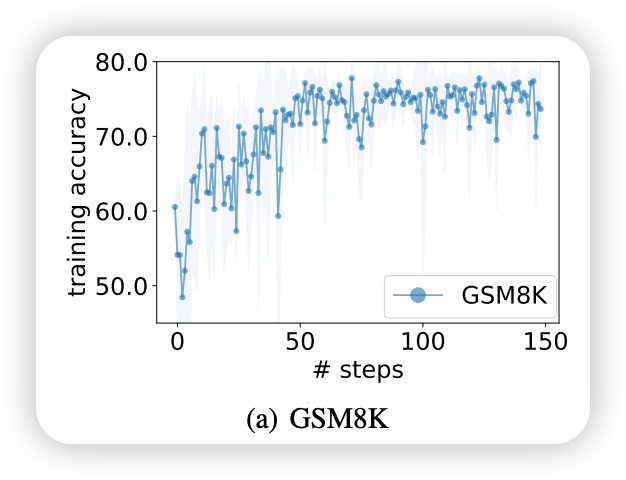
数据使用策略
- 训练样本使用: 仅3.5%的GSM8K训练集 (约261个样本)
- 目的: 平衡评估成本与泛化性能
- 验证: 小训练集优化足以在完整测试集上获得良好性能
通过优化曲线图展示训练过程:
Figure 1(a): PaLM 2-L评分器 + PaLM 2-L-IT优化器
-
起始点: “Let’s solve the problem” (60.5%训练准确率)
-
优化轨迹: 显示整体上升趋势和几次显著跃升
-
终点: 达到更高的性能水平
关键优化里程碑
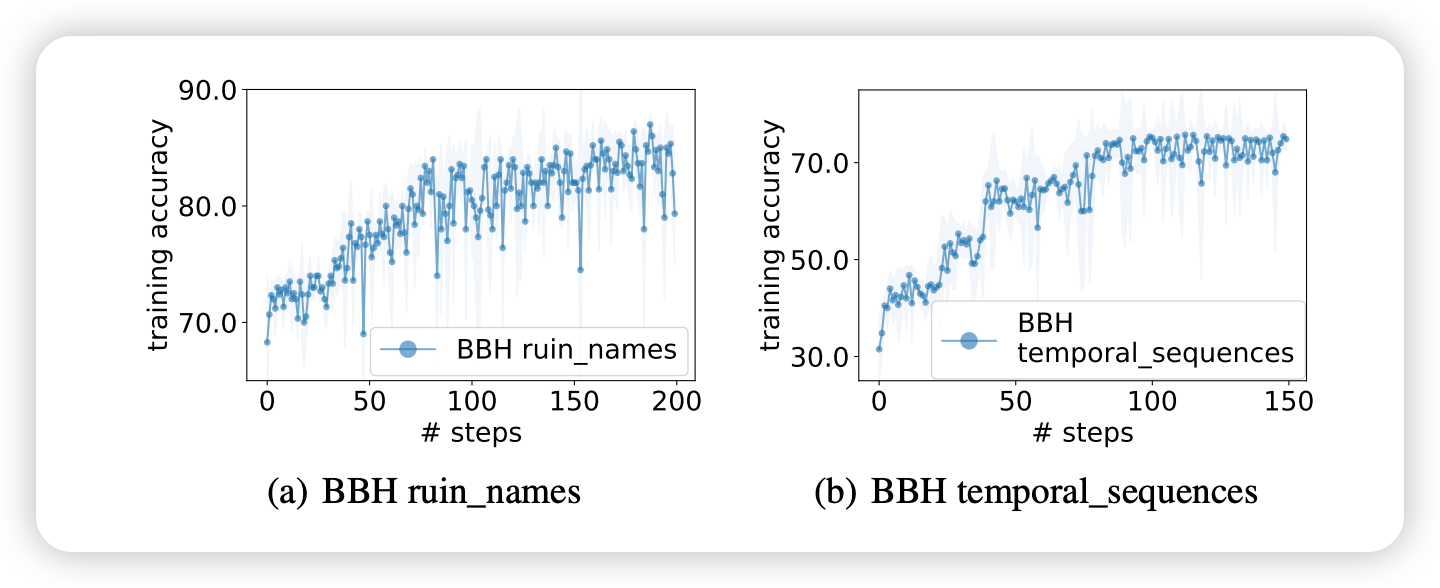
第2步: "Let's think carefully about the problem..." → 63.2%
第4步: "Let's break it down!" → 71.3%
第5步: "Let's calculate our way to the solution!" → 73.9%
第6步: "Let's do the math!" → 78.2%
第107步: "Take a deep breath and work..." → 80.2% (最终最佳)
优化特征分析
- 整体上升趋势: 训练准确率持续改善
- 方差递减: 每步生成指令的准确率分布方差逐渐减小
- 分布式改进: 不是单个突破,而是整体指令质量的系统性提升
(2) BBH结果全面展示
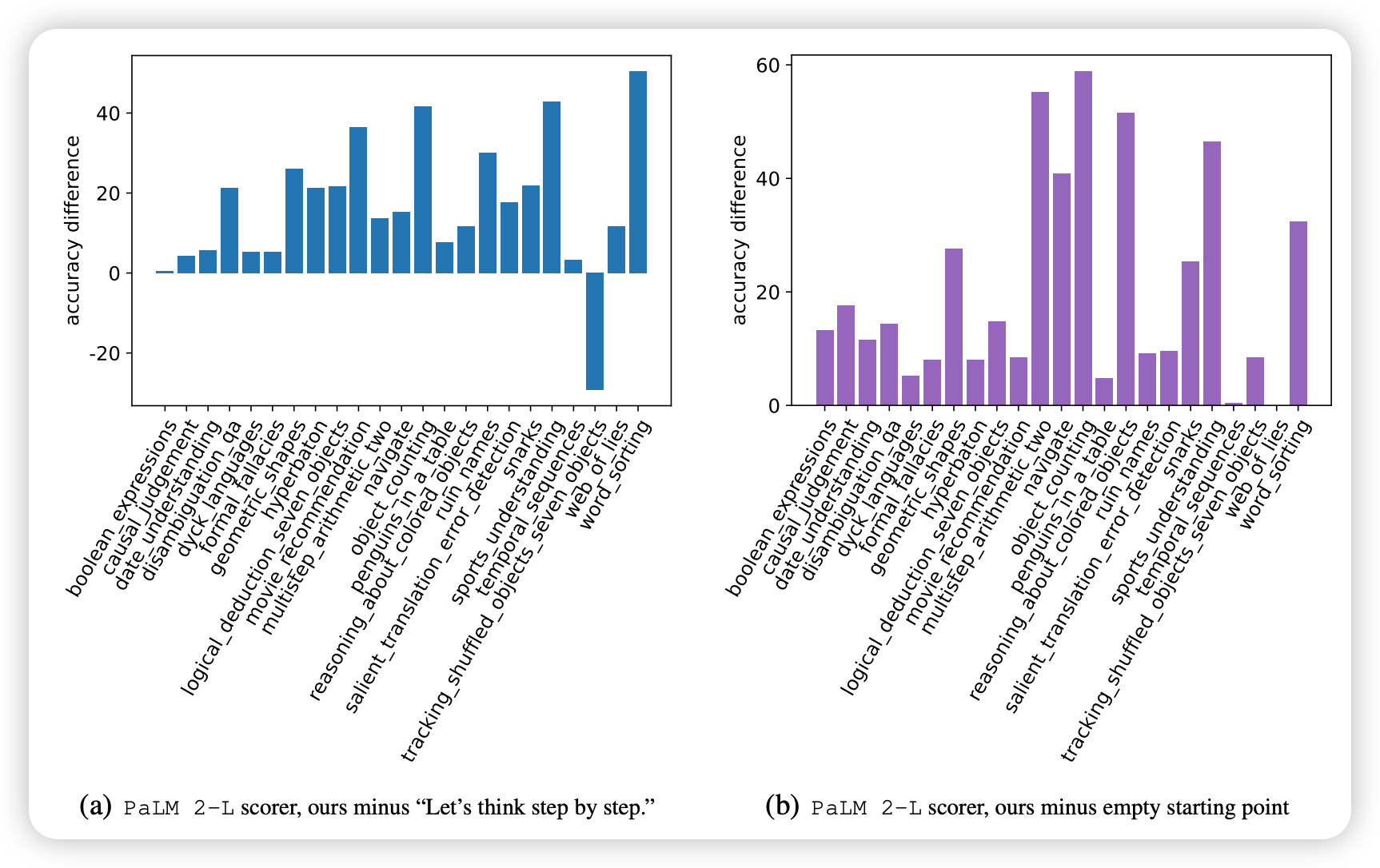
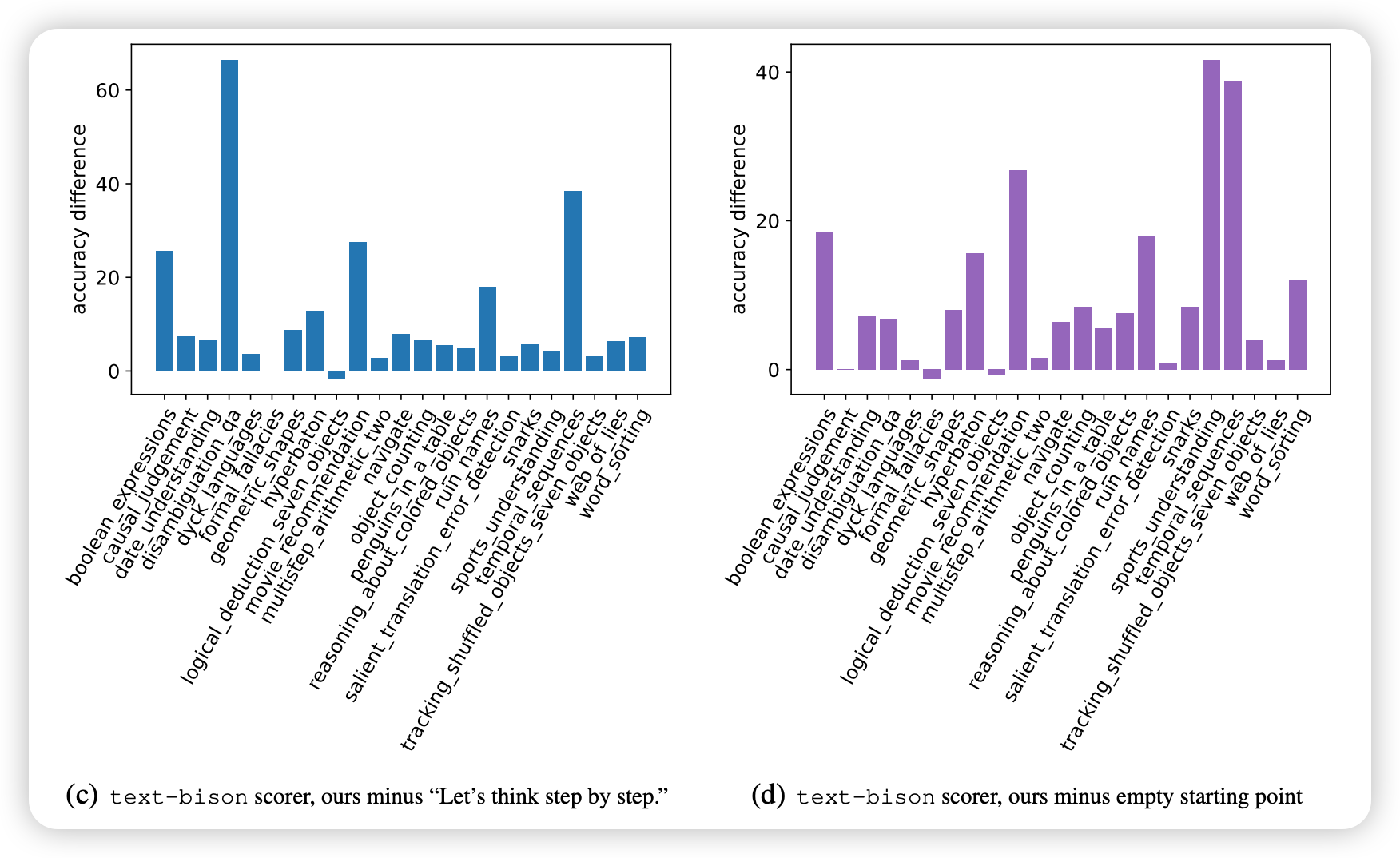
BBH任务总数: 23个具有挑战性的任务
覆盖领域:
- 符号操作 (symbolic manipulation)
- 常识推理 (commonsense reasoning)
- 逻辑推理
- 数学推理
等广泛主题
每个任务:
- 20%样例 → 提示优化
- 80%样例 → 测试评估起始指令: 默认从空字符串开始
指令位置:
- PaLM 2-L评分器 → A_begin
- text-bison评分器 → Q_begin
评分器: text-bison
优化器: PaLM 2-L-IT
起始: 空指令 (训练准确率64.0%)优化里程碑:
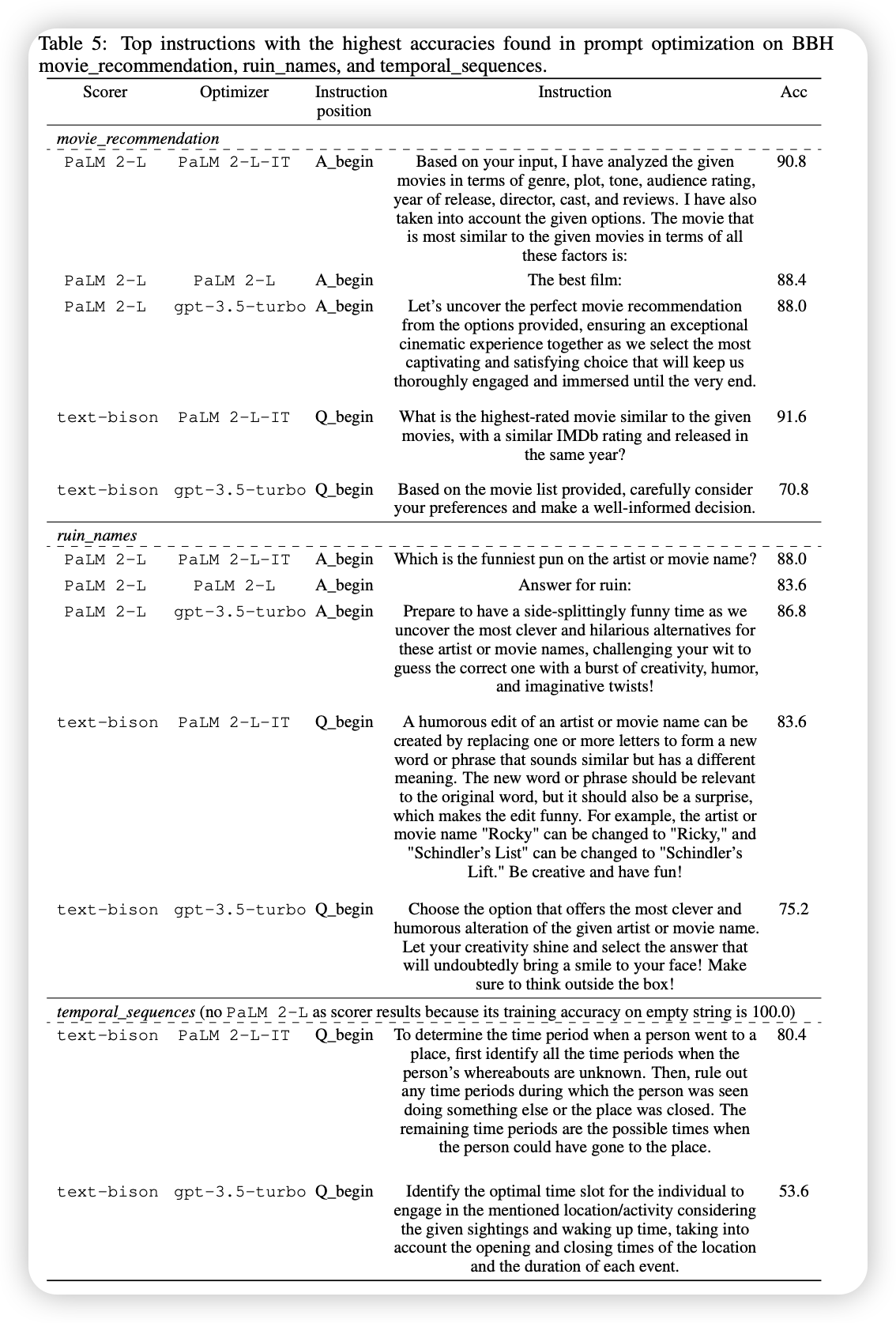
第1步: "Consider the following when editing artist or movie names humorously:"
→ 训练准确率: 72.0%第18步: "When making humorous edits of artist or movie names, you can change one or more letters or even create puns by adding new words that sound similar."
→ 训练准确率: 80.0%第38步: "We can make humorous edits of artist/movie names by changing letters to create new words that are similar in sound but have different meanings. For example, The Police can be changed to The Polite, The Abyss can be changed to Toe Abyss, and Schindler's List can be changed to Schindler's Lost."
→ 训练准确率: 82.0%
起始: 空指令 (训练准确率64.0%)第2步: "To solve this problem, we need to first identify the time period when the person was not seen doing anything else. Then, we need to check if the place they went to was open during that time period. If it was, then that is the time period when they could have gone to that place."
→ 训练准确率: 42.0% (临时下降)第18步: "To find the time period when a person could have gone to a place, identify the time periods when they were not seen doing anything else and the place was open. If there are multiple time periods that match these criteria, then the person could have gone to the place during any of these time periods."
→ 训练准确率: 54.0%第41步: "To determine the possible time period when a person went to a place, first identify all the time periods when the person was not seen doing anything else and the place was open. Then, rule out any time periods during which the person was seen doing something else. The remaining time periods are the possible times when the person could have gone to the place."
→ 训练准确率: 72.0%
这些BBH结果证明了:
- 广泛适用性: OPRO不仅适用于数学推理,还适用于多种推理任务
- 持续有效性: 在23个不同任务上都能找到改进的指令
- 多样化优化: 不同任务需要不同类型的指令,OPRO能适应这种多样性
- 鲁棒性验证: 大规模多任务实验为方法的可靠性提供了强有力证据
BBH实验展示了OPRO作为通用提示词优化方法的强大能力和广泛适用性。
(3) 语义相似指令的性能差异分析
即使是语义上非常相似的指令,在实际任务性能上可能表现出巨大且出人意料的差异。
"Let's think step by step."
→ 准确率: 71.8%"Let's solve the problem together."
→ 准确率: 60.5%"Let's work together to solve this problem step by step."
→ 准确率: 49.4%第三个指令看似是前两个的"语义组合":
"solve the problem together" + "step by step"
→ 但性能却是最差的 (49.4%)违反直觉:语义组合 ≠ 性能提升
提示词敏感性的根本原因:
LLM的上下文敏感性
LLM对输入文本的细微变化极其敏感:
- 词汇选择
- 句式结构
- 语调风格
- 指令长度
都可能影响模型的"理解"和反应
隐含语义的复杂性
"step by step" → 可能激活系统化推理模式
"together" → 可能激活协作对话模式
"work together...step by step" → 可能产生模式冲突
训练数据的分布偏差
不同表述在训练数据中的出现频率不同
模型对某些特定表述有更强的"条件反射"
(4) 优化指令的跨数据集转移能力
源任务: GSM8K (小学数学应用题)
目标任务:
- MultiArith (Roy & Roth, 2016) - 数学推理
- AQuA (Ling et al., 2017) - 数学推理
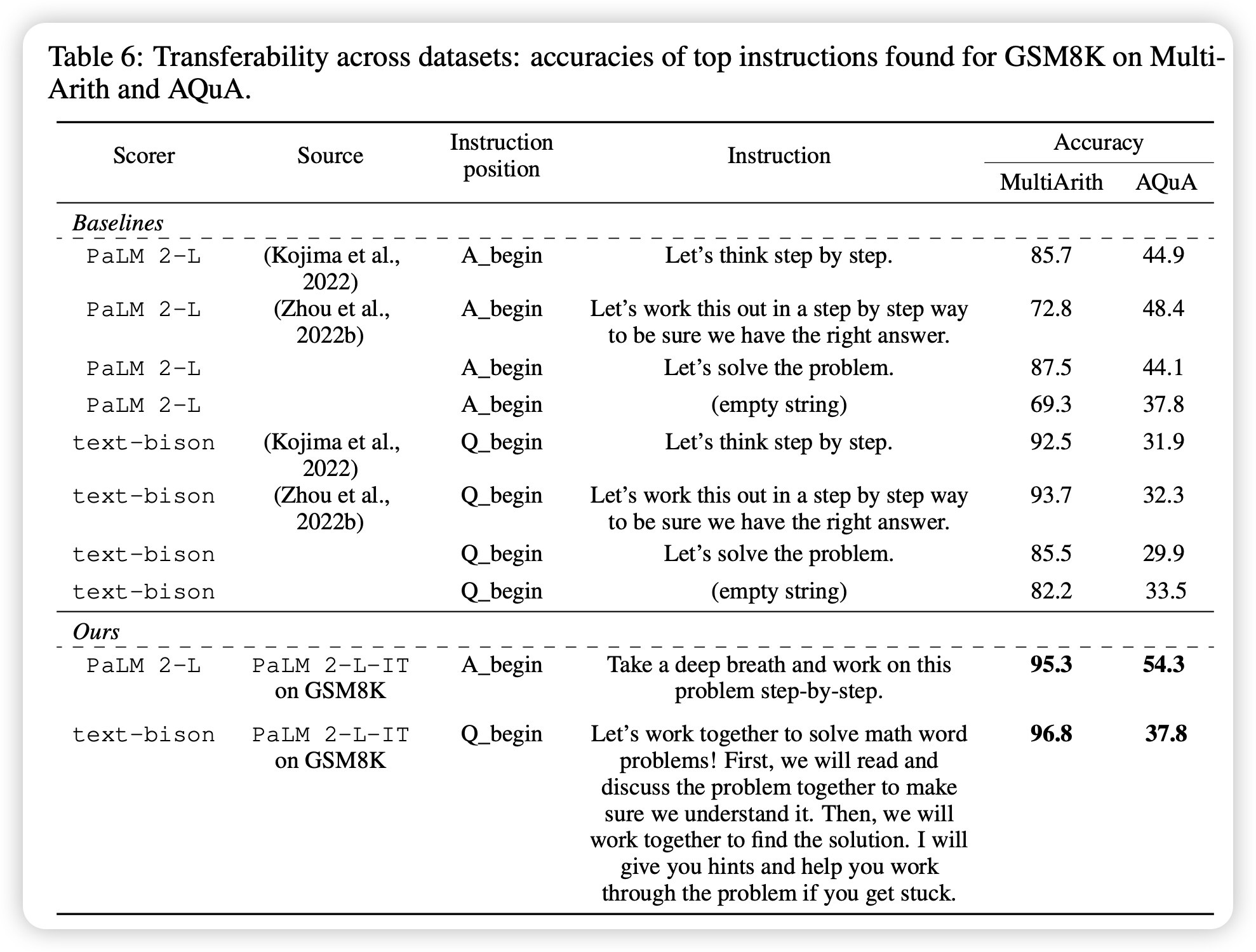
转移成功性验证
- 所有测试场景中OPRO指令都超越基线
- 提升幅度与原GSM8K任务相当
- 证明优化指令学到了通用的数学推理模式
1.7.3 消融研究 (Ablation Studies)
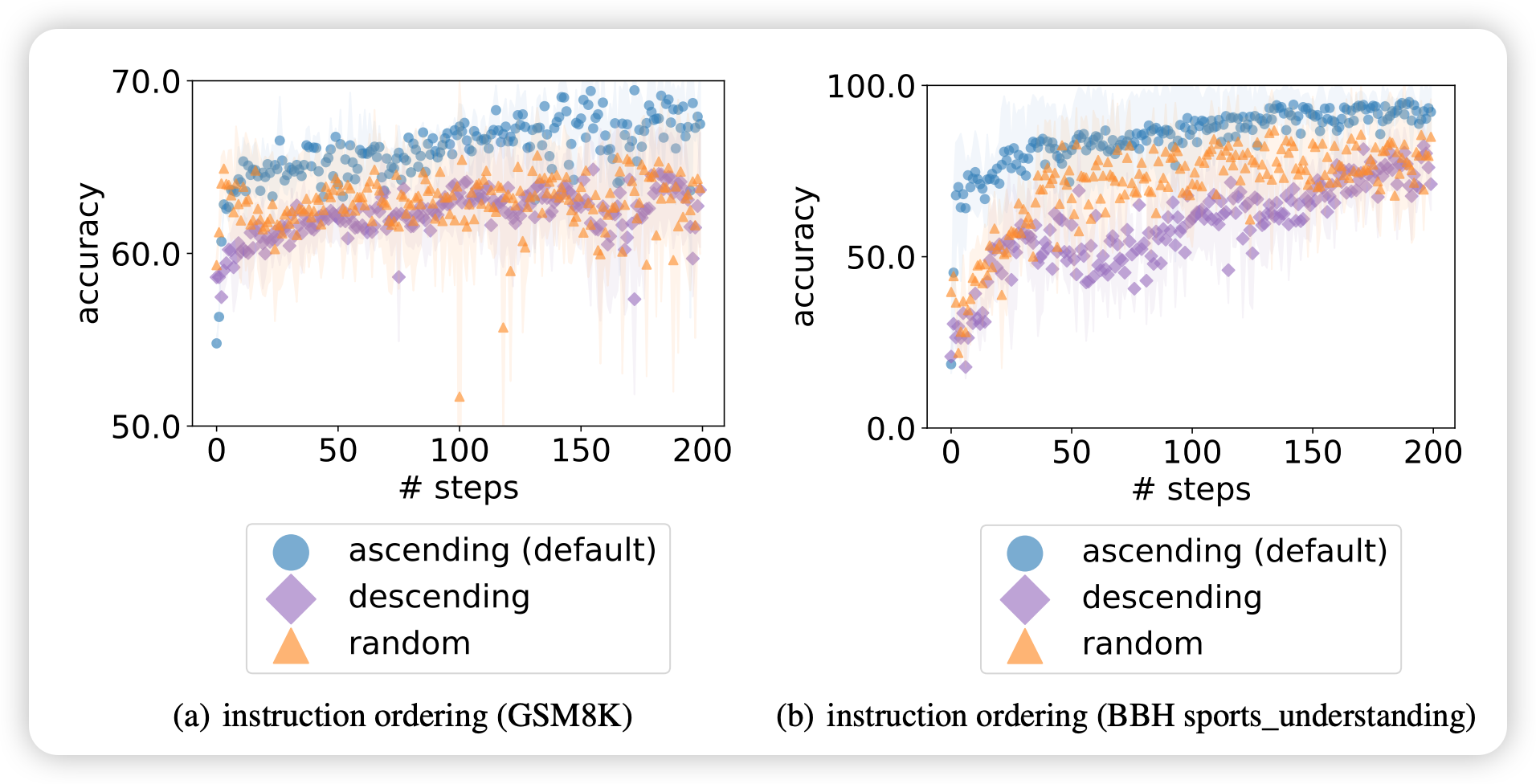
历史指令排序方式的影响:
- 假设: LLM输出更容易受到提示末尾内容的影响
- 根据: 近因偏差 (recency bias) - Zhao et al. (2021)
- 结论: 将最佳指令放在末尾能更好地指导生成
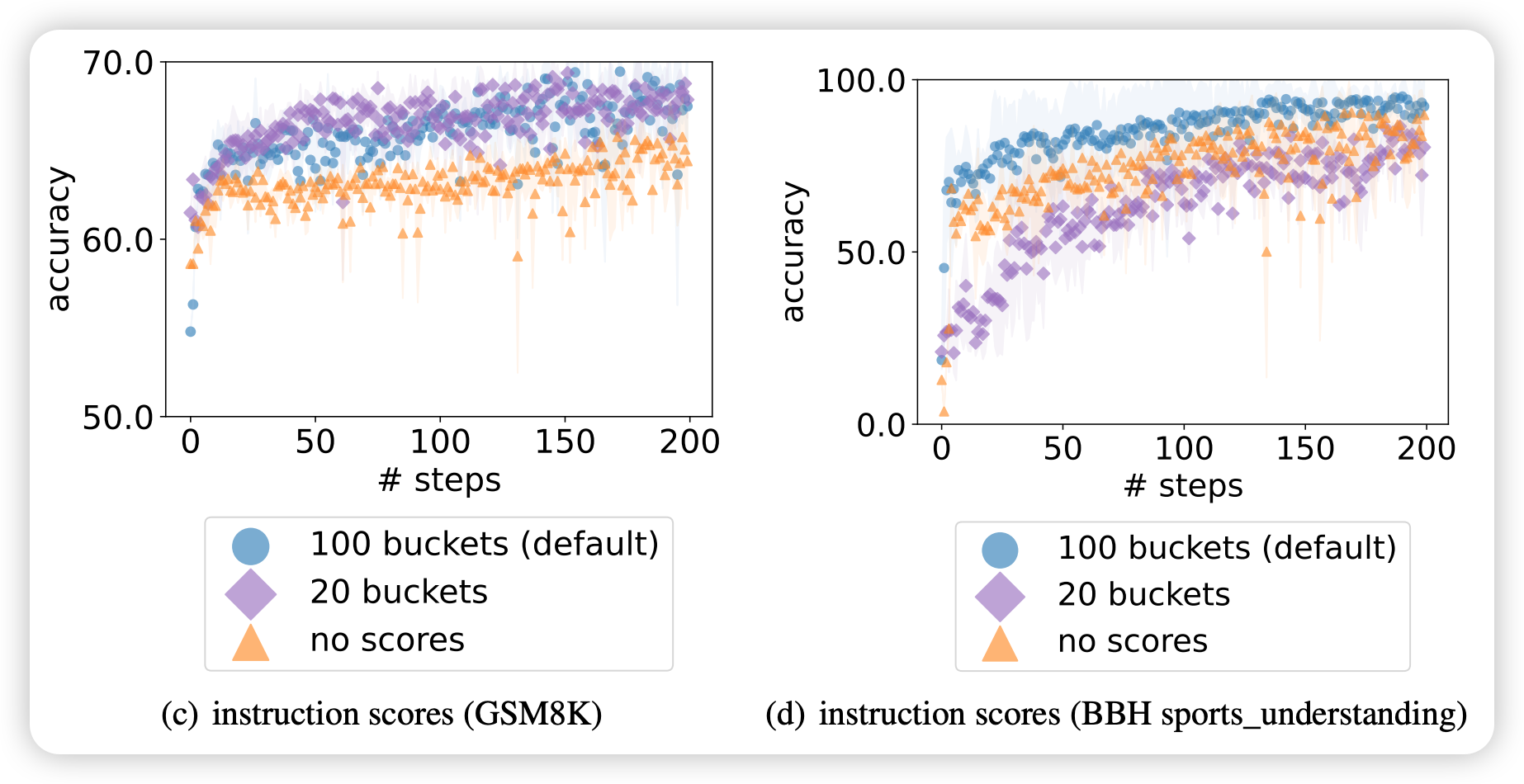
准确率分数呈现方式的影响:
- 四舍五入到整数 (默认设置) - 相当于100个桶
- 分桶到20个级别
- 不显示分数,只按升序排列
实验结果:
- 显示准确率分数 > 不显示分数
- 结论: 分数信息帮助优化器LLM理解质量差异
- 机制: 更好地识别高质量指令的特征
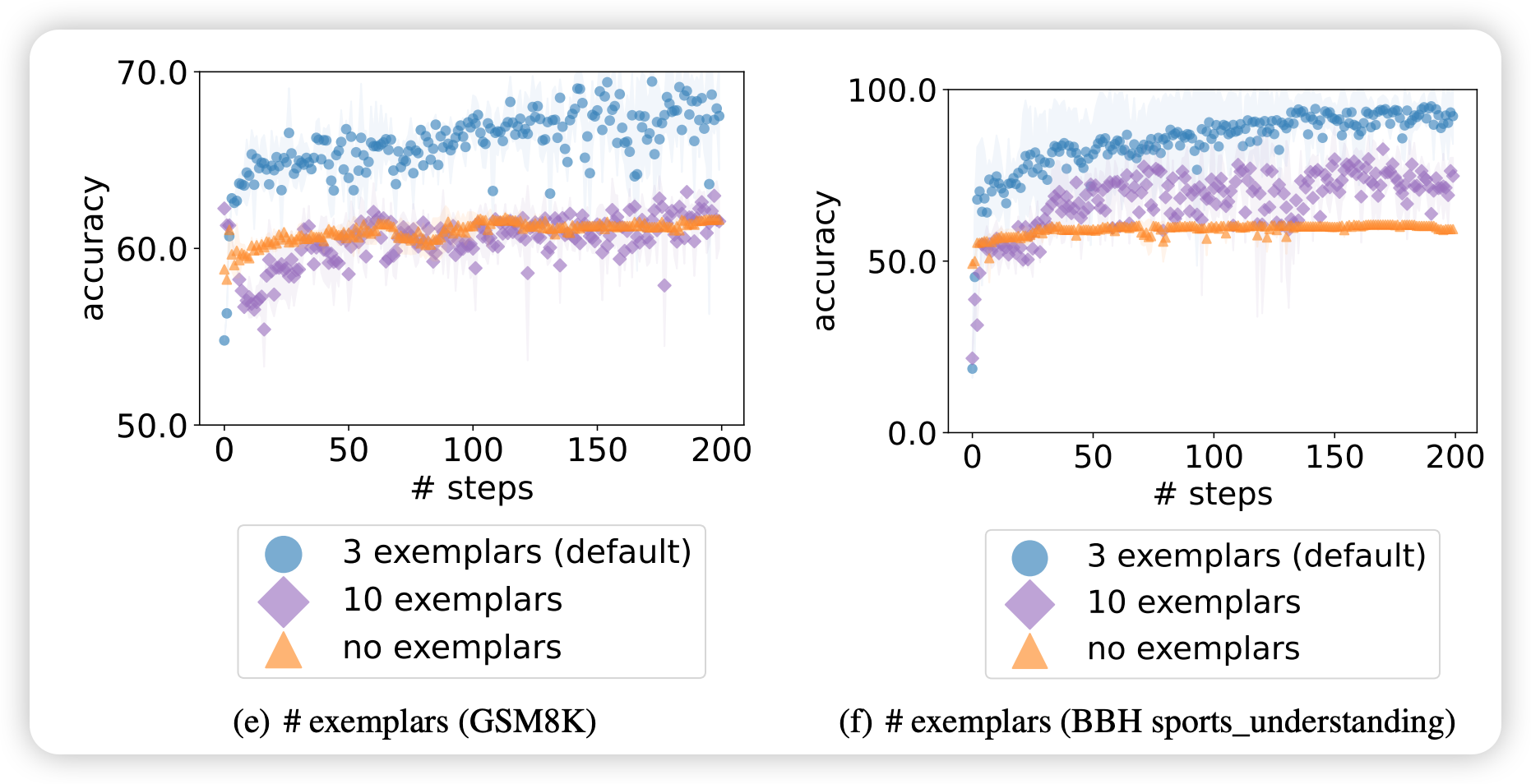
任务样例数量的影响:
- 3个样例 (默认设置)
- 10个样例
- 无样例
关键发现:
- 包含样例至关重要:
- 提供任务理解信息
- 帮助生成更合适的指令
- 更多样例不一定更好:
- 10个样例效果并不比3个好
- 过多样例占用上下文空间
- 可能分散优化器LLM的注意力
- 平衡点: 少量样例足以描述任务特征
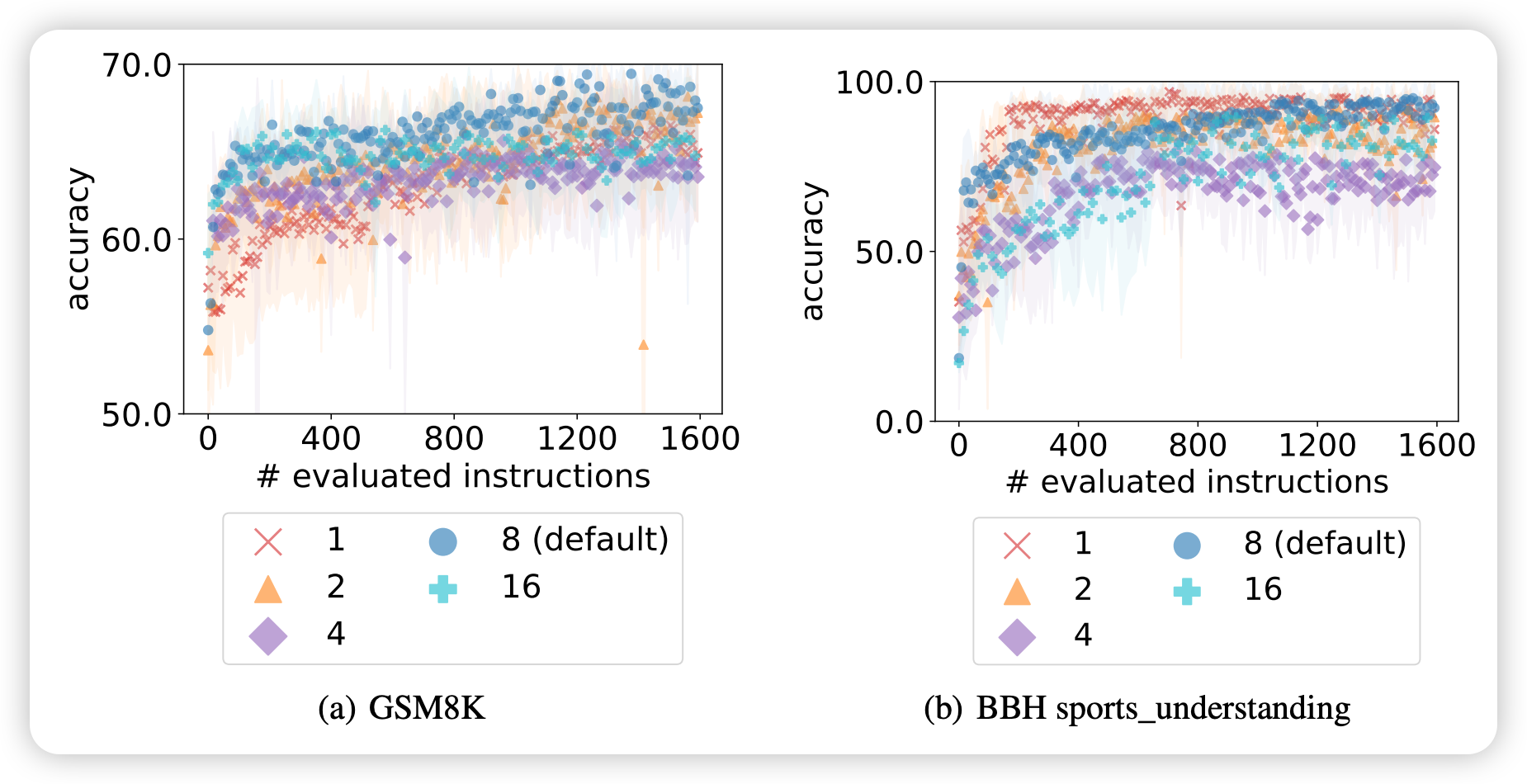
每步生成指令数量的影响
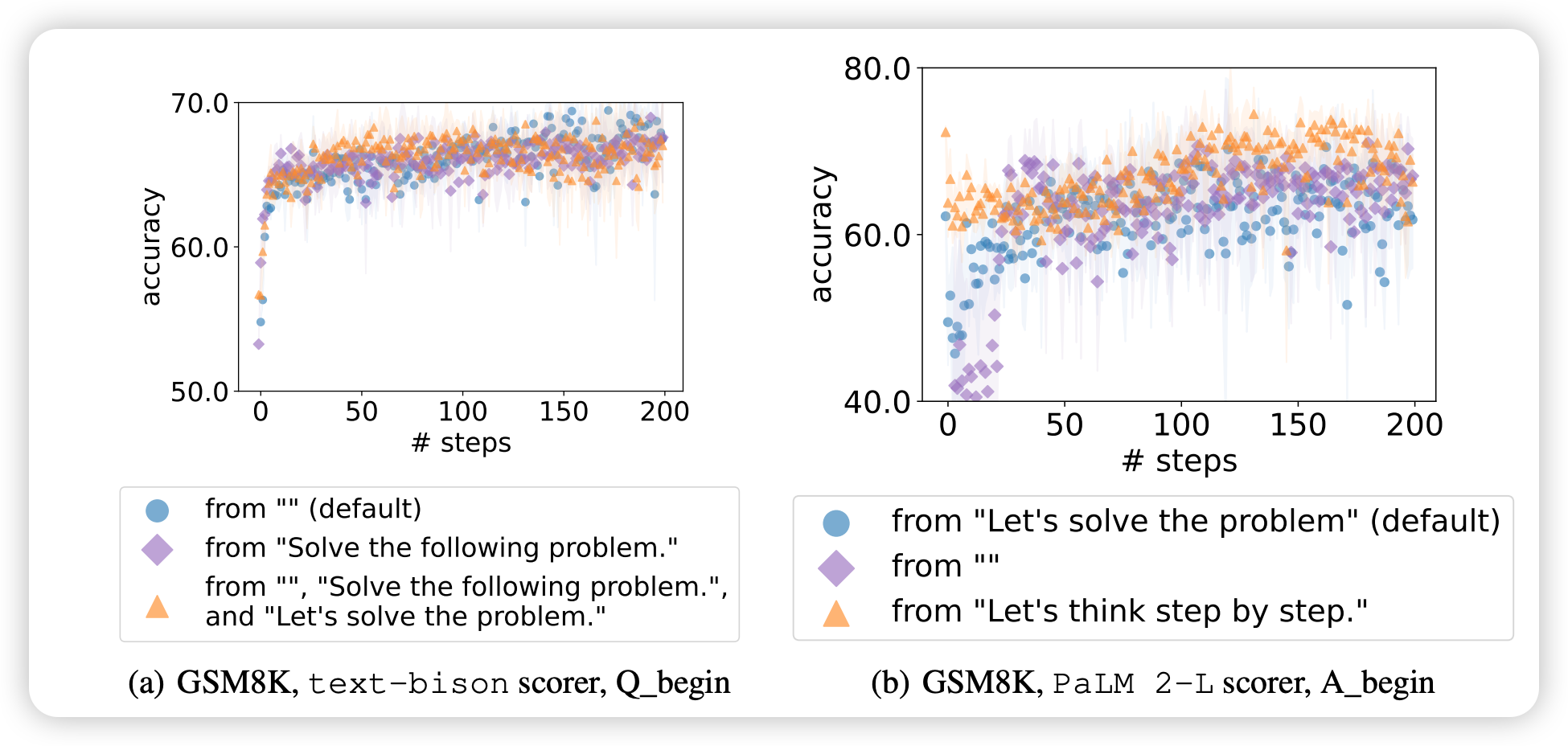
起始指令的影响
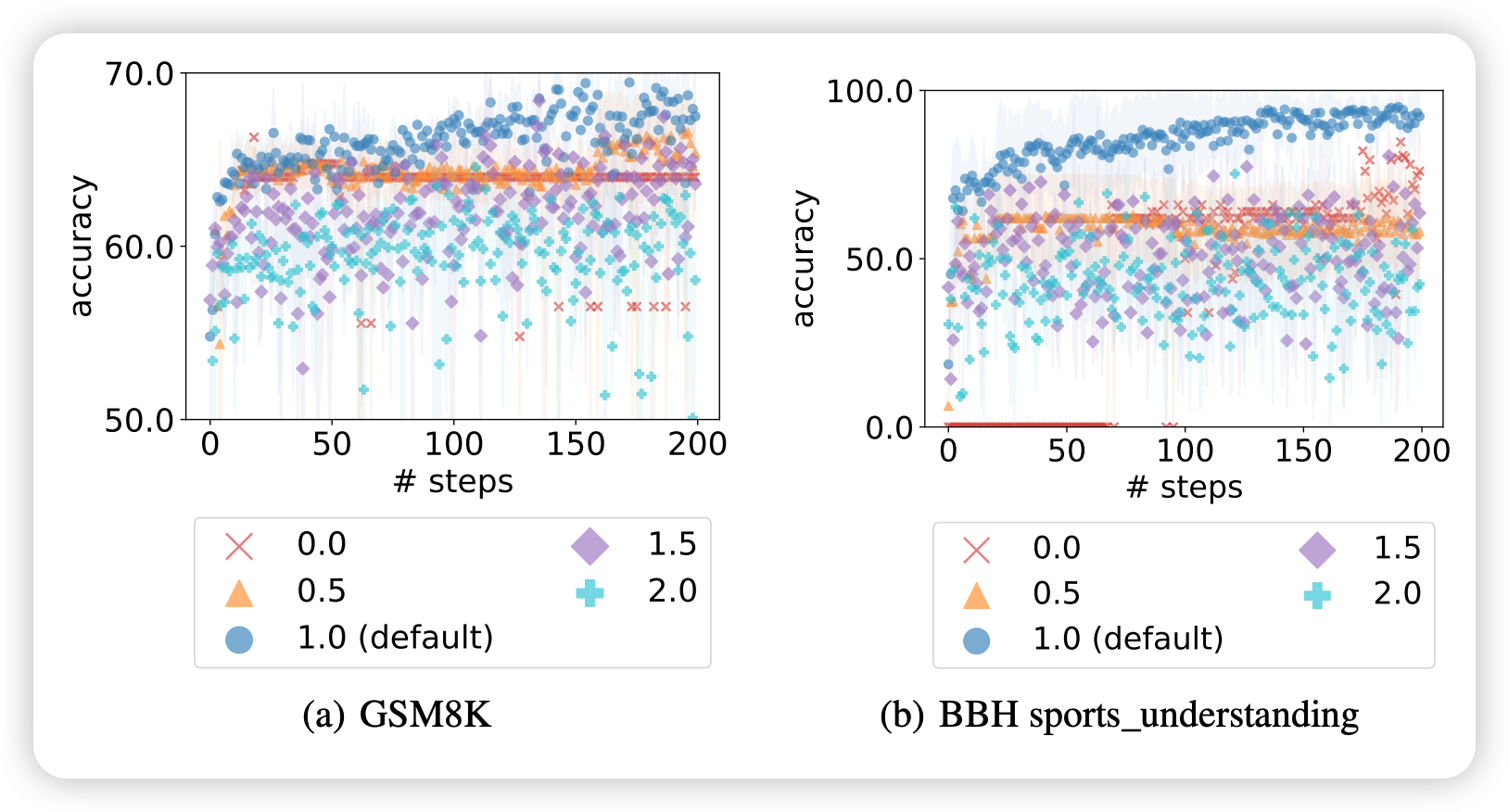
温度参数的消融分析
测试温度: 0.0, 0.5, 1.0(默认), 1.5, 2.0
温度1.0 表现最佳温度过低 (0.0, 0.5):
- 缺乏探索和创造性
- 容易困在相同指令
- 优化曲线平坦温度过高 (1.5, 2.0):
- 缺乏利用性
- 忽略历史轨迹信息
- 优化曲线不稳定
1.8 结论
核心方法论:
- 创新范式: 将LLM作为优化器使用
- 工作机制: LLM基于优化问题描述和历史轨迹逐步生成改进的解决方案
- 应用价值: 展示了LLM在优化领域的巨大潜力
实验验证成果:、
- 数学优化验证
- 线性回归: 证明LLM能理解数值优化逻辑
- 旅行商问题: 在小规模问题上与手工启发式算法性能相当
- 提示词优化突破
- GSM8K数学推理:优化提示词超越人工设计提示词高达8%
- Big-Bench Hard推理任务:最高提升幅度超过50% 、在23个不同任务上普遍有效
- 跨任务转移性:GSM8K优化的指令在MultiArith和AQuA上同样有效
当前局限性与挑战
探索-利用平衡:
- 如何减少对初始化的敏感性
- 如何更好地平衡探索新解与利用已知好解适用范围:
- 当前主要在小到中等规模问题上有效
- 大规模复杂优化问题仍有挑战
提示词优化的具体局限
- 错误案例利用不足
- 训练集依赖性
未来研究方向
- 增强错误分析能力
- 模式总结与知识提取
- 样本效率提升

